HBase 二级索引与Coprocessor协处理器
Coprocessor简介
(1)实现目的
- HBase无法轻易建立“二级索引”;
- 执行求和、计数、排序等操作比较困难,必须通过MapReduce/Spark实现,对于简单的统计或聚合计算时,可能会因为网络与IO开销大而带来性能问题。
(2)灵感来源
灵感来源于Bigtable的协处理器,包含如下特性:
- 每个表服务器的任意子表都可以运行代码;
- 客户端能够直接访问数据表的行,多行读写会自动分片成多个并行的RPC调用。
(3)提供接口
- RegionObserver:提供客户端的数据操纵事件钩子:Get、Put、Delete、Scan等;
- WALObserver:提供WAL相关操作钩子;
- MasterObserver:提供DDL-类型的操作钩子。如创建、删除、修改数据表等;
- Endpoint:终端是动态RPC插件的接口,它的实现代码被安装在服务器端,能够通过HBase RPC调用唤醒。
(4)应用范围
- 通过使用RegionObserver接口可以实现二级索引的创建和维护;
- 通过使用Endpoint接口,在对数据进行简单排序和sum,count等统计操作时,能够极大提高性能。
Endpoint服务端实现
在传统关系型数据库里面,可以随时的对某列进行求和sum,但是目前HBase目前所提供的接口,直接求和是比较困难的,所以先编写好服务端代码,并加载到对应的Table上,加载协处理器有几种方法,可以通过HTableDescriptor的addCoprocessor方法直接加载,同理也可以通过removeCoprocessor方法卸载协处理器。
Endpoint协处理器类似传统数据库的存储过程,客户端调用Endpoint协处理器执行一段Server端代码,并将Server端代码的结果返回给Client进一步处理,最常见的用法就是进行聚合操作。举个例子说明:如果没有协处理器,当用户需要找出一张表中的最大数据即max聚合操作,必须进行全表扫描,客户端代码遍历扫描结果并执行求max操作,这样的方法无法利用底层集群的并发能力,而将所有计算都集中到Client端统一执行, 效率非常低。但是使用Coprocessor,用户将求max的代码部署到HBase Server端,HBase将利用底层Cluster的多个节点并行执行求max的操作即在每个Region范围内执行求最大值逻辑,将每个Region的最大值在Region Server端计算出,仅仅将该max值返回给客户端。客户端进一步将多个Region的max进一步处理而找到其中的max,这样整体执行效率提高很多。但是一定要注意的是Coprocessor一定要写正确,否则导致RegionServer宕机。
Protobuf定义
如前所述,客户端和服务端之间需要进行RPC通信,所以两者间需要确定接口,当前版本的HBase的协处理器是通过Google Protobuf协议来实现数据交换的,所以需要通过Protobuf来定义接口。
如下所示:
option java_package = "com.my.hbase.protobuf.generated";
option java_outer_classname = "AggregateProtos";
option java_generic_services = true;
option java_generate_equals_and_hash = true;
option optimize_for = SPEED; import "Client.proto"; message AggregateRequest {
required string interpreter_class_name = 1;
required Scan scan = 2;
optional bytes interpreter_specific_bytes = 3;
} message AggregateResponse {
repeated bytes first_part = 1;
optional bytes second_part = 2;
} service AggregateService {
rpc GetMax (AggregateRequest) returns (AggregateResponse);
rpc GetMin (AggregateRequest) returns (AggregateResponse);
rpc GetSum (AggregateRequest) returns (AggregateResponse);
rpc GetRowNum (AggregateRequest) returns (AggregateResponse);
rpc GetAvg (AggregateRequest) returns (AggregateResponse);
rpc GetStd (AggregateRequest) returns (AggregateResponse);
rpc GetMedian (AggregateRequest) returns (AggregateResponse);
}
可以看到这里定义7个聚合服务RPC,名字分别叫做GetMax、GetMin、GetSum等,本文通过GetSum进行举例,其他的聚合RPC也是类似的内部实现。RPC有一个入口参数,用消息AggregateRequest表示;RPC的返回值用消息AggregateResponse表示。Service是一个抽象概念,RPC的Server端可以看作一个用来提供服务的Service。在HBase Coprocessor中Service就是Server端需要提供的Endpoint Coprocessor服务,主要用来给HBase的Client提供服务。AggregateService.java是由Protobuf软件通过终端命令“protoc filename.proto--java_out=OUT_DIR”自动生成的,其作用是将.proto文件定义的消息结构以及服务转换成对应接口的RPC实现,其中包括如何构建request消息和response响应以及消息包含的内容的处理方式,并且将AggregateService包装成一个抽象类,具体的服务以类的方法的形式提供。AggregateService.java定义Client端与Server端通信的协议,代码中包含请求信息结构AggregateRequest、响应信息结构AggregateResponse、提供的服务种类AggregateService,其中AggregateRequest中的interpreter_class_name指的是column interpreter的类名,此类的作用在于将数据格式从存储类型解析成所需类型。
服务端的架构
首先,Endpoint Coprocessor是一个Protobuf Service的实现,因此需要它必须继承某个ProtobufService。我们在前面已经通过proto文件定义Service,命名为AggregateService,因此Server端代码需要重载该类,其次作为HBase的协处理器,Endpoint 还必须实现HBase定义的协处理器协议,用Java的接口来定义。具体来说就是CoprocessorService和Coprocessor,这些HBase接口负责将协处理器和HBase 的RegionServer等实例联系起来以便协同工作。Coprocessor接口定义两个接口函数:start和stop。
加载Coprocessor之后Region打开的时候被RegionServer自动加载,并会调用器start 接口完成初始化工作。一般情况该接口函数仅仅需要将协处理器的运行上下文环境变量CoprocessorEnvironment保存到本地即可。
CoprocessorEnvironment保存协处理器的运行环境,每个协处理器都是在一个RegionServer进程内运行并隶属于某个Region。通过该变量获取Region的实例等 HBase运行时环境对象。
Coprocessor接口还定义stop()接口函数,该函数在Region被关闭时调用,用来进行协处理器的清理工作。本文里我们没有进行任何清理工作,因此该函数什么也不干。
我们的协处理器还需要实现CoprocessorService接口。该接口仅仅定义一个接口函数 getService()。我们仅需要将本实例返回即可。HBase的Region Server在接收到客户端的调用请求时,将调用该接口获取实现RPCService的实例,因此本函数一般情况下就是返回自身实例即可。
完成以上三个接口函数之后,Endpoint的框架代码就已完成。每个Endpoint协处理器都必须实现这些框架代码而且写法雷同。
Server端的代码就是一个Protobuf RPC的Service实现,即通过Protobuf提供的某种服务。其开发内容主要包括:
- 实现Coprocessor的基本框架代码
- 实现服务的RPC具体代码
Endpoint 协处理的基本框架
Endpoint 是一个Server端Service的具体实现,其实现有一些框架代码,这些框架代码与具体的业务需求逻辑无关。仅仅是为了和HBase运行时环境协同工作而必须遵循和完成的一些粘合代码。因此多数情况下仅仅需要从一个例子程序拷贝过来并进行命名修改即可。不过我们还是完整地对这些粘合代码进行粗略的讲解以便更好地理解代码。
public Service getService() {
return this;
}
public void start(CoprocessorEnvironment env) throws IOException {
if(env instanceof RegionCoprocessorEnvironment) {
this.env = (RegionCoprocessorEnvironment)env;
} else {
throw new CoprocessorException("Must be loaded on a table region!");
}
}
public void stop(CoprocessorEnvironment env) throws IOException {
}
Endpoint协处理器真正的业务代码都在每一个RPC函数的具体实现中。
在本文中,我们的Endpoint协处理器仅提供一个RPC函数即getSUM。我将分别介绍编写该函数的几个主要工作:了解函数的定义,参数列表;处理入口参数;实现业务逻辑;设置返回参数。
public void getSum(RpcController controller, AggregateRequest request, RpcCallbackdone) {
AggregateResponse response = null;
RegionScanner scanner = null;
long sum = 0L;
try {
ColumnInterpreter ignored = this.constructColumnInterpreterFromRequest(request);
Object sumVal = null;
Scan scan = ProtobufUtil.toScan(request.getScan());
scanner = this.env.getRegion().getScanner(scan);
byte[] colFamily = scan.getFamilies()[0];
NavigableSet qualifiers = (NavigableSet) scan.getFamilyMap().get(colFamily);
byte[] qualifier = null;
if (qualifiers != null && !qualifiers.isEmpty()) {
qualifier = (byte[]) qualifiers.pollFirst();
}
ArrayList results = new ArrayList();
boolean hasMoreRows = false;
do {
hasMoreRows = scanner.next(results);
int listSize = results.size();
for (int i = 0; i < listSize; ++i) {
//取出列值
Object temp = ignored.getValue(colFamily, qualifier,
(Cell) results.get(i));
if (temp != null) {
sumVal = ignored.add(sumVal, ignored.castToReturnType(temp));
}
}
results.clear();
} while (hasMoreRows);
if (sumVal != null) {
response = AggregateResponse.newBuilder().addFirstPart(
ignored.getProtoForPromotedType(sumVal).toByteString()).build();
}
} catch (IOException var27) {
ResponseConverter.setControllerException(controller, var27);
} finally {
if (scanner != null) {
try {
scanner.close();
} catch (IOException var26) {
;
}
}
}
log.debug("Sum from this region is " +
this.env.getRegion().getRegionInfo().getRegionNameAsString() + ": " + sum);
done.run(response);
}
Endpoint类比于数据库的存储过程,其触发服务端的基于Region的同步运行再将各个结果在客户端搜集后归并计算。特点类似于传统的MapReduce框架,服务端Map客户端Reduce。
Endpoint客户端实现
HBase提供客户端Java包org.apache.hadoop.hbase.client.HTable,提供以下三种方法来调用协处理器提供的服务:
- coprocessorService(byte[])
- coprocessorService(Class, byte[], byte[],Batch.Call),
- coprocessorService(Class, byte[], byte[],Batch.Call, Batch.Callback)
该方法采用rowkey指定Region。这是因为HBase客户端很少会直接操作Region,一般不需要知道Region的名字;况且在HBase中Region名会随时改变,所以用rowkey来指定Region是最合理的方式。使用rowkey可以指定唯一的一个Region,如果给定的Rowkey并不存在,只要在某个Region的rowkey范围内依然用来指定该Region。比如Region 1处理[row1, row100]这个区间内的数据,则rowkey=row1就由Region 1来负责处理,换句话说我们可以用row1来指定Region 1,无论rowkey等于”row1”的记录是否存在。CoprocessorService方法返回类型为CoprocessorRpcChannel的对象,该 RPC通道连接到由rowkey指定的Region上面,通过此通道可以调用该Region上面部署的协处理器RPC。
有时候客户端需要调用多个 Region上的同一个协处理器,比如需要统计整个Table的sum,在这种情况下,需要所有的Region都参与进来,分别统计自身Region内部的sum并返回客户端,最终客户端将所有Region的返回结果汇总,就可以得到整张表的sum。
这意味着该客户端同时和多个Region进行批处理交互。一个可行的方法是,收集每个 Region的startkey,然后循环调用第一种coprocessorService方法:用每一个Region的startkey 作为入口参数,获得RPC通道创建stub对象,进而逐一调用每个Region上的协处理器RPC。这种做法需要写很多的代码,为此HBase提供两种更加简单的 coprocessorService方法来处理多个Region的协处理器调用。先来看第一种方法 coprocessorService(Class, byte[],byte[],Batch.Call)
该方法有 4 个入口参数。第一个参数是实现RPC的Service 类,即前文中的AggregateService类。通过它,HBase就可以找到相应的部署在Region上的协处理器,一个Region上可以部署多个协处理器,客户端必须通过指定Service类来区分究竟需要调用哪个协处理器提供的服务。
要调用哪些Region上的服务则由startkey和endkey来确定,通过 rowkey范围即可确定多个 Region。为此,coprocessorService方法的第二个和第三个参数分别是 startkey和endkey,凡是落在[startkey,endkey]区间内的Region都会参与本次调用。
第四个参数是接口类Batch.Call。它定义了如何调用协处理器,用户通过重载该接口的call()方法来实现客户端的逻辑。在call()方法内,可以调用RPC,并对返回值进行任意处理。即前文代码清单1中所做的事情。coprocessorService将负责对每个 Region调用这个call()方法。
coprocessorService方法的返回值是一个Map类型的集合。该集合的key是Region名字,value是Batch.Call.call方法的返回值。该集合可以看作是所有Region的协处理器 RPC 返回的结果集。客户端代码可以遍历该集合对所有的结果进行汇总处理。
这种coprocessorService方法的大体工作流程如下。首先它分析startkey和 endkey,找到该区间内的所有Region,假设存放在regionList中。然后,遍历regionList,为每一个Region调用Batch.Call,在该接口内,用户定义具体的RPC调用逻辑。最后coprocessorService将所有Batch.Call.call()的返回值加入结果集合并返回。
coprocessorService的第三种方法比第二个方法多了一个参数callback。coprocessorService第二个方法内部使用HBase自带的缺省callback,该缺省 callback将每个Region的返回结果都添加到一个Map类型的结果集中,并将该集合作为coprocessorService方法的返回值。
HBase 提供第三种coprocessorService方法允许用户定义callback行为,coprocessorService 会为每一个RPC返回结果调用该callback,用户可以在callback 中执行需要的逻辑,比如执行sum累加。用第二种方法的情况下,每个Region协处理器RPC的返回结果先放入一个列表,所有的 Region 都返回后,用户代码再从该列表中取出每一个结果进行累加;用第三种方法,直接在callback中进行累加,省掉了创建结果集合和遍历该集合的开销,效率会更高一些。
因此我们只需要额外定义一个callback即可,callback是一个Batch.Callback接口类,用户需要重载其update方法。
public S sum(final HTable table, final ColumnInterpreter<R, S, P, Q, T> ci,final Scan scan)throws Throwable {
final AggregateRequest requestArg = validateArgAndGetPB(scan, ci, false);
class SumCallBack implements Batch.Callback {
S sumVal = null;
public S getSumResult() {
return sumVal;
}
@Override
public synchronized void update(byte[] region, byte[] row, S result) {
sumVal = ci.add(sumVal, result);
}}
SumCallBack sumCallBack = new SumCallBack();
table.coprocessorService(AggregateService.class, scan.getStartRow(), scan.getStopRow(),
new Batch.Call<AggregateService, S>() {
@Override
public S call(AggregateService instance) throws IOException {
ServerRpcController controller = new ServerRpcController();
BlockingRpcCallback<AggregateResponse> rpcCallback =
new BlockingRpcCallback<AggregateResponse>();
//RPC 调用
instance.getSum(controller, requestArg, rpcCallback);
AggregateResponse response = rpcCallback.get();
if (controller.failedOnException()) {
throw controller.getFailedOn();
}
if (response.getFirstPartCount() == 0) {
return null;
}
ByteString b = response.getFirstPart(0);
T t = ProtobufUtil.getParsedGenericInstance(ci.getClass(), 4, b);
S s = ci.getPromotedValueFromProto(t);
return s;
}
}, sumCallBack);
return sumCallBack.getSumResult();
Observer实现二级索引
Observer类似于传统数据库中的触发器,当发生某些事件的时候这类协处理器会被 Server 端调用。Observer Coprocessor是一些散布在HBase Server端代码的 hook钩子, 在固定的事件发生时被调用。比如:put操作之前有钩子函数prePut,该函数在pu 操作执 行前会被Region Server调用;在put操作之后则有postPut 钩子函数。
RegionObserver工作原理
RegionObserver提供客户端的数据操纵事件钩子,Get、Put、Delete、Scan,使用此功能能够解决主表以及多个索引表之间数据一致性的问题
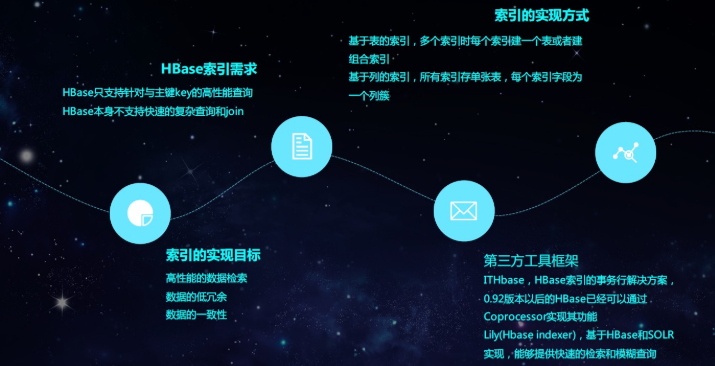
- 客户端发出put请求;
- 该请求被分派给合适的RegionServer和Region;
- coprocessorHost拦截该请求,然后在该表上登记的每个 RegionObserver 上调用prePut();
- 如果没有被preGet()拦截,该请求继续送到 region,然后进行处理;
- Region产生的结果再次被CoprocessorHost拦截,调用postGet();
- 假如没有postGet()拦截该响应,最终结果被返回给客户端;

如上图所示,HBase可以根据rowkey很快的检索到数据,但是如果根据column检索数据,首先要根据rowkey减小范围,再通过列过滤器去过滤出数据,如果使用二级索引,可以先查基于column的索引表,获取到rowkey后再快速的检索到数据。
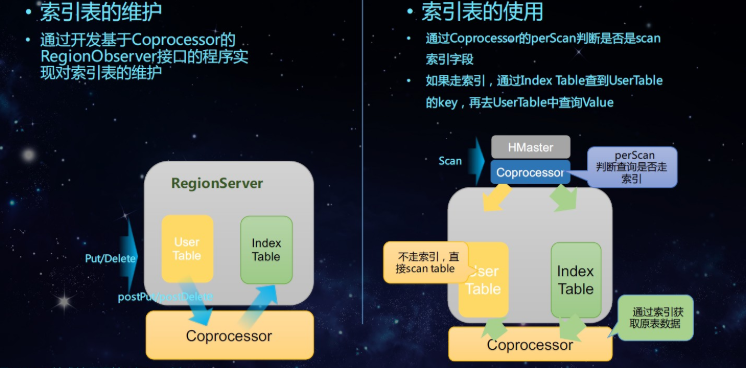
如图所示首先继承BaseRegionObserver类,重写postPut,postDelete方法,在postPut方法体内中写Put索引表数据的代码,在postDelete方法里面写Delete索引表数据,这样可以保持数据的一致性。
在Scan表的时候首先判断是否先查索引表,如果不查索引直接scan主表,如果走索引表通过索引表获取主表的rowkey再去查主表。
使用Elastic Search建立二级索引也是一样。
我们在同一个主机集群上同时建立了HBase集群和Elastic Search集群,存储到HBase的数据必须实时地同步到Elastic Search。而恰好HBase和Elastic Search都没有更新的概念,我们的需求可以简化为两步:
- 当一个新的Put操作产生时,将Put数据转化为json,索引到ElasticSearch,并把RowKey作为新文档的ID;
- 当一个新的Delete操作产生时获取Delete数据的rowkey删除Elastic Search中对应的ID。
协处理的主要应用场景
- Observer允许集群在正常的客户端操作过程中可以有不同的行为表现;
- Endpoint允许扩展集群的能力,对客户端应用开放新的运算命令;
- Observer类似于RDBMS的触发器,主要在服务端工作;
- Endpoint类似于RDBMS的存储过程,主要在服务端工作;
- Observer可以实现权限管理、优先级设置、监控、ddl控制、二级索引等功能;
- Endpoint可以实现min、max、avg、sum、distinct、group by等功能。
HBase 二级索引与Coprocessor协处理器的更多相关文章
- HBase二级索引、读写流程
HBase二级索引.读写流程 一.HBse二级索引方案 1.1 基于Coprocessor方案 1.2 Phoenix二级索引特点 1.3 Phoenix 二级索引方案 二.HBase读写流程 2.1 ...
- HBase二级索引方案总结
转自:http://blog.sina.com.cn/s/blog_4a1f59bf01018apd.html 附hbase如何创建二级索引以及创建二级索引实例:http://www.aboutyun ...
- HBase二级索引的设计(案例讲解)
摘要 最近做的一个项目涉及到了多条件的组合查询,数据存储用的是HBase,恰恰HBase对于这种场景的查询特别不给力,一般HBase的查询都是通过RowKey(要把多条件组合查询的字段都拼接在RowK ...
- hbase 二级索引创建
在单机上运行hbase 二级索引: import java.io.IOException; import java.util.HashMap; import java.util.Map; import ...
- HBase二级索引的设计
摘要 最近做的一个项目涉及到了多条件的组合查询,数据存储用的是HBase,恰恰HBase对于这种场景的查询特别不给力,一般HBase的查询都是通过RowKey(要把多条件组合查询的字段都拼接在RowK ...
- HBase之八--(1):HBase二级索引的设计(案例讲解)
摘要 最近做的一个项目涉及到了多条件的组合查询,数据存储用的是HBase,恰恰HBase对于这种场景的查询特别不给力,一般HBase的查询都是通过RowKey(要把多条件组合查询的字段都拼接在RowK ...
- HBase 二级索引与Join
二级索引与索引Join是Online业务系统要求存储引擎提供的基本特性.RDBMS支持得比较好,NOSQL阵营也在摸索着符合自身特点的最佳解决方案. 这篇文章会以HBase做为对象来探讨如何基于Hba ...
- HBase二级索引与Join
转自:http://www.oschina.net/question/12_32573 二级索引与索引Join是Online业务系统要求存储引擎提供的基本特性.RDBMS支持得比较好,NOSQL阵营也 ...
- HBase + Solr Cloud实现HBase二级索引
1. 执行流程 2. Solr Cloud实现 http://blog.csdn.net/u011462328/article/details/53008344 3. HBase实现 1) 自定义Ob ...
随机推荐
- memset使用
void memset(void s, int ch, size_t n); 函数解释:将s中当前位置后面的n个字节 (typedef unsigned int size_t )用 ch 替换并返回 ...
- gsub! 和 gsub
ruby中带“!"和不带"!"的方法的最大的区别就是带”!"的会改变调用对象本身了.比方说str.gsub(/a/, 'b'),不会改变str本身,只会返回一个 ...
- HackerRank - angry-children 【排序】
题意 求一个序列当中 其 长度为 K 的子序列 中的 最大值 - 最小值 求 这个值 最小是多少 思路 先将序列排序 然后 I = 0, J = K - 1 然后 往下遍历 如果 arr[j] - a ...
- Oracle数据库体系结构(3)数据库进程
一.Oracle进程概述 在oracle中进程分为用户进程(User Process).服务器进程(server process)和后天进程3种. 1.用户进程:当用户连接到数据库执行一个应用程序是, ...
- c的详细学习(7)指针学习(一)
指针是c语言的一个重要概念,指针类型是c语言最有特色的数据类型: *利用指针编写的程序可使调用函数共享变量或数据结构,实现双向数据通信: *可以实现内存空间的动态存储分配:可以提高程序的编译效率和执行 ...
- P4844 LJJ爱数数
题目 P4844 LJJ爱数数 本想找到莫比乌斯反演水题练练,结果直接用了两个多小时才做完 做法 \(\sum\limits_{a=1}^n\sum\limits_{b=1}^n\sum\limits ...
- RabbitMQ之Exchange Direct模式
场景: 生产者发送消息到交换机并指定一个路由key, 消费者队列绑定到交换机时要指定路由key(key匹配就能接受消息,key不匹配就不能接受消息) 例如:我们可以把路由key设置为insert ,那 ...
- sql的执行过程
from ===> where ===> group by ===> select ===>order by 这个执行流程 很重要~~
- 织梦dedecms 调用文章图片数功能
function BodyImgNum($aid) { global $dsql; $sql = "select aid,body from dede_addonarticle where ...
- Qt之界面实现技巧-- 窗体显示,绘制背景,圆角,QSS样式
转自 --> http://blog.sina.com.cn/s/blog_a6fb6cc90101dech.html 总结一下,在开发Qt的过程中的一些技巧!可遇而不可求... 一.主界面 1 ...