ElasticSearch相关概念与客户端操作
一、Elasticsearch概述

二、 Elasticsearch核心概念
1、索引 index
2、类型 type
3、字段Field
4、映射 mapping
5、文档 document
6、接近实时 NRT
7、集群 cluster
8、节点 node
9、 分片和复制 shards&replicas
三、ElasticSearch的客户端操作
1、自行安装postman工具
2、使用Postman工具进行Restful接口访问
curl ‐X<VERB> '<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>' ‐d '<BODY>'

四、添加索引库
1、请求方式:PUT http://ip:9200/索引库名称

2、利用PUT发送添加索引库请求,指定请求体为raw
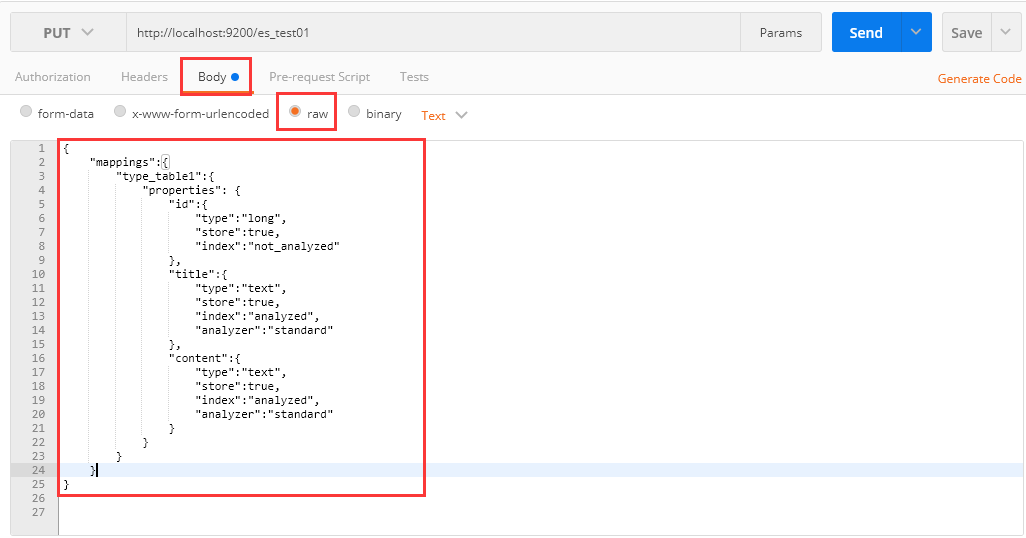
请求体:
{
"mappings":{
"type_table1":{
"properties": {
"id":{
"type":"long",
"store":true,
"index":"not_analyzed"
},
"title":{
"type":"text",
"store":true,
"index":"analyzed",
"analyzer":"standard"
},
"content":{
"type":"text",
"store":true,
"index":"analyzed",
"analyzer":"standard"
}
}
}
}
}
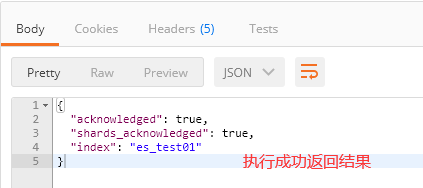
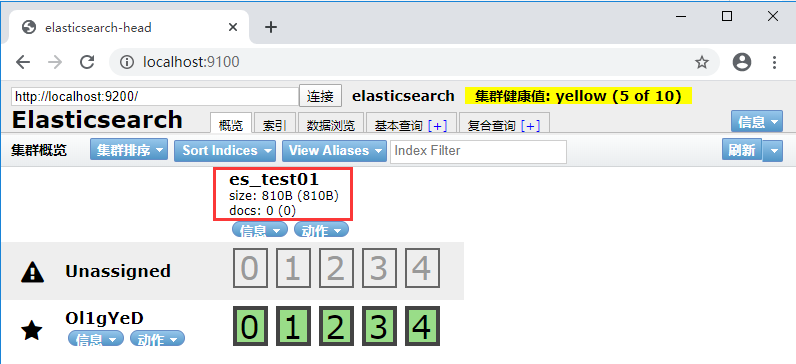
3、查看索引信息

四、修改索引库
1、创建一个索引库不指定mapping信息
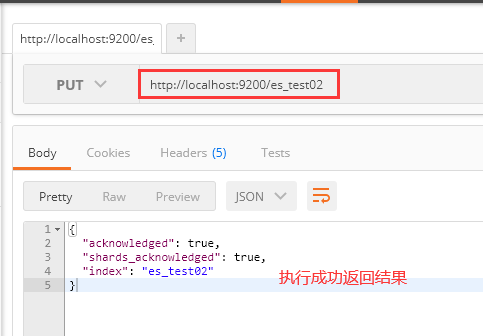
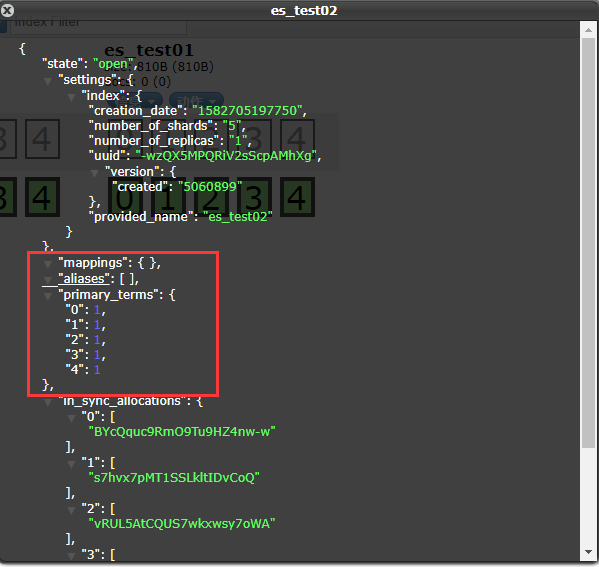
2、POST请求 http://127.0.0.1:9200/es_test02/type_table1/_mapping
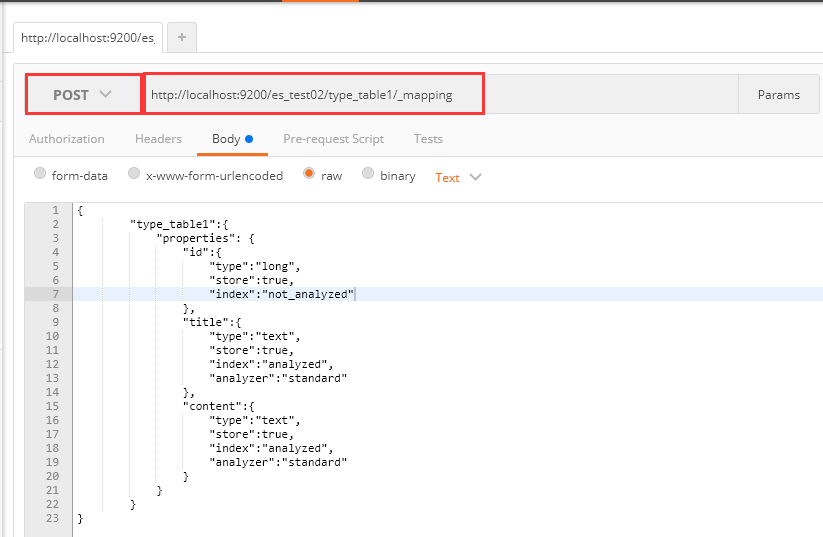

请求体:
{
"type_table1":{
"properties": {
"id":{
"type":"long",
"store":true,
"index":"not_analyzed"
},
"title":{
"type":"text",
"store":true,
"index":"analyzed",
"analyzer":"standard"
},
"content":{
"type":"text",
"store":true,
"index":"analyzed",
"analyzer":"standard"
}
}
}
}
3、查看效果

五、删除索引库
1、请求方式:DELETE url地址为:localhost:9200/es_test02
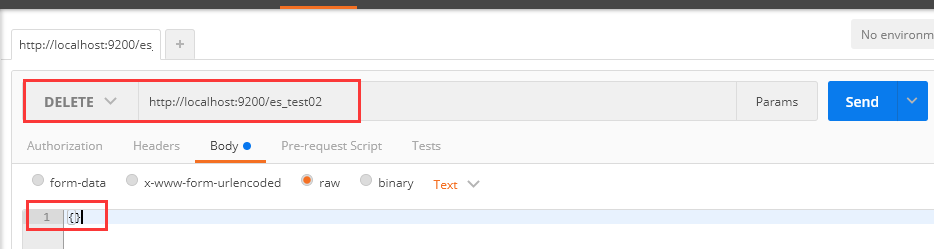
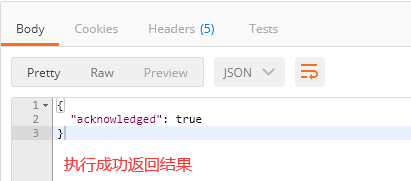
2、删除前效果
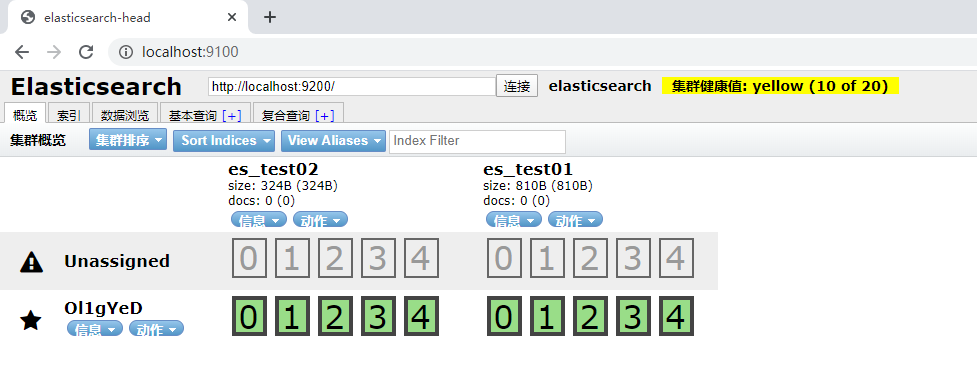
3、删除后效果
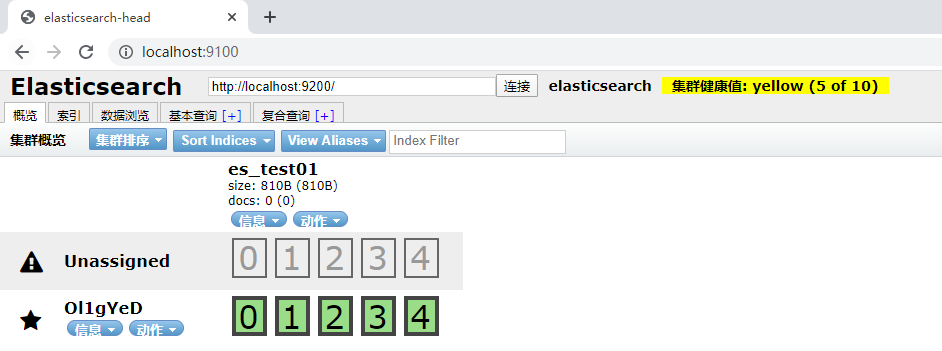
六、创建文档document
1、请求为:POST http://localhost:9200/es_test01/type_table1/1
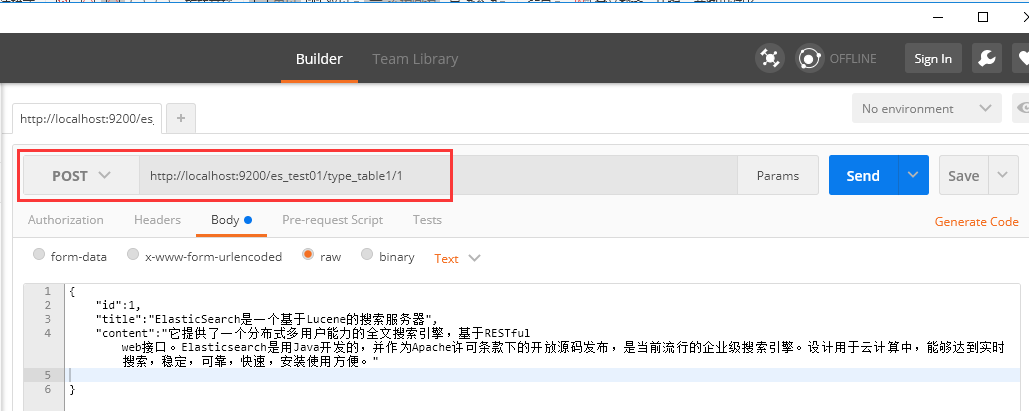

请求体:
{
"id":1,
"title":"ElasticSearch是一个基于Lucene的搜索服务器",
"content":"它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,
是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时 搜索,稳定,可靠,快速,安装使用方便。"
}
2、elasticsearch-head查看
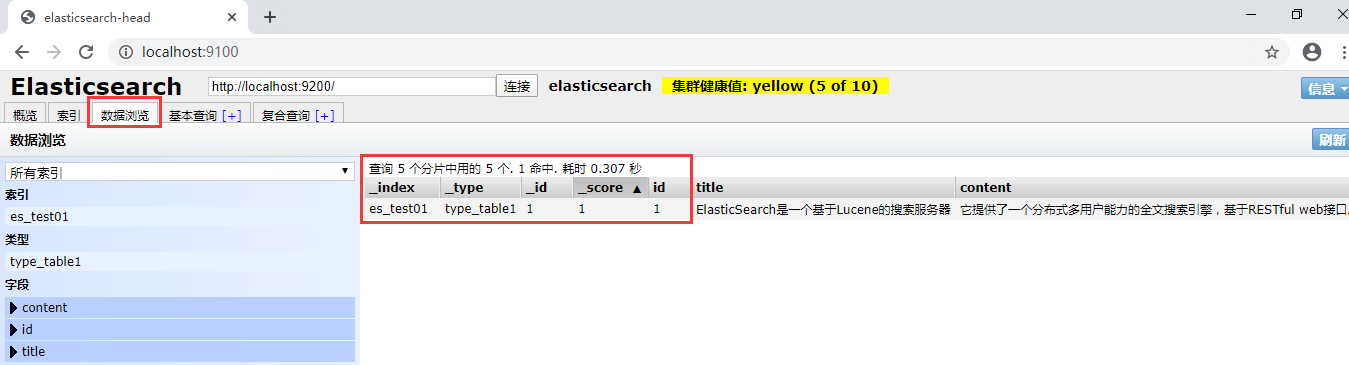
七、修改文档document
1、请求为:POST http://localhost:9200/es_test01/type_table1/1
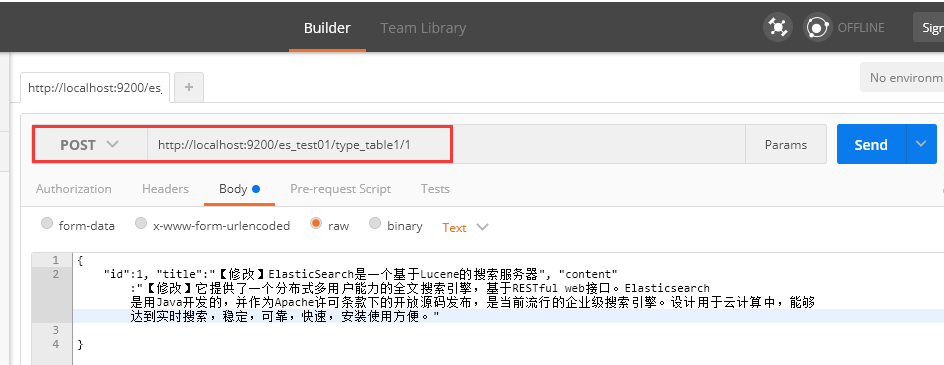
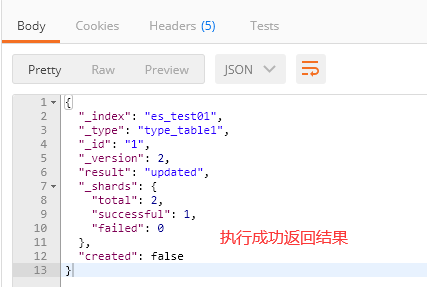
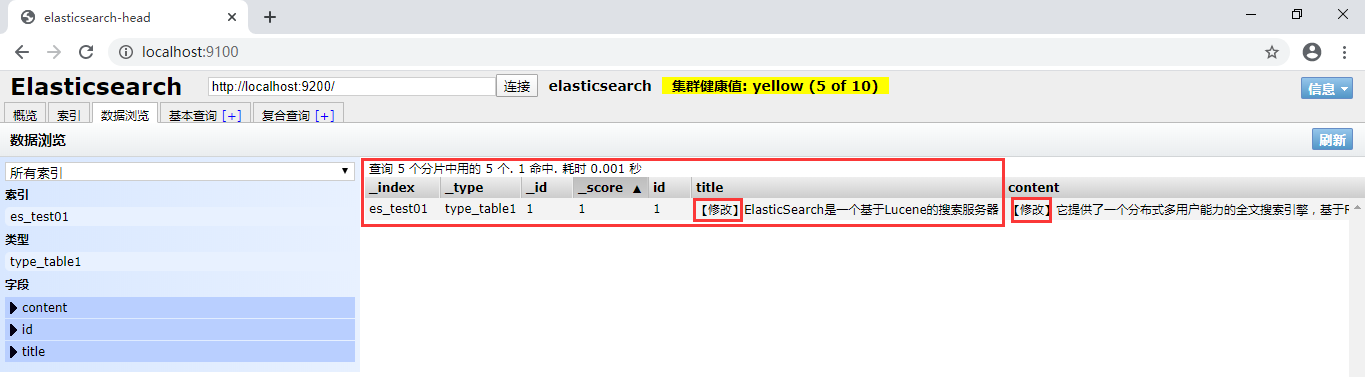
2、elasticsearch-head查看
八、删除文档document
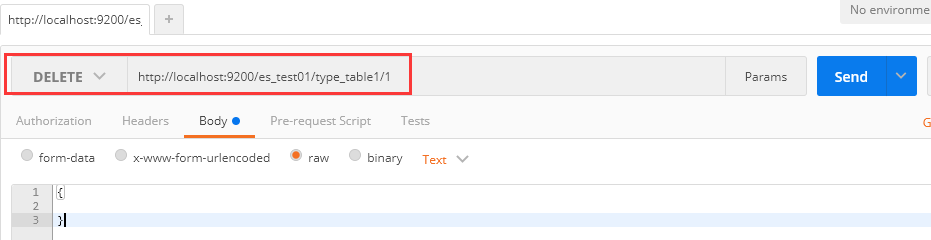
1、请求为:DELETE http://localhost:9200/es_test01/type_table1/1
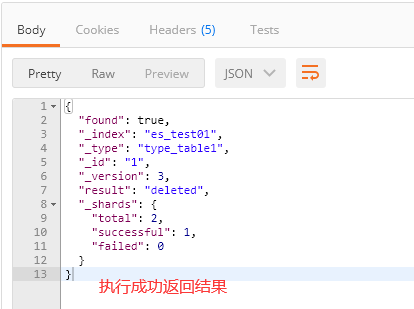
2、elasticsearch-head查看
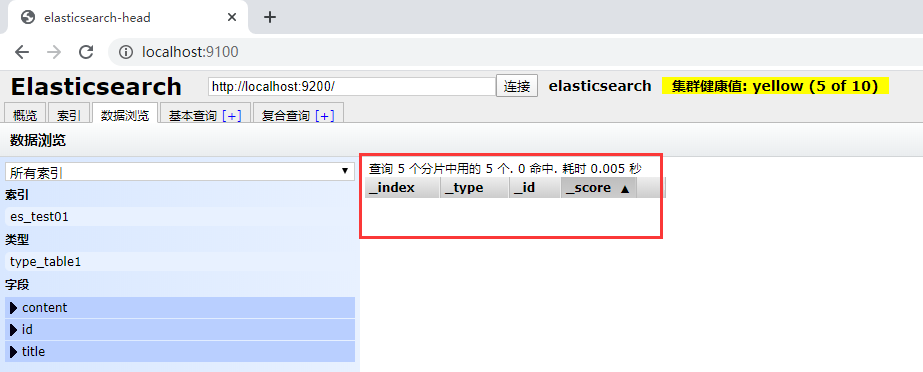
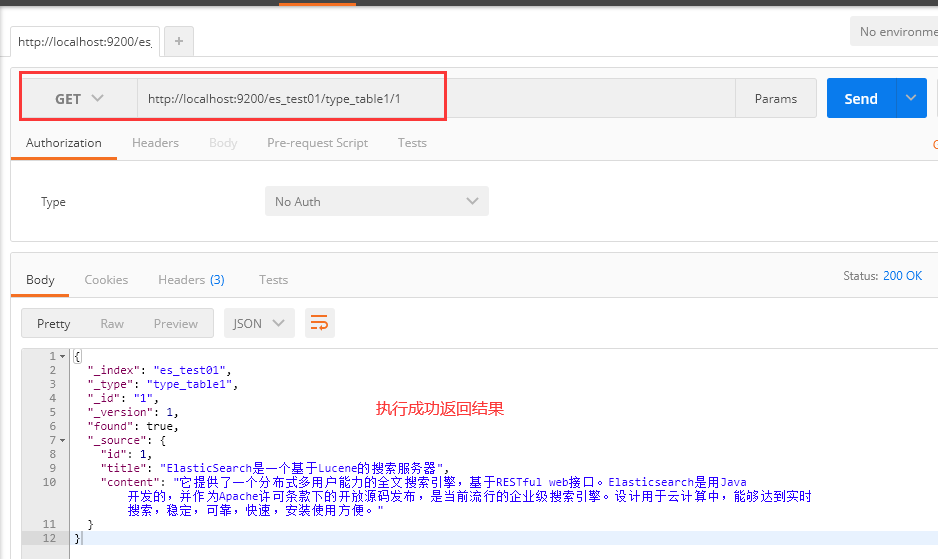
九、查询文档-根据id查询
请求为:GET http://localhost:9200/es_test01/type_table1/1
十、查询文档-querystring查询
1、请求为:POST http://localhost:9200/es_test01/type_table1/_search
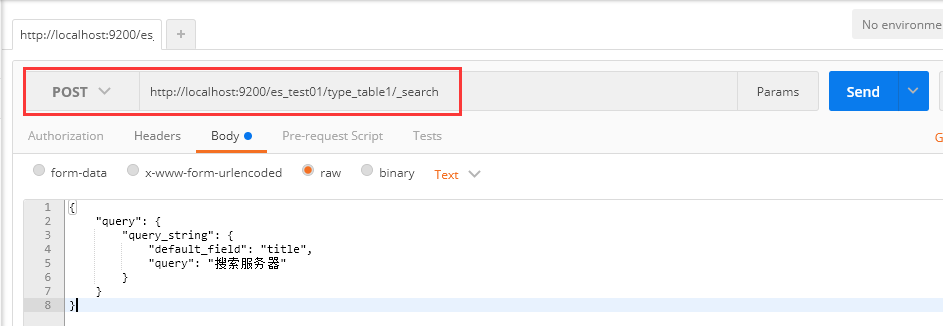
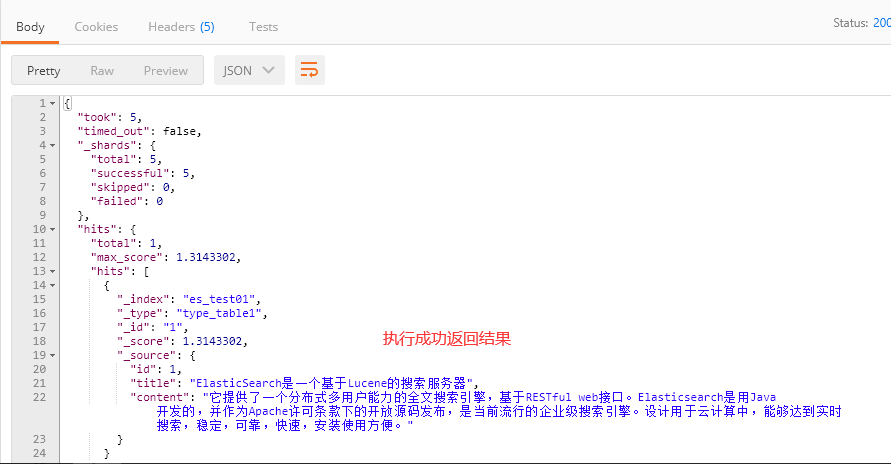
请求体:
{
"query": {
"query_string": {
"default_field": "title",
"query": "搜索服务器"
}
}
}
2、注意
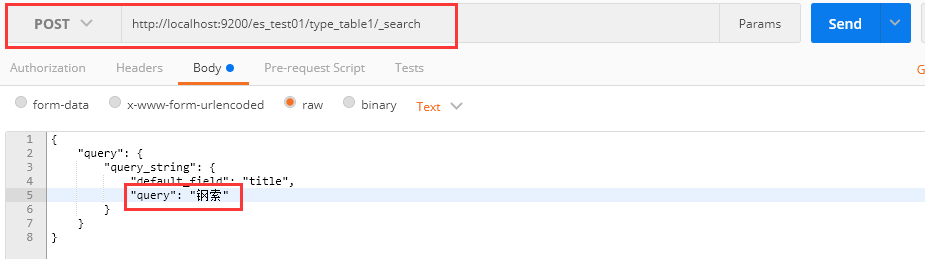
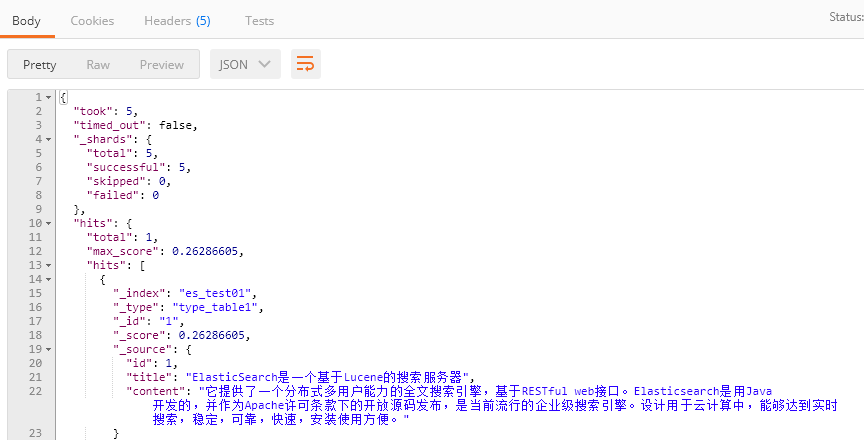
原因:
十一、查询文档-term查询
请求为:POST http://localhost:9200/es_test01/type_table1/_search
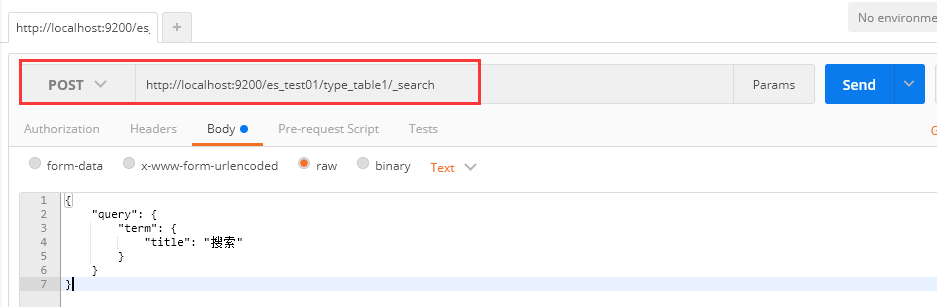
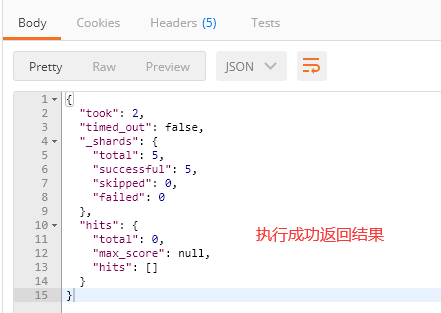
请求体:
{
"query": {
"term": {
"title": "搜索"
}
}
}
注意:term方式查询,因为分词规律所以查询“搜索”返回结果信息为null,添加IK分词器以后便可以查询到!
ElasticSearch相关概念与客户端操作的更多相关文章
- springboot整合es客户端操作elasticsearch(五)
springboot整合es客户端操作elasticsearch的总结: 客户端可以进行可以对所有文档进行查询,就是不加任何条件: SearchRequest searchRequest = new ...
- 使用Java客户端操作elasticsearch(二)
承接上文,使用Java客户端操作elasticsearch,本文主要介绍 常见的配置 和Sniffer(集群探测) 的使用. 常见的配置 前面已介绍过,RestClientBuilder支持同时提供一 ...
- ElasticSearch-命令行客户端操作
1.引言 实际开发中,主要有三种方式可以作为elasticsearch服务的客户端: 第一种,elasticsearch-head插件(可视化工具) 第二种,使用elasticsearch提供的Res ...
- 使用Hive或Impala执行SQL语句,对存储在Elasticsearch中的数据操作(二)
CSSDesk body { background-color: #2574b0; } /*! zybuluo */ article,aside,details,figcaption,figure,f ...
- 使用Hive或Impala执行SQL语句,对存储在Elasticsearch中的数据操作
http://www.cnblogs.com/wgp13x/p/4934521.html 内容一样,样式好的版本. 使用Hive或Impala执行SQL语句,对存储在Elasticsearch中的数据 ...
- HDFS的Java客户端操作代码(HDFS的查看、创建)
1.HDFS的put上传文件操作的java代码: package Hdfs; import java.io.FileInputStream; import java.io.FileNotFoundEx ...
- Elasticsearch索引和文档操作
列出所有索引 现在来看看我们的索引 GET /_cat/indices?v 响应 health status index uuid pri rep docs.count docs.deleted st ...
- java web 获取客户端操作系统信息
package com.java.basic.pattern; import java.util.regex.Matcher; import java.util.regex.Pattern; /** ...
- Hadoop系列007-HDFS客户端操作
title: Hadoop系列007-HDFS客户端操作 date: 2018-12-6 15:52:55 updated: 2018-12-6 15:52:55 categories: Hadoop ...
随机推荐
- Activiti服务任务(serviceTask)
Activiti服务任务(serviceTask) 作者:Jesai 都有一段沉默的时间,等待厚积薄发 应用场景: 当客户有这么一个需求:下一个任务我需要自动执行一些操作,并且这个节点不需要任何的人工 ...
- 「2.0」一个人开发一个App,小程序从0到1,文件剖析
不知你是不是见到“文件剖析”这4个大字,才点进来看一看的?如果真是的话,那我可以坦诚.真心.负责任地告诉你:你上当了,你上了贼船啦,如果你现在想跳的话,还来得及,反正茫茫大海中,鲨鱼正缺搞程序的人.说 ...
- JS中字符串切片
1.charAt 作用:根据索引值获取字符串 s1= "Hello world"; // 根据索引求字符 var myChar = s1.charAt(4); console.lo ...
- Bug的等级程度(Blocker, Critical, Major, Minor/Trivial)及修复优先级
Priority()和Severity(严重程度)是Bug的两个重要属性.很多新人经常混淆这两个概念. 通常,人员在提交Bug时,只定义Bug的Severity, 即该Bug的严重程度, 而将Prio ...
- 「 从0到1学习微服务SpringCloud 」02 Eureka服务注册与发现
系列文章(更新ing): 「 从0到1学习微服务SpringCloud 」01 一起来学呀! Spring Cloud Eureka 基于Netflix Eureka做了二次封装(Spring Clo ...
- MySQL军规升级版(转)
一.基础规范 表存储引擎必须使用InnoDB 表字符集默认使用utf8,必要时候使用utf8mb4 解读:(1)通用,无乱码风险,汉字3字节,英文1字节(2)utf8mb4是utf8的超集,有存储4字 ...
- Kindle Unlimited 上线的最热书单
Kindle 也给出了一份,到现在为止,在 Kindle Unlimited 上线的最热书单: 1.岛上书店2.一个人的朝圣3.自控力4.嫌疑人 X 的献身5.沉默的大多数(王小波文集)6.跟任何人都 ...
- CSS-05-伪类及伪元素选择器
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- Java面试技巧—如何自我介绍
在企业面试环节中“自我介绍”这个老生常谈的话题就不用多说什么了,面试官必定会问的.那么如何在自我介绍的时候就能够打动面试官,吸引面试官对面试者的兴趣?如何进行自我介绍比较好?有没有什么方式方法呢?当然 ...
- 手把手实操教程!使用k3s运行轻量级VM
前 言 k3s作为轻量级的Kubernetes发行版,运行容器是基本功能.VM的管理原本是IaaS平台的基本能力,随着Kubernetes的不断发展,VM也可以纳入其管理体系.结合Container和 ...