python学习【第八篇】python模块
模块与包
模块的概念
在python中一个.py文件就是一个模块。
使用模块可以提高代码的可维护性。
模块分为三种:
- python标准库
- 第三方模块
- 自定义模块
模块的导入方法
1.import语句
import module1[, module2[,... moduleN]
当我们使用import语句的时候,python解释器会去sys.path中搜索对应的文件
2.from ... import 语句
from modname import name1[, name2[, ... nameN]]
3.from ... import * 语句
from modname import *
提供了一个简单的方法来导入一个模块中的所有项目。(不推荐使用)
包
引入了包以后,只要顶层的包名不与别人冲突,那所有模块都不会与别人冲突
每一个包目录下面都会有一个__init__.py的文件,这个文件是必须存在的,否则,Python就把这个目录当成普通目录(文件夹),而不是一个包。__init__.py可以是空文件,也可以有Python代码,因为__init__.py本身就是一个模块,而它的模块名就是对应包的名字。
调用包就是执行包下的__init__.py文件
注:导入包时,如果python解释器找不到,那么需要把myapp的这层路径添加到sys.path中
import sys,os BASE_DIR=os.path.dirname(os.path.dirname(os.path.abspath(__file__))) sys.path.append(BASE_DIR)
调试代码时可以使用:
if __name__ == '__main__': # 在本文件中运行时 __name__ 就等于 __main__
pass
发布模块
创建setup.py文件
from distutils.core import setup
setup(name="hm_message", # 包名
version="1.0", # 版本
description="itheima's 发送和接收消息模块", # 描述信息
long_description="完整的发送和接收消息模块", # 完整描述信息
author="itheima", # 作者
author_email="itheima@itheima.com", # 作者邮箱
url="www.itheima.com", # 主页
py_modules=["hm_message.send_message",
"hm_message.receive_message"])
setup.py
构建模块
$ python3 setup.py build
生成发布压缩包
python3 setup.py sdist
time模块
python中的时间表示形式有三种:
- 时间戳(timestamp) :通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。
- 元组(struct_time):struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天,夏令时)。
- 格式化字符串
import time
# 1 time() :返回当前时间的时间戳
time.time() # 1473525444.037215
# ----------------------------------------------------------
# 2 localtime([secs])
# 将一个时间戳转换为当前时区的struct_time。secs参数未提供,则以当前时间为准。
time.localtime() # time.struct_time(tm_year=2016, tm_mon=9, tm_mday=11, tm_hour=0,
# tm_min=38, tm_sec=39, tm_wday=6, tm_yday=255, tm_isdst=0)
time.localtime(1473525444.037215)
# ----------------------------------------------------------
# 3 gmtime([secs]) 和localtime()方法类似,gmtime()方法是将一个时间戳转换为UTC时区(0时区)的struct_time。
# ----------------------------------------------------------
# 4 mktime(t) : 将一个struct_time转化为时间戳。
print(time.mktime(time.localtime())) # 1473525749.0
# ----------------------------------------------------------
# 5 asctime([t]) : 把一个表示时间的元组或者struct_time表示为这种形式:'Sun Jun 20 23:21:05 1993'。
# 如果没有参数,将会将time.localtime()作为参数传入。
print(time.asctime()) # Sun Sep 11 00:43:43 2016
# ----------------------------------------------------------
# 6 ctime([secs]) : 把一个时间戳(按秒计算的浮点数)转化为time.asctime()的形式。如果参数未给或者为
# None的时候,将会默认time.time()为参数。它的作用相当于time.asctime(time.localtime(secs))。
print(time.ctime()) # Sun Sep 11 00:46:38 2016
print(time.ctime(time.time())) # Sun Sep 11 00:46:38 2016
# 7 strftime(format[, t]) : 把一个代表时间的元组或者struct_time(如由time.localtime()和
# time.gmtime()返回)转化为格式化的时间字符串。如果t未指定,将传入time.localtime()。如果元组中任何一个
# 元素越界,ValueError的错误将会被抛出。
print(time.strftime("%Y-%m-%d %X", time.localtime())) # 2016-09-11 00:49:56
# 8 time.strptime(string[, format])
# 把一个格式化时间字符串转化为struct_time。实际上它和strftime()是逆操作。
print(time.strptime('2011-05-05 16:37:06', '%Y-%m-%d %X'))
# time.struct_time(tm_year=2011, tm_mon=5, tm_mday=5, tm_hour=16, tm_min=37, tm_sec=6,
# tm_wday=3, tm_yday=125, tm_isdst=-1)
# 在这个函数中,format默认为:"%a %b %d %H:%M:%S %Y"。
# 9 sleep(secs)
# 线程推迟指定的时间运行,单位为秒。
# 10 clock()
# 这个需要注意,在不同的系统上含义不同。在UNIX系统上,它返回的是“进程时间”,它是用秒表示的浮点数(时间戳)。
# 而在WINDOWS中,第一次调用,返回的是进程运行的实际时间。而第二次之后的调用是自第一次调用以后到现在的运行
# 时间,即两次时间差

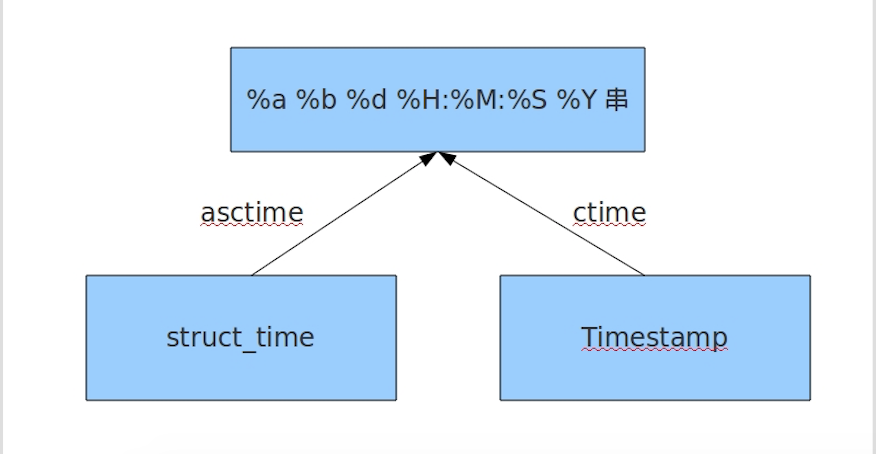
%y 两位数的年份表示(00-99) %Y 四位数的年份表示(000-9999) %m 月份(01-12) %d 月内中的一天(0-31) %H 24小时制小时数(0-23) %I 12小时制小时数(01-12) %M 分钟数(00=59) %S 秒(00-59) %a 本地简化星期名称 %A 本地完整星期名称 %b 本地简化的月份名称 %B 本地完整的月份名称 %c 本地相应的日期表示和时间表示 %j 年内的一天(001-366) %p 本地A.M.或P.M.的等价符 %U 一年中的星期数(00-53)星期天为星期的开始 %w 星期(0-6),星期天为星期的开始 %W 一年中的星期数(00-53)星期一为星期的开始 %x 本地相应的日期表示 %X 本地相应的时间表示 %Z 当前时区的名称 %% %号本身
python中时间日期格式化符号
random模块
import random print(random.random()) # (0,1)----float print(random.randint(1, 3)) # [1,3] print(random.randrange(1, 3)) # [1,3) print(random.choice([1, '23', [4, 5]])) # 23 取任意一个 print(random.sample([1, '23', [4, 5]], 2)) # 取任意两个 print(random.uniform(1, 3)) # 1.927109612082716----float item = [1, 3, 5, 7, 9] random.shuffle(item) # 打乱顺序 print(item)
def general_code():
"""
生成随机验证码
:return:
"""
code = ''
for i in range(5):
num = random.randint(0, 9)
alf = chr(random.randint(65, 90))
add = random.choice([num, alf])
code += str(add)
return code
print(general_code())
随机验证码
os模块
os模块是与系统交互的模块
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为:
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
sys模块
sys.argv 命令行参数List,第一个元素是程序本身路径 sys.exit(n) 退出程序,正常退出时exit(0) sys.version 获取Python解释程序的版本信息 sys.maxint 最大的Int值 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform 返回操作系统平台名称sys.stdout 标准输出
json && pickle
什么是序列化?
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
json
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
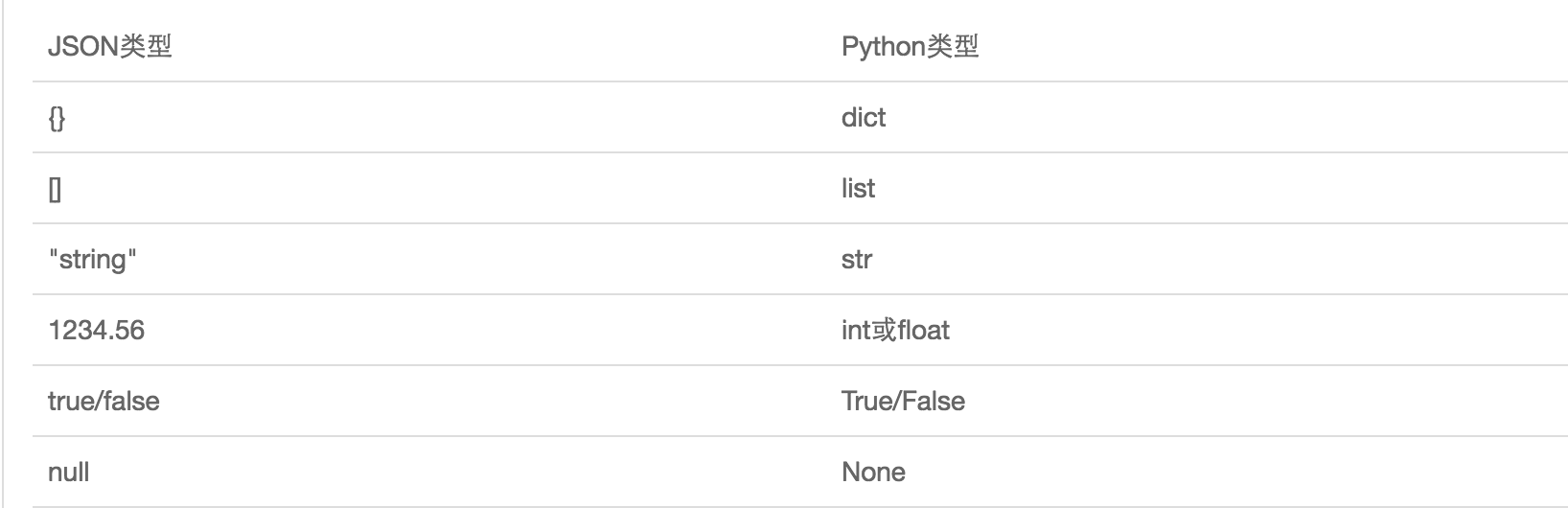
JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下:
import json
dic = {'name': 'alvin', 'age': 23, 'sex': 'male'}
print(type(dic)) # <class 'dict'>
# 序列化
j = json.dumps(dic)
print(type(j)) # <class 'str'>
# 反序列化
d = json.loads(j)
print(type(d)) # <class 'dict'>
注:json类型只认双引号,不认单引号
pickle
import pickle
dic = {'name': 'alvin', 'age': 23, 'sex': 'male'}
print(type(dic)) # <class 'dict'>
# 序列化
j = pickle.dumps(dic)
print(type(j)) # <class 'bytes'>
# 反序列化
data = pickle.loads(j)
print(type(data)) # <class 'dict'>
print(data['name'])
Pickle的问题和所有其他编程语言特有的序列化问题一样,就是它只能用于Python,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的数据,不能成功地反序列化也没关系。
xml模块
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,不过,古时候,在json还没诞生的黑暗年代,大家只能选择用xml呀,至今很多传统公司如金融行业的很多系统的接口还主要是xml。
xml的格式如下,就是通过<>节点来区别数据结构的:
<?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>
xml数据
xml数据
xml协议在各个语言里的都 是支持的,在python中可以用以下模块操作xml:
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml")
root = tree.getroot()
print(root.tag)
#遍历xml文档
for child in root:
print(child.tag, child.attrib)
for i in child:
print(i.tag,i.text)
#只遍历year 节点
for node in root.iter('year'):
print(node.tag,node.text)
#---------------------------------------
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml")
root = tree.getroot()
#修改
for node in root.iter('year'):
new_year = int(node.text) + 1
node.text = str(new_year)
node.set("updated","yes")
tree.write("xmltest.xml")
#删除node
for country in root.findall('country'):
rank = int(country.find('rank').text)
if rank > 50:
root.remove(country)
tree.write('output.xml')
创建xml文档:
import xml.etree.ElementTree as ET
new_xml = ET.Element("namelist")
name = ET.SubElement(new_xml,"name",attrib={"enrolled":"yes"})
age = ET.SubElement(name,"age",attrib={"checked":"no"})
sex = ET.SubElement(name,"sex")
sex.text = '
name2 = ET.SubElement(new_xml,"name",attrib={"enrolled":"no"})
age = ET.SubElement(name2,"age")
age.text = '
et = ET.ElementTree(new_xml) #生成文档对象
et.write("test.xml", encoding="utf-8",xml_declaration=True)
ET.dump(new_xml) #打印生成的格式
创建xml文档
re模块
就其本质而言,正则表达式(或 RE)是一种小型的、高度专业化的编程语言,(在Python中)它内嵌在Python中,并通过 re 模块实现。正则表达式模式被编译成一系列的字节码,然后由用 C 编写的匹配引擎执行。
正则表达式语法
1.普通字符与11个元字符
| 普通字符 | 匹配自身 | 示例 | abc |
| . | 匹配任意除换行符"\n"外的字符(在DOTALL模式中也能匹配换行符 | a.c | abc |
| \ | 转义字符,使后一个字符改变原来的意思 | a\.c;a\\c | a.c;a\c |
| * | 匹配前一个字符0或多次 | abc* | ab;abccc |
| + | 匹配前一个字符1次或无限次 | abc+ | abc;abccc |
| ? | 匹配一个字符0次或1次 | abc? | ab;abc |
| ^ | 匹配字符串开头。在多行模式中匹配每一行的开头 | ^abc | abc |
| $ | 匹配字符串末尾,在多行模式中匹配每一行的末尾 | abc$ | abc |
| | | 或。匹配|左右表达式任意一个,从左到右匹配,如果|没有包括在()中,则它的范围是整个正则表达式 | abc|def |
abc
def
|
| {} | {m}匹配前一个字符m次,{m,n}匹配前一个字符m至n次,若省略n,则匹配m至无限次 | ab{1,2}c |
abc
abbc
|
| [] | 字符集。对应的位置可以是字符集中任意字符。字符集中的字符可以逐个列出,也可以给出范围,如[abc]或[a-c]。[^abc]表示取反,即非abc。 所有特殊字符在字符集中都失去其原有的特殊含义。用\反斜杠转义恢复特殊字符的特殊含义。 |
a[bcd]e |
abe
ace
ade
|
| () | 被括起来的表达式将作为分组,从表达式左边开始没遇到一个分组的左括号“(”,编号+1. 分组表达式作为一个整体,可以后接数量词。表达式中的|仅在该组中有效。 |
(abc){2} a(123|456)c |
abcabc
a456c
|
这里需要强调一下反斜杠\的作用:
- 反斜杠后边跟元字符去除特殊功能;(即将特殊字符转义成普通字符)
- 反斜杠后边跟普通字符实现特殊功能;(即预定义字符)
- 引用序号对应的字组所匹配的字符串
2.预定义字符集(可以写在字符集[...]中)
| \d | 数字:[0-9] | a\bc | a1c |
| \D | 非数字:[^\d] | a\Dc | abc |
| \s | 匹配任何空白字符:[<空格>\t\r\n\f\v] | a\sc | a c |
| \S | 非空白字符:[^\s] | a\Sc | abc |
| \w | 匹配包括下划线在内的任何字字符:[A-Za-z0-9_] | a\wc | abc |
| \W | 匹配非字母字符,即匹配特殊字符 | a\Wc | a c |
| \A | 仅匹配字符串开头,同^ | \Aabc | abc |
| \Z | 仅匹配字符串结尾,同$ | abc\Z | abc |
| \b | 匹配\w和\W之间,即匹配单词边界匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 | \babc\b a\b!bc |
空格abc空格 a!bc |
| \B | [^\b] | a\Bbc | abc |
re模块常用的函数
1.compile()
编译正则表达式模式,返回一个对象的模式。(可以把那些常用的正则表达式编译成正则表达式对象,这样可以提高一点效率。)
格式:re.compile(pattern,flags=0)
pattern:编译时用的表达式字符串
flags:编译标志位,用于修改正则表达式的匹配方式,如:是否区分大小写,多行匹配等。常用的flags有:
| 标志 | 含义 |
| re.S(DOTALL) | 使.匹配包括换行在内的所有字符 |
| re.I(IGNORECASE) | 使匹配对大小写不敏感 |
| re.L(LOCALE) | 做本地化识别(locale-aware)匹配,法语等 |
| re.M(MULTILINE) | 多行匹配,影响^和$ |
| re.X(VERBOSE) | 该标志通过给予更灵活的格式以便将正则表达式写得更易于理解 |
| re.U | 根据Unicode字符集解析字符,这个标志影响\w,\W,\b,\B |
tt = "Tina is a good girl, she is cool, clever, and so on..." rr = re.compile(r'\w*oo\w*') print(rr.findall(tt)) # 查找所有包含'oo'的单词 # 执行结果:['good', 'cool']
2.match()
尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
格式:re.match(pattern, string, flags=0)
import re
print(re.match('www', 'www.runoob.com').group())
# 在起始位置匹配,结果为www
print(re.match('com', 'www.runoob.com'))
# 不在起始位置匹配 结果为None
3.search()
格式:re.search(pattern, string, flags=0)
re.search函数会在字符串内查找模式匹配,只要找到第一个匹配然后返回,如果字符串没有匹配,则返回None。
import re
print(re.search('\dcom','www.4comrunoob.5com').group())
# 执行结果:4com
*注:match和search一旦匹配成功,就是一个match object对象,而match object对象有以下方法:
- group() 返回被re匹配的字符串
- start() 返回匹配开始的位置
- end() 返回匹配结束的位置
- span() 返回一个元组包含匹配 (开始,结束) 的位置
- groups() 方法返回一个包含正则表达式中所有小组字符串的元组,从 1 到所含的小组号,通常groups()不需要参数,返回一个元组,元组中的元就是正则表达式中定义的组。
import re
a = "123abc456"
print(re.search("([0-9]*)([a-z]*)([0-9]*)", a).group(0)) #123abc456,返回整体
print(re.search("([0-9]*)([a-z]*)([0-9]*)", a).group(1)) #123
print(re.search("([0-9]*)([a-z]*)([0-9]*)", a).group(2)) #abc
print(re.search("([0-9]*)([a-z]*)([0-9]*)", a).group(3)) #456
# 列出第一个括号匹配部分,group(2) 列出第二个括号匹配部分,group(3) 列出第三个括号匹配部分
4、findall()
re.findall遍历匹配,可以获取字符串中所有匹配的字符串,返回一个列表。
格式:re.findall(pattern, string, flags=0)
import re
p = re.compile(r'\d+')
print(p.findall('o1n2m3k4'))
执行结果如下:
['1', '2', '3', '4']
tt = "Tina is a good girl, she is cool, clever, and so on..."
rr = re.compile(r'\w*oo\w*')
print(rr.findall(tt))
print(re.findall(r'(\w)*oo(\w)', tt)) # ()表示子表达式
# 执行结果如下:
# ['good', 'cool']
# [('g', 'd'), ('c', 'l')]
5.split()
按照能够匹配的子串将string分割后返回列表。
可以使用re.split来分割字符串,如:re.split(r'\s+', text);将字符串按空格分割成一个单词列表。
格式:re.split(pattern, string[, maxsplit])
maxsplit:指最大分割次数,不指定将全部分割
import re
print(re.split('\d+','one1two2three3four4five5'))
执行结果如下:
['one', 'two', 'three', 'four', 'five', '']
6.sub()
使用re替换string中每一个匹配的子串后返回替换后的字符串。
格式:re.sub(pattern, repl, string, count)
import re text = "JGood is a handsome boy, he is cool, clever, and so on..." print(re.sub(r'\s+', '-', text)) 执行结果如下: JGood-is-a-handsome-boy,-he-is-cool,-clever,-and-so-on... 其中第二个函数是替换后的字符串;本例中为'-' 第四个参数指替换个数。默认为0,表示每个匹配项都替换。
re.sub还允许使用函数对匹配项的替换进行复杂的处理。
如:re.sub(r'\s', lambda m: '[' + m.group(0) + ']', text, 0);将字符串中的空格' '替换为'[ ]'。
import re text = "JGood is a handsome boy, he is cool, clever, and so on..." print(re.sub(r'\s+', lambda m:'['+m.group(0)+']', text,0)) 执行结果如下: JGood[ ]is[ ]a[ ]handsome[ ]boy,[ ]he[ ]is[ ]cool,[ ]clever,[ ]and[ ]so[ ]on...
贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪则相反,总是尝试匹配尽可能少的字符。在"*","?","+","{m,n}"后面加上?,使贪婪变成非贪婪
>>> s="This is a number 1112-3333-111-42223"
>>> r=re.match("(.+)(\d+-\d+-\d+-\d+)",s) # 贪婪模式
>>> r.group(1)
'This is a number 111'
>>> r=re.match("(.+?)(\d+-\d+-\d+-\d+)",s) # 非贪婪模式
>>> r.group(1)
'This is a number'
>>>
python学习【第八篇】python模块的更多相关文章
- python学习第八讲,python中的数据类型,列表,元祖,字典,之字典使用与介绍
目录 python学习第八讲,python中的数据类型,列表,元祖,字典,之字典使用与介绍.md 一丶字典 1.字典的定义 2.字典的使用. 3.字典的常用方法. python学习第八讲,python ...
- Python 学习 第八篇:函数2(参数、lamdba和函数属性)
函数的参数是参数暴露给外部的接口,向函数传递参数,可以控制函数的流程,函数可以0个.1个或多个参数:在Python中向函数传参,使用的是赋值方式. 一,传递参数 参数是通过赋值来传递的,传递参数的特点 ...
- Python学习笔记进阶篇——总览
Python学习笔记——进阶篇[第八周]———进程.线程.协程篇(Socket编程进阶&多线程.多进程) Python学习笔记——进阶篇[第八周]———进程.线程.协程篇(异常处理) Pyth ...
- Python学习笔记基础篇——总览
Python初识与简介[开篇] Python学习笔记——基础篇[第一周]——变量与赋值.用户交互.条件判断.循环控制.数据类型.文本操作 Python学习笔记——基础篇[第二周]——解释器.字符串.列 ...
- Python 学习 第十篇 CMDB用户权限管理
Python 学习 第十篇 CMDB用户权限管理 2016-10-10 16:29:17 标签: python 版权声明:原创作品,谢绝转载!否则将追究法律责任. 不管是什么系统,用户权限都是至关重要 ...
- Python学习系列(六)(模块)
Python学习系列(六)(模块) Python学习系列(五)(文件操作及其字典) 一,模块的基本介绍 1,import引入其他标准模块 标准库:Python标准安装包里的模块. 引入模块的几种方式: ...
- python学习第四十八天json模块与pickle模块差异
在开发过程中,字符串和python数据类型进行转换,下面比较python学习第四十八天json模块与pickle模块差异. json 的优点和缺点 优点 跨语言,体积小 缺点 只能支持 int st ...
- Python学习day17-常用的一些模块
figure:last-child { margin-bottom: 0.5rem; } #write ol, #write ul { position: relative; } img { max- ...
- python学习第六讲,python中的数据类型,列表,元祖,字典,之列表使用与介绍
目录 python学习第六讲,python中的数据类型,列表,元祖,字典,之列表使用与介绍. 二丶列表,其它语言称为数组 1.列表的定义,以及语法 2.列表的使用,以及常用方法. 3.列表的常用操作 ...
- python学习第七讲,python中的数据类型,列表,元祖,字典,之元祖使用与介绍
目录 python学习第七讲,python中的数据类型,列表,元祖,字典,之元祖使用与介绍 一丶元祖 1.元祖简介 2.元祖变量的定义 3.元祖变量的常用操作. 4.元祖的遍历 5.元祖的应用场景 p ...
随机推荐
- 使用MyEclipse创建可执行jar
MyEclipse请从这里下载: http://pan.baidu.com/s/1o6Jm5vk 具体步骤: 右键点工程->Export->选择Java下面的Runnable Jar Fi ...
- HDU 2191悼念512汶川大地震遇难同胞——珍惜如今,感恩生活(多重背包)
HDU 2191悼念512汶川大地震遇难同胞--珍惜如今.感恩生活(多重背包) http://acm.hdu.edu.cn/showproblem.php?pid=2191 题意: 如果你有资金n元, ...
- vue - config
build/build.js -> config 详细的config配置走向.
- odoo8.0条形码改为js方式处理
群里网友@上海-gavin 提供的odoo条形码处理,将原来的图片生成方式改为js处理方式. <div class="row text-center"> <div ...
- HDU 5407(2015多校10)-CRB and Candies(组合数最小公倍数+乘法逆元)
题目地址:pid=5407">HDU 5407 题意:CRB有n颗不同的糖果,如今他要吃掉k颗(0<=k<=n),问k取0~n的方案数的最小公倍数是多少. 思路:首先做这道 ...
- C# 匿名类型 分组 求和
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.T ...
- HDU 3085 双广
n*m地图上有 '. ':路 'X':墙 'Z':鬼,每秒蔓延2个单位长度,能够穿墙.共两个,每秒開始时鬼先动 'M':一号,每分钟可移动3个单位长度 'G':二号,每分钟课移动1个单位长度 问两人能 ...
- ssl中间证书
中间证书,其实也叫中间CA(中间证书颁发机构,Intermediate certificate authority, Intermedia CA),对应的是根证书颁发机构(Root certifica ...
- Go环境IDE安装配置
终于配好了自己的Go环境,每天可以来一点积累了. MAC安装配置过程参考了如下几个博文~谢谢 Intellij安装配置: http://blog.csdn.net/fenglailea/article ...
- 关于Xilinx FPGA JTAG下载时菊花链路中的芯片数量
关于Xilinx FPGA JTAG下载时菊花链路中的芯片数量 emesjx | 2014-08-13 13:13:30 阅读:1793 发布文章 当一个系统中含有多片(2片以上)Xil ...