分布式爬虫搭建系列 之三---scrapy框架初用
第一,scrapy框架的安装
通过命令提示符进行安装(如果没有安装的话)
pip install Scrapy
如果需要卸载的话使用命令为:
pip uninstall Scrapy
第二,scrapy框架的使用
先通过命令提示符创建项目,运行命令:
scrapy startproject crawlquote#crawlquote这是我起的项目名
其次,通过我们的神器PyCharm打开我们的项目--crawlquote(也可以将PyCharm打开我们使用虚拟环境创建的项目)
然后,打开PyCharm的Terminal,如图
然后在命令框中输入
scrapy genspider quotes quotes.toscrape.com
此时的代码目录为:
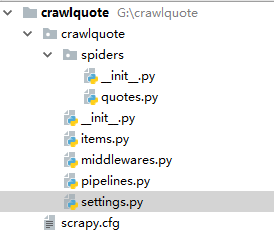
文件说明:
scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
items.py 设置数据存储模板,用于结构化数据,如:Django的Model
pipelines 数据处理行为,如:一般结构化的数据持久化
settings.py 配置文件,如:递归的层数、并发数,延迟下载等
spiders 爬虫目录,如:创建文件,编写爬虫规则
quotes.py使我们书写的爬虫---里面是发起请求-->拿到数据---->临时存储到item.py中
运行爬虫命令为:
scrapy crawl quotes
第三,使用scrapy的基本流程
(1)明确需要爬取的数据有哪些
(2)分析页面结构知道需要爬取的内容在页面中的存在形式
(3)在item.py中定义需要爬取的数据的存储字段
(4)书写爬虫 -spider中定义(spiders中的quotes.py) --数据重新格式化化后在item.py中存储
(5)管道中--pipeline.py ----对item里面的内容在加工 , 以及定义链接数据库的管道
(6)配置文件中----settings.py中开启管道作用:ITEM_PIPELINES ,定义数据库的名称,以及链接地址
(7)中间件中----middlewares.py
根据上述的一个简单的代码演示:
1)item.py中
import scrapy class CrawlquoteItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
text = scrapy.Field()
author = scrapy.Field()
tags = scrapy.Field()
2)spiders--quotes(爬虫)
# -*- coding: utf- -*-
import scrapy
from crawlquote.items import CrawlquoteItem class QuotesSpider(scrapy.Spider):
name = 'quotes'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['http://quotes.toscrape.com/'] def parse(self, response):
quotes = response.css('.quote')
for quote in quotes:
item = CrawlquoteItem()
text = quote.css('.text::text').extract_first() # 获取一个
author = quote.css('.author::text').extract_first()
tags = quote.css('.tags .tag::text').extract()
item['text'] = text
item['author'] = author
item['tags'] = tags
yield item # 将网页中的内容重新生成一个item以便于后面的认识 next = response.css('.pager .next a::attr(href)').extract_first()
url = response.urljoin(next) # urljoin翻页
yield scrapy.Request(url=url, callback=self.parse) # 递归调用
3)pipeline.py中
# -*- coding: utf- -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymongo
from scrapy.exceptions import DropItem class TextPipeline(object):
def __init__(self):
self.limit = def process_item(self, item, spider): # 对重新生成的item进行再制作
if item['text']:
if len(item['text']) > self.limit:
item['text'] = item['text'][:self.limit].rstrip() + '...'
return item
else:
return DropItem('Missing Text') class MongoPipeline(object): # 与数据库有关的操作
def __init__(self, mongo_uri, mongo_db): # () MongoPipeline构造函数
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db @classmethod
def from_crawler(cls, crawler): # ()读取settings里面的值,类方法
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DB')
) def open_spider(self, spider): # ()爬虫启动时需要的操作
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db] def process_item(self, item, spider): # 保存到mongodb数据库
name = item.__class__.__name__
self.db[name].insert(dict(item))
return item def close_spider(self, spider): # 关闭mongodb
self.client.close()
4)settings.py中
BOT_NAME = 'crawlquote' SPIDER_MODULES = ['crawlquote.spiders']
NEWSPIDER_MODULE = 'crawlquote.spiders' #数据库链接
MONGO_URI = 'localhost'
MONGO_DB = 'crawlquote' #项目管道开启
ITEM_PIPELINES = {
'crawlquote.pipelines.TextPipeline': ,
'crawlquote.pipelines.MongoPipeline': ,
}
5)此处还没有用的middelwares.py
总结一下:
针对某部分数据的爬取,先要在item中定义字段,然后在爬虫程序中通过选择器拿到数据并存储到item中,再然后通过pipeline的在加工+setting文件修改--存储到数据库中。此时简单爬取就实现了。
分布式爬虫搭建系列 之三---scrapy框架初用的更多相关文章
- 分布式爬虫搭建系列 之四---scrapy分布式框架
带录入SAFCDS
- 分布式爬虫搭建系列 之一------python安装及以及虚拟环境的配置及scrapy依赖库的安装
python及scrapy框架依赖库的安装步骤: 第一步,python的安装 在Windows上安装Python 首先,根据你的Windows版本(64位还是32位)从Python的官方网站下载Pyt ...
- 分布式爬虫搭建系列 之二-----神器PyCharm的安装
这里我们使用PyCharm作为开发工具,以下过程摘抄于:http://blog.csdn.net/qq_29883591/article/details/52664478 作者:陌上行走 Pytho ...
- Python爬虫进阶三之Scrapy框架安装配置
初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此整理如下. Windows 平台: 我的系统是 ...
- 5、爬虫系列之scrapy框架
一 scrapy框架简介 1 介绍 (1) 什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能(高性能 ...
- 爬虫系列之Scrapy框架
一 scrapy框架简介 1 介绍 (1) 什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能(高性能 ...
- 爬虫(九)scrapy框架简介和基础应用
概要 scrapy框架介绍 环境安装 基础使用 一.什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能 ...
- Python3爬虫(十七) Scrapy框架(一)
Infi-chu: http://www.cnblogs.com/Infi-chu/ 1.框架架构图: 2.各文件功能scrapy.cfg 项目的配置文件items.py 定义了Item数据结构,所有 ...
- 爬虫 (5)- Scrapy 框架简介与入门
Scrapy 框架 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页 ...
随机推荐
- STL标准容器特征
一. vector vector类是一种顺序容器,可以看作动态数组,容器中的元素存放在连续存储区域. vector容器自动分配.释放.扩展.收缩存储空间,不需要使用new或delete关键字. vec ...
- 有云Ceph课堂:使用CivetWeb快速搭建RGW
转自:https://www.ustack.com/blog/civetweb/ 优秀的开源项目正在改变传统IT,OpenStack名头最响,已经成为了IaaS的事实标准.Ceph同样颇有建树,通过其 ...
- Hadoop WordCount程序
一.把所有Hadoop的依赖jar包导入buildpath,不用一个一个调,都导一遍就可以,因为是一个工程,所以覆盖是没有问题的 二.写wordcount程序 1.工程目录结构如下: 2.写mappe ...
- 关于微软C#中的CHART图表控件的简单使用
最近公司项目要用到Chart图表控件,这是一个比较老的东西了,目前网络上似乎已经不太流行这个控件,但是只要配置了相关的属性,效果还是可以的.前前后后摸索了好久,接下来谈谈这个件控件最重要的几个属性. ...
- 内存保护机制及绕过方案——通过覆盖虚函数表绕过/GS机制
1 GS内存保护机制 1.1 GS工作原理 栈中的守护天使--GS,亦称作Stack Canary / Cookie,从VS2003起开始启用(也就说,GS机制是由编译器决定的,跟操作系统 ...
- java中的策略设计模式
本文主要讲java中的策略模式:一个可以根据不同的传入参数而具有不同行为的方法,就叫策略模式.概念可能有点不好理解,具体看下面代码: import java.util.Arrays; /** * 策略 ...
- CFile与CArchive区别
一,区别 CFile是直接与磁盘打交道的一个文件对象,可以处理文本和二进制文件 CArchive将CFile作为自己的一个参数,通过该参数可以实现文本,二进制甚至继承至COject对象的类的本地存储和 ...
- canvas 绘制坐标轴
结果: 代码: <!DOCTYPE html> <html> <head lang="en"> <meta charset="U ...
- Java中最常见的十道面试题
第一,谈谈final, finally, finalize的区别. final?修饰符(关键字)如果一个类被声明为final,意味着它不能再派生出新的子类,不能作为父类被继承.因此一个类不能既被声明为 ...
- 关于Sublime Text不能在打开方式中显示并且不能被设置成默认打开方式的问题
解决方法: 1. Windows 输入 regedit 后 回车 打开注册表 2.找到 "HKEY_CLASSES_ROOT\Applications\sublime_text.exe\sh ...