Spark最简安装
该环境适合于学习使用的快速Spark环境,采用Apache预编译好的包进行安装。而在实际开发中需要使用针对于个人Hadoop版本进行编译安装,这将在后面进行介绍。
Spark预编译安装包下载——Apache版
下载地址:http://spark.apache.org/downloads.html (本例使用的是Spark-2.2.0版本)
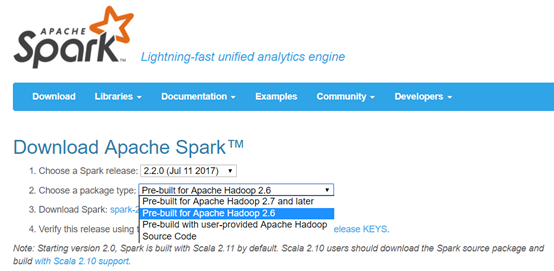
接下来依次执行下载,上传,然后解压缩操作。
[hadoop@masternode ~]$ cd /home/hadoop/app
[hadoop@masternode app]$ rz //上传
选中刚才下载好的Spark预编译好的包,点击上传。
[hadoop@masternode app]$ tar –zxvf spark-2.2.0-bin-hadoop2.6.tgz //解压
[hadoop@masternode app]$ rm spark-2.2.0-bin-hadoop2.6.tgz
[hadoop@masternode app]$ mv spark-2.2.0-bin-hadoop2.6/ spark-2.2.0 //重命名
[hadoop@masternode app]$ ll
total 24
drwxrwxr-x. 7 hadoop hadoop 4096 Aug 23 16:32 elasticsearch-2.4.0
drwxr-xr-x. 10 hadoop hadoop 4096 Apr 20 13:59 hadoop
drwxr-xr-x. 8 hadoop hadoop 4096 Aug 5 2015 jdk1.8.0_60
drwxrwxr-x. 11 hadoop hadoop 4096 Nov 4 2016 kibana-4.6.3-linux-x86_64
drwxr-xr-x. 12 hadoop hadoop 4096 Jul 1 2017 spark-2.2.0
drwxr-xr-x. 14 hadoop hadoop 4096 Apr 19 10:00 zookeeper
[hadoop@masternode app]$ cd spark-2.2.0/
[hadoop@masternode spark-2.2.0]$ ll
total 104
drwxr-xr-x. 2 hadoop hadoop 4096 Jul 1 2017 bin
drwxr-xr-x. 2 hadoop hadoop 4096 Jul 1 2017 conf
drwxr-xr-x. 5 hadoop hadoop 4096 Jul 1 2017 data
drwxr-xr-x. 4 hadoop hadoop 4096 Jul 1 2017 examples
drwxr-xr-x. 2 hadoop hadoop 12288 Jul 1 2017 jars
-rw-r--r--. 1 hadoop hadoop 17881 Jul 1 2017 LICENSE
drwxr-xr-x. 2 hadoop hadoop 4096 Jul 1 2017 licenses
-rw-r--r--. 1 hadoop hadoop 24645 Jul 1 2017 NOTICE
drwxr-xr-x. 6 hadoop hadoop 4096 Jul 1 2017 python
drwxr-xr-x. 3 hadoop hadoop 4096 Jul 1 2017 R
-rw-r--r--. 1 hadoop hadoop 3809 Jul 1 2017 README.md
-rw-r--r--. 1 hadoop hadoop 128 Jul 1 2017 RELEASE
drwxr-xr-x. 2 hadoop hadoop 4096 Jul 1 2017 sbin
drwxr-xr-x. 2 hadoop hadoop 4096 Jul 1 2017 yarn
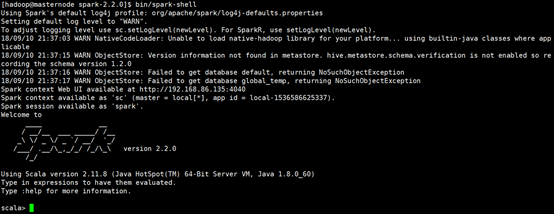
如图所示,可以进入Spark Shell模式,表示安装正常。
Spark目录介绍
1.bin 运行脚本目录
beeline
find-spark-home
load-spark-env.sh //加载spark-env.sh中的配置信息,确保仅会加载一次
pyspark //启动python spark shell,./bin/pyspark --master local[]
run-example //运行example
spark-class //内部最终变成用java运行java类
sparkR
spark-shell //启动scala spark shell,./bin/spark-shell --master local[]
spark-sql
spark-submit //提交作业到master
运行example
# For Scala and Java, use run-example:
./bin/run-example SparkPi
# For Python examples, use spark-submit directly:
./bin/spark-submit examples/src/main/python/pi.py
# For R examples, use spark-submit directly:
./bin/spark-submit examples/src/main/r/dataframe.R2.conf
docker.properties.template
fairscheduler.xml.template
log4j.properties.template //集群日志模版
metrics.properties.template
slaves.template //worker 节点配置模版
spark-defaults.conf.template //SparkConf默认配置模版
spark-env.sh.template //集群环境变量配置模版
3.data (例子里用到的一些数据)
graphx
mllib
streaming
4.examples 例子源码
jars
src
5.jars (spark依赖的jar包)
6.licenses (license协议声明文件)
7.python
8.R
9.sbin (集群启停脚本)
slaves.sh //在所有定义在${SPARK_CONF_DIR}/slaves的机器上执行一个shell命令
spark-config.sh //被其他所有的spark脚本所包含,里面有一些spark的目录结构信息
spark-daemon.sh //将一条spark命令变成一个守护进程
spark-daemons.sh //在所有定义在${SPARK_CONF_DIR}/slaves的机器上执行一个spark命令
start-all.sh //启动master进程,以及所有定义在${SPARK_CONF_DIR}/slaves的机器上启动Worker进程
start-history-server.sh //启动历史记录进程
start-master.sh //启动spark master进程
start-mesos-dispatcher.sh
start-mesos-shuffle-service.sh
start-shuffle-service.sh
start-slave.sh //启动某机器上worker进程
start-slaves.sh //在所有定义在${SPARK_CONF_DIR}/slaves的机器上启动Worker进程
start-thriftserver.sh
stop-all.sh //在所有定义在${SPARK_CONF_DIR}/slaves的机器上停止Worker进程
stop-history-server.sh //停止历史记录进程
stop-master.sh //停止spark master进程
stop-mesos-dispatcher.sh
stop-mesos-shuffle-service.sh
stop-shuffle-service.sh
stop-slave.sh //停止某机器上Worker进程
stop-slaves.sh //停止所有worker进程
stop-thriftserver.sh
10.yarn
spark-2.1.-yarn-shuffle.jar
Spark example
下面运行一个官网的小example。
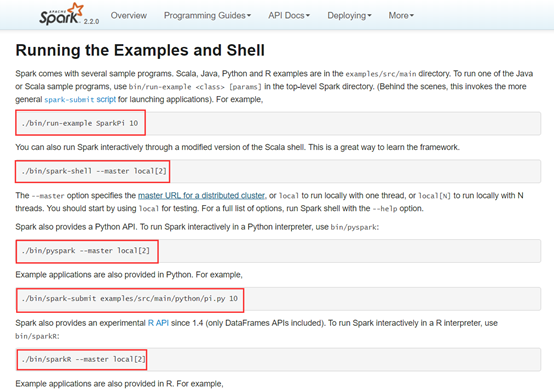
可以看到官网给出了详细的运行指令,我们运行第一个,算一下Pi的值。
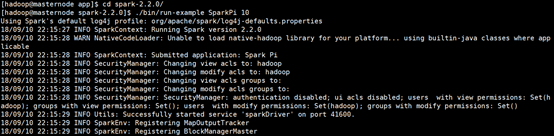
运算结果如下图所示:
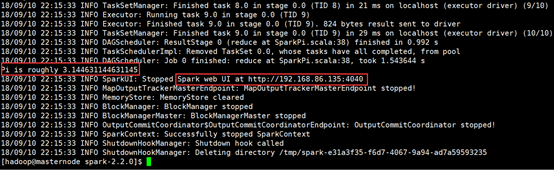
并且,如上图所示,我们可以根据图中URL地址查看web UI情况。

注意:此地址只能是在运行过程中才能查看的哦!
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
Spark最简安装的更多相关文章
- [bigdata] spark集群安装及测试
在spark安装之前,应该已经安装了hadoop原生版或者cdh,因为spark基本要基于hdfs来进行计算. 1. 下载 spark: http://mirrors.cnnic.cn/apache ...
- Win7 单机Spark和PySpark安装
欢呼一下先.软件环境菜鸟的我终于把单机Spark 和 Pyspark 安装成功了.加油加油!!! 1. 安装方法参考: 已安装Pycharm 和 Intellij IDEA. win7 PySpark ...
- spark集群安装配置
spark集群安装配置 一. Spark简介 Spark是一个通用的并行计算框架,由UCBerkeley的AMP实验室开发.Spark基于map reduce 算法模式实现的分布式计算,拥有Hadoo ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- [软件开发技巧]·树莓派极简安装OpenCv
树莓派极简安装OpenCv 个人主页–> https://xiaosongshine.github.io/ 因为最近在开发使用树莓派+usb摄像头识别模块,打算用OpenCv,发现网上的树莓派O ...
- [深度学习工具]·极简安装Dlib人脸识别库
[深度学习工具]·极简安装Dlib人脸识别库 Dlib介绍 Dlib是一个现代化的C ++工具箱,其中包含用于在C ++中创建复杂软件以解决实际问题的机器学习算法和工具.它广泛应用于工业界和学术界,包 ...
- Spark学习笔记——安装和WordCount
1.去清华的镜像站点下载文件spark-2.1.0-bin-without-hadoop.tgz,不要下spark-2.1.0-bin-hadoop2.7.tgz 2.把文件解压到/usr/local ...
- CentOS6安装各种大数据软件 第十章:Spark集群安装和部署
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- hadoop环境的安装 和 spark环境的安装
hadoop环境的安装1.前提:安装了java spark环境的安装1.前提:安装了java,python2.直接pip install pyspark就可以安装完成.(pip是python的软件安装 ...
随机推荐
- POJ2080:Calendar(计算日期)
Calendar Time Limit: 1000MS Memory Limit: 30000K Total Submissions: 12842 Accepted: 4641 Descrip ...
- HDU1698(线段树入门题)
Just a Hook Time Limit:2000MS Memory Limit:32768KB 64bit IO Format:%I64d & %I64u Descrip ...
- hibernate 数据关联一对多
一对多,多对一 (在多的一端存放一的外键) 但是在实体类中不需要创建这个外键 // 在一的一方创建Set集合 public class User { private Integer id; priva ...
- Break 、Continue 和ReadOnly、Const和Ref和Out params
Break和Continue区别 之前对于Break和Continue:ReadOnly和Const:ref和out,params之类的基础东东学习过,但是一直没有仔细去研究到底是怎么一回事儿,最近在 ...
- Math类简介
Math abs max min 分别是绝对值 最大值,最小值 round 四舍五入 ceil ceil(32.6) 33.0 ceil(32.2) 33.0 返回大于该数值的较大的整数 与之相对 ...
- Matlab零碎知识
1.不定积分的求取 int syms x;%为自变量 f=x.^2; s=int(f,x); 其中显示辅助函数simple()和pretty()
- Dialog 自定义使用1
一: 布局文件 <?xml version="1.0" encoding="utf-8"?> <LinearLayout xmlns:andr ...
- [MySQL] Data too long for column 'title' at row 1
李刚轻量级JavaEE第六章的坑..艹李刚自己有没试过这些代码的啊,6.4这一份HqlQuery.java里需要的表,根本就跟他提供的sql脚本对不上啊..坑爹啊,而且字符编码集也有问题. 出现这个原 ...
- Swoole 整合成一个小框架
目录 概述 效果 代码 小结 概述 这是关于 Swoole 学习的第六篇文章:Swoole 整合成一个小框架. 第五篇:Swoole 多协议 多端口 的应用 第四篇:Swoole HTTP 的应用 第 ...
- Codeforces - 1181B - Split a Number - 贪心
https://codeforces.com/contest/1181/problem/B 从中间拆开然后用大数搞一波. 当时没想清楚奇偶是怎么弄,其实都可以,奇数长度字符串的中心就在len/2,偶数 ...