scrapy--json(360美图)
之前开始学习scrapy,接触了AJax异步加载。一直没放到自己博客,趁现在不忙,也准备为下一个爬虫做知识储存,就分享给大家。
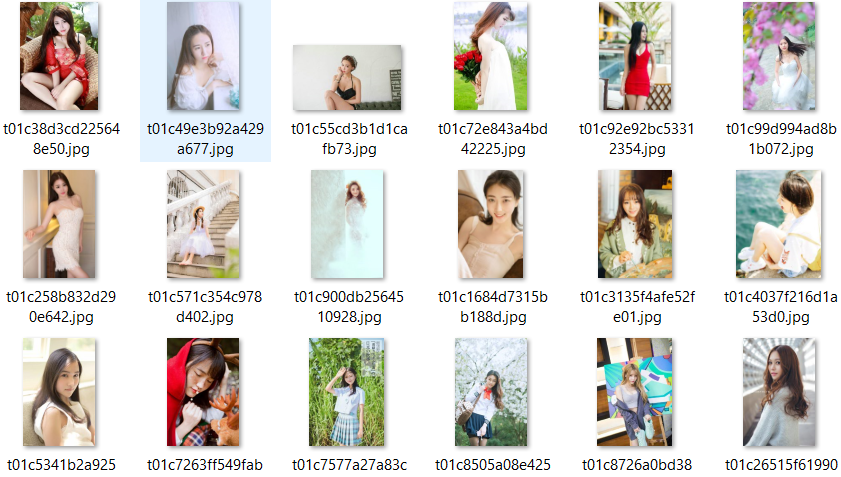
还是从爬取图片开始,先上图给大家看看成果,QAQ。
一、图片加载的方法
1.1:网页源码__javascript加载数据
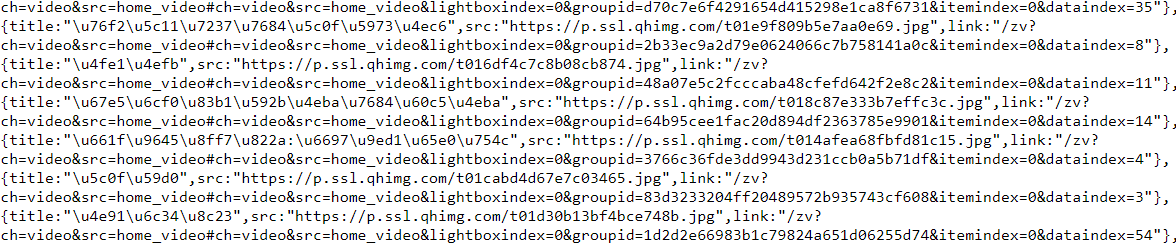
1.2:F12审查元素:滑动滑块,图片开始不断加载,
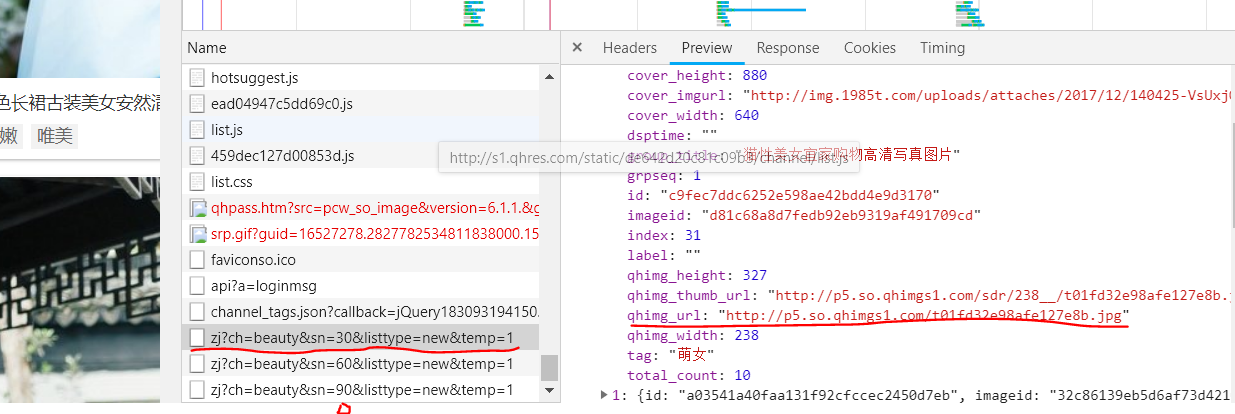
1.3:json数据:"http://image.so.com/zj?ch=beauty&sn=30&listtype=new&temp=1"

图片的URL储存在["list"]["qhimg_url"]
二、实现代码image.py.items.py,middlewares.py,settings.py,pipelines.py在我之前博客中能找到,在这里就不展示了,也可以进我的github:
# -*- coding: utf-8 -*-
import scrapy
from Tupian360.items import Tupian360Item
import json
import pdb
from Tupian360.settings import USER_AGENT
import random class ImageSpider(scrapy.Spider):
name = 'image'
allowed_domains = ['image.so.com']
pager_count = 0 headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Length': '',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Host': 'image.so.com',
'Origin': 'image.so.com',
'Referer': 'http://image.so.com/zj?ch=beauty&sn=%s&listtype=new&temp=1'%pager_count,
'User-Agent': USER_AGENT,
'X-Requested-With': 'XMLHttpRequest',
} old_urls = 'http://image.so.com/zj?ch=beauty&sn=%s&listtype=new&temp=1'
start_urls = [old_urls%pager_count] def parse(self, response):
tupian = Tupian360Item()
sel = json.loads(response.body.decode('utf8'))
counts = sel['count']
self.pager_count += int(counts)
new_url = self.old_urls%self.pager_count
for link in sel['list']:
tupian['image_urls'] = link['qhimg_url']
yield tupian yield scrapy.Request(new_url,callback=self.parse)
scrapy--json(360美图)的更多相关文章
- 分析AJAX抓取今日头条的街拍美图并把信息存入mongodb中
今天学习分析ajax 请求,现把学得记录, 把我们在今日头条搜索街拍美图的时候,今日头条会发起ajax请求去请求图片,所以我们在网页源码中不能找到图片的url,但是今日头条网页中有一个json 文件, ...
- thinkphp + 美图秀秀api 实现图片裁切上传,带数据库
思路: 1.数据库 创建test2 创建表img,字段id,url,addtime 2.前台页: 1>我用的是bootstrap 引入必要的js,css 2>引入美图秀秀的js 3.后台: ...
- 分析ajax请求抓取今日头条关键字美图
# 目标:抓取今日头条关键字美图 # 思路: # 一.分析目标站点 # 二.构造ajax请求,用requests请求到索引页的内容,正则+BeautifulSoup得到索引url # 三.对索引url ...
- 15-分析Ajax请求并抓取今日头条街拍美图
流程框架: 抓取索引页内容:利用requests请求目标站点,得到索引网页HTML代码,返回结果. 抓取详情页内容:解析返回结果,得到详情页的链接,并进一步抓取详情页的信息. 下载图片与保存数据库:将 ...
- python爬虫之分析Ajax请求抓取抓取今日头条街拍美图(七)
python爬虫之分析Ajax请求抓取抓取今日头条街拍美图 一.分析网站 1.进入浏览器,搜索今日头条,在搜索栏搜索街拍,然后选择图集这一栏. 2.按F12打开开发者工具,刷新网页,这时网页回弹到综合 ...
- 分析Ajax请求并抓取今日头条街拍美图
项目说明 本项目以今日头条为例,通过分析Ajax请求来抓取网页数据. 有些网页请求得到的HTML代码里面并没有我们在浏览器中看到的内容.这是因为这些信息是通过Ajax加载并且通过JavaScript渲 ...
- 美图DPOS以太坊教程(Docker版)
一.前言 最近,需要接触区块链项目的主链开发,在EOS.BTC.ethereum.超级账本这几种区块链技术当中,相互对比后,最终还是以go-ethereum为解决方案. 以ethereum为基准去找解 ...
- Python Spider 抓取今日头条街拍美图
""" 抓取今日头条街拍美图 """ import os import time import requests from hashlib ...
- 小幻美图 API
『不忘初心,方得始终.』 小幻美图 API 更新:2015.03.29 目前提供的API共有10种! 必应各种今日获取API共4种! 本站收录图片获取API共4种! 网络图片尺寸修改API共1枚! 百 ...
随机推荐
- textarea输入框显隐文字
html: <textarea class="dxtd_text"></textarea> javascript: //管理端短信 var textarea ...
- 树莓派直连线连接PC
刚入手树莓派一天不到,SSH树莓派一直用的是路由+无线网卡的配置.想到明天就要出差了,本想把树莓派也带去,可宾馆的房间只有一个网口,通常都是兄弟们连接小型无线路由用的,连接树莓派似乎成了一个难题.于是 ...
- iOS中MD5加密字符串实现
1.MD5加密 Message Digest Algorithm MD5(中文名为消息摘要算法第五版)为计算机安全领域广泛使用的一种散列函数,用以提供消息的完整性保护.该算法的文件号为RFC 1321 ...
- Android 设置软键盘搜索键以及监听搜索键点击事件
如图所示,有时候为了布局美观,在搜索时没有搜索按钮,而是调用软件盘上的按钮.调用的实现只需要在XML在输入框中加入android:imeOptions="actionSearch" ...
- react-native —— 在Mac上搭建React Native Android开发环境
需要:JDK,Android SDK,Node.js 1.安装JDK 去Java官网下载列表选择Mac OS X x64版 2.安装Android SDK 虽然现在谷歌推荐使用Android ...
- 【MATLAB】对离散采样信号添加高斯白噪声(已知Eb/N0)
(1)首先计算已知信号序列(采样之后得到的信号)的平均功率.该序列在第n个点处的功率为: 如果已知的信号序列中的总共的点数为N个,则该序列的平均功率为: 在MATLAB中求平均功率的方法是: Pav= ...
- azkaban调度
azkaban调度 1.概述 azkaban是一套调度系统,常用大数据作业调度.azkaban包括web和executor两套程序,web主要完成展示和交互,executor上完成调度和作业提交执行. ...
- April 14 2017 Week 15 Friday
Try to be a rainbow in someone's cloud. 当乌云萦绕心头,我愿意成为你的彩虹. Actually there are many rainbows in our l ...
- MySQL入门很简单: 6 视图
1. 视图含义作用 视图是虚拟的表,是从数据率中一个或多个表中导出来的表: 数据库中只存放了视图的定义,没有存放视图中的数据,数据在原先的表中: 一旦表中的数据发生变化,显示在视图中的数据也会发生 ...
- selenium安装及官方文档
selenium-python官方文档: https://selenium-python.readthedocs.io/ python3.5已安装的情况下,安装示意图如下 命令行输入 pip3 ins ...