python 正则表达式 (重点) re模块
京东的注册页面,打开页面我们就看到这些要求输入个人信息的提示。
假如我们随意的在手机号码这一栏输入一个11111111111,它会提示我们格式有误。
这个功能是怎么实现的呢?
假如现在你用python写一段代码,类似:
phone_number = input('please input your phone number : ')
你怎么判断这个phone_number是合法的呢?
根据手机号码一共11位并且是只以13、14、15、18开头的数字这些特点,我们用python写了如下代码:
while True:
phone_number = input('please input your phone number : ')
if len(phone_number) == 11 \
and phone_number.isdigit()\
and (phone_number.startswith('') \
or phone_number.startswith('') \
or phone_number.startswith('') \
or phone_number.startswith('')):
print('是合法的手机号码')
else:
print('不是合法的手机号码')
low版
import re
phone_number = input('please input your phone number : ')
if re.match('^(13|14|15|18)[0-9]{9}$',phone_number):
print('是合法的手机号码')
else:
print('不是合法的手机号码')
正则版
对比上面的两种写法,此时此刻,我要问你你喜欢哪种方法呀?你肯定还是会说第一种,为什么呢?因为第一种不用学呀!
但是如果现在有一个文件,我让你从整个文件里匹配出所有的手机号码。你用python给我写个试试?
但是学了今天的技能之后,分分钟帮你搞定!
今天我们要学习python里的re模块和正则表达式,学会了这个就可以帮我们解决刚刚的疑问。正则表达式不仅在python领域,在整个编程届都占有举足轻重的地位。
不管以后你是不是去做python开发,只要你是一个程序员就应该了解正则表达式的基本使用。如果未来你要在爬虫领域发展,你就更应该好好学习这方面的知识。
但是你要知道,re模块本质上和正则表达式没有一毛钱的关系。re模块和正则表达式的关系 类似于 time模块和时间的关系
你没有学习python之前,也不知道有一个time模块,但是你已经认识时间了 12:30就表示中午十二点半(这个时间可好,一般这会儿就该下课了)。
时间有自己的格式,年月日时分秒,12个月,365天......已经成为了一种规则。你也早就牢记于心了。time模块只不过是python提供给我们的可以方便我们操作时间的一个工具而已
正则表达式本身也和python没有什么关系,就是匹配字符串内容的一种规则。
官方定义:正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,
这个“规则字符串”用来表达对字符串的一种过滤逻辑。
正则表达式
一说规则我已经知道你很晕了,现在就让我们先来看一些实际的应用。在线测试工具 http://tool.chinaz.com/regex/
首先你要知道的是,谈到正则,就只和字符串相关了。在我给你提供的工具中,你输入的每一个字都是一个字符串。
其次,如果在一个位置的一个值,不会出现什么变化,那么是不需要规则的。
比如你要用"1"去匹配"1",或者用"2"去匹配"2",直接就可以匹配上。这连python的字符串操作都可以轻松做到。
那么在之后我们更多要考虑的是在同一个位置上可以出现的字符的范围。
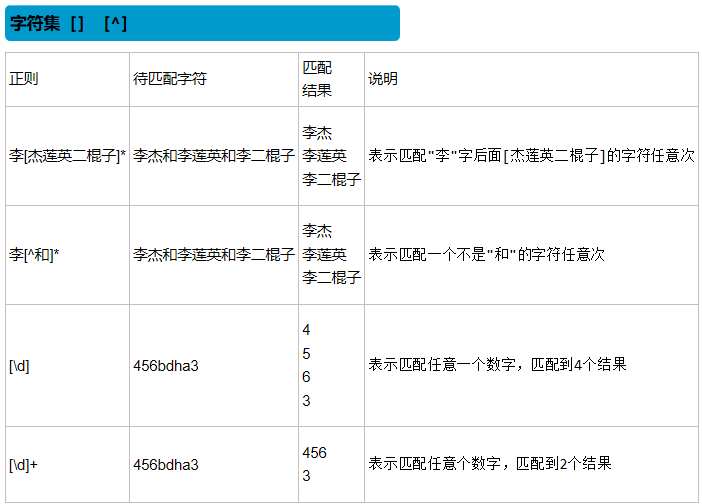
字符组 : [字符组]
在同一个位置可能出现的各种字符组成了一个字符组,在正则表达式中用[]表示
字符分为很多类,比如数字、字母、标点等等。
假如你现在要求一个位置"只能出现一个数字",那么这个位置上的字符只能是0、1、2...9这10个数之一。
字符组
正则 |
待匹配字符 |
匹配 |
说明 |
[0123456789] |
8 |
True |
在一个字符组里枚举合法的所有字符,字符组里的任意一个字符 |
[0123456789] |
a |
False |
由于字符组中没有"a"字符,所以不能匹配 |
[0-9] |
7 |
True |
也可以用-表示范围,[0-9]就和[0123456789]是一个意思 |
[a-z] |
s |
True |
同样的如果要匹配所有的小写字母,直接用[a-z]就可以表示 |
[A-Z] |
B |
True |
[A-Z]就表示所有的大写字母 |
[0-9a-fA-F] |
e |
True |
可以匹配数字,大小写形式的a~f,用来验证十六进制字符 |
字符:
元字符 |
匹配内容 |
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母或数字或下划线 |
| \s | 匹配任意的空白符 |
| \d | 匹配数字 |
| \n | 匹配一个换行符 |
| \t | 匹配一个制表符 |
| \b | 匹配一个单词的结尾 |
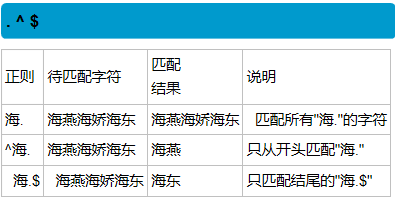
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结尾 |
| \W |
匹配非字母或数字或下划线 |
| \D |
匹配非数字 |
| \S |
匹配非空白符 |
| a|b |
匹配字符a或字符b |
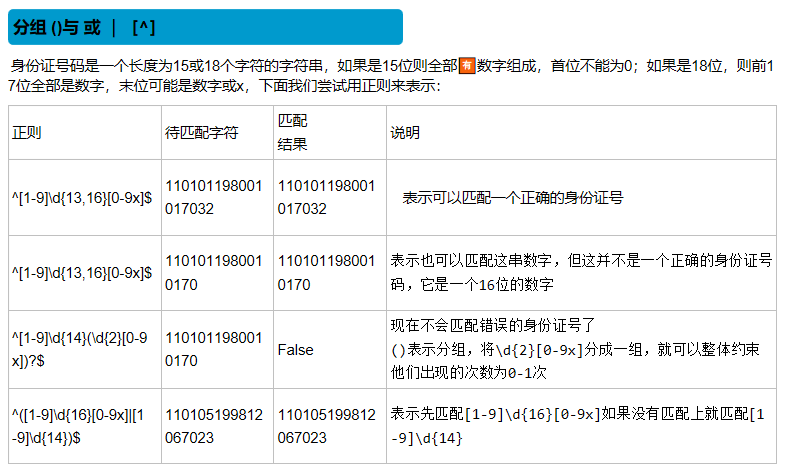
| () |
匹配括号内的表达式,也表示一个组 |
| [...] |
匹配字符组中的字符 |
| [^...] |
匹配除了字符组中字符的所有字符 |



re模块下的常用方法
ret = re.findall('\d+','kjasdgk912798jkshf912847jzhsfk91278')
print(ret)
# 一次性返回所有匹配到的项,直接存在列表中
import re
# ret = re.findall('\d+(?:\.\d+)?','1.2345+4.3')
# ?:写在一个分组的最开始,表示在findall方法中取消这个分组的优先级
# 1.2345 4.3
# .2345 .3
# print(ret)
例子2:
# ret = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com')
# print(ret) 加上?:打印全部,不加打印oldboy
findall
注意:
1 findall的优先级查询:

import re
ret = re.findall('www.(baidu|oldboy).com', 'www.oldboy.com')
print(ret) # ['oldboy'] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可
ret = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com')
print(ret) # ['www.oldboy.com']
ret = re.search('a', 'eva egon yuan').group()
print(ret) #结果 : 'a'
# 函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以
# 通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。
search
注意:
s="2.22*33"
m=re.search("(\d+\.\d+)([*])(\d+)",s)
print(m.group(0)) 2.22*33
print(m.group(1)) 2.22
print(m.group(2)) *
print(m.group(3)) 33
ret = re.match('a', 'abc').group() # 同search,不过只在字符串开始处进行匹配
print(ret)
#结果 : 'a'
match
ret = re.split('[ab]', 'abcd') # 先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割
print(ret) # ['', '', 'cd']
# split中如果带有分组,会在分割的同时保留被分割内容中带分组的部分
# ret = re.split('(\d\d)','alex83wusir38egon20')
# print(ret) ['alex', '83', 'wusir', '38', 'egon', '20', '']
split
ret = re.sub('\d', 'H', 'eva3egon4yuan4', 1)#将数字替换成'H',参数1表示只替换1个
print(ret) #evaHegon4yuan4
sub
ret = re.subn('\d', 'H', 'eva3egon4yuan4')#将数字替换成'H',返回元组(替换的结果,替换了多少次)
print(ret) ('evaHegonHyuanH', 3)
subn
obj = re.compile('\d{3}') #将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字
ret = obj.search('abc123eeee') #正则表达式对象调用search,参数为待匹配的字符串
print(ret.group()) #结果 : 123
compile
ret = re.finditer('\d', 'ds3sy4784a') #finditer返回一个存放匹配结果的迭代器
print(ret) # <callable_iterator object at 0x10195f940>
print(next(ret).group()) #查看第一个结果
print(next(ret).group()) #查看第二个结果
print([i.group() for i in ret]) #查看剩余的左右结果
finditer
综合练习与扩展
import re
ret = re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>")
#还可以在分组中利用?<name>的形式给分组起名字
#获取的匹配结果可以直接用group('名字')拿到对应的值
print(ret.group('tag_name')) #结果 :h1
print(ret.group()) #结果 :<h1>hello</h1>
ret = re.search(r"<(\w+)>\w+</\1>","<h1>hello</h1>")
#如果不给组起名字,也可以用\序号来找到对应的组,表示要找的内容和前面的组内容一致
#获取的匹配结果可以直接用group(序号)拿到对应的值
print(ret.group(1))
print(ret.group()) #结果 :<h1>hello</h1>
匹配标签
import re ret=re.findall(r"\d+","1-2*(60+(-40.35/5)-(-4*3))")
print(ret) #['1', '2', '60', '40', '35', '5', '4', '3']
ret=re.findall(r"-?\d+\.\d*|(-?\d+)","1-2*(60+(-40.35/5)-(-4*3))")
print(ret) #['1', '-2', '60', '', '5', '-4', '3']
ret.remove("")
print(ret) #['1', '-2', '60', '5', '-4', '3']
匹配整数
1、 匹配一段文本中的每行的邮箱
http://blog.csdn.net/make164492212/article/details/51656638 2、 匹配一段文本中的每行的时间字符串,比如:‘1990-07-12’; 分别取出1年的12个月(^(0?[1-9]|1[0-2])$)、
一个月的31天:^((0?[1-9])|((1|2)[0-9])|30|31)$ 3、 匹配qq号。(腾讯QQ号从10000开始) [1,9][0,9]{4,} 4、 匹配一个浮点数。 ^(-?\d+)(\.\d+)?$ 或者 -?\d+\.?\d* 5、 匹配汉字。 ^[\u4e00-\u9fa5]{0,}$ 6、 匹配出所有整数
数字匹配
import requests import re
import json def getPage(url): response=requests.get(url)
return response.text def parsePage(s): com=re.compile('<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\d+).*?<span class="title">(?P<title>.*?)</span>'
'.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>',re.S) ret=com.finditer(s)
for i in ret:
yield {
"id":i.group("id"),
"title":i.group("title"),
"rating_num":i.group("rating_num"),
"comment_num":i.group("comment_num"),
} def main(num): url='https://movie.douban.com/top250?start=%s&filter='%num
response_html=getPage(url)
ret=parsePage(response_html)
print(ret)
f=open("move_info7","a",encoding="utf8") for obj in ret:
print(obj)
data=json.dumps(obj,ensure_ascii=False)
f.write(data+"\n") if __name__ == '__main__':
count=0
for i in range(10):
main(count)
count+=25
爬虫练习简单版
import re
import json
from urllib.request import urlopen def getPage(url):
response = urlopen(url)
return response.read().decode('utf-8') def parsePage(s):
com = re.compile(
'<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\d+).*?<span class="title">(?P<title>.*?)</span>'
'.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>', re.S) ret = com.finditer(s)
for i in ret:
yield {
"id": i.group("id"),
"title": i.group("title"),
"rating_num": i.group("rating_num"),
"comment_num": i.group("comment_num"),
} def main(num):
url = 'https://movie.douban.com/top250?start=%s&filter=' % num
response_html = getPage(url)
ret = parsePage(response_html)
print(ret)
f = open("move_info7", "a", encoding="utf8") for obj in ret:
print(obj)
data = str(obj)
f.write(data + "\n") count = 0
for i in range(10):
main(count)
count += 25
爬虫练习高级版
flags有很多可选值: re.I(IGNORECASE)忽略大小写,括号内是完整的写法
re.M(MULTILINE)多行模式,改变^和$的行为
re.S(DOTALL)点可以匹配任意字符,包括换行符
re.L(LOCALE)做本地化识别的匹配,表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境,不推荐使用
re.U(UNICODE) 使用\w \W \s \S \d \D使用取决于unicode定义的字符属性。在python3中默认使用该flag
re.X(VERBOSE)冗长模式,该模式下pattern字符串可以是多行的,忽略空白字符,并可以添加注释
flags

在线测试工具 http://tool.chinaz.com/regex/
python 正则表达式 (重点) re模块的更多相关文章
- python正则表达式之re模块方法介绍
python正则表达式之re模块其他方法 1:search(pattern,string,flags=0) 在一个字符串中查找匹配 2:findall(pattern,string,flags=0) ...
- python正则表达式与re模块-02
正则表达式 正则表达式与python的关系 # 正则表达式不是Python独有的,它是一门独立的技术,所有的编程语言都可以使用正则 # 但要在python中使用正则表达式,就必须依赖于python内置 ...
- Python正则表达式与re模块介绍
Python中通过re模块实现了正则表达式的功能.re模块提供了一些根据正则表达式进行查找.替换.分隔字符串的函数.本文主要介绍正则表达式先关内容以及re模块中常用的函数和函数常用场景. 正则表达式基 ...
- Python正则表达式与hashlib模块
菜鸟学python第十六天 1.re模块(正则表达式) 什么是正则表达式 正则表达式是一个由特殊字符组成的序列,他能帮助对字符串的某种对应模式进行查找. 在python中,re 模块使其拥有全部的正则 ...
- python 正则表达式re使用模块(match()、search()和compile())
摘录 python核心编程 python的re模块允许多线程共享一个已编译的正则表达式对象,也支持命名子组.下表是常见的正则表达式属性: 函数/方法 描述 仅仅是re模块函数 compile(patt ...
- Python正则表达式与re模块
在线正则表达式测试 http://tool.oschina.net/regex/ 常见匹配模式 模式 描述 \w 匹配字母数字及下划线 \W 匹配非字母数字下划线 \s 匹配任意空白字符,等价于 [\ ...
- python 正则表达式与re模块
一.正则表达式 用途 用事先定义好的一些特定字符.及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑. #### 简单地说 就是用于字符串匹配的 字符组 在 ...
- Python 正则表达式、re模块
一.正则表达式 对字符串的操作的需求几乎无处不在,比如网站注册时输入的手机号.邮箱判断是否合法.虽然可以使用python中的字符串内置函数,但是操作起来非常麻烦,代码冗余不利于重复使用. 正则表达式是 ...
- [ python ] 正则表达式及re模块
正则表达式 正则表达式描述: 正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符.及这些特定字符的组合,组成一个‘规则字符串’,这个‘规则字符串’用来 表达对字符串的一种过滤 ...
随机推荐
- 消息中间件JMS(二)
之前介绍了ActiveMQ下载与安装,并且启动了.下面进行ActiveMQ的Demo 1. JMS入门Demo 1.1 点对点模式 点对点模式主要建立在一个队列上面,当连接一个队列的时候,发送端不需要 ...
- 课时59.体验css(理解)
我们想做这样一个样式,应该怎么做? 分析: 有一个标题(h1),还有一些段落(p) 标题是居中的,段落也是居中的,所以我们可以设置h标签和p标签居的align属性等于center来实现 标题和段落都有 ...
- oracle client安装与配置
(一)安装Oracle client 环境:windows7 64-bit.oracle client 64-bit (1)解压client安装包 (2)双击setup.exe,选择管理员,一直nex ...
- Mybatis中使用UpdateProvider注解实现根据主键批量更新
Mapper中这样写: @UpdateProvider(type = SjjcSqlProvider.class, method = "updateTaskStatusByCBh" ...
- LeetCode 简单 - 最大子序和(53)
采用动态规划方法O(n) 设sum[i]为以第i个元素结尾且和最大的连续子数组.假设对于元素i,所有以它前面的元素结尾的子数组的长度都已经求得,那么以第i个元素结尾且和最大的连续子数组实际上,要么是以 ...
- DISTINCT 去重仍有重复的分析
logger日志报错 插入数据时违反主键唯一约束 org.springframework.dao.DuplicateKeyException: ### Error updating database. ...
- conda 安装 graph-tool, 无需编译
1. 添加以下channels到~/.condarc $ conda config --add channels conda-forge $ conda config --add channels o ...
- 【nat---basic,napt,easy ip】
display nat :显示nat 信息 debugging nat :对nat进行调试 reset nat session:擦除nat连接配置 basic-nat:公网->私网(一对一) n ...
- Spring笔记1
Spring Spring特点 1. 方便解耦,简化开发 通过Spring提供的IoC容器,我们可以将对象之间的依赖关系交由Spring进行控制,避免硬编码所造成的过度程序耦合.有了Spring,用户 ...
- Java : 多态表现:静态绑定与动态绑定(向上转型的运行机制)
本来想自己写写的,但是看到有人分析的可以说是很清晰了,故转过来. 原文地址:http://www.cnblogs.com/ygj0930/p/6554103.html 一:绑定 把一个方法与其所在的类 ...