Go语言基础之12--Channel
一、不同goroutine之间如何进行通讯?
1、全局变量和锁同步
缺点:多个goroutine要通信时,定义太多的全局变量(每个全局变量功能不一样),不好维护
2、Channel
二、channel概念
a. 类似unix中管道(pipe)
b. 先进先出
c. 线程安全,多个goroutine同时访问,不需要加锁
d. channel是有类型的,比如说:一个整数(int)的channel只能存放整数(int)
注意:channel是引用类型,channel的零值也是nil
三、channel声明
var 变量名 chan 类型
var test chan int
var test chan string
var test chan map[string]string
var test chan stu
var test chan *stu
四、channel初始化
channel是引用类型,channel的零值也是nil,所以需要使用make进行初始化,比如:
var test chan int
test = make(chan int, ) //第1个参数chan是声明为channel,第2个参数是channel的类型,第3个参数是channel的长度
上述channel长度为10,channel最多只能存10个元素,当第11个元素插入时,channel也不会扩容,此时channel已经满了,队列只能阻塞住了,除非第1个被取走了,第11个才能进去channel。
总结:channel队列两种情况会阻塞
第一种:channel为空时,取数据会阻塞;
第二种:channel满了,再往channel中插入数据,也会阻塞
注意:如果初始化channel时不定义队列长度(无缓冲区(长度为0)channel),channel就相当于没有长度,也就相当于没有空间去存放元素。但是也有解决办法:
就是程序中:一个去放,还有一个去取,相当于立马取出来。
代码示例如下:
package main import (
"fmt"
"time"
) func main() {
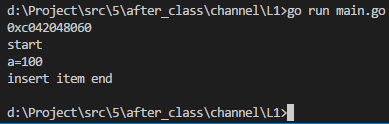
var intChan chan int = make(chan int) //channel没有长度
fmt.Printf("%p\n", intChan)
go func() {
intChan <- //放100进没有长度的channel
fmt.Printf("insert item end\n")
}()
go func() {
fmt.Printf("start\n")
time.Sleep(time.Second * )
var a int
a = <-intChan //读取100,相当于立马取
fmt.Printf("a=%d\n", a) }() time.Sleep(time.Second * )
}
执行结果如下:
再来看一个定义了channel(带缓冲区channel)长度的实例:
package main import (
"fmt"
"time"
) func main() {
var intChan chan int = make(chan int, ) //channel长度为1
fmt.Printf("%p\n", intChan)
go func() {
intChan <- //放100进channel,之后随时可以读取channel
fmt.Printf("insert item end\n")
}()
go func() {
fmt.Printf("start\n")
time.Sleep(time.Second * )
var a int
a = <-intChan //a读取channel中的元素
fmt.Printf("a=%d\n", a) }() time.Sleep(time.Second * )
}
执行结果如下:

五、channel的基本操作
1、 从channel读取数据:
var testChan chan int
testChan = make(chan int, )
var a int
a = <- testChan //相当于从testChan中读取出来数据并赋值给a
2、为channel写入数据:
var testChan chan int
testChan = make(chan int, )
var a int =
testChan <- a //写入数据10给管道testChan
intChan <- 100
intChan是一个channel类型的变量,根据箭头方向来判断,很形象,此处就表示将100插入到管道(channel)intChan中去。
a <- intChan
a为新定义的变量,表示a读取管道intChan中的值。
六、goroutine与channel结合
代码实例:
package main import (
"fmt"
"time"
) func main() {
ch := make(chan string) //不带缓冲区的channel
go sendData(ch)
go getData(ch)
time.Sleep( * time.Second)
}
func sendData(ch chan string) { //该goroutine函数为channel中插入数据,类似于生产者
ch <- "Washington"
ch <- "Tripoli"
ch <- "London"
ch <- "Beijing"
ch <- "Tokio"
}
func getData(ch chan string) { //该goroutine函数读取channel中数据,类似于消费者
var input string
for {
input = <-ch
fmt.Println(input)
}
}
执行结果如下:

七、channel阻塞(无缓冲区)
总结:channel队列两种情况会阻塞
第一种:channel为空时,取数据会阻塞;
第二种:channel满了,再往channel中插入数据,也会阻塞
实例如下:
package main import (
"fmt"
"time"
) func main() {
ch := make(chan string) //定义一个无缓冲区(长度为0)channel
go sendData(ch)
time.Sleep( * time.Second)
}
func sendData(ch chan string) { //往channel中插入数据,但是没有人取,只能阻塞了
var i int
for {
var str string
str = fmt.Sprintf("stu %d", i)
fmt.Println("write:", str)
ch <- str
i++
}
}
执行结果:
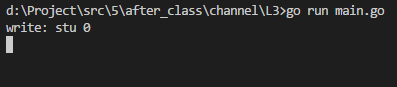
解释:
可以看到只有写入没有读取,阻塞住了
八、带缓冲区channel
1、如下所示, testChan长度为0:
var testChan chan int
testChan = make(chan int)
var a int
a = <- testChan
2、如下所示, testChan是带缓冲区的chan,一次可以放10个元素:
var testChan chan int
testChan = make(chan int, )
var a int =
testChan <- a
九、channel之间的同步
代码实例:
package main import (
"fmt"
"time"
) func main() {
ch := make(chan string)
go sendData(ch)
go getData(ch)
time.Sleep( * time.Second)
}
func sendData(ch chan string) {
ch <- "Washington"
ch <- "Tripoli"
ch <- "London"
ch <- "Beijing"
ch <- "Tokio"
}
func getData(ch chan string) {
var input string
for {
input = <-ch
fmt.Println(input)
}
}
会有一个问题,如果sleep时间都结束了,但是sendData和getdata所在的函数还没执行完,那么也会被中断执行,如何解决呢:
解决办法:
1、死循环:( 缺点:有时生产者和消费者已经执行完,却依然还在死循环,退不出。)
2、标识位,也就是全局变量和加锁(缺点:比较麻烦,如果有100个goroutine,也要写100个标识位)
上述2个办法都太麻烦不可取,可以pass掉了,下面我们有更好办法:
9.1 方法1:channel
代码实例:
package main import (
"fmt"
// "time"
) func main() {
ch := make(chan string)
exitChan := make(chan bool, ) //此例我们有3个goroutine,所以我们定义一个长度为3的channel,当我的channel中可以读取到3个元素时,即表示3个goroutine都执行完毕了。
go sendData(ch, exitChan) //每一个goroutine执行结束时,往channel中插入一个数据
go getData(ch, exitChan)
go getData2(ch, exitChan) //等待其他goroutine退出,当goroutine都执行完毕退出之后,channel中有3个元素,我们可以做一个取3次的操作,当3次都取完了,表示所有goroutine都退出了
<-exitChan //从channel中取出来元素并未赋值给任何变量,就相当于丢弃了
<-exitChan
<-exitChan
fmt.Printf("main goroutine exited\n")
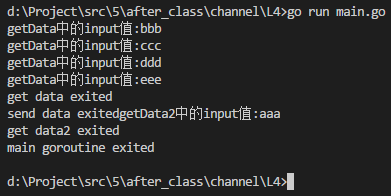
} func sendData(ch chan string, exitCh chan bool) {
ch <- "aaa"
ch <- "bbb"
ch <- "ccc"
ch <- "ddd"
ch <- "eee"
close(ch) //插入数据结束后,关闭管道channnel
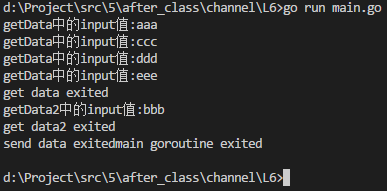
fmt.Printf("send data exited")
exitCh <- true //此时已经往goroutine中插入数据结束,goroutine退出之前,往我们定义的channel中插入一个数据true,相当于告知我已经执行完成
} func getData(ch chan string, exitCh chan bool) {
//var input string
for {
//input = <- ch
input, ok := <-ch //检查管道是否被关闭
if !ok { //如果被关闭了,ok=false,我们就break退出
break
}
// 此处 打印出来的顺序 和写入的顺序 是一致的
// 遵循队列的原则: 先入先出
fmt.Printf("getData中的input值:%s\n", input)
}
fmt.Printf("get data exited\n")
exitCh <- true
} func getData2(ch chan string, exitCh chan bool) {
//var input2 string
for {
//input2 = <- ch
input2, ok := <-ch
if !ok {
break
}
// 此处 打印出来的顺序 和写入的顺序 是一致的
// 遵循队列的原则: 先入先出
fmt.Printf("getData2中的input值:%s\n", input2)
}
fmt.Printf("get data2 exited\n")
exitCh <- true
}
执行结果如下:
注意:当我们为channel中放入10个元素,然后把channel关闭,这些元素还是在channel中的,不会消失的,之后想取还是可以取出来的。
通过如下实例来证明:
package main import (
"fmt"
"time"
) func main() {
var intChan chan int
intChan = make(chan int, )
for i := ; i < ; i++ {
intChan <- i
} close(intChan)
time.Sleep(time.Second * )
for i := ; i < ; i++ {
var a int
a = <-intChan
fmt.Printf("a=%d\n", a)
}
}
执行结果如下图:
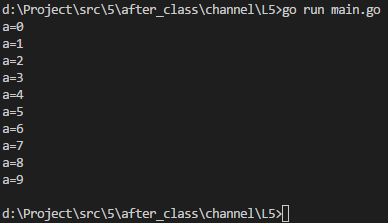
解释:
可以看到在为channel中放入10个元素之后,就关闭了channel,之后依然可以取出来。
9.1 方法2:(推荐)
针对大批量goroutine,用sync包中的waitGroup方法,其本身是一个结构体,该方法的本质在底层就是一个计数。
代码实例如下:
package main import (
"fmt"
"sync"
// "time"
) func main() {
var wg sync.WaitGroup //定义一个waitgroup(结构体)类型的变量,针对大批量goroutine时比较方便。
ch := make(chan string)
wg.Add() //3个goroutine,就传入3,Add方法相当于计数
go sendData(ch, &wg) //,相当于goroutine执行完,Add计数就减1,所以我们将wg传入,但注意结构体必须要传入一个地址进去
go getData(ch, &wg)
go getData2(ch, &wg) wg.Wait() //只要Add中计数依然存在,就一直Wait,除非为0
fmt.Printf("main goroutine exited\n")
} func sendData(ch chan string, waitGroup *sync.WaitGroup) {
ch <- "aaa"
ch <- "bbb"
ch <- "ccc"
ch <- "ddd"
ch <- "eee"
close(ch)
fmt.Printf("send data exited")
waitGroup.Done() //goroutine退出时,计数减1,所以这里用Done方法来通知Add方法
} func getData(ch chan string, waitGroup *sync.WaitGroup) {
//var input string
for {
//input = <- ch
input, ok := <-ch
if !ok {
break
}
// 此处 打印出来的顺序 和写入的顺序 是一致的
// 遵循队列的原则: 先入先出
fmt.Printf("getData中的input值:%s\n", input)
}
fmt.Printf("get data exited\n")
waitGroup.Done()
} func getData2(ch chan string, waitGroup *sync.WaitGroup) {
//var input2 string
for {
//input2 = <- ch
input2, ok := <-ch
if !ok {
break
}
// 此处 打印出来的顺序 和写入的顺序 是一致的
// 遵循队列的原则: 先入先出
fmt.Printf("getData2中的input值:%s\n", input2)
}
fmt.Printf("get data2 exited\n")
waitGroup.Done()
}
执行结果如下:
十、for range 遍历channel
for range遍历channel的好处,channel关闭了,for range循环会自动退出
for range结束判断的标准也是看channel是否close关闭,不然就会阻塞,具体可看如下例子:
package main import (
"fmt"
"time"
) func main() {
ch := make(chan string)
go sendData(ch)
go getData(ch)
time.Sleep( * time.Second)
}
func sendData(ch chan string) {
ch <- "Washington"
ch <- "Tripoli"
ch <- "London"
ch <- "Beijing"
ch <- "Tokio"
close(ch)
}
func getData(ch chan string) {
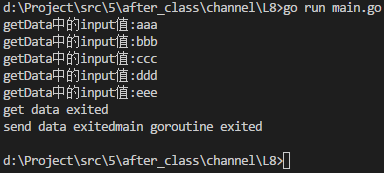
for input := range ch {
fmt.Println(input)
}
}
执行结果如下:

下面再看一个有channel关闭的例子,for range执行完会自动退出
实例如下:
package main import (
"fmt"
"sync"
) func main() {
var wg sync.WaitGroup
ch := make(chan string)
wg.Add()
go sendData(ch, &wg)
go getData(ch, &wg) wg.Wait()
fmt.Printf("main goroutine exited\n")
} func sendData(ch chan string, waitGroup *sync.WaitGroup) {
ch <- "aaa"
ch <- "bbb"
ch <- "ccc"
ch <- "ddd"
ch <- "eee"
close(ch)
fmt.Printf("send data exited")
waitGroup.Done()
} func getData(ch chan string, waitGroup *sync.WaitGroup) {
//var input string
for {
//input = <- ch
input, ok := <-ch
if !ok {
break
}
// 此处 打印出来的顺序 和写入的顺序 是一致的
// 遵循队列的原则: 先入先出
fmt.Printf("getData中的input值:%s\n", input)
}
fmt.Printf("get data exited\n")
waitGroup.Done()
}
执行结果如下:
十一、channel的关闭
1. 使用内置函数close进行关闭, chan关闭之后, for range遍历chan中
已经存在的元素后结束
2. 使用内置函数close进行关闭, chan关闭之后,没有使用for range的写法
需要使用, v, ok := <- ch进行判断chan是否关闭
十二、channel的只读和只写
a. 只读chan的声明
Var 变量的名字 <-chan int
Var readChan <- chan int
只读实例:
package main
func main() {
var intChan <-chan int = make(chan int, )
intChan <-
}
执行结果如下:

解释:
只读实例进行写入,可以看见编译时直接报错。
b. 只写chan的声明
Var 变量的名字 chan<- int
Var writeChan chan<- int
只写实例:
package main
func main() {
var ch chan<- int = make(chan int, )
<-ch
}
执行结果:

解释:
可以看见只写实例进行读取channel时,也是编译时直接报错。
应用场景:
比如说写一个第三方的自定义包,暴露channel给别人去掉用,这个时候就可以控制返回给别人channel的权限控制,来防止误操作。
十三、对channel进行select操作
13.1 场景:
假如channel中有数据或无数据,我们是通过一个阻塞的读或者阻塞的写去操作数据,如果程序是去阻塞的读,那么相当于程序直接是阻塞的了,这种形式是不好的,比如说处理一个web请求,不能够阻塞的,这时候就有一种机制select操作,通过判断channel中有没有数据,如果没有数据,则立即返回。
13.2 为什么要用select操作channel?
通过select语句来监测channel到底是满了还是空了,来避免程序阻塞,但是如果没有加default分支,程序依然还是会被阻塞。
补充:
1)select语句的形式其实和switch语句有点类似,这里每个case代表一个通信操作;
2)在某个channel上发送或者接收,并且会包含一些语句组成的一个语句块 ;
3)select中的default来设置当 其它的操作都不能够马上被处理时程序需要执行哪些逻辑;
4)channel 的零值是nil, 并且对nil的channel 发送或者接收操作都会永远阻塞,在select语句中操作nil的channel永远都不会被select到。所以我们可以用nil来激活或者禁用case,来达成处理其他输出或者输出时间超时和取消的逻辑
13.3 声明语法
语法如下:
select {
case u := <- ch1: //channel有数据,该分支就会被激活
case e := <- ch2: //channel有数据,该分支也会被激活
default: //如果上述分支都未被激活,则进入default分支
}
注意:不同的case分支调度总体来说是平衡的,不是说永远只执行第1个分支,而不执行第2个分支。
13.4 实例
实例:
package main import (
"fmt"
"sync"
"time"
) func main() {
var intChan chan int = make(chan int, ) //定义1个int类型channel,给10个空间
var strChan chan string = make(chan string, ) //定义1个string类型channel,给10个空间 var wg sync.WaitGroup //通过waitgroup来控制goroutine的同步
wg.Add()
//插入数据,空间满了,channel也会阻塞,所以通过select解决
go func() {
var count int //因为目前for循环是一个死循环,所以需要有一个限制条件来break
for count < {
count++
select {
case intChan <- : //插入一个10进去
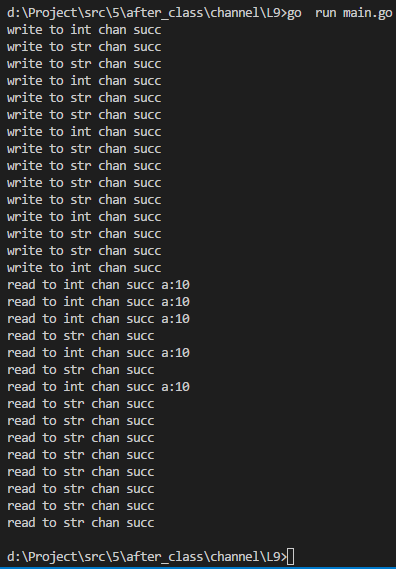
fmt.Printf("write to int chan succ\n")
case strChan <- "hello": //插入一个hello进去
fmt.Printf("write to str chan succ\n")
default: //当上述所有case分支对应的管道都被被插满数据后,会走到如下default分支
fmt.Printf("all chan is full\n")
time.Sleep(time.Second)
}
}
wg.Done() //for循环结束就可以退出了
}() //读取数据
go func() {
var count int
for count < {
count++
select {
case a := <-intChan: //读取intChan中的数据
fmt.Printf("read to int chan succ a:%d\n", a)
case <-strChan: //如果只想读出来strChan中的数据,并不赋值,可以这么写,但实际数据还是读出来了
fmt.Printf("read to str chan succ\n")
default: //当取完上述case分支对应的所有channel数据后,其会走如下的default分支
fmt.Printf("all chan is empty\n")
time.Sleep(time.Second)
}
}
wg.Done() //for循环结束就可以退出了
}()
wg.Wait()
}
执行结果:
解释:

如上图为插入数据匿名函数执行结果(往channel中插入数据)我们可以看到当前两个分支都写满之后,就会进入default分支,可以看到程序是不会阻塞的。
十四、定时器使用
14.1 定时器的使用
package main import (
"fmt"
"time"
) func main() {
t := time.NewTicker(time.Second)
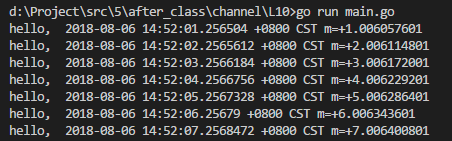
for v := range t.C { //定时器Newticker会返回一个时间的channel
fmt.Println("hello, ", v)
}
}
执行结果:
解释:

定时器C的方法其实是一个只读的channel,里面放的是时间。
因为是channel,所以我们可以用for range去遍历。
14.2 一次性定时器
package main import (
"fmt"
"time"
) func main() {
select {
case <-time.After(time.Second): //用time.After方法,到了1秒之后,就会触发这个分支
fmt.Println("after")
}
}
执行结果如下:

14.3 超时定时器
场景:
线上进行DB查询时,如果超过一定时间没有返回,那么我们就应该给调用方返回一个值,不能一直在干等着吧,所以我们就需要有一个超时控制。比如说:查询结果1秒没有返回,就返回一个错误给调用方。
如何做一个超时控制呢?
通过select来实现。
实例:
package main import (
"fmt"
"time"
) func queryDb(ch chan int) {
time.Sleep(time.Second)
ch <-
}
func main() {
ch := make(chan int)
go queryDb(ch) //起了1个goroutine,异步查询db,传入一个channel进去(异步的线程查询完,会将结果放入到channel中)。
t := time.NewTicker(time.Second)
select { //主线程进行查询,如果channel中有数据,就会去指定分支,如果没有也会去指定分支
case v := <-ch:
fmt.Println("result", v)
case <-t.C: //超过1秒,就会触发该分支,上面channel中还有数据的话,就会走如下分支,也就是超时了。
fmt.Println("timeout")
}
}
执行结果:

十五、goroutine中使用recover
应用场景,如果某个goroutine panic了,而且这个goroutine里面没有捕获(recover), 那么整个进程就会挂掉。所以,好的习惯是每当go产生一个goroutine,就需要写下recover。
首先我们来模拟一下这种情况:
实例:
package main import (
"fmt"
"time"
) func main() {
go func() {
var p *int
*p =
fmt.Printf("hello")
}() var i int
for {
fmt.Printf("%d\n", i)
time.Sleep(time.Second)
}
}
执行结果:

解释:
我们可以看到匿名函数所在的goroutine线程因为打印了一个空指针导致panic了,进而最终导致主线程也panic了。
所以我们该如何取捕获(recover)子线程的panic,使其不影响主线程的运行呢?
如何解决是很重要的,比如web应用场景,不能因为一个web请求挂掉而影响其他的web请求导致服务崩掉。下面我们来看一看解决方案:
解决方案:
通过recover函数来捕获goroutine内的任何异常。
实例如下:
package main import (
"fmt"
"time"
) func main() {
go func() {
defer func() { //捕获异常
err := recover() //调用recover函数来做
if err != nil {
fmt.Printf("catch panic exception err:%v\n", err)
}
}()
var p *int
*p =
fmt.Printf("hello")
}() var i int
for {
fmt.Printf("%d\n", i)
time.Sleep(time.Second)
}
}
执行结果:
可以看到通过捕获(recover)goroutine的panic异常后,只会影响panic的goroutine,并不会影响到其他goroutine和主线程。
总结:
所以之后我们需要养成一个好的习惯,每起一个goroutine时,需要捕获一下异常,相当于记一个日志错误,这样我们也可以通过这个错误日志知道程序出问题在哪里,也可以去修复了
Go语言基础之12--Channel的更多相关文章
- Coursera课程笔记----计算导论与C语言基础----Week 12
期末编程测试(Week 12) Quiz1 判断闰年 #include <iostream> using namespace std; int main() { int year; cin ...
- GO学习-(12) Go语言基础之函数
Go语言基础之函数 函数是组织好的.可重复使用的.用于执行指定任务的代码块.本文介绍了Go语言中函数的相关内容. 函数 Go语言中支持函数.匿名函数和闭包,并且函数在Go语言中属于"一等公民 ...
- 【GoLang】GO语言系列--002.GO语言基础
002.GO语言基础 1 参考资料 1.1 http://www.cnblogs.com/vimsk/archive/2012/11/03/2736179.html 1.2 https://githu ...
- Go语言基础之函数
Go语言基础之函数 函数是组织好的.可重复使用的.用于执行指定任务的代码块.本文介绍了Go语言中函数的相关内容. 函数 Go语言中支持函数.匿名函数和闭包,并且函数在Go语言中属于“一等公民”. 函数 ...
- D14——C语言基础学PYTHON
C语言基础学习PYTHON——基础学习D14 20180919内容纲要: 1.html认识 2.常用标签 3.京东html 4.小结 5.练习(简易淘宝html) 1.html初识(HyperText ...
- 20155327 学习基础和C语言基础调查
20155327 学习基础和C语言基础调查 通过阅读老师推荐的五篇文章之后,其中有几个点引发了我的思考,便是"量变引起质变""循序渐进"以及"坚持&q ...
- 《MSSQL2008技术内幕:T-SQL语言基础》读书笔记(下)
索引: 一.SQL Server的体系结构 二.查询 三.表表达式 四.集合运算 五.透视.逆透视及分组 六.数据修改 七.事务和并发 八.可编程对象 五.透视.逆透视及分组 5.1 透视 所谓透视( ...
- 《MSSQL2008技术内幕:T-SQL语言基础》读书笔记(上)
索引: 一.SQL Server的体系结构 二.查询 三.表表达式 四.集合运算 五.透视.逆透视及分组 六.数据修改 七.事务和并发 八.可编程对象 一.SQL Server体系结构 1.1 数据库 ...
- C#语言基础
第一部分 了解C# C#是微软公司在2000年7月发布的一种全新且简单.安全.面向对象的程序设计语言,是专门为.NET的应用而开发的.体现了当今最新的程序设计技术的功能和精华..NET框架为C#提供了 ...
- C语言基础回顾
第一章 C语言基础 1. C语言编译过程 预处理:宏替换.条件编译.头文件包含.特殊符号 编译.优化:翻译并优化成等价的中间代码表示或汇编代码 汇编:生成目标文件,及与源程序等效的目标的机器语言代码 ...
随机推荐
- MyBatis总结一:快速入门
简介 MyBatis 是一款优秀的持久层框架,它支持定制化 SQL.存储过程以及高级映射.MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集.MyBatis 可以使用简单的 ...
- 解决swfupload改变display属性后flash重新加载的问题(chome,safari内核的所有浏览器)
最近在做的项目中有要用到上传控件,所有就用到了swfupload flash上传控件 因为在项目中要使用到Tab控件,tab控件通过改变display属性来控制tab页的显 示与隐藏.当swfuplo ...
- Spring_02 注入类型值、利用引用注入类型值、spring表达式、与类相关的注解、与依赖注入相关的注解、注解扫描
注意:注入基本类型值在本质上就是依赖注入,而且是利用的set方式进行的依赖注入 1 注入基本类型的值 <property name="基本类型的成员变量名" value=&q ...
- Python Matplotlib.plot Update image Questions
1. 最近在测试一款设备,采集了一些设备后需要一帧一帧显示图像,经常使用Python,所以选用了Matplotlib进行图像操作 数据结构: timesatamp polar_distance hor ...
- Entity Framework Tutorial Basics(11):Code First
Code First development with Entity Framework: Entity Framework supports three different development ...
- 浅谈assert()函数的用法
#include<stdio.h> #include<assert.h> char * Strcpy(char *dst,const char *src) { assert(d ...
- kaggle Cross-Validation
The Cross-Validation Procedure In cross-validation, we run our modeling process on different subsets ...
- (数组)字符串的回文构词法( anagrams)
题目:https://www.nowcoder.com/practice/e84e273b31e74427b2a977cbfe60eaf4?tpId=46&tqId=29130&tPa ...
- android 应用间共享数据,调用其他app数据资源
在Android里面每个app都有一个唯一的linux user ID,则这样权限就被设置成该应用程序的文件只对该用户可见,只对该应用程序自身可见:而我们可以使他们对其他的应用程序可见,可以通过Sha ...
- jQuery 插件开发——GridData(表格)第二版
开发背景 表格插件之前我也写个一篇,当时写那个插件的时候,我自己还没有总结出写插件的方法,虽然功能实现了,但是使用起来还是有点别扭的,并且需要在调用写添加特定名称的方法,这个地方着实违背了开发插件的易 ...