python系列3之内置函数和文件操作
目录
- 自定义函数
- 内置函数
- 文件的操作
- 练习题
一. 自定义函数
1. 函数的创建
函数的创建
1.def关键字
2.函数名+()
3.冒号
4.缩进
5. return返回值,可以不写,默认的返回值为None
例:
def hanshuming():
print(123)
print(456)
return True
hanshuming()
2. 函数的参数
(1)参数的定义
参数是使用通用变量来建立函数和变量之间关系的一个变量。我们都知道函数是用来被调用的,当我们需要给这个函数传送值的时候,参数用来接收调用者传递过来的数据,并保存下来作为一个变量以便后期使用。
(2)参数的分类
<1>.实参: 指的是用户在调用函数的时候传递给函数的值。
<2>.形参: 指的是在函数名后面括号中写入的参数,用来接收用户的实际参数的。
例:
# a 指的是形参,用来接收用户的实参
# lsjeg 是实参,用来传递给形参
def test(a):
print(a)
test('lsjeg')
<3>.指定参数: 指的是传递的参数。
<4>.默认参数: 指的是函数名后面括号内跟的参数,当没有实参传入的时候,默认是这个值。
例:由结果可知,当传递的有实参的时候,将用实参,这就是指定参数,当没有实参传入的时候,就用默认值“中国”,这就是默认参数。
def test(a='中国'):
print(a)
test(123)
test()
结果:
123
中国
<5>.动态参数: 指的是加*号的参数。为什么会有动态参数呢?其实就是python把所有的实参循环的放在一个元组里面而已。
<6>.普通参数: 指的是没有加*的函数,他可以接受任意的实参。
例:一个星号的动态参数
# a是普通参数
# *args是动态参数,把接收的所有参数都保存在一个元组中
# 动态参数必须放在普通参数后面
# 要注意的是Python他会自动的把第一个形参传递a,然后后面的都会传递给动态参数。
def test(a,*args):
print(args)
test(123,'sl','s2','s3')
例:两个星号的动态参数(主要为了存储字典)
注意他的结果,【11,22,33】前面有*,所以会把里面的元素依次的放入元组中,
# a是普通参数
# *args是动态参数,把接收的所有参数都保存在一个元组中
# **kwargs也是动态参数,把接收的所有参数保存在一个字典中,注意,实参必须是键值对
# 一个*的必须在后面,两个*的必须在一个*的后面
def test(a,*args,**kwargs):
print(args)
print(kwargs)
test(123,*[11,22,33],sle=23)
结果:
(11, 22, 33)
{'sle': 23}
3. 变量
<1>.全局变量:简单来说就是没有在函数中定义的变量。一般用大写表示
<2>.局部变量: 相反,就是在函数中定义的变量。一般小写
例1:
# 默认函数里面是没有办法修改全局变量的
TEST = 123
def test(a):
TEST = 456
test(1)
print(TEST)
结果:
123
例2:修改全局变量
TEST = 123
def test(a):
global TEST
TEST = 456
test(1)
print(TEST)
结果:
456
4. lambda表达式
什么是lambda表达式呢,其实就是对自定义函数的一个简化,当然,他也是只能用于简单的函数创建。
例:
# 定义了两个函数,两个函数的功能是一样的
# 一般方式定义test
# lambda表达式定义的lambda_test def test(a1, a2):
return a1+a2 lambda_test = lambda a1,a2: a1+a2 print(test(1,2))
print(lambda_test(1,2))
5. 三元表达式
三元表达式是什么东西呢,其实就是对if...else循环的一个简化,但是只能用于简单的if...else的简化,在很多的语言中都有。
例:if前面的为条件成立后执行的语句,else后面的为条件不成立时执行的语句
# 普通的判断语句
a = 1
if a < 6:
name = 'huwentao'
else:
name = 'zhouyan'
print(name) # 这个是三元表达式,
name = 'zhouyan' if a < 6 else 'huwentao'
print(name) 输出结果:
huwentao
zhouyan
二. 内置函数简介
1. str(), int(), bool(), list(), dict(), set(), tuple(), bytes(), type(), isinstance()
这个是一系列的关于数据类型的函数,因为对于数据类型创建一般有两种方式,
例: <1>: i = 10 <2>: i = int(10) 这两种方式是一样的,其本质都是调用int函数的_init_函数去创建的对象,其他的类型也一样
type(): type() 可以显示出类型
例:
i = 10
print(type(i))
结果:<class 'int'>
isinstance(要判断的数据, 数据类型): 用来判断是不是某个类型
例:
i = 10
print(isinstance(i, int))
结果: True 因为i就是int类型。所以返回True 2. bin(), int(), hex(), oct()
这是一系列关于进制转换的函数,
bin(): 十进制转二进制
例:print(bin(10)) ----->0b1010
hex(): 十进制转十六进制
例:print(hex(10)) ----->0xa
oct(): 十进制转八进制
例:print(oct(10)) ----->0o12
int(): 其他进制转十进制
例:
print(int('', 2)) #二进制---》十进制
print(int('ab', 16)) #二进制---》十进制
print(int('', 8)) #二进制---》十进制
结果:
21
171
8
3. repr(), ascii()
这两个函数差不多是一样的,就是调用内置函数里面的_repr__() 4. all(), any()
all(): 里面的变量全部为真,返回值为真
例:
print(all(['hu','zhou','xiaozhou']))
print(all(['hu','zhou','xiaozhou','']))
结果:
True
False
any(): 里面的变量只要有一个为真,就返回为真
例:
print(any([]))
print(any(['hu','zhou','xiaozhou']))
print(any(['hu','zhou','xiaozhou','']))
结果:
False
True
True 5. dir(), help()
用来获得当前模块或者函数的属性列表
dir() 获取简单的属性列表
print(dir(list))
help() 获取详细的属性列表
help(list) 6. enumrate() ,len()
会给一个序列在生成一列索引,由以下例子可以看出,自动增加缩进然后以一个元组的形式保存在i变量中
例:
list = ['hu','zhou','xiaozhou']
for i in enumerate(list, 1):
print(i)
结果:
(1, 'hu')
(2, 'zhou')
(3, 'xiaozhou')
len(): 得到长度 7. max(), min(), sum(), sorted(), round(), reversed(), abs(), pow(), range(), divmod(), zip()
这个是一系列关于数据操作的函数
由名字可以看出,取最大值,最下值,求和,排序,四舍五入,翻转,取绝对值,求幂运算,生成一个可迭代对象
round():
例:
print(round(11.1))
print(round(11.5))
print(round(11.6))
结果:
11
12
12
reversed():
例:
list = [99,32,1,232,44]
print(sorted(list))
range():生成一个可迭代对象
例:
a = range(10)
print(a)
for i in a:
print(i, end = ' ')
结果:
range(0, 10)
0 1 2 3 4 5 6 7 8 9
divmod(): 把除数和余数同时输出来
例:
print(divmod(10, 3)) -----》 (3, 1)
zip(): 结合两个列表
list = [11,22,33,44]
hu = ['hu','zhou','xiaohu','xiaozhou']
a = zip(list, hu)
for i in a:
print(i) 8. callable()
判断里面的数据是否可执行,一般函数和类是可执行的
例:
def test():
return 10
print(callable(1))
print(callable('weg'))
print(callable(test))
结果:
False
False
True
9. chr(), ofd()
chr(): 数字转ascii
ord(): asscii转数字
例:
print(chr(69))
print(ord('E'))
10. compile(),exec(),eval()
complie():用来编译生成对象
exec(): 用来执行编译生成的对象
例:
str = '''
for i in range(4):
print(i)
'''
c = compile(str,'','exec')
exec(c)
eval():只能对简单的代码进行操作,不能进行代码的执行
例:
print(eval('1+2')) 11. local() globals(), hash()
local():当前执行函数的所有局部变量
globals:当前执行函数的所有全局变量
hash(): 对里面的数据进行hash运算
12. exit()
exit(): 退出程序
13. open(), import
open是打开文件
import导入模块 14. filter(), map()
filter(函数,过滤的对象): 每一个过滤的对象都相应的执行函数,当返回为真的时候,就返回回去,并且返回的是一个对象
例:
def hanshu(aa):
if aa > 22:
return True
else:
return False
a = filter(hanshu, [11,22,33,44])
print(a)
for i in a:
print(i)
结果:
<filter object at 0x000000A1636B4470>
33
44
map(函数,对象):每一个过滤的对象都响应的代入函数中执行,返回的是他的返回值,而且返回的是一个对象
例:
def hanshu(aa):
if aa > 22:
return True
else:
return False
a = map(hanshu, [11,22,33,44])
print(a)
for i in a:
print(i)
结果:
<map object at 0x0000005B2B504470>
False
False
True
True
三. 文件的操作
1. 文件的操作
文件的基本操作有打开,和关闭,读写等。
# 一般在打开一个文件的时候会创建一个对象传递给一个变量f
# parameter1:文件名,如果是相对路径,必须在一个目录下面
# parameter2:模式, 大致分为两种r,w
# parameter3:编码方式
f = open('parameter1','parameter2','parameter3')
f.close()
2. 文件的模式
(1)普通的读写
<1>. r: 只能读,传入的文件参数必须要存在,否则会报错
# test在当前目录下一定要存在
# flie.write不能用,只能读
file = open('test','r')
data = file.read()
# file.write('lwjege')
file.close()
<2>. w: 只能写,不能读,传入的文件如果存在,就清空里面的内容,如果不存在,就创建
# 当传入的参数是w的时候,执行完此代码再去查看test文件的时候,会发现里面的内容为“大中国”,无论之前的内容是什么,都是这个内容,因为写操作不是追加的,而是先清空之前的内容然后在写入。
file = open('test','w')
file.write('大中国')
file.close()
<3>. x: 只能写,不能读,传入的文件不能存在,存在就报错
# 这里的参数test2在此目录下面不能存在,如果存在就会报错,而且不能读数据
file = open('test2','x')
# file.read()
file.write('大中国')
file.close()
<4>. a: 只能写,不能读,传入的文件存在,就追加写入,如果不存在,就创建
# 当传入的参数是a的时候,不能读数据,只能进行写数据,而且他是追加写入,不像w,会把之前的数据都清空
file = open('test','w')
file.write('大中国')
file.close()
(2)可读可写
以下的操作其实很大程度上是继承了上面普通操作的属性,只是加上+号的都是可读可写的,其余的都基本上一样。
<1>. r+: 可读可写,文件必须存在,不存在就报错,而且他不是覆盖存储的,也不是清空之后存储的。由以下例子可见,r+是从前往后覆盖存储的。
例1:写入文件
file = open('test','r+',encoding='utf-8')
print(file.tell())
file.write('我是中国人,我骄傲.')
file.close()
查看文件内容:
我是中国人,我骄傲.
例2:再次写入文件
file = open('test','r+',encoding='utf-8')
print(file.tell())
file.write('woshi')
file.close()
显示文件文内容:
woshi�中国人,我骄傲.
例3:有读操作
# 只要是读操作执行了,在写的时候就会默认的在后面追加
with open('test','r+',encoding='utf-8') as f:
print(f.tell())
f.read(1)
f.write('xxx')
原文件内容:123456
执行完上述操作的内容:123456xxx
例4: 有读操作,也有seek
# 如果在写操作前面加上seek指定地址,写操作就会再这个地址后面添加内容,覆盖后面的内容
with open('test','r+',encoding='utf-8') as f:
print(f.tell())
f.read(1)
f.seek(2)
print(f.tell())
f.write('xxx') 源文件内容:123456789
执行完代码的内容:12xxx6789
<2>. w+: 可读可写,文件不存在可以创建,存在就清空再存储
file = open('test','w+',encoding='utf-8')
print(file.tell())
file.write('woshidab')
file.close()
显示内容:
woshidab
<3>. x+: 依然是文件不能存在,存在就报错,可读可写。
file = open('test6','x+',encoding='utf-8')
print(file.tell())
# file.write('woshidab')
file.close()
<4>. a+: 可读可写,文件存在就追加存储,文件不存在就创建。
file = open('test7','a+',encoding='utf-8')
print(file.tell())
file.write('woshidab')
file.close()
(3)字节方式的存储
r 和不加r的区别主要在于一个 是python内部自动给我们转换成了字符串的格式,一个是没有转换的直接就是字节格式。
例:
# 此例可知道,加上b之后的的操作都是bytes,而不加b就是字符
file = open('test','r')
data = file.read()
print(type(data))
file.close()
file = open('test','rb')
data = file.read()
print(type(data))
file.close()
显示结果:
<class 'str'>
<class 'bytes'>
原理:
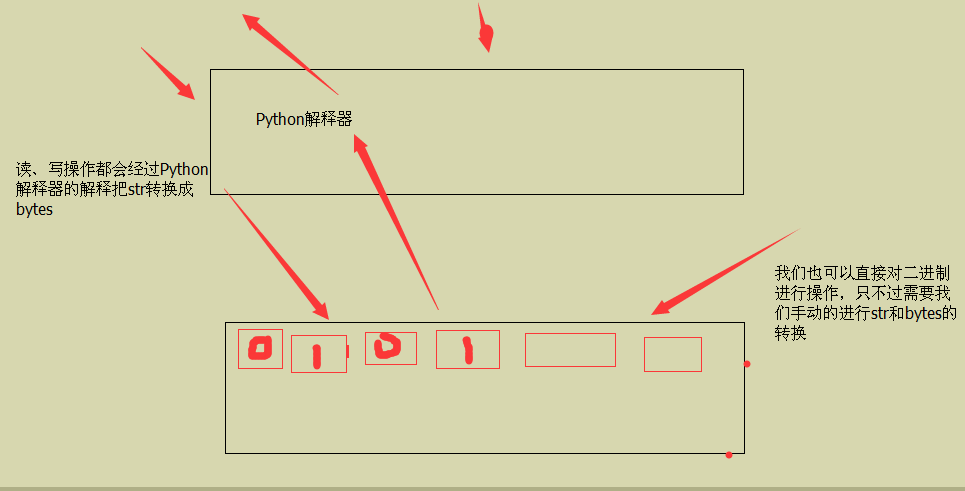
<1>. rb: 和r的属性都一样,只是输出的是字节而已,我们把他转换一下就可以了。
# 输出的那一句做了字节到字符串的转换,编码方式需要看test本身的编码方式是什么
file = open('test','rb')
data = file.read()
print(str(data,encoding='utf-8'))
file.close()
<2>. wb: 和w的属性都一样,只是输出的是字节而已,我们把他转换一下就可以了。
# 读和写的编码方式要一样
file = open('test','wb')
file.write(bytes('我是中国人',encoding='utf-8'))
file.close() file = open('test','rb')
print(str(file.read(),encoding='utf-8'))
file.close() 输出结果:
我是中国人
<3>. xb: 和x的属性都一样,只是输出的是字节而已,我们把他转换一下就可以了。
<4>. ab: 和a的属性都一样,只是输出的是字节而已,我们把他转换一下就可以了。
# 因为他是追加输入,我多运行了几次,因此显示如下结果
file = open('test','ab')
file.write(bytes('我是中国人',encoding='utf-8'))
file.close() file = open('test','rb')
print(str(file.read(),encoding='utf-8'))
file.close() 输出结果:
我是中国人我是中国人我是中国人我是中国人
3. 文件类的额外功能
flush:用来刷新缓冲区的,把缓冲区的内容写入文件中而不需要等待文件被关闭,并清除缓冲区。
readline:一次读入一行
tell: 获取当前指针指向的位置
seek: 调整当前指针的指向的位置
truncate:用来截断文件,当前内容后面的都将会被删除
write: 写入操作
read: 读取操作
open: 打开文件
close: 关闭文件
4. 同时打开多个文件
# 固定的格式
with open('源文件','r') as obj1,with open('新文件','w') as obj2
for line in obj1:
obj2.write(line)
四. 练习题:
1. 简述普通参数,指定参数,默认参数,动态参数的区别
2. 写函数,计算传入字符串中【数字】,【字母】,【空格】以及【其他】的个数
# -*- coding:GBK -*-
# zhou
# 2017/6/13
def function1(a):
digit = 0
str = 0
space = 0
other = 0
for i in a:
if i.isdigit():
digit += 1
elif i.isalpha():
str += 1
elif i.isspace():
space += 1
else:
other += 1
return ({'数字':digit,'字符':str,'空格':space,'其他':other})
a = function1('234wlj**ego ewjgo')
for i in a:
print(i,a[i],'个') 显示结果:
字符 11 个
空格 2 个
数字 3 个
其他 2 个
3. 写函数,判断用户传入的对象(字符串,列表,元组)长度是否大于5
# -*- coding:GBK -*-
# zhou
# 2017/6/13
def function(a):
if len(a) <= 5:
print('传入的参数长度小于等于5')
else:
print('传入的参数长度大于5')
function('lwejglejgl')
function([11,22,33,44])
function((1,2,3,4,5,6))
显示结果:
传入的参数长度大于5
传入的参数长度小于等于5
传入的参数长度大于5
4. 写函数,检查传入列表的长度,如果大于2,那么仅保留前两个长度的内容,并将其作为新列表返回给调用者
# -*- coding:GBK -*-
# zhou
# 2017/6/13 def function(a):
if isinstance(a,list):
if len(a) > 2:
ret = a[0:2]
else:
ret = a
else:
ret = a
return ret
print(function([11,22,33,44]))
print(function(['hu','zhou']))
结果:
[11, 22]
['hu', 'zhou']
5. 写函数,判断用户传入的对象(字符串,列表,元组)的每一个元素是否含有空内容
# -*- coding:GBK -*-
# zhou
# 2017/6/13
def function(a):
for i in range(len(a)):
if a[i].count(' ') != 0:
print('输入的对象中第%d元素中含有空格'%(i+1)) function(['hu','zh ou'])
6. 写函数,检查获取传入列表或元组对象的所有奇数位索引对应的元素,并将其作为新列表返回给调用者
# -*- coding:GBK -*-
# zhou
# 2017/6/13 def function(a):
ret = []
for i in range(len(a)):
if i % 2 == 1:
ret.append(a[i])
return ret
print(function(['hu','zhou','mage','laomanhai']))
7. 写函数,检查传入字典的每一个value的长度,如果大于2,那么仅保留前两个长度的内容,并将其新内容返回给调用者
# -*- coding:GBK -*-
# zhou
# 2017/6/13
def function(a):
ret = a
for i in a.keys():
if len(a[i]) > 2:
ret[i] = a[i][0:2]
else:
ret[i] = a[i]
return ret
print(function({'k1':'v1','hu':'haoshuai','zhou':'haomei'}))
结果:
{'k1': 'v1', 'zhou': 'ha', 'hu': 'ha'}
8. 验证码
# -*- coding:utf-8 -*-
# zhou
# 2017/6/14
import random
temp = str()
for i in range(6):
num = random.randrange(0, 4)
if num == 1 or num == 3:
num = random.randrange(0, 10)
temp = temp + str(num)
else:
rad = random.randrange(65, 91)
rad = chr(rad)
temp = temp + rad
print(temp)
python系列3之内置函数和文件操作的更多相关文章
- python day5 lambda,内置函数,文件操作,冒泡排序以及装饰器
目录 python day 5 1. 匿名函数lambda 2. python的内置函数 3. python文件操作 4. 递归函数 5. 冒泡排序 6. 装饰器 python day 5 2019/ ...
- python基础十三之内置函数
内置函数 操作字符串代码 eval和exec print(eval('1+2')) # 简单的计算 有返回值 exec('for i in range(10):print(i)') # 简单的流程控制 ...
- Python全栈开发之4、内置函数、文件操作和递归
转载请注明出处http://www.cnblogs.com/Wxtrkbc/p/5476760.html 一.内置函数 Python的内置函数有许多,下面的这张图全部列举出来了,然后我会把一些常用的拿 ...
- Python学习日记(六)——内置函数和文件操作(lambda)
lambda表达式 学习条件运算时,对于简单的 if else 语句,可以使用三元运算来表示,即: # 普通条件语句 if 1 == 1: name = 'prime' else: name = 'c ...
- set、def、lambda、内置函数、文件操作
set : 无序,不重复,可以嵌套 .add (添加元素) .update(接收可迭代对象)---等于批量 添加 .diffrents()两个集合不同差 .sysmmetric difference( ...
- 【python】函数之内置函数
Python基础 内置函数 今天来介绍一下Python解释器包含的一系列的内置函数,下面表格按字母顺序列出了内置函数: 下面就一一介绍一下内置函数的用法: 1.abs() 返回一个数值的绝对值,可以是 ...
- Python之内置函数
内置函数 python里的内置函数.截止到python版本3.6.2,现在python一共为我们提供了68个内置函数.它们就是python提供给你直接可以拿来使用的所有函数. 分类学习内置函数: 总共 ...
- python之内置函数(一)
一.内置函数一1.内置函数总览 abs() dict() help() min() setattr()all() dir() hex() next() slice() any() divmod() i ...
- python基础之内置函数和匿名函数
内置函数 学习函数以后多了很多概念,例如函数的命名空间,函数的作用域,函数的调用等等,函数的作用就是为了实现某些功能而方便以后可以调用,内置函数就是这样的一些公共的函数,被称为内置函数. 我们就一 ...
随机推荐
- 在mac上使用github for mac 创建并上传项目
1.下载github for mac https://mac.github.com/ 2.登陆 偏好设置 3.用Xcode 创建一个项目,勾上“create local git respository ...
- php赋值运算符
= 赋值 += $x+=3相当于$x = $x+3; -= *= /+ %= .=
- python面试题——基础篇(80题)
1.为什么学习Python? Python是一门优秀的综合语言, Python的宗旨是简明.优雅.强大,在人工智能.云计算.金融分析.大数据开发.WEB开发.自动化运维.测试等方向应用广泛 2.通过什 ...
- input type="file"获取文件名方法
文件上传比较丑,样式调整时会有一个获取文件名,或者包含文件路径的文件名的方法 html代码 <div class="file-box"> <form id=&qu ...
- open ssh 常用的东西
清除已经存在的但是不同设备的连接信息 ssh-keygen -f "/users/he/.ssh/known_hosts" -R 192.168.1.118 无密码登录openss ...
- Spark master节点HA配置
Spark master节点HA配置 1.介绍 Spark HA配置需要借助于Zookeeper实现,因此需要先搭建ZooKeeper集群. 2.配置 2.1 修改所有节点的spark-evn.sh文 ...
- TP5.1:将外部资源引入到框架中(css/js/font文件)
为了让我们的框架形式变得更加好看,我们需要加入Bootstrap和Jq文件到框架中 1.通过Bootstrap和jq官网进行相关文件的下载 (1)Bootstrap下载地址:https://v3.bo ...
- 显示C++ vector中的数据
C++ 中的vector是一个容器数据类型,不能使用cout直接显示容器中的值. 以下程序中,myvector 是一个vector数据类型.将myvector替换为需要输出的vector. for(i ...
- window下mycat要放在根目录下
原理文档没有跟我开玩笑呢? 建议放在盘符根目录下 ,无视的我,检查了多遍jdk环境,检查了多遍bat文件内容,仍然没有解决 找不到或无法加载主类 直到我乖乖的把目录放跟盘符才解决,心好累= =! 可能 ...
- java集合框架——Map
一.概述 1.Map是一种接口,在JAVA集合框架中是以一种非常重要的集合.2.Map一次添加一对元素,所以又称为“双列集合”(Collection一次添加一个元素,所以又称为“单列集合”)3.Map ...