DirectX11--HLSL语法入门
前言
编写本内容仅仅是为了完善当前的教程体系,入门级别的内容其实基本上都是千篇一律,仅有一些必要细节上的扩充。要入门HLSL,只是掌握入门语法,即便把HLSL的全部语法也吃透了也并不代表你就能着色器代码了,还需要结合到渲染管线中,随着教程的不断深入来不断学习需要用到的新的语法,然后尝试修改着色器,再根据实际需求自己编写着色器来实现特定的效果。
注意:在翻阅HLSL文档的时候,要避开Effects11相关的内容。因为当前教程与Effects11是不兼容的。
DirectX11 With Windows SDK完整目录
欢迎加入QQ群: 727623616 可以一起探讨DX11,以及有什么问题也可以在这里汇报。
数据类型
标量
常用标量类型如下:
| 类型 | 描述 |
|---|---|
| bool | 32位整数值用于存放逻辑值true和false |
| int | 32位有符号整数 |
| uint | 32位无符号整数 |
| half | 16位浮点数(仅提供用于向后兼容) |
| float | 32位浮点数 |
| double | 64位浮点数 |
注意:一些平台可能不支持
int,half和double,如果出现这些情况将会使用float来模拟
此外,浮点数还有规格化的形式:
snorm float是IEEE 32位有符号且规格化的浮点数,表示范围为-1到1unorm float是IEEE 32位无符号且规格化的浮点数,表示范围为0到1
向量
向量类型可以支持2到4个同类元素
一种表示方式是使用类似模板的形式来描述
vector<float, 4> vec1; // 向量vec1包含4个float元素
vector<int, 2> vec2; // 向量vec2包含2个int元素
另一种方式则是直接在基本类型后面加上数字
float4 vec1; // 向量vec1包含4个float元素
int3 vec2; // 向量vec2包含3个int元素
当然,只使用vector本身则表示为一种包含4个float元素的类型
vector vec1; // 向量vec1包含4个float元素
向量类型有如下初始化方式:
float2 vec0 = {0.0f, 1.0f};
float3 vec1 = float3(0.0f, 0.1f, 0.2f);
float4 vec2 = float4(vec1, 1.0f);
向量的第1到第4个元素既可以用x, y, z, w来表示,也可以用r, g, b, a来表示。除此之外,还可以用索引的方式来访问。下面展示了向量的取值和访问方式:
float4 vec0 = {1.0f, 2.0f, 3.0f, 0.0f};
float f0 = vec0.x; // 1.0f
float f1 = vec0.g; // 2.0f
float f2 = vec0[2]; // 3.0f
vec0.a = 4.0f; // 4.0f
我们还可以使用swizzles的方式来进行赋值,可以一次性提供多个分量进行赋值操作,这些分量的名称可以重复出现:
float4 vec0 = {1.0f, 2.0f, 3.0f, 4.0f};
float3 vec1 = vec0.xyz; // (1.0f, 2.0f, 3.0f)
float2 vec2 = vec0.rg; // (1.0f, 2.0f)
float4 vec3 = vec0.zzxy; // (4.0f, 4.0f, 1.0f, 2.0f)
vec3.wxyz = vec3; // (2.0f, 4.0f, 4.0f, 1.0f)
vec3.yw = ve1.zz; // (2.0f, 3.0f, 4.0f, 3.0f)
矩阵(matrix)
矩阵有如下类型(以float为例):
float1x1 float1x2 float1x3 float1x4
float2x1 float2x2 float2x3 float2x4
float3x1 float3x2 float3x3 float3x4
float4x1 float4x2 float4x3 float4x4
此外,我们也可以使用类似模板的形式来描述:
matrix<float, 2, 2> mat1; // float2x2
而单独的matrix类型的变量实际上可以看做是一个包含了4个vector向量的类型,即包含16个float类型的变量。matrix本身也可以写成float4x4:
matrix mat1; // float4x4
矩阵的初始化方式如下:
float2x2 mat1 = {
1.0f, 2.0f, // 第一行
3.0f, 4.0f // 第二行
};
float3x3 TBN = float3x3(T, B, N); // T, B, N都是float3
矩阵的取值方式如下:
matrix M;
// ...
float f0 = M._m00; // 第一行第一列元素(索引从0开始)
float f1 = M._12; // 第一行第二列元素(索引从1开始)
float f2 = M[0][1]; // 第一行第二列元素(索引从0开始)
float4 f3 = M._11_12; // Swizzles
矩阵的赋值方式如下:
matrix M;
vector v = {1.0f, 2.0f, 3.0f, 4.0f};
// ...
M[0] = v; // 矩阵的第一行被赋值为向量v
M._m11 = v[0]; // 等价于M[1][1] = v[0];和M._22 = v[0];
M._12_21 = M._21_12; // 交换M[2][3]和M[3][2]
无论是向量还是矩阵,乘法运算符都是用于对每个分量进行相乘,例如:
float4 vec0 = 2.0f * float4(1.0f, 2.0f, 3.0f, 4.0f); //(2.0f, 4.0f, 6.0f, 8.0f)
float4 vec1 = vec0 * float4(1.0f, 0.2f, 0.1f, 0.0f); //(2.0f, 0.8f, 0.6f, 0.0f)
若要进行向量与矩阵的乘法,则需要使用mul函数。
在C++代码层中,DirectXMath数学库创建的矩阵都是行矩阵,但当矩阵从C++传递给HLSL时,HLSL默认是列矩阵的,看起来就好像传递的过程中进行了一次转置那样。如果希望不发生转置操作的话,可以添加修饰关键字row_major:
row_major matrix M;
数组
和C++一样,我们可以声明数组:
float M[4][4];
int p[4];
float3 v[12]; // 12个3D向量
结构体(struct)
HLSL的结构体和C/C++的十分相似,它可以存放任意数目的标量,向量和矩阵类型,除此之外,它还可以存放数组或者别的结构体类型。结构体的成员访问也和C/C++相似:
struct A
{
float4 vec;
};
struct B
{
int scalar;
float4 vec;
float4x4 mat;
float arr[8];
A a;
};
// ...
B b;
b.vec = float4(1.0f, 2.0f, 3.0f, 4.0f);
变量的修饰符
| 关键字 | 含义 |
|---|---|
| static | 该着色器变量将不会暴露给C++应用层,需要在HLSL中自己初始化,否则使用默认初始化 |
| extern | 与static相反,该着色器变量将会暴露给C++应用层 |
| uniform | 该着色器变量允许在C++应用层被改变,但在着色器执行的过程中,其值始终保持不变(运行前可变,运行时不变)。着色器程序中的全局变量默认为既uniform又extern |
| const | 和C++中的含义相同,它是一个常量,需要被初始化且不可以被修改 |
类型转换
HLSL有着极其灵活的类型转换机制。HLSL中的类型转换语法和C/C++的相同。下面是一些例子:
float f = 4.0f;
float4x4 m = (float4x4)f; // 将浮点数f复制到矩阵m的每一个元素当中
float3 n = float3(...);
float3 v = 2.0f * n - 1.0f; // 这里1.0f将会隐式转换成(1.0f, 1.0f, 1.0f)
float4x4 WInvT = float4x4(...);
float3x3 mat = (float3x3)WInvT; // 只取4x4矩阵的前3行前3列
typedef关键字
和C++一样,typedef关键字用来声明一个类型的别称:
typedef float3 point;
typedef const float cfloat;
point p; // p为float3
cfloat f = 1.0f; // f为const float
运算符的一些特例
本教程不列出关键字,在学习的时候再逐渐接触需要用到的会好一点。
C/C++中能用的运算符在HLSL中基本上都能用,也包括位运算。这里只列出运算符的一些特例情况。
- 模运算符%不仅可以用于整数,还能用于浮点数。而且,要进行模运算就必须保证取模运算符左右操作数都具有相同的符号(要么都为正数,要么都为负数)。
- 基于运算符的向量间的运算都是以分量为展开的。
例如:
float3 pos = {1.0f, 2.0f, 3.0f};
float3 p1 = pos * 2.0f; // (2.0f, 4.0f, 6.0f)
float3 p2 = pos * pos; // (1.0f, 4.0f, 9.0f)
bool3 b = (p1 == p2); // (false, true, false)
++pos; // (2.0f, 3.0f, 4.0f)
因此,如果乘法运算符的两边都是矩阵,则表示为矩阵的分量乘法,而不是矩阵乘法。
最后是二元运算中变量类型的提升规则:
- 对于二元运算来说,如果运算符左右操作数的维度不同,那么维度较小的变量类型将会被隐式提升为维度较大的变量类型。但是这种提升仅限于标量到向量的提升,即
x会变为(x, x, x)。但是不支持像float2到float3的提升。 - 对于二元运算来说,如果运算符左右的操作数类型不同,那么低精度变量的类型将被隐式提升为高精度变量的类型,这点和C/C++是类似的。
控制流
条件语句
HLSL也支持if, else, continue, break, switch关键字,此外discard关键字用于像素着色阶段抛弃该像素。
条件的判断使用一个布尔值进行,通常由各种逻辑运算符或者比较运算符操作得到。注意向量之间的比较或者逻辑操作是得到一个存有布尔值的向量,不能够直接用于条件判断,也不能用于switch语句。
判断与动态分支
基于值的条件分支只有在程序执行的时候被编译好的着色器汇编成两种方式:判断(predication)和动态分支(dynamic branching)。
如果使用的是判断的形式,编译器会提前计算两个不同分支下表达式的值。然后使用比较指令来基于比较结果来"选择"正确的值。
而动态分支使用的是跳转指令来避免一些非必要的计算和内存访问。
着色器程序在同时执行的时候应当选择相同的分支,以防止硬件在分支的两边执行。通常情况下,硬件会同时将一系列连续的顶点数据传入到顶点着色器并行计算,或者是一系列连续的像素单元传入到像素着色器同时运算等。
动态分支会由于执行分支指令所带来的开销而导致一定的性能损失,因此要权衡动态分支的开销和可以跳过的指令数目。
通常情况下编译器会自行选择使用判断还是动态分支,但我们可以通过重写某些属性来修改编译器的行为。我们可以在条件语句前可以选择添加下面两个属性之一:
| 属性 | 描述 |
|---|---|
| [branch] | 根据条件值的结果,只计算其中一边的内容,会产生跳转指令。默认不加属性的条件语句为branch型。 |
| [flatten] | 两边的分支内容都会计算,然后根据条件值选择其中一边。可以避免跳转指令的产生。 |
用法如下:
[flatten]
if (x)
{
x = sqrt(x);
}
循环语句
HLSL也支持for, while和do while循环。和条件语句一样,它可能也会在基于运行时的条件值判断而产生动态分支,从而影响程序性能。如果循环次数较小,我们可以使用属性[unroll]来展开循环,代价是产生更多的汇编指令。用法如下:
times = 4;
sum = times;
[unroll]
while (times--)
{
sum += times;
}
若没有添加属性,默认使用的则为[loop]。
函数
函数的语法也和C/C++的十分类似,但它具有以下属性:
- 参数只能按值传递
- 不支持递归
- 只有内联函数(避免产生调用的跳转来减小开销)
此外,HLSL函数的形参可以指定输入/输出类别:
| 输入输出类别 | 描述 |
|---|---|
| in | 仅读入。实参的值将会复制到形参上。若未指定则默认为in |
| out | 仅输出。对形参修改的最终结果将会复制到实参上 |
| inout | 即in和out的组合 |
例如:
bool foo(in bool b, // 输入的bool类型参数
out int r1, // 输出的int类型参数
inout float r2) // 具备输入/输出的float类型参数
{
if (b)
{
f1 = 5;
}
else
{
r1 = 1;
}
// 注意r1不能出现在等式的右边
// r2既可以被读入,也可以写出结果到外面的实参上
r2 = r2 * r2 * r2;
return true;
}
内置函数
HLSL提供了一些内置全局函数,它通常直接映射到指定的着色器汇编指令集。这里只列出一些比较常用的函数:
| 函数名 | 描述 | 最小支持着色器模型 |
|---|---|---|
| abs | 每个分量求绝对值 | 1.1 |
| acos | 求x分量的反余弦值 | 1.1 |
| all | 测试x分量是否按位全为1 | 1.1 |
| any | 测试x分量是否按位存在1 | 1.1 |
| asdouble | 将值按位重新解释成double类型 | 5.0 |
| asfloat | 将值按位重新解释成float类型 | 4.0 |
| asin | 求x分量的反正弦值 | 1.1 |
| asint | 将值按位重新解释成int类型 | 4.0 |
| asuint | 将值按位重新解释成uint类型 | 4.0 |
| atan | 求x分量的反正切值值 | 1.1 |
| atan2 | 求(x,y)分量的反正切值 | 1.1 |
| ceil | 求不小于x分量的最小整数 | 1.1 |
| clamp | 将x分量的值限定在[min, max] | 1.1 |
| clip | 丢弃当前像素,如果x分量的值小于0 | 1.1 |
| cos | 求x分量的余弦值 | 1.1 |
| cosh | 求x分量的双曲余弦值 | 1.1 |
| countbits | 计算输入整数的位1个数(对每个分量) | 5.0 |
| cross | 计算两个3D向量的叉乘 | 1.1 |
| ddx | 估算屏幕空间中的偏导数\(\partial \mathbf{p} / \partial x\)。这使我们可以确定在屏幕空间的x轴方向上,相邻像素间某属性值\(\mathbf{p}\)的变化量 | 2.1 |
| ddy | 估算屏幕空间中的偏导数\(\partial \mathbf{p} / \partial y\)。这使我们可以确定在屏幕空间的y轴方向上,相邻像素间某属性值\(\mathbf{p}\)的变化量 | 2.1 |
| degrees | 将x分量从弧度转换为角度制 | 1.1 |
| determinant | 返回方阵的行列式 | 1.1 |
| distance | 返回两个点的距离值 | 1.1 |
| dot | 返回两个向量的点乘 | 1.1 |
| dst | 计算距离向量 | 5.0 |
| exp | 计算e^x | 1.1 |
| exp2 | 计算2^x | 1.1 |
| floor | 求不大于x分量的最大整数 | 1.1 |
| fmod | 求x/y的余数 | 1.1 |
| frac | 返回x分量的小数部分 | 1.1 |
| isfinite | 返回x分量是否为有限的布尔值 | 1.1 |
| isinf | 返回x分量是否为无穷大的布尔值 | 1.1 |
| isnan | 返回x分量是否为nan的布尔值 | 1.1 |
| length | 计算向量的长度 | 1.1 |
| lerp | 求x + s(y - x) | 1.1 |
| lit | 返回一个光照系数向量(环境光亮度, 漫反射光亮度, 镜面光亮度, 1.0f) | 1.1 |
| log | 返回以e为底,x分量的对数 | 1.1 |
| log10 | 返回以10为底,x分量的对数 | 1.1 |
| log2 | 返回以2为底,x分量的自然对数 | 1.1 |
| mad | 返回mvalue * avalue + bvalue | 1.1 |
| max | 返回x分量和y分量的最大值 | 1.1 |
| min | 返回x分量和y分量的最小值 | 1.1 |
| modf | 将值x分开成整数部分和小数部分 | 1.1 |
| mul | 矩阵乘法运算 | 1 |
| normalize | 计算规格化的向量 | 1.1 |
| pow | 返回x^y | 1.1 |
| radians | 将x分量从角度值转换成弧度值 | 1 |
| rcp | 对每个分量求倒数 | 5 |
| reflect | 返回反射向量 | 1 |
| refract | 返回折射向量 | 1.1 |
| reversebits | 对每个分量进行位的倒置 | 5 |
| round | x分量进行四舍五入 | 1.1 |
| rsqrt | 返回1/sqrt(x) | 1.1 |
| saturate | 对x分量限制在[0,1]范围 | 1 |
| sign | 计算符号函数的值,x大于0为1,x小于0为-1,x等于0则为0 | 1.1 |
| sin | 计算x的正弦 | 1.1 |
| sincos | 返回x的正弦和余弦 | 1.1 |
| sinh | 返回x的双曲正弦 | 1.1 |
| smoothstep | 给定范围[min, max],映射到值[0, 1]。小于min的值取0,大于max的值取1 | 1.1 |
| step | 返回(x >= a) ? 1 : 0 | 1.1 |
| tan | 返回x的正切值 | 1.1 |
| tanh | 返回x的双曲正切值 | 1.1 |
| transpose | 返回矩阵m的转置 | 1 |
| trunc | 去掉x的小数部分并返回 | 1 |
语义
语义通常是附加在着色器输入/输出参数上的字符串。它在着色器程序的用途如下:
- 用于描述传递给着色器程序的变量参数的含义
- 允许着色器程序接受由渲染管线生成的特殊系统值
- 允许着色器程序传递由渲染管线解释的特殊系统值
顶点着色器语义
| 输入 | 描述 | 类型 |
|---|---|---|
| BINORMAL[n] | 副法线(副切线)向量 | float4 |
| BLENDINDICES[n] | 混合索引 | uint |
| BLENDWEIGHT[n] | 混合权重 | float |
| COLOR[n] | 漫反射/镜面反射颜色 | float4 |
| NORMAL[n] | 法向量 | float4 |
| POSITION[n] | 物体坐标系下的顶点坐标 | float4 |
| POSITIONT | 变换后的顶点坐标 | float4 |
| PSIZE[n] | 点的大小 | float |
| TANGENT[n] | 切线向量 | float4 |
| TEXCOORD[n] | 纹理坐标 | float4 |
| Output | 仅描述输出 | Type |
| FOG | 顶点雾 | float |
n是一个可选的整数,从0开始。比如POSITION0, TEXCOORD1等等。
像素着色器语义
| 输入 | 描述 | 类型 |
|---|---|---|
| COLOR[n] | 漫反射/镜面反射颜色 | float4 |
| TEXCOORD[n] | 纹理坐标 | float4 |
| Output | 仅描述输出 | Type |
| DEPTH[n] | 深度值 | float |
系统值语义
所有的系统值都包含前缀SV_。这些系统值将用于某些着色器的特定用途(并未全部列出)
| 系统值 | 描述 | 类型 |
|---|---|---|
| SV_Depth | 深度缓冲区数据,可以被任何着色器写入/读取 | float |
| SV_InstanceID | 每个实例都会在运行期间自动生成一个ID。在任何着色器阶段都能读取 | uint |
| SV_IsFrontFace | 指定该三角形是否为正面。可以被几何着色器写入,以及可以被像素着色器读取 | bool |
| SV_Position | 若被声明用于输入到着色器,它描述的是像素位置,在所有着色器中都可用,可能会有0.5的偏移值 | float4 |
| SV_PrimitiveID | 每个原始拓扑都会在运行期间自动生成一个ID。可用在几何/像素着色器中写入,也可以在像素/几何/外壳/域着色器中读取 | uint |
| SV_StencilRef | 代表当前像素着色器的模板引用值。只可以被像素着色器写入 | uint |
| SV_VertexID | 每个实例都会在运行期间自动生成一个ID。仅允许作为顶点着色器的输入 | uint |
通用着色器的核心
所有的可编程着色器阶段使用通用着色器核心来实现相同的基础功能。此外,顶点着色阶段、几何着色阶段和像素着色阶段则提供了独特的功能,例如几何着色阶段可以生成新的图元或删减图元,像素着色阶段可以决定当前像素是否被抛弃等。下图展示了数据是怎么流向一个着色阶段,以及通用着色器核心与着色器内存资源之间的关系:
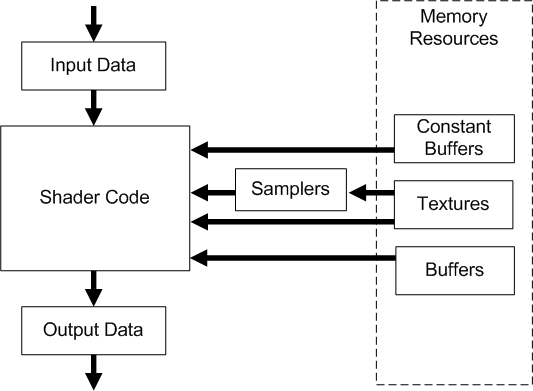
Input Data:顶点着色器从输入装配阶段获取数据;几何着色器则从上一个着色阶段的输出获取等等。通过给形参引入可以使用的系统值可以提供额外的输入
Output Data:着色器生成输出的结果然后传递给管线的下一个阶段。有些输出会被通用着色器核心解释成特定用途(如顶点位置、渲染目标对应位置的值),另外一些输出则由应用程序来解释。
Shader Code:着色器代码可以从内存读取,然后用于执行代码中所期望的内容。
Samplers:采样器决定了如何对纹理进行采样和滤波。
Textures:纹理可以使用采样器进行采样,也可以基于索引的方式按像素读取。
Buffers:缓冲区可以使用读取相关的内置函数,在内存中按元素直接读取。
Constant Buffers:常量缓冲区对常量值的读取有所优化。他们被设计用于CPU对这些数据的频繁更新,因此他们有额外的大小、布局和访问限制。
着色器常量
着色器常量存在内存中的一个或多个缓冲区资源当中。他们可以被组织成两种类型的缓冲区:常量缓冲区(cbuffers)和纹理缓冲区(tbuffers)。关于纹理缓冲区,我们不在这讨论。
常量缓冲区(Constant Buffer)
常量缓冲区允许C++端将数据传递给HLSL中使用,在HLSL端,这些传递过来的数据不可更改,因而是常量。常量缓冲区对这种使用方式有所优化,表现为低延迟的访问和允许来自CPU的频繁更新,因此他们有额外的大小、布局和访问限制。
声明方式如下:
cbuffer VSConstants
{
float4x4 g_WorldViewProj;
fioat3 g_Color;
uint g_EnableFog;
float2 g_ViewportXY;
float2 g_ViewportWH;
}
由于我们写的是原生HLSL,当我们在HLSL中声明常量缓冲区时,还需要在HLSL的声明中使用关键字register手动指定对应的寄存器索引,然后编译器会为对应的着色器阶段自动将其映射到15个常量缓冲寄存器的其中一个位置。这些寄存器的名字为b0到b14:
cbuffer VSConstants : register(b0)
{
float4x4 g_WorldViewProj;
fioat3 g_Color;
uint g_EnableFog;
float2 g_ViewportXY;
float2 g_ViewportWH;
}
在C++端是通过ID3D11DeviceContext::*SSetConstantBuffers指定特定的槽(slot)来给某一着色器阶段对应的寄存器索引提供常量缓冲区的数据。
如果是存在多个不同的着色器阶段使用同一个常量缓冲区,那就需要分别给这两个着色器阶段设置好相同的数据。
综合前面几节内容,下面演示了顶点着色器和常量缓冲区的用法:
cbuffer ConstantBuffer : register(b0)
{
float4x4 g_WorldViewProj;
}
void VS_Main(
in float4 inPos : POSITION, // 绑定变量到输入装配器
in uint VID : SV_VertexID, // 绑定变量到系统生成值
out float4 outPos : SV_Position) // 告诉管线将该值解释为输出的顶点位置
{
outPos = mul(inPos, g_WorldViewProj);
}
上面的代码也可以写成:
cbuffer ConstantBuffer : register(b0)
{
float4x4 g_WorldViewProj;
}
struct VertexIn
{
float4 inPos : POSITION; // 源自输入装配器
uint VID : SV_VertexID; // 源自系统生成值
};
float4 VS_Main(VertexIn vIn) : SV_Position
{
return mul(vIn.inPos, g_WorldViewProj);
}
有关常量缓冲区的打包规则,建议在阅读到时索引缓冲区、常量缓冲区一章时,再来参考杂项篇的HLSL常量缓冲区的打包规则。
DirectX11 With Windows SDK完整目录
欢迎加入QQ群: 727623616 可以一起探讨DX11,以及有什么问题也可以在这里汇报。
DirectX11--HLSL语法入门的更多相关文章
- [独孤九剑]持续集成实践(二)– MSBuild语法入门
本系列文章包含: [独孤九剑]持续集成实践(一)- 引子 [独孤九剑]持续集成实践(二)– MSBuild语法入门 [独孤九剑]持续集成实践(三)- Jenkins安装与配置(Jenkins+MSBu ...
- Java基础语法入门01
Java基础语法入门01 学习java你要先进行去了解JDK,JRE,JVM JDK Java开发工具包 JRE Java语言开发的运行环境 JVM Java虚拟机,用于Java语言的跨平台所用. 当 ...
- 【转】.MD语法入门
@2019-02-13 [小记] .MD语法入门
- Markdown之语法入门篇
Markdown语法入门 一.什么是Markdown语言 我相信有很多小伙伴没有听说过Markdown语言.的确,对于一般人来说,有word足够了.但是有这么一群人,受够了word那糟糕的排版方式,需 ...
- python语法入门之流程控制
python语法入门之流程控制 流程控制是指控制流程,具体指控制程序执行的流程. 流程控制分为三种: 1.顺序结构 程序从上而下的正常执行(正常执行的代码就是顺序结构) 2.分支结构 赋予程序人的思维 ...
- PHP语法入门以及变量
1PHP语法入门 1.1PHP是编译型语言 编译语言和解释语言的区别在于是否保存最终的可执行程序. 1.2PHP定界符 因为PHP是脚本语言,所以需要定界符 <?php e ...
- 14 微服务电商【黑马乐优商城】:day04-ES6语法入门
day01-springboot(理论篇) :day01-springboot(实践篇) day02-springcloud(理论篇一) :day02-springcloud(理论篇二) :day ...
- 常用markdown语法入门
入门markdown常用基本语法,简单到让你怀疑人生~~ 不说废话,直接上图(如果图片显示不清晰,建议选中图片右键——在新标签页中打开图片,妥妥的呢!!) (左侧黑色背景为markdown语法,右侧为 ...
- Vue 基础语法入门(转载)
使用vue.js原文介绍:Vue.js是一个构建数据驱动的web界面库.Vue.js的目标是通过尽可能简单的API实现响应式数据绑定和组合的视图组件.vue.js上手非常简单,先看看几个例子: 例一: ...
随机推荐
- js 细节
1.js中var a=s=1和var a=1,s=1的区别 function fl() { ; } function fl1() { , s = ; } 看出问题所在了吗? var q=w=1 中的s ...
- webpack--介绍、安装及入门
最早的时候,所有Javascript代码都写在一个文件里面,只要加载这一个文件就够了.后来,代码越来越多,一个文件不够了,必须分成多个文件,依次加载.下面的网页代码,相信很多人都见过. <scr ...
- asp.net MVC项目开发之统计图的使用(前言)
接触这个项目,是项目组长已经完成了多数需求,并且有2个项目需要完工的情况下,让我加入,给了我2个表格,让我去设计出统计图. 第一次做统计图,可以说没有任何经验,不知道该如何下手,表格的数据量 ...
- linux传输文件-sftp
SFTP sftp登陆远程服务器 sftp username@ip 例如:sftp mqadmin@10.10.1.150 然后输入password即可 put:上传文件 例如:put iosta ...
- redis中key键操作
keys */查看所有的key remoteSelf:1>select 0 "OK" remoteSelf:0>keys * 1) "SUBCRIBEMAP& ...
- JS高阶编程技巧--柯理化函数
首先看一段代码: let obj = { x: 100 }; function fn(y) { this.x += y; console.log(this); } 现在有一个需求:在1秒后,执行函数f ...
- (二)LoadRunner目录分析
学习一个软件的适用,首先应该了解软件目录,对以后深入学习工具有很大的好处. 查看目录文件如下: Analysis Templates——分析模板(默认的模板,可以将自己的模板保存到该目录下) bin— ...
- 为什么你SQL Server中SQL日期转换出错了呢?
开发人员有时候使用类似下面SQL将字符串转换为日期时间类型,乍一看,这样的SQL的写法是没有什么问题的.但是这样的SQL其实有时候就是一个定时炸弹,随时可能出现问题(),下面简单对这种情况进行一个简单 ...
- Java学习之String、StringBuffer、StringBuilder
String 我们知道字符串的分配和其他对象分配一样,是需要消耗高昂的时间和空间的,而且字符串我们使用的非常多.JVM为了提高性能和减少内存的开销,在实例化字符串的时候进行了一些优化:使用字符串常量池 ...
- Flutter初探_环境配置以及创建项目
还没学会这个怎么排版,写了一版 太丑 没发看,' 先换到我熟悉的网站,后面搞定了排版再更新过来 https://www.jianshu.com/p/6fc913861461