sklearn中常用数据预处理方法
1. 标准化(Standardization or Mean Removal and Variance Scaling)
变换后各维特征有0均值,单位方差。也叫z-score规范化(零均值规范化)。计算方式是将特征值减去均值,除以标准差。
sklearn.preprocessing.scale(X)
一般会把train和test集放在一起做标准化,或者在train集上做标准化后,用同样的标准化器去标准化test集,此时可以用scaler
scaler = sklearn.preprocessing.StandardScaler().fit(train)
scaler.transform(train)
scaler.transform(test)
实际应用中,需要做特征标准化的常见情景:SVM
2. 最小-最大规范化
最小-最大规范化对原始数据进行线性变换,变换到[0,1]区间(也可以是其他固定最小最大值的区间)
min_max_scaler = sklearn.preprocessing.MinMaxScaler()
min_max_scaler.fit_transform(X_train)
3.规范化(Normalization)
规范化是将不同变化范围的值映射到相同的固定范围,常见的是[0,1],此时也称为归一化。《机器学习》周志华
将每个样本变换成unit norm。
X = [[ 1, -1, 2],[ 2, 0, 0], [ 0, 1, -1]]
sklearn.preprocessing.normalize(X, norm='l2')
得到
array([[ 0.40, -0.40, 0.81], [ 1, 0, 0], [ 0, 0.70, -0.70]])
可以发现对于每一个样本都有,0.4^2+0.4^2+0.81^2=1,这就是L2 norm,变换后每个样本的各维特征的平方和为1。类似地,L1 norm则是变换后每个样本的各维特征的绝对值和为1。还有max norm,则是将每个样本的各维特征除以该样本各维特征的最大值。
在度量样本之间相似性时,如果使用的是二次型kernel,需要做Normalization
4. 特征二值化(Binarization)
给定阈值,将特征转换为0/1
binarizer = sklearn.preprocessing.Binarizer(threshold=1.1)
binarizer.transform(X)
5. 标签二值化(Label binarization)
lb = sklearn.preprocessing.LabelBinarizer()
6. 类别特征编码
有时候特征是类别型的,而一些算法的输入必须是数值型,此时需要对其编码。
enc = preprocessing.OneHotEncoder()
enc.fit([[0, 0, 3], [1, 1, 0], [0, 2, 1], [1, 0, 2]])
enc.transform([[0, 1, 3]]).toarray() #array([[ 1., 0., 0., 1., 0., 0., 0., 0., 1.]])
上面这个例子,第一维特征有两种值0和1,用两位去编码。第二维用三位,第三维用四位
7.标签编码(Label encoding)
le = sklearn.preprocessing.LabelEncoder()
le.fit([1, 2, 2, 6])
le.transform([1, 1, 2, 6]) #array([0, 0, 1, 2])
#非数值型转化为数值型
le.fit(["paris", "paris", "tokyo", "amsterdam"])
le.transform(["tokyo", "tokyo", "paris"]) #array([2, 2, 1])
8.特征中含异常值时
sklearn.preprocessing.robust_scale
9.生成多项式特征
这个其实涉及到特征工程了,多项式特征/交叉特征。
poly = sklearn.preprocessing.PolynomialFeatures(2)
poly.fit_transform(X)
原始特征:
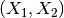
转化后:
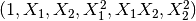
sklearn中常用数据预处理方法的更多相关文章
- sklearn中的数据预处理和特征工程
小伙伴们大家好~o( ̄▽ ̄)ブ,沉寂了这么久我又出来啦,这次先不翻译优质的文章了,这次我们回到Python中的机器学习,看一下Sklearn中的数据预处理和特征工程,老规矩还是先强调一下我的开发环境是 ...
- 机器学习实战基础(八):sklearn中的数据预处理和特征工程(一)简介
1 简介 数据挖掘的五大流程: 1. 获取数据 2. 数据预处理 数据预处理是从数据中检测,纠正或删除损坏,不准确或不适用于模型的记录的过程 可能面对的问题有:数据类型不同,比如有的是文字,有的是数字 ...
- 机器学习实战基础(十五):sklearn中的数据预处理和特征工程(八)特征选择 之 Filter过滤法(二) 相关性过滤
相关性过滤 方差挑选完毕之后,我们就要考虑下一个问题:相关性了. 我们希望选出与标签相关且有意义的特征,因为这样的特征能够为我们提供大量信息.如果特征与标签无关,那只会白白浪费我们的计算内存,可能还会 ...
- 机器学习实战基础(十三):sklearn中的数据预处理和特征工程(六)特征选择 feature_selection 简介
当数据预处理完成后,我们就要开始进行特征工程了. 在做特征选择之前,有三件非常重要的事:跟数据提供者开会!跟数据提供者开会!跟数据提供者开会!一定要抓住给你提供数据的人,尤其是理解业务和数据含义的人, ...
- 机器学习实战基础(十一):sklearn中的数据预处理和特征工程(四) 数据预处理 Preprocessing & Impute 之 处理分类特征:编码与哑变量
处理分类特征:编码与哑变量 在机器学习中,大多数算法,譬如逻辑回归,支持向量机SVM,k近邻算法等都只能够处理数值型数据,不能处理文字,在sklearn当中,除了专用来处理文字的算法,其他算法在fit的 ...
- 机器学习实战基础(十):sklearn中的数据预处理和特征工程(三) 数据预处理 Preprocessing & Impute 之 缺失值
缺失值 机器学习和数据挖掘中所使用的数据,永远不可能是完美的.很多特征,对于分析和建模来说意义非凡,但对于实际收集数据的人却不是如此,因此数据挖掘之中,常常会有重要的字段缺失值很多,但又不能舍弃字段的 ...
- 机器学习实战基础(九):sklearn中的数据预处理和特征工程(二) 数据预处理 Preprocessing & Impute 之 数据无量纲化
1 数据无量纲化 在机器学习算法实践中,我们往往有着将不同规格的数据转换到同一规格,或不同分布的数据转换到某个特定分布的需求,这种需求统称为将数据“无量纲化”.譬如梯度和矩阵为核心的算法中,譬如逻辑回 ...
- matlab、sklearn 中的数据预处理
数据预处理(normalize.scale) 0. 使用 PCA 降维 matlab: [coeff, score] = pca(A); reducedDimension = coeff(:,1:5) ...
- sklearn中的数据预处理----good!! 标准化 归一化 在何时使用
RESCALING attribute data to values to scale the range in [0, 1] or [−1, 1] is useful for the optimiz ...
随机推荐
- Luogu 2312 [NOIP2014] 解方程
感觉好无聊. 秦九昭算法:一般地,一元n次多项式的求值需要经过(n+1)*n/2次乘法和n次加法,而秦九韶算法只需要n次乘法和n次加法.在人工计算时,一次大大简化了运算过程.(百度百科) 具体来说怎么 ...
- 第二篇:MySQL库相关操作
一 系统数据库 information_schema: 虚拟库,不占用磁盘空间,存储的是数据库启动后的一些参数,如用户表信息.列信息.权限信息.字符信息等performance_schema: MyS ...
- Git 之 与Github交互
我们不可能只在一台电脑上开发,白天在公司用公司电脑,晚上在家可以用自己电脑.但是这个代码怎么让两台电脑同步呢?总不能用U盘复制粘贴.太繁琐. 这里我们就可以找个代码托管的平台,帮我们做这件事. Git ...
- HUST高级软件工程--测试管理工具实践--Day1
测试管理工具实践--Day1 今天完成任务情况: 课前组好队伍,建好微信群. 课上通过老师的介绍,初步了解各种测试工具的使用情况. 课后选取了组长,在微信群经过"广泛而激烈"的讨论 ...
- (数组)对数组中的数字加1(plus one)
题目:https://www.nowcoder.com/practice/4d135ddb2e8649ddb59ee7ac079aa882?tpId=46&tqId=29111&tPa ...
- iOS CocoaPods安装与使用
1.MAC安装Ruby环境 1> 安装RVM 控制台命令:$curl –L https://get.rvm.io | bash –s stable $source ~/.rvm/scripts ...
- 关于UI Automation框架
微软提供的UI Automation框架给开发windows平台的自动化测试带来了很大的便利,这里就总结一下相关的代码. 首先,直接使用UI Automation框架,完成一个NotePad的abou ...
- mvvm模式下在WPF项目中动态加载项目的程序集和类
在mvvm模式的wpf项目中有个需求需要去加载解决方案的程序集,并且根据程序集去动态加载当前程序集的类,做成下拉框形式. 效果: //全局定义 private ComboBox abList= nul ...
- ubuntu - 14.04,如何使用鼠标右键菜单在shell中打开选择项目?
在shell中执行:“sudo apt-get install nautilus-open-terminal”,随后重新启动系统,在要打开的文件夹上面鼠标右键,会有一个菜单项目“在终端中打开”,点击后 ...
- KMP算法不同写法之间区别
网上之所以有这么多版本的KMP算法,是因为有的人写的是最大长度串版本的,有的人写的是next数组版本的(具体区别看下面博文),有的人写的是next优化版的,有的人写的是未优化的,不同人写的循环方法不同 ...