Python读取MNIST数据集
MNIST数据集获取
MNIST数据集是入门机器学习/模式识别的最经典数据集之一。最早于1998年Yan Lecun在论文:
中提出。经典的LeNet-5 CNN网络也是在该论文中提出的。
数据集包含了0-9共10类手写数字图片,每张图片都做了尺寸归一化,都是28x28大小的灰度图。每张图片中像素值大小在0-255之间,其中0是黑色背景,255是白色前景。如下图所示:

MNIST共包含70000张手写数字图片,其中有60000张用作训练集,10000张用作测试集。原始数据集可在MNIST官网下载。
下载之后得到4个压缩文件:
train-images-idx3-ubyte.gz #60000张训练集图片 train-labels-idx1-ubyte.gz #60000张训练集图片对应的标签 t10k-images-idx3-ubyte.gz #10000张测试集图片 t10k-labels-idx1-ubyte.gz #10000张测试集图片对应的标签
将其解压,得到:
train-images-idx3-ubyte train-labels-idx1-ubyte t10k-images-idx3-ubyte t10k-labels-idx1-ubyte
MNIST二进制文件的存储格式
解压得到的四个文件都是二进制格式,我们如何获取其中的信息呢?这得首先了解MNIST二进制文件的存储格式(官网底部有介绍),以训练集图像文件train-images-idx3-ubyte为例:
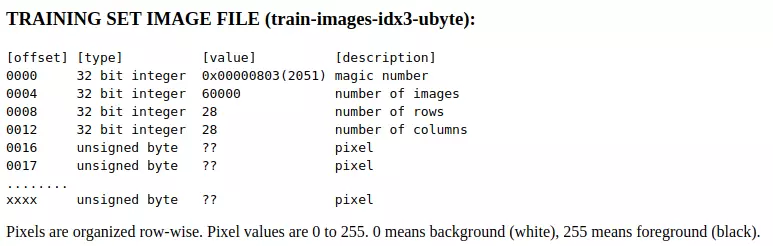
图像文件的
- 第1-4个byte(字节,1byte=8bit),即前32bit存的是文件的magic number,对应的十进制大小是2051;
- 第5-8个byte存的是number of images,即图像数量60000;
- 第9-12个byte存的是每张图片行数/高度,即28;
- 第13-16个byte存的是每张图片的列数/宽度,即28。
- 从第17个byte开始,每个byte存储一张图片中的一个像素点的值。
因为train-images-idx3-ubyte文件总共包含了60000张图片数据,按照以上的存储方式,我们算一下该文件的大小:
- 一张图片包含28x28=784个像素点,需要784bytes的存储空间;
- 60000张图片则需要784x60000=47040000 bytes的存储空间;
- 此外,文件开始处使用了16个bytes用于存储magic number、图像数量、图像高度和图像宽度,因此,训练集图像文件的大小应该是47040000+16=47040016 bytes。
我们查看解压后的train-images-idx3-ubyte文件的属性:
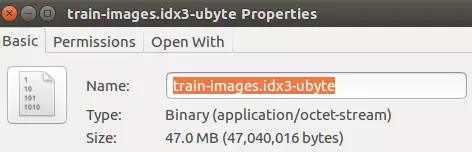
文件实际大小和我们计算的结果一致。
类似地,我们查看训练集标签文件train-labels-idx1-ubyte的存储格式:
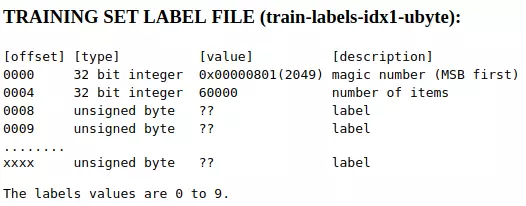
和图像文件类似:
- 第1-4个byte存的是文件的magic number,对应的十进制大小是2049;
- 第5-8个byte存的是number of items,即label数量60000;
- 从第9个byte开始,每个byte存一个图片的label信息,即数字0-9中的一个。
计算一下训练集标签文件train-labels-idx1-ubyte的文件大小:
- 1x60000+8=60008 bytes。
与该文件实际的大小一致:

另外两个文件,即测试集图像文件、测试集标签文件的存储方式和训练图像文件、训练标签文件相似,只是图像数量由60000变为10000。
使用python访问MNIST数据集文件内容
知道了MNIST二进制文件的存储方式,下面介绍如何使用python访问文件内容。同样以训练集图像文件train-images-idx3-ubyte为例:
import numpy as np
import matplotlib.pyplot as plt
'''试验transpose()
def back (a,b):
return a,b
if __name__ == '__main__':
a = np.array([[1,2,3],[11,12,13],[21,22,23]])
print(a)
b = np.array([[31,32,33],[41,42,43],[51,52,53]])
print(b)
a, b = transpose(back(a,b))
#a, b = back(a, b)
print(a)
print(b)
'''
# 数据加载器基类
class Loader(object):
def __init__(self, path, count):
'''
初始化加载器
path: 数据文件路径
count: 文件中的样本个数
'''
self.path = path
self.count = count
def get_file_content(self):
'''
读取文件内容
'''
f = open(self.path, 'rb')
content = f.read()
f.close()
return content
def to_int(self, byte):
'''
将unsigned byte字符转换为整数
'''
#print(byte)
#return struct.unpack('B', byte)[0]
return byte
# 图像数据加载器
class ImageLoader(Loader):
def get_picture(self, content, index):
'''
内部函数,从文件中获取图像
'''
start = index * 28 * 28 + 16
picture = []
for i in range(28):
picture.append([])
for j in range(28):
picture[i].append(
self.to_int(content[start + i * 28 + j]))
return picture
def get_one_sample(self, picture):
'''
内部函数,将图像转化为样本的输入向量
'''
sample = []
for i in range(28):
for j in range(28):
sample.append(picture[i][j])
return sample
def load(self):
'''
加载数据文件,获得全部样本的输入向量
'''
content = self.get_file_content()
data_set = []
for index in range(self.count):
data_set.append(
self.get_one_sample(
self.get_picture(content, index)))
return data_set
# 标签数据加载器
class LabelLoader(Loader):
def load(self):
'''
加载数据文件,获得全部样本的标签向量
'''
content = self.get_file_content()
labels = []
for index in range(self.count):
labels.append(self.norm(content[index + 8]))
return labels
def norm(self, label):
'''
内部函数,将一个值转换为10维标签向量
'''
label_vec = []
label_value = self.to_int(label)
for i in range(10):
if i == label_value:
label_vec.append(0.9)
else:
label_vec.append(0.1)
return label_vec
def get_training_data_set():
'''
获得训练数据集
'''
image_loader = ImageLoader('train-images.idx3-ubyte', 60000)
label_loader = LabelLoader('train-labels.idx1-ubyte', 60000)
return image_loader.load(), label_loader.load()
def get_test_data_set():
'''
获得测试数据集
'''
image_loader = ImageLoader('t10k-images.idx3-ubyte', 10000)
label_loader = LabelLoader('t10k-labels.idx1-ubyte', 10000)
return image_loader.load(), label_loader.load()
if __name__ == '__main__':
train_data_set, train_labels = get_training_data_set()
line = np.array(train_data_set[0])
img = line.reshape((28,28))
plt.imshow(img)
plt.show()
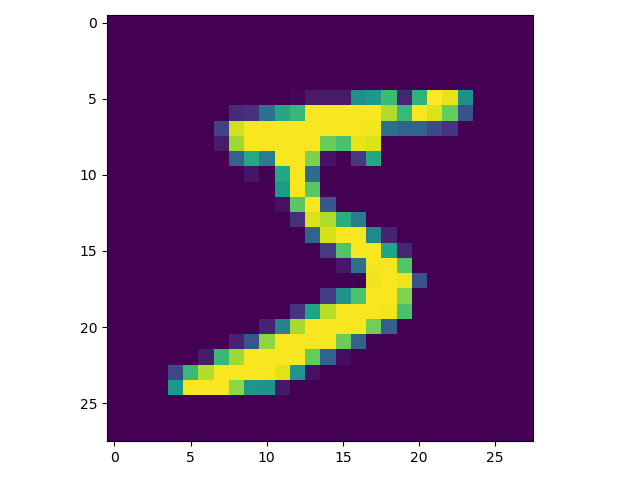
输出图片如下:
参考:
Python读取MNIST数据集的更多相关文章
- python读取mnist
python读取mnist 其实就是python怎么读取binnary file mnist的结构如下,选取train-images TRAINING SET IMAGE FILE (train-im ...
- mnist的格式说明,以及在python3.x和python 2.x读取mnist数据集的不同
有一个关于mnist的一个事例可以参考,我觉得写的很好:http://www.cnblogs.com/x1957/archive/2012/06/02/2531503.html #!/usr/bin/ ...
- python 将Mnist数据集转为jpg,并按比例/标签拆分为多个子数据集
现有条件:Mnist数据集,下载地址:跳转 下载后的四个.gz文件解压后放到同一个文件夹下,如:/raw Step 1:将Mnist数据集转为jpg图片(代码来自这篇博客) 1 import os 2 ...
- C++读取MNIST数据集
MNIST是一个标准的手写字符测试集. Mnist数据集对应四个文件: train-images-idx3-ubyte: training set images train-labels-idx1- ...
- python读取,显示,保存mnist图片
python处理二进制 python的struct模块可以将整型(或者其它类型)转化为byte数组.看下面的代码. # coding: utf-8 from struct import * # 包装成 ...
- C++基于文件流和armadillo读取mnist
发现网上大把都是用python读取mnist的,用C++大都是用opencv读取的,但我不怎么用opencv,因此自己摸索了个使用文件流读取mnist的方法,armadillo仅作为储存矩阵的一种方式 ...
- 深度学习(一)之MNIST数据集分类
任务目标 对MNIST手写数字数据集进行训练和评估,最终使得模型能够在测试集上达到\(98\%\)的正确率.(最终本文达到了\(99.36\%\)) 使用的库的版本: python:3.8.12 py ...
- 利用Python读取外部数据文件
不论是数据分析,数据可视化,还是数据挖掘,一切的一切全都是以数据作为最基础的元素.利用Python进行数据分析,同样最重要的一步就是如何将数据导入到Python中,然后才可以实现后面的数据分析.数 ...
- MNIST数据集转化为二维图片
#coding: utf-8 from tensorflow.examples.tutorials.mnist import input_data import scipy.misc import o ...
随机推荐
- 每天进步一点点------Allegro 建立封装的一般步骤
在制作封装之前,先确定你需要的焊盘,如果库中没有,那就要自己画了,(我就是自己画的) 制作二极管1N5822 SMD,实际尺寸:480milX520mil 一.添加元件焊盘 1 启动Allegro P ...
- UVA 1267 Network(DFS)
题目链接:https://vjudge.net/problem/UVA-1267 首先我们要把这样一棵无根树转换成有根树,那么树根我们可以直接使用$VOD$. 还有一个性质:如果深度为$d$的一个节点 ...
- typedef基本用法
[代码演示] 例一 例二 例三
- binwalk在Windows10和kali_Linux下的安装及使用教程
(一)binwalk简介 binwalk 是用于搜索给定二进制镜像文件以获取嵌入的文件和代码的工具. 具体来说,binwalk是一个固件的分析工具,旨在协助研究人员对固件非分析,提取及逆向工程 ...
- HBase 启动后HMaster进程自动消失
原因分析 1.hadoop 与 hbase 版本不兼容,导致的异常. 2.log日志信息显示 org.apache.hadoop.hbase.TableExistsException: hbase:n ...
- [原]eclipse中spring配置文件的自动提示和命名空间的添加
在用spring或者springmvc框架进行开发时,编辑applicationcontext.xml等配置文件是必不可少的,在eclipse中打开applicationcontext.xml通常是这 ...
- Postman 设置token为全局变量
在做接口测试的时候,经常会用到不同用户登陆的token,来测试API,通过设置全局的token,这样更便捷: 注意设置的名称必须与你登陆后返回的名称一致,我这里是 AccessToken 1.配置环境 ...
- JS中数组实现(倒序遍历数组,数组连接字符串)
// =================== 求最大值===================================== <script> var arr = [10,35,765 ...
- cs/bs
c(客户端)/s服务器:使用前必须安装,更新是,c s同时更新,不能跨频繁太,采用自由协议,相对来说安全. b(浏览器)/s:本质上还是cs ,只是使用了浏览器:如京东,淘宝.无需安装,客户端不需要更 ...
- Java 倒入文章显示前n个单词频率
package com_1; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOExc ...