决策树 ID3 C4.5 CART(未完)
1.决策树 :监督学习
决策树是一种依托决策而建立起来的一种树。
在机器学习中,决策树是一种预测模型,代表的是一种对象属性与对象值之间的一种映射关系,每一个节点代表某个对象,树中的每一个分叉路径代表某个可能的属性值,而每一个叶子节点则对应从根节点到该叶子节点所经历的路径所表示的对象的值。
决策树仅有单一输出,如果有多个输出,可以分别建立独立的决策树以处理不同的输出。
优点:
- 决策树算法中学习简单的决策规则建立决策树模型的过程非常容易理解,
- 决策树模型可以可视化,非常直观
- 应用范围广,可用于分类和回归,而且非常容易做多类别的分类
- 能够处理数值型和连续的样本特征
缺点:
- 很容易在训练数据中生成复杂的树结构,造成过拟合(overfitting)。剪枝可以缓解过拟合的负作用,常用方法是限制树的高度、叶子节点中的最少样本数量。
- 学习一棵最优的决策树被认为是NP-Complete问题。实际中的决策树是基于启发式的贪心算法建立的,这种算法不能保证建立全局最优的决策树。Random Forest 引入随机能缓解这个问题
2.ID3算法,即Iterative Dichotomiser 3,迭代二叉树3代
1.基于奥卡姆剃刀原理的,即用尽量用较少的东西做更多的事。
2.启发式算法
3.核心思想 用信息增益来度量属性的选择,选择分裂后信息增益最大的属性进行分裂。
2.1信息增益 统计学习方法p60
2.1.1熵
信息熵公式
假如一个随机变量X的取值为{x1,x2,x3....xk},每一种取到的概率分别是{p1,p2,p3....pK},
那么的熵定义为H(X) = -∑ pi log2(pi)(i=1...k)
特点
1.熵只依赖于X的分布,而与X的取值无关(只与概率p有关)
2.熵越大,随机变量的不确定性就越大
对于分类系统来说,类别C变量,它的取值是{C1,C2,C3....CK},而每一个类别出现的概率分别是{P1,P2,P3....PK},
而这里的k就是类别的总数,此时分类系统的熵就可以表示为H(C) = -∑ Pi log2(Pi)(i=1...k)
2.1.2信息增益
信息增益是依赖于特征:看一个特征,系统有它和没有它时的信息量各是多少,两者的差值就是这个特征给系统带来的信息量,即信息增益。
决策树中信息增益 等价于 训练集中类与特征的互信息
(互信息:一个随机变量中包含的关于另一个随机变量的信息量,或者说是一个随机变量由于已知另一个随机变量而减少的不确定性)
决策树学习应用信息增益选择特征
应用信息增益选择特征的方法:对训练数据集(或子集)D,计算其每个特征的信息增益,并比较它们的大小,选择信息增益最大的特征。
计算方法:
1.计算数据集分类的不确定性,p是属于某分类的样本占总体的比例 有几个分类计算几个
2.计算给定特征下数据集分类的不确定性,p是 在特征的某个取值下 属于某分类的样本占 特征在这个取值下总样本数 的比例,有几个分类求几次 加起来。 求得后乘上特征在这个取值下样本数占 总体 的比例 特征有几个取值就计算几个 加起来。
3. 1减去2

2.2 ID3
在决策树的每一个非叶子结点划分之前,先计算每一个属性所带来的信息增益,选择最大信息增益的属性来划分,由该特征的不同取值建立子节点。
因为信息增益越大,区分样本的能力就越强,越具有代表性,很显然这是一种自顶向下的贪心策略。
算法输入:数据集D,特征集A,信息增益阈值,特征的信息增益小于阈值就结束算法,因为剩下的特征区分度不强。
特征如果用作节点就把它从特征集删去
算法输出:决策树T
2.3 ID3算法存在的缺点
(1)ID3算法在选择根节点和各内部节点中的分支属性时,采用信息增益作为评价标准。它一般会优先选择有较多属性值的Feature,因为属性值多的Feature会有相对较大的信息增益(信息增益反映的给定一个条件以后不确定性减少的程度,必然是分得越细的数据集确定性更高,也就是条件熵越小,信息增益越大)
(2)ID3算法只能对描述属性为离散型属性的数据集构造决策树。
(3)只有树的生成,容易过拟合
3.C4.5
C4.5中是用信息增益比率(gain ratio)来作为选择分支的准则。
信息增益比率通过引入一个被称作分裂信息(Split information)的项来惩罚取值较多的Feature。
除此之外,C4.5还弥补了ID3中不能处理特征属性值连续的问题。
(1)用信息增益率来选择属性,选择信息增益率大的产生决策树的节点,克服了用信息增益来选择属性时偏向选择值多的属性的不足。
定义5.3(信息增益比)特征A对训练数据集D的信息增益比定义为其信息增益与训练数据集D关于特征A的值的熵之比,即

分子表示信息增益,和ID3算法一样;
分母表示训练数据集D关于特征A的值的熵
信息增益比本质: 是在信息增益的基础之上乘上一个惩罚参数。特征个数较多时,惩罚参数较小;特征个数较少时,惩罚参数较大。
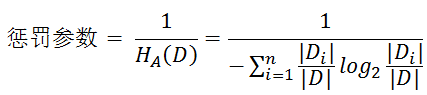
(2)可以处理连续数值型属性
C4.5既可以处理离散型描述属性,也可以处理连续性描述属性。在选择某节点上的分枝属性时,
对于离散型描述属性,C4.5的处理方法与ID3相同,按照该属性本身的取值个数进行计算;
对于某个连续性描述属性Ac,假设在某个结点上的数据集的样本数量为total,C4.5将作以下处理。
Ø 将该结点上的所有数据样本按照连续型描述属性的具体数值,由小到大进行排序,得到属性值的取值序列{A1c,A2c,……Atotalc}。
Ø 在取值序列中生成total-1个分割点。第i(0<i<total)个分割点的取值设置为Vi=(Aic+A(i+1)c)/2,它可以将该节点上的数据集划分为两个子集。
Ø 从total-1个分割点中选择最佳分割点。对于每一个分割点划分数据集的方式,C4.5计算它的信息增益率,并且从中选择信息增益比最大的分割点来划分数据集。
(3)采用悲观剪枝(Pessimistic Error Pruning (PEP)),避免树的高度无节制的增长,避免过度拟合数据。
PEP后剪枝技术是由大师Quinlan提出的。它不需要像REP(错误率降低修剪)样,需要用部分样本作为测试数据,而是完全使用训练数据来生成决策树,又用这些训练数据来完成剪枝。决策树生成和剪枝都使用训练集, 所以会产生错分。现在我们先来介绍几个定义:
|
符号 |
含义 |
|
T1 |
决策树T的所有内部节点(非叶子节点) |
|
T2 |
决策树T的所有叶子节点 |
|
T3 |
决策树T的所有节点,T3=T1∪T2 |
|
n(t) |
节点t的所有样本数 |
|
ni(t) |
节点t中类别i的所有样本数 |
|
e(t) |
t中不属于节点t所标识类别的样本数 |
在剪枝时,我们使用r(t)=e(t)/n(t),就是当节点被剪枝后在训练集上的错误率,而下面公式表示具体的计算公式,其中s为t节点的叶子节点。

在此,我们把错误分布看成是二项式分布,由上面“二项分布的正态逼近”相关介绍知道,上面的式子是有偏差的,因此需要连续性修正因子来矫正数据,有 r‘(t)=[e(t) + 1/2]/n(t):

其中s为t节点的叶子节点,你不认识的那个符号为 t的所有叶子节点的数目。
为了简单,我们就只使用错误数目而不是错误率了,如下e'(t) = [e(t) + 1/2]:

接着求e'(Tt)的标准差,由于误差近似看成是二项式分布,根据u = np, σ2=npq可以得到

当节点t满足下面公式是,Tt子树就会被剪掉:

(4)对于缺失值的处理
在某些情况下,可供使用的数据可能缺少某些属性的值。假如〈x,c(x)〉是样本集S中的一个训练实例,但是其属性A的值A(x)未知。
处理缺少属性值的一种策略是赋给它结点n所对应的训练实例中该属性的最常见值;
另外一种更复杂的策略是为A的每个可能值赋予一个概率。例如,给定一个布尔属性A,如果结点n包含6个已知A=1和4个A=0的实例,那么A(x)=1的概率是0.6,而A(x)=0的概率是0.4。于是,实例x的60%被分配到A=1的分支,40%被分配到另一个分支。这些片断样例(fractional examples)的目的是计算信息增益,另外,如果有第二个缺少值的属性必须被测试,这些样例可以在后继的树分支中被进一步细分。C4.5就是使用这种方法处理缺少的属性值。
C4.5算法的优缺点
优点:产生的分类规则易于理解,准确率较高。
缺点:在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效。此外,C4.5只适合于能够驻留于内存的数据集,当训练集大得无法在内存容纳时程序无法运行。
4.CART(Classification And Regression Tree)分类回归树
分类 基尼指数
基尼指数
定义:基尼指数(基尼不纯度):表示在样本集合中一个随机选中的样本被分错的概率。
注意: Gini指数越小表示集合中被选中的样本被分错的概率越小,也就是说集合的纯度越高,反之,集合越不纯。
即 基尼指数(基尼不纯度)= 样本被选中的概率 * 样本被分错的概率
书中公式:
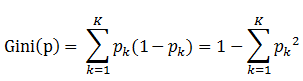
说明:
1. pk表示选中的样本属于k类别的概率,则这个样本被分错的概率是(1-pk)
2. 样本集合中有K个类别,一个随机选中的样本可以属于这k个类别中的任意一个,因而对类别就加和
3. 当为二分类是,Gini(P) = 2p(1-p)
样本集合D的Gini指数 : 假设集合中有K个类别,则:
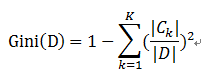
基于特征A划分样本集合D之后的基尼指数:
需要说明的是CART是个二叉树,也就是当使用某个特征划分样本集合只有两个集合:1. 等于给定的特征值 的样本集合D1 , 2 不等于给定的特征值 的样本集合D2
实际上是对拥有多个取值的特征的二值处理。
举个例子:
假设现在有特征 “学历”,此特征有三个特征取值: “本科”,“硕士”, “博士”,
当使用“学历”这个特征对样本集合D进行划分时,划分值分别有三个,因而有三种划分的可能集合,划分后的子集如下:
- 划分点: “本科”,划分后的子集合 : {本科},{硕士,博士}
- 划分点: “硕士”,划分后的子集合 : {硕士},{本科,博士}
- 划分点: “硕士”,划分后的子集合 : {博士},{本科,硕士}
对于上述的每一种划分,都可以计算出基于 划分特征= 某个特征值 将样本集合D划分为两个子集的纯度:
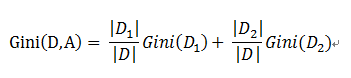
因而对于一个具有多个取值(超过2个)的特征,需要计算以每一个取值作为划分点,对样本D划分之后子集的纯度Gini(D,Ai),(其中Ai 表示特征A的可能取值)
然后从所有的可能划分的Gini(D,Ai)中找出Gini指数最小的划分,这个划分的划分点,便是使用特征A对样本集合D进行划分的最佳划分点。
回归 最小二乘
决策树的 分类树 VS 回归树
提到决策树算法,很多想到的就是上面提到的ID3、C4.5、CART分类决策树。其实决策树分为分类树和回归树,前者用于分类,如晴天/阴天/雨天、用户性别、邮件是否是垃圾邮件,后者用于预测实数值,如明天的温度、用户的年龄等。
作为对比,先说分类树,我们知道ID3、C4.5分类树在每次分枝时,是穷举每一个特征属性的每一个阈值,找到使得按照feature<=阈值,和feature>阈值分成的两个分枝的熵最大的feature和阈值。按照该标准分枝得到两个新节点,用同样方法继续分枝直到所有人都被分入性别唯一的叶子节点,或达到预设的终止条件,若最终叶子节点中的性别不唯一,则以多数人的性别作为该叶子节点的性别。
回归树总体流程也是类似,不过在每个节点(不一定是叶子节点)都会得一个预测值,以年龄为例,该预测值等于属于这个节点的所有人年龄的平均值。分枝时穷举每一个feature的每个阈值找最好的分割点,但衡量最好的标准不再是最大熵,而是最小化均方差--即(每个人的年龄-预测年龄)^2 的总和 / N,或者说是每个人的预测误差平方和 除以 N。这很好理解,被预测出错的人数越多,错的越离谱,均方差就越大,通过最小化均方差能够找到最靠谱的分枝依据。分枝直到每个叶子节点上人的年龄都唯一(这太难了)或者达到预设的终止条件(如叶子个数上限),若最终叶子节点上人的年龄不唯一,则以该节点上所有人的平均年龄做为该叶子节点的预测年龄。
CART算法中某一特征被使用后还能被重复使用吗?
剪枝
https://www.zhihu.com/question/22697086
决策树 ID3 C4.5 CART(未完)的更多相关文章
- 决策树(ID3,C4.5,CART)原理以及实现
决策树 决策树是一种基本的分类和回归方法.决策树顾名思义,模型可以表示为树型结构,可以认为是if-then的集合,也可以认为是定义在特征空间与类空间上的条件概率分布. [图片上传失败...(image ...
- 21.决策树(ID3/C4.5/CART)
总览 算法 功能 树结构 特征选择 连续值处理 缺失值处理 剪枝 ID3 分类 多叉树 信息增益 不支持 不支持 不支持 C4.5 分类 多叉树 信息增益比 支持 ...
- ID3\C4.5\CART
目录 树模型原理 ID3 C4.5 CART 分类树 回归树 树创建 ID3.C4.5 多叉树 CART分类树(二叉) CART回归树 ID3 C4.5 CART 特征选择 信息增益 信息增益比 基尼 ...
- 决策树模型 ID3/C4.5/CART算法比较
决策树模型在监督学习中非常常见,可用于分类(二分类.多分类)和回归.虽然将多棵弱决策树的Bagging.Random Forest.Boosting等tree ensembel 模型更为常见,但是“完 ...
- 机器学习算法总结(二)——决策树(ID3, C4.5, CART)
决策树是既可以作为分类算法,又可以作为回归算法,而且在经常被用作为集成算法中的基学习器.决策树是一种很古老的算法,也是很好理解的一种算法,构建决策树的过程本质上是一个递归的过程,采用if-then的规 ...
- 机器学习相关知识整理系列之一:决策树算法原理及剪枝(ID3,C4.5,CART)
决策树是一种基本的分类与回归方法.分类决策树是一种描述对实例进行分类的树形结构,决策树由结点和有向边组成.结点由两种类型,内部结点表示一个特征或属性,叶结点表示一个类. 1. 基础知识 熵 在信息学和 ...
- 机器学习之决策树二-C4.5原理与代码实现
决策树之系列二—C4.5原理与代码实现 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/9435712.html I ...
- 机器学习总结(八)决策树ID3,C4.5算法,CART算法
本文主要总结决策树中的ID3,C4.5和CART算法,各种算法的特点,并对比了各种算法的不同点. 决策树:是一种基本的分类和回归方法.在分类问题中,是基于特征对实例进行分类.既可以认为是if-then ...
- 决策树(ID3、C4.5、CART)
ID3决策树 ID3决策树分类的根据是样本集分类前后的信息增益. 假设我们有一个样本集,里面每个样本都有自己的分类结果. 而信息熵可以理解为:“样本集中分类结果的平均不确定性”,俗称信息的纯度. 即熵 ...
随机推荐
- sizeof结构体
规则1:结构体的对折长度为其基本数据成员的长度的最大值. 规则2:指定边界情况下,结构体的对折长度为自身对折长度和指定对折长度中较小者. 规则3:当行内结构体的基本数据成员的起始地址必须为其长度的整数 ...
- element-ui 的el-button组件中添加自定义颜色和图标的实现方法
这篇文章主要介绍了element-ui 的el-button组件中添加自定义颜色和图标的实现方法,目前的解决方案是:添加一个自定义全局指令,同时在element-ui源码中,加入对应的组件.需要的朋友 ...
- 【scala】继承
Scala中的继承与Java有着显著的不同. 抽象类abstract class abstract class Car{//抽象类 val carBrand:String;//抽象字段,一个没有被初始 ...
- Codeforces Round #394 (Div. 2) A. Dasha and Stairs
A. Dasha and Stairs time limit per test:2 seconds memory limit per test:256 megabytes input:standard ...
- react login page demo
1. login form import React from "react"; import {Row, Col} from "antd"; import { ...
- php实现安装程序的 安装
install.php 只要填写数据库就可以把数据插入到数据库中,实现安装 <?php header("Content-type:text/html;charset=utf-8&quo ...
- CBP是什么?
coded_block_pattern 简称CBP,用来反映该宏块编码中残差情况的语法元素.CBP共有6位,其中前面2位代表UV分量,描述如下表所示:后面4位是Y分量,分别代表宏块内的4个8x8子宏 ...
- Debian, Ubuntu, LinuxMint 安裝 MySQL 5.7, 5.6, 5.5
以下會示範在 Debian, Ubuntu 及 LinuxMint 分別安裝 MySQL 5.7, 5.6, 5.5 的方法. 首先按照需要的安裝的 MySQL 版本, 加入相應的 Repositor ...
- 让cocos h5里的文字可以在手机上被长按复制
更改CCBoot.js代码: // Adjust mobile css settings if (cc.sys.isMobile) { var fontStyle = document.createE ...
- c++使用http协议上传文件到七牛云服务器
使用c++ http协议上传文件到七牛服务器时,比较搞的一点就是header的设置: "Content-Type:multipart/form-data;boundary=xxx" ...