感知器(Perception)
感知器是一种早期的神经网络模型,由美国学者F.Rosenblatt于1957年提出.感知器中第一次引入了学习的概念,使人脑所具备的学习功能在基于符号处理的数学到了一定程度模拟,所以引起了广泛的关注。
简单感知器
简单感知器模型实际上仍然是MP模型的结构,但是它通过采用监督学习来逐步增强模式划分的能力,达到所谓学习的目的。
其结构如下图所示
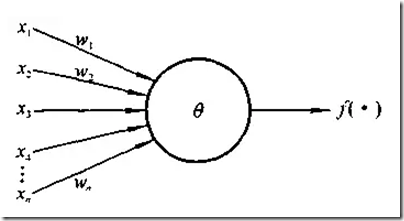
感知器处理单元对n个输入进行加权和操作v即:
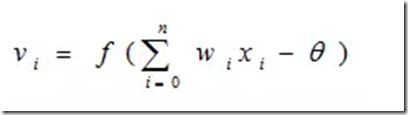
其中,Wi为第i个输入到处理单元的连接权值,f为阶跃函数。
感知器在形式上与MP模型差不多,它们之间的区别在于神经元间连接权的变化。感知器的连接权定义为可变的,这样感知器就被赋予了学习的特性。
利用简单感知器可以实现逻辑代数中的一些运算。
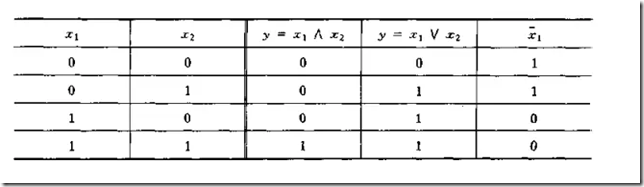
Y=f(w1x1+w2x2-θ)
(1)“与”运算。当取w1=w2=1,θ=1.5时,上式完成逻辑“与”的运算。
(2)“或”运算, 当取wl=w2=1,θ=0.5时,上式完成逻辑“或”的运算。
(3)“非”运算,当取wl=-1,w2=0,θ=-1时.完成逻辑“非”的运算。
与许多代数方程一样,上式中不等式具有一定的几何意义。
对于一个两输入的简单感知器,每个输入取值为0和1,如上面结出的逻辑运算,所有输入样本有四个,记为(x1,x2):(0,0),(0,1),(1,0),(1,1),构成了样本输入空间。例如,在二维平面上,对于“或”运算,各个样本的分布如下图所示。
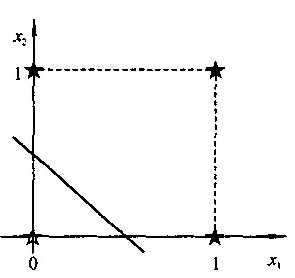
直线1*x1+1*x2-0.5=0将二维平面分为两部分,上部为激发区(y,=1,用★表示),下部为抑制区(y=0,用☆表示)。
简单感知器引入的学习算法称之为误差学习算法。该算法是神经网络学习中的一个重要算法,并已被广泛应用。
现介绍如下:
误差型学习规则:
(1)选择一组初始权值wi(0)。
(2)计算某一输入模式对应的实际输出y与期望输出d的误差δ
(3)如果δ小于给定值,结束,否则继续。
(4)更新权值(阈值可视为输入恒为1的一个权值): Δwi(t+1)=wi(t+1)- wi(t)=η[d—y(t)]xi。
式中η为在区间(0,1)上的一个常数,称为学习步长,它的取值与训练速度和w收敛的稳定性有关;d、y为神经元的期望输出和实际输出;xi为神经元的第i个输入。
(5)返回(2),重复,直到对所有训练样本模式,网络输出均能满足要求。
对于学习步长V的取值一般是在(0,1)上的一个常数,但是为了改进收敛速度,也可以采用变步长的方法,这里介绍一个算法如下式:
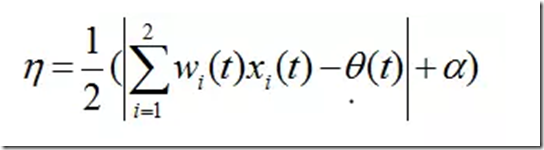
式中,α为一个正的常量。这里取值为0.1。
感知器对线性不可分问题的局限性决定了它只有较差的归纳性,而且通常需要较长的离线学习才能达到收效。
多层感知器
如果在输入和输出层间加上一层或多层的神经元(隐层神经元),就可构成多层前向网络,这里称为多层感知器。
这里需指出的是:多层感知器只允许调节一层的连接权。这是因为按感知器的概念,无法给出一个有效的多层感知器学习算法。
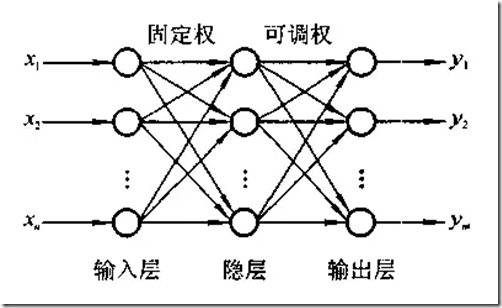
上述三层感知器中,有两层连接权,输入层与隐层单元间的权值是随机设置的固定值,不被调节;输出层与隐层间的连接权是可调节的。
对于上面述及的异或问题,用一个简单的三层感知器就可得到解决。
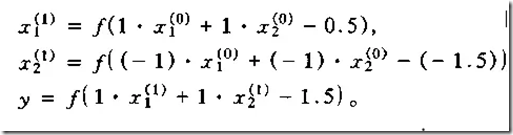
实际上,该三层感知器的输入层和隐层的连接,就是在模式空间中用两个超平面去划分样本,即用两条直线: x1+x2=0.5 x1十x 2=1.5。
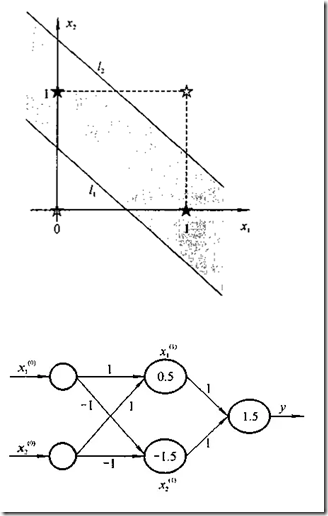
可以证明,只要隐层和隐层单元数足够多,多层感知器网络可实现任何模式分类。
但是,多层网络的权值如何确定,即网络如何进行学习,在感知器上没有得到解决:
当年Minsky等人就是因为对于非线性空间的多层感知器学习算法未能得到解决,
使其对神经网络的研究作出悲观的结论。
感知器收敛定理
对于一个N个输入的感知器,如果样本输入函数是线性可分的,那么对任意给定的一个输入
样本x,要么属于某一区域F+,要么不属于这一区域,记为F—。F+,F—两类样本构成了整个线性可分样本空间。
[定理] 如果样本输入函数是线性可分的,那么下面的感知器学习算法经过有限次迭代后,
可收敛到正确的权值或权向量。
假设样本空间F是单位长度样本输入向量的集合,若存在一个单位权向量w*。和一个较小的正数δ>0,
使得w*·x>= δ对所有的样本输入x都成立,则权向量w按下述学习过程仅需有限步就可收敛。
因此,感知器学习迭代次数是一有限数,经过有限次迭代,学习算法可收敛到正确的权向量w*。
对于上述证明,要说明的是:正数δ越小,迭代次数越多;
其次,若样本输入函数不是线性可分的,则学习过程将出现振荡,得不到正确的结果。
感知器与逻辑回归的区别
两者都为线性分类器,只能处理线性可分的数据。
两者的损失函数有所不同,PLA针对分错的数据进行建模,LR使用平方损失建模。
两者的优化方法可以统一为GD。
LR比PLA的优点之一在于对于激活函数的改进。
前者为sigmoid function,后者为step function。
LR使得最终结果有了概率解释的能力(将结果限制在0-1之间),sigmoid为平滑函数,能够得到更好的分类结果,而step function为分段函数,对于分类的结果处理比较粗糙,非0即1,而不是返回一个分类的概率。
感知机学习旨在求出将训练数据集进行线性划分的分类超平面,为此,导入了基于误分类的损失函数,然后利用梯度下降法对损失函数进行极小化,从而求出感知机模型。感知机模型是神经网络和支持向量机的基础。下面分别从感知机学习的模型、策略和算法三个方面来介绍。
1. 感知机模型
感知机模型如下:
f(x)= sign(w*x+b)
其中,x为输入向量,sign为符号函数,括号里面大于等于0,则其值为1,括号里面小于0,则其值为-1。w为权值向量,b为偏置。求感知机模型即求模型参数w和b。感知机预测,即通过学习得到的感知机模型,对于新的输入实例给出其对应的输出类别1或者-1。
2. 感知机策略
假设训练数据集是线性可分的,感知机学习的目标就是求得一个能够将训练数据集中正负实例完全分开的分类超平面,为了找到分类超平面,即确定感知机模型中的参数w和b,需要定义一个损失函数并通过将损失函数最小化来求w和b。
这里选择的损失函数是误分类点到分类超平面S的总距离。输入空间中任一点x0到超平面S的距离为:

其中,||w||为w的L2范数。
其次,对于误分类点来说,当-yi (wxi + b)>0时,yi=-1,当-yi(wxi + b)<0时,yi=+1。所以对误分类点(xi, yi)满足:
-yi (wxi +b) > 0
所以误分类点(xi, yi)到分类超平面S的距离是:

3. 感知机算法
感知机学习问题转化为求解损失函数式(1)的最优化问题,最优化的方法是随机梯度下降法。感知机学习算法是误分类驱动的,具体采用随机梯度下降法。首先,任意选取一个超平面w0,b0,然后用梯度下降法不断极小化目标函数式(1)。极小化的过程不是一次使M中所有误分类点的梯度下降,而是一次随机选取一个误分类点使其梯度下降。
损失函数L(w,b)的梯度是对w和b求偏导,即:

其中,(0<<=1)是学习率,即学习的步长。综上,感知机学习算法如下:

这种算法的基本思想是:当一个实例点被误分类,即位于分类超平面错误的一侧时,则调整w和b,使分类超平面向该误分类点的一侧移动,以减少该误分类点与超平面的距离,直到超平面越过该误分类点使其被正确分类为止。
需要注意的是,这种感知机学习算法得到的模型参数不是唯一的,它会由于采用不同的参数初始值或选取不同的误分类点,而导致解不同。为了得到唯一的分类超平面,需要对分类超平面增加约束条件,线性支持向量机就是这个想法。另外,当训练数据集线性不可分时,感知机学习算法不收敛,迭代结果会发生震荡。而对于线性可分的数据集,算法一定是收敛的,即经过有限次迭代,一定可以得到一个将数据集完全正确划分的分类超平面及感知机模型。
以上是感知机学习算法的原始形式,下面介绍感知机学习算法的对偶形式,对偶形式的基本想法是,将w和b表示为实例xi和标记yi的线性组合形式,通过求解其系数而求得w和b。对误分类点(xi, yi)通过

所以,感知机学习算法的对偶形式如下:

参考文献:
1.《统计学习方法》
2.http://blog.csdn.net/qll125596718/article/details/8394186
3.https://www.zhihu.com/question/64158565
感知器(Perception)的更多相关文章
- Python实现感知器的逻辑电路(与门、与非门、或门、异或门)
在神经网络入门回顾(感知器.多层感知器)中整理了关于感知器和多层感知器的理论,这里实现关于与门.与非门.或门.异或门的代码,以便对感知器有更好的感觉. 此外,我们使用 pytest 框架进行测试. p ...
- 4.2tensorflow多层感知器MLP识别手写数字最易懂实例代码
自己开发了一个股票智能分析软件,功能很强大,需要的点击下面的链接获取: https://www.cnblogs.com/bclshuai/p/11380657.html 1.1 多层感知器MLP(m ...
- 感知器、逻辑回归和SVM的求解
这篇文章将介绍感知器.逻辑回归的求解和SVM的部分求解,包含部分的证明.本文章涉及的一些基础知识,已经在<梯度下降.牛顿法和拉格朗日对偶性>中指出,而这里要解决的问题,来自<从感知器 ...
- 从感知器到SVM
这篇文章主要是分析感知器和SVM处理分类问题的原理,不涉及求解 感知器: 感知器要解决的是这样的一个二分类问题:给定了一个线性可分的数据集,我们需要找到一个超平面,将该数据集分开.这个超平面的描述如下 ...
- Stanford大学机器学习公开课(三):局部加权回归、最小二乘的概率解释、逻辑回归、感知器算法
(一)局部加权回归 通常情况下的线性拟合不能很好地预测所有的值,因为它容易导致欠拟合(under fitting).如下图的左图.而多项式拟合能拟合所有数据,但是在预测新样本的时候又会变得很糟糕,因为 ...
- 第三集 欠拟合与过拟合的概念、局部加权回归、logistic回归、感知器算法
课程大纲 欠拟合的概念(非正式):数据中某些非常明显的模式没有成功的被拟合出来.如图所示,更适合这组数据的应该是而不是一条直线. 过拟合的概念(非正式):算法拟合出的结果仅仅反映了所给的特定数据的特质 ...
- 设计一个简单的,低耗的能够区分红酒和白酒的感知器(sensor)
学习using weka in your javacode 主要学习两个部分的代码:1.过滤数据集 2 使用J48决策树进行分类.下面的例子没有对数据集进行分割,完全使用训练集作为测试集,所以不符合数 ...
- [置顶] 局部加权回归、最小二乘的概率解释、逻辑斯蒂回归、感知器算法——斯坦福ML公开课笔记3
转载请注明:http://blog.csdn.net/xinzhangyanxiang/article/details/9113681 最近在看Ng的机器学习公开课,Ng的讲法循循善诱,感觉提高了不少 ...
- 【中文分词】结构化感知器SP
结构化感知器(Structured Perceptron, SP)是由Collins [1]在EMNLP'02上提出来的,用于解决序列标注的问题:中文分词工具THULAC.LTP所采用的理论模型便是基 ...
随机推荐
- nginx的buffered to a temporary警告
nginx日志报a client request body is buffered to a temporary file 这个意思是客户全请求的文件超过了nginx的缓存区大小,nginx将内容写入 ...
- Android控件常见属性
1.宽/高android:layout_width android:layout_height// 取值match_parent //匹配父控件wrap_content //自适应,根据内容 如果指定 ...
- 【Excle】在重复数据中对日期排序并查询最新的一条记录
现在存在以下数据: 需要查询出以下数据 姓名 日期 张三 2017-12-14 李四 2017-12-16 在E1中写入以下公式:=IF(D2=MAX(IF($C$ ...
- EFCore & Mysql migration on Production
最好的办法是通过脚本进行生产环境数据库更新. 如: dotnet ef migration script -i -o "script.sql". 这样将会产生一个你不用在意线上版本 ...
- MySQL:习题(单表多条件查询二)
Sutdent表的定义 字段名 字段描述 数据类型 主键 外键 非空 唯一 自增 Id 学号 INT(10) 是 否 是 是 是 Name 姓名 VARCHAR(20) 否 否 是 否 否 Sex 性 ...
- Android开发和Android Studio使用教程
Android studio安装和简单介绍http://www.jianshu.com/p/36cfa1614d23 是时候把Android 项目切换到Android Studio http://ww ...
- 看完这篇还不会 GestureDetector 手势检测,我跪搓衣板!
引言 在 android 开发过程中,我们经常需要对一些手势,如:单击.双击.长按.滑动.缩放等,进行监测.这时也就引出了手势监测的概念,所谓的手势监测,说白了就是对于 GestureDetector ...
- centos中git使用
先用root用户登录, yum install git 进行安装,然后退出用普通用户登录. ssh-keygen -t rsa -C "tuhooo@163.com" 登录GitH ...
- myeclipse配置问题
一,配置相关 1,myeclipse配置jdk Window --> Preferences --> Java --> Installed JREs 2.myeclipse配置tom ...
- (总结)RHEL/CentOS 7.x的几点新改变
一.CentOS的Services使用了systemd来代替sysvinit管理 1.systemd的服务管理程序: systemctl是主要的工具,它融合之前service和chkconfig的功能 ...