Flume推送数据到SparkStreaming案例实战和内幕源码解密
本期内容:
1. Flume on HDFS案例回顾
2. Flume推送数据到Spark Streaming实战
3. 原理绘图剖析
1. Flume on HDFS案例回顾
上节课要求大家自己安装配置Flume,并且测试数据的传输。我昨天是要求传送的HDFS上。
文件配置:
~/.bashrc:
export FLUME_HOME=/usr/local/flume/apache-flume-1.6.0-bin
export FLUME_CONF_DIR=$FLUME_HOME/conf
PATH中增加:${FLUME_HOME}/bin;
拷贝conf/flume-conf.properties.template,更名为conf/flume-cong.properties,只写以下内容:
agent1表示代理名称
agent1.sources=source1
agent1.sinks=sink1
agent1.channels=channel1
#配置source1
agent1.sources.source1.type=spooldir
agent1.sources.source1.spoolDir=/usr/local/flume/tmp/TestDir
agent1.sources.source1.channels=channel1
agent1.sources.source1.fileHeader = false
agent1.sources.source1.interceptors = i1
agent1.sources.source1.interceptors.i1.type = timestamp
#配置sink1
agent1.sinks.sink1.type=hdfs
agent1.sinks.sink1.hdfs.path=hdfs://master:9000/library/flume
agent1.sinks.sink1.hdfs.fileType=DataStream
agent1.sinks.sink1.hdfs.writeFormat=TEXT
agent1.sinks.sink1.hdfs.rollInterval=1
agent1.sinks.sink1.channel=channel1
agent1.sinks.sink1.hdfs.filePrefix=%Y-%m-%d
#agent1.sinks.sink1.type=avro
#agent1.sinks.sink1.channel=channel1
#agent1.sinks.sink1.hostname=Master
#agent1.sinks.sink1.port=9999
#配置channel1
agent1.channels.channel1.type=file
agent1.channels.channel1.checkpointDir=/usr/local/flume/tmp/checkpointDir
agent1.channels.channel1.dataDirs=/usr/local/flume/tmp/dataDirs
flume-env.sh配置:
# export JAVA_HOME=/usr/lib/jvm/java-6-sun
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_60
# Give Flume more memory and pre-allocate, enable remote monitoring via JMX
# export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"
export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"
建立文件夹 /usr/local/flume/tmp/TestDir。
在hdfs上建立/library/flume文件夹。
flume的bin文件夹下启动Flume:
./flume-ng agent -n agent1 -c conf -f /usr/local/flume/apache-flume-1.6.0-bin/conf/flume-conf.properties -Dflume.root.logger=DEBUG,console
在/usr/local/flume/tmp/TestDir下,拷入测试用的文件,比如:NOTICE
flume 控制台会有一些相关信息:
16/04/22 11:03:49 INFO avro.ReliableSpoolingFileEventReader: Preparing to move file /usr/local/flume/tmp/TestDir/NOTICE to /usr/local/flume/tmp/TestDir/NOTICE.COMPLETED
16/04/22 11:03:51 INFO hdfs.HDFSDataStream: Serializer = TEXT, UseRawLocalFileSystem = false
16/04/22 11:03:51 INFO hdfs.BucketWriter: Creating hdfs://master:9000/library/flume/2016-04-22.1461294231806.tmp
16/04/22 11:03:52 INFO hdfs.BucketWriter: Closing hdfs://master:9000/library/flume/2016-04-22.1461294231806.tmp
16/04/22 11:03:52 INFO hdfs.BucketWriter: Renaming hdfs://master:9000/library/flume/2016-04-22.1461294231806.tmp to hdfs://master:9000/library/flume/2016-04-22.1461294231806
可以发现本地的NOTICE文件更名为NOTICE.COMPLETED。
用浏览器查询:http://localhost:50070/explorer.html#/library/flume,可看到Flume把NOTICE文件传送到 HDFS的/library/flume下,文件名为 2016-04-22.1461294231806。打开文件看内容可以验证。说明当Flume指定的源文件夹中有新文件时,Flume会自动将此文件,导入到Flume配置时指定的HDFS文件夹中。
一般正常业务情况下,应该是把Flume的数据放到Kafka中,然后让不同的数据消费者去消费数据。如果要在Flume和Kafka两者间做选择的话,则要看业务中数据是否持续不断的产生。如果是这样,则应该选择Kafka。如果产生的数据时大时小,甚至有些时间没有数据,则没必要用Kafka,可以节省资源。
2. Flume推送数据到Spark Streaming实战
现在我们不把Flume的数据导入到HDFS中,而是把数据推送到Spark Streaming中。
修改conf/flume-cong.properties文件,改导入到HDFS,变为推送到Spark Streaming。
#配置sink1
#agent1.sinks.sink1.type=hdfs
#agent1.sinks.sink1.hdfs.path=hdfs://master:9000/library/flume
#agent1.sinks.sink1.hdfs.fileType=DataStream
#agent1.sinks.sink1.hdfs.writeFormat=TEXT
#agent1.sinks.sink1.hdfs.rollInterval=1
#agent1.sinks.sink1.channel=channel1
#agent1.sinks.sink1.hdfs.filePrefix=%Y-%m-%d
agent1.sinks.sink1.type=avro
agent1.sinks.sink1.channel=channel1
agent1.sinks.sink1.hostname=Master
agent1.sinks.sink1.port=9999
编写Spark Streaming应用的Java程序:
public class FlumePushData2SparkStreaming {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local[4]").setAppName("FlumePushDate2SparkStreaming");
JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(30));
JavaReceiverInputDStream lines = FlumeUtils.createStream(jsc,"Master", 9999);
// 注意此处输入的event类型是SparkFlumeEvent类型。
JavaDStream<String> words = lines.flatMap(new FlatMapFunction<SparkFlumeEvent, String>() {
@Override
public Iterable<String> call(SparkFlumeEvent event) throws Exception {
String line = new String(event.event().getBody().array());
return Arrays.asList(line.split(" "));
}
});
JavaPairDStream<String, Integer> pairs = words.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word, 1);
}
});
JavaPairDStream<String, Integer> wordsCount = pairs.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
wordsCount.print();
jsc.start();
jsc.awaitTermination();
jsc.close();
}
}
代码中用到了FlumeUtils。我们剖析一下代码中用到的FlumeUtils。
以上代码中FlumeUtil的方法createStream:
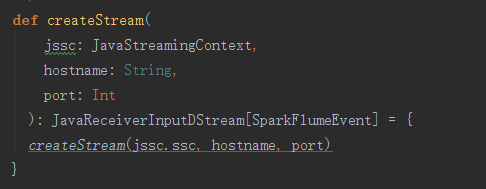
实际是调用以下createStream方法:
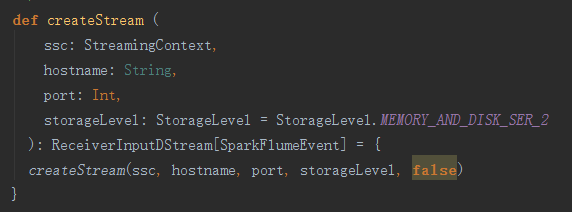
可以看到流处理默认的存储方式是,既在内存,又在磁盘中,同时做序列化,而且用两台机器。
继续看调用的createStream方法:

实际上返回的是FlumeInputDStream对象,而且事件是Flume所定义的事件SparkFlumeEvent。所以要注意,在以上Java代码做flatMap时,FlatMapFunction的输入类型必须是SparkFlumeEvent类型。
再看看FlumeInputDStream的代码:
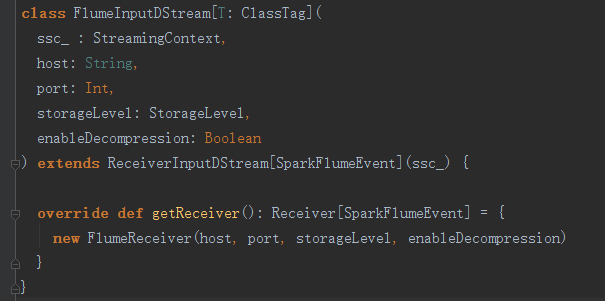
可以看到getReceiver返回的是用于接收数据的FlumeReceiver对象。再看FlumeReceiver:

可以发现Flume使用了Netty。如果搞分布式编程,要重视使用Netty。
把以上的应用Spark Streaming的Java程序运行起来。确认Flume也在运行。
我们找若干文件拷入TestDir文件夹,比如:flume下的若干文本文件。那么在Java运行的控制台,可以发现以下信息:

说明Flume推送数据到了Spark Streaming,Spark Streaming对数据及时进行了处理。
3. 原理绘图剖析

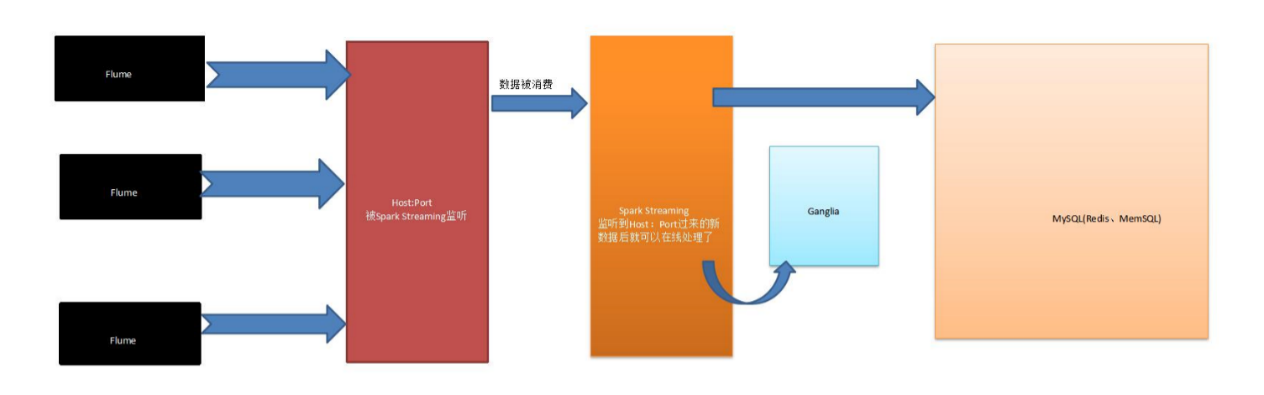
总结:
备注:87课
更多私密内容,请关注微信公众号:DT_Spark
Flume推送数据到SparkStreaming案例实战和内幕源码解密的更多相关文章
- 基于HDFS的SparkStreaming案例实战和内幕源码解密
一:Spark集群开发环境准备 启动HDFS,如下图所示: 通过web端查看节点正常启动,如下图所示: 2.启动Spark集群,如下图所示: 通过web端查看集群启动正常,如下图所示: 3.启动sta ...
- Spark Streaming updateStateByKey案例实战和内幕源码解密
本节课程主要分二个部分: 一.Spark Streaming updateStateByKey案例实战二.Spark Streaming updateStateByKey源码解密 第一部分: upda ...
- Spark Streaming从Flume Poll数据案例实战和内幕源码解密
本节课分成二部分讲解: 一.Spark Streaming on Polling from Flume实战 二.Spark Streaming on Polling from Flume源码 第一部分 ...
- SQL Server 2000向SQL Server 2008 R2推送数据
[文章摘要]最近做的一个项目要获取存在于其他服务器的一些数据,为了安全起见,采用由其他“服务器”向我们服务器推送的方式实现.我们服务器使用的是SQL Server 2008 R2,其他“服务器”使用的 ...
- WebService推送数据,数据结构应该怎样定义?
存放在Session有一些弊端,不能实时更新.server压力增大等... 要求:将从BO拿回来的数据存放在UI Cache里面,数据库更新了就通过RemoveCallback "告诉&qu ...
- java接口对接——调用别人接口推送数据
实际开发中经常会遇到要和其他平台或系统对接的情况,实际操作就是互相调用别人的接口获取或者推送数据, 当我们调用别人接口推送数据时,需要对方给一个接口地址以及接口的规范文档,规范中要包括接口的明确入参及 ...
- SuperSocket主动从服务器端推送数据到客户端
关键字: 主动推送, 推送数据, 客户端推送, 获取Session, 发送数据, 回话快照 通过Session对象发送数据到客户端 前面已经说过,AppSession 代表了一个逻辑的 socke ...
- httpclient post推送数据
客户端代码 /** * 从接口获取数据 * @param url 服务器接口地址 * @param json 传入的参数 若获取全部,此项为空 * @return 返回查询到的数据 * @throws ...
- Asp.net Core3.1+Vue 使用SignalR推送数据
本文就简单使用 往前端页面推送消息 SignalR 是什么 SignalR是一个.NET Core/.NET Framework的开源实时框架. SignalR的可使用Web Socket, Serv ...
随机推荐
- [bzoj3270] 博物馆 [期望+高斯消元]
题面 传送门 思路 本题的点数很少,只有20个 考虑用二元组$S=(u,v)$表示甲在$u$点,乙在$v$点的状态 那么可以用$f(S)$表示状态$S$出现的概率 不同的$f$之间的转移就是通过边 转 ...
- 枪战(maf)
枪战(maf) settle the dispute. Negotiations were very tense, and at one point the trigger-happy partici ...
- 【linux高级程序设计】(第十一章)System V进程间通信 2
消息队列 消息队列是消息的链式队列,模型如下: 包括两种数据结构: msqid_ds消息队列数据结构 msg消息队列数据结构 struct msg_msg{ struct list_head m_li ...
- Selenium2+python自动化11-定位一组元素find_elements【转载】
前言 前面的几篇都是讲如何定位一个元素,有时候一个页面上有多个对象需要操作,如果一个个去定位的话,比较繁琐,这时候就可以定位一组对象. webdriver 提供了定位一组元素的方法,跟前面八种定位方式 ...
- hdu 3047(扩展并查集)
Zjnu Stadium Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Tota ...
- Centos查看文件夹大小
查看当前目录下文件夹大小 du -h --max-depth=1 查看整体情况 df -h
- 【原创】Oracle 11g R2 Client安装配置说明(多图详解)
1. 准备工作 安装Oracle11gR2client的时候,如果刚从网上下载的Oracle client,可能无法再2008 R2或者2012 R2的服务器上面运行. 报错:[INS-13001]环 ...
- 部署站点支持Https访问的方法
1.申请公钥和私钥,放到服务器 2.编辑default配置文件 改为 加上证书路径 ps:泛域名支持admin.xxx.com.demo.xxx.com等等,而免费的Let's Encrypt仅支持w ...
- 树莓派3b入门教程
原文地址:传送门 这篇教程将带您一起玩转树莓派3(Raspberry Pi 3).和普通PC一样,拿到新设备第一件事就是要给它安装一个操作系统,并做一些初始化的操作.比PC简单的是,树莓派是一个固定配 ...
- Python的程序结构[1] -> 方法/Method[0] -> 类实例方法、私有方法和抽象方法
类实例方法.私有方法和抽象方法 Python中最常用的就是类实例方法,类似于属性中的类实例属性,同时,也存在与私有属性类似方法,即私有方法,下面介绍这两种常见的方法,以及一种特殊意义的类实例方法 -- ...