MapReduce框架结构及代码示例
一个完整的 mapreduce 程序在分布式运行时有三类实例进程:
1、MRAppMaster:负责整个程序的过程调度及状态协调
2、MapTask:负责 map 阶段的整个数据处理流程
3、ReduceTask:负责 reduce 阶段的整个数据处理流程
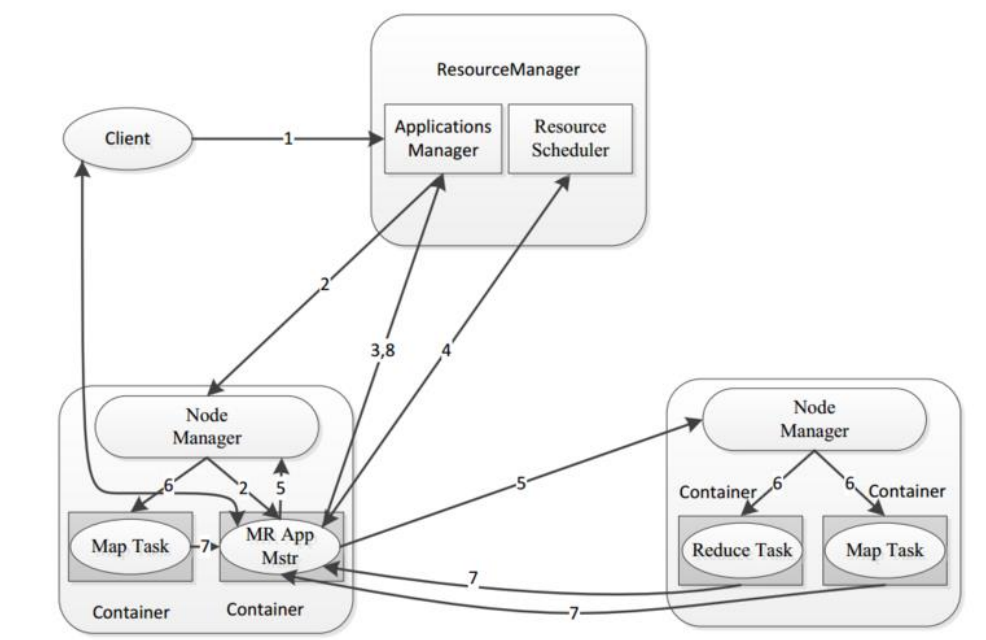
设计构思
MapReduce 是一个分布式运算程序的编程框架,核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在Hadoop 集群上。
既然是做计算的框架,那么表现形式就是有个输入(input),MapReduce 操作这个输入(input),通过本身定义好的计算模型,得到一个输出(output)。
对许多开发者来说,自己完完全全实现一个并行计算程序难度太大,而MapReduce 就是一种简化并行计算的编程模型,降低了开发并行应用的入门门槛。
Hadoop MapReduce 构思体现在如下的三个方面:
- 如何对付大数据处理:分而治之
对相互间不具有计算依赖关系的大数据,实现并行最自然的办法就是采取分而治之的策略。并行计算的第一个重要问题是如何划分计算任务或者计算数据以便对划分的子任务或数据块同时进行计算。不可分拆的计算任务或相互间有依赖关系的数据无法进行并行计算!
- 构建抽象模型:Map 和 Reduce
MapReduce 借鉴了函数式语言中的思想,用 Map 和 Reduce 两个函数提供了高层的并行编程抽象模型。
Map: 对一组数据元素进行某种重复式的处理;
Reduce: 对 Map 的中间结果进行某种进一步的结果整理。
MapReduce 中定义了如下的 Map 和 Reduce 两个抽象的编程接口,由用户去编程实现:
map: (k1; v1) → [(k2; v2)]
reduce: (k2; [v2]) → [(k3; v3)]
Map 和 Reduce 为程序员提供了一个清晰的操作接口抽象描述。通过以上两个编程接口,大家可以看出 MapReduce 处理的数据类型是<key,value>键值对。
- 统一构架,隐藏系统层细节
如何提供统一的计算框架,如果没有统一封装底层细节,那么程序员则需要考虑诸如数据存储、划分、分发、结果收集、错误恢复等诸多细节;为此,MapReduce 设计并提供了统一的计算框架,为程序员隐藏了绝大多数系统层面的处理细节。
MapReduce 最大的亮点在于通过抽象模型和计算框架把需要做什么(whatneed to do)与具体怎么做(how to do)分开了,为程序员提供一个抽象和高层的编程接口和框架。程序员仅需要关心其应用层的具体计算问题,仅需编写少量的处理应用本身计算问题的程序代码。如何具体完成这个并行计算任务所相关的诸多系统层细节被隐藏起来,交给计算框架去处理:从分布代码的执行,到大到数千小到单个节点集群的自动调度使用。
代码示例
- pom依赖
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.4</version>
</dependency>
</dependencies> <build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>2.4</version>
<configuration>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<classpathPrefix>lib/</classpathPrefix>
<mainClass>hadoop.mr.wc.WordCountDriver</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
</plugins>
</build>
- Mapper类
/**
* mr程序执行的时候mapper阶段运行的类,也就是maptask
*/
public class WordCountMapper extends Mapper<LongWritable,Text,Text,IntWritable> {
//该方法为map阶段具体的业务逻辑的实现
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//获取传入的一行内容
String line = value.toString();
//按照分隔符切割数据返回数组
String[] words = line.split(" ");
//遍历数组
for (String word : words) {
//每出现一个单词都标记1
context.write(new Text(word),new IntWritable(1));
}
}
}
- Reducer类
/**
* mr程序执行的时候reducer阶段运行的类,也就是reducertask
*/
public class WordCountReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
//该方法为reducer阶段具体的业务逻辑的实现
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//定义一个变量统计
int count = 0;
//遍历所有value所在的迭代器 累加构成该单词最终的总个数
for (IntWritable value : values) {
count += value.get();
}
//相同key的一组调用reduce完毕,直接输出
context.write(key,new IntWritable(count));
}
}
- 入口函数
/**
* mr程序运行时的主类,除了入口函数之外,还要对mr程序做具体描述
*/
public class WordCountDriver {
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
//指定mr程序使用本地模式模拟一套环境执行mr程序,一般用于本地代码测试
// conf.set("mapreduce.framework.name","local"); //通过job方法获得mr程序运行的实例
Job job = Job.getInstance(conf); //指定本次mr程序的运行主类
job.setJarByClass(WordCountDriver.class);
//指定本次mr程序使用的mapper reduce
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class); //指定本次mr程序map输出的数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class); //指定本次mr程序reduce输出的数据类型,也就是说最终的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); //指定本次mr程序待处理数据目录 输出结果存放目录
FileInputFormat.addInputPath(job,new Path("/wordcount/input"));
FileOutputFormat.setOutputPath(job,new Path("/wordcount/output"));
// FileInputFormat.addInputPath(job,new Path("D:\\wordcount\\input"));
// FileOutputFormat.setOutputPath(job,new Path("D:\\wordcount\\output")); //提交本次mr程序
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);//程序执行成功,退出状态码为0,退出程序,否则为1
}
} - 测试
入口类中被注释的部分为本地测试方法,也就是在windows指定路径中准备测试数据,直接run执行,
而另一种方法是将代码打成jar包上传到集群中,在hdfs上指定路径准备数据,使用hadoop命令启动
hadoop jar wordcount.jar
MapReduce框架结构及代码示例的更多相关文章
- MapReduce序列化及分区的java代码示例
概述 序列化(Serialization)是指把结构化对象转化为字节流. 反序列化(Deserialization)是序列化的逆过程.把字节流转为结构化对象. 当要在进程间传递对象或持久化对象的时候, ...
- Hadoop RCFile存储格式详解(源码分析、代码示例)
RCFile RCFile全称Record Columnar File,列式记录文件,是一种类似于SequenceFile的键值对(Key/Value Pairs)数据文件. 关键词:Reco ...
- MapReduce 编程模型 & WordCount 示例
学习大数据接触到的第一个编程思想 MapReduce. 前言 之前在学习大数据的时候,很多东西很零散的做了一些笔记,但是都没有好好去整理它们,这篇文章也是对之前的笔记的整理,或者叫输出吧.一来是加 ...
- 高级渲染技巧和代码示例 GPU Pro 7
下载代码示例 移动设备正呈现着像素越来越高,屏幕尺寸越来越小的发展趋势. 由于像素着色的能耗非常大,因此 DPI 的增加以及移动设备固有的功耗受限环境为降低像素着色成本带来了巨大的压力. MSAA 有 ...
- Java8-Function使用及Groovy闭包的代码示例
导航 定位 概述 代码示例 Java-Function Groovy闭包 定位 本文适用于想要了解Java8 Function接口编程及闭包表达式的筒鞋. 概述 在实际开发中,常常遇到使用模板模式的场 ...
- [IOS 开发] 懒加载 (延迟加载) 的基本方式,好处,代码示例
懒加载的好处: 1> 不必将创建对象的代码全部写在viewDidLoad方法中,代码的可读性更强 2> 每个属性的getter方法中分别负责各自的实例化处理,代码彼此之间的独立性强,松耦合 ...
- SELECT控件操作的JS代码示例
SELECT控件操作的JS代码示例 1 检测是否有选中 if(objSelect.selectedIndex > -1) { //说明选中 } else { //说明没有选中 } 2.动态创建s ...
- 转:HIBERNATE一些_方法_@注解_代码示例---写的非常好
HIBERNATE一些_方法_@注解_代码示例操作数据库7步骤 : 1 创建一个SessionFactory对象 2 创建Session对象 3 开启事务Transaction : hibernate ...
- Python实现各种排序算法的代码示例总结
Python实现各种排序算法的代码示例总结 作者:Donald Knuth 字体:[增加 减小] 类型:转载 时间:2015-12-11我要评论 这篇文章主要介绍了Python实现各种排序算法的代码示 ...
随机推荐
- rest-assured的默认值与Specification重用
一.默认值 rest-assured发起请求时,默认使用的host为localhost,端口为8080,如果你想使用不同的端口,你可以这样做: given().port(80)...... 或者是简单 ...
- sharepoint_study_3
SharePoint网页无法打开 描述:安装部署好SharePoint开发环境后,再修改计算机的机器名,重启计算机后,发现SharePoint网站不能打开. 解决:1.将机器名改回去,重启计算机,问题 ...
- HDU - 1907 anti-SG
题意:nim游戏,最后取光为[输] anti-SG的应用,搬运一下我的摸鱼小笔记 最先看到的应该是分奇偶的非充裕堆判断,若为偶数则先手胜,否则后手胜 按SG分类 SG!=0时 1.只有一堆大于1,先手 ...
- 页面加载时的div动画
用@keyframes(动画),实现页面加载时的div动画(不要用js控制,因为当页面加载的时候,js还不一定可以使用) 可以在https://daneden.github.io/animate.cs ...
- Robot Framework变量的使用技巧
1.变量的使用 变量可以在命令行中设置,个别变量设置使用--variable (-v)选项,变量文件的选择使用--variablefile (-V)选项.通过命令行设置的变量是全局变量,对其所有执行的 ...
- 使用Maven运行Java main的3种方式使用Maven运行Java main的3种方式
maven使用exec插件运行java main方法,以下是3种不同的操作方式. 一.从命令行运行 1.运行前先编译代码,exec:java不会自动编译代码,你需要手动执行mvn compile来完成 ...
- 1.nginx安装和配置
1.安装 1.1安装编译工具及库文件 yum -y install make zlib zlib-devel gcc-c++ libtool openssl openssl-devel wget 1. ...
- switch case 注意事项
switch case常见的注意事项: 1.case后面常量值的顺序可以任意,一般按顺序编写 2.default顺序也可以编写在switch中的任意位置 当所有case都不满足时则执行default ...
- nginx优化项目
隐藏版本信息 server_tokensSyntax: server_tokens on | off | build | string;Default: server_tokens o ...
- poi生成excel报表合并列
功能任务 poi导出excel统计报表,有合并列的. 根据结构生成层级. 目标 1输入一个linkshashmap LinkedHashMap<String, Object> fieldM ...