小匠第二周期打卡笔记-Task04
一、机器翻译及相关技术
机器翻译(MT):将一段文本从一种语言自动翻译为另一种语言,用神经网络解决这个问题通常称为神经网络翻译(NMT)。
主要特征:输出是单词序列而不是单个单词。输出序列的长度可能与源序列的长度不可。
数据预处理:
将数据集清洗、转化为神经网络的输入minbatch
空格处理编码。数据清洗。
大小写修改
分词source:
字符串----单词组成的列表
单词表里的特殊符号:
句子开始符、句子结束符、未知单词
建立字典
token单词组成的列表----单词id组成的列表
tokenization 用于把字符型式的句子转化为单词组成的列表
counter:词频统计
得到数据生成器
载入数据集
Encoder-Decoder
encoder:输入到隐藏状态(语义编码)
decoder:隐藏状态(语义编码)到输出
应用:机器翻译、对话机器人、语音识别任务。
Sequence to Sequence模型
训练时decode每个单元输出得到的单词作为下一个单元的输入单词。
预测时decoder单元输出为句子结束符时跳出循环。
每个batch训练时encoder和decoder都有固定长度的输入。
集束搜索(Beam Search)
集束搜索结合了greedy search和维特比算法
集束搜索使用beam size参数来限制再每一步保留下来的可能性词的数量。
集束搜索是一种贪心算法。
二、注意力机制与Seq2seq模型
在“编码器—解码器(seq2seq)”⼀节⾥,解码器在各个时间步依赖相同的背景变量(context vector)来获取输⼊序列信息。当编码器为循环神经⽹络时,背景变量来⾃它最终时间步的隐藏状态。将源序列输入信息以循环单位状态编码,然后将其传递给解码器以生成目标序列。然而这种结构存在着问题,尤其是RNN机制实际中存在长程梯度消失的问题,对于较长的句子,我们很难寄希望于将输入的序列转化为定长的向量而保存所有的有效信息,所以随着所需翻译句子的长度的增加,这种结构的效果会显著下降。
与此同时,解码的目标词语可能只与原输入的部分词语有关,而并不是与所有的输入有关。例如,当把“Hello world”翻译成“Bonjour le monde”时,“Hello”映射成“Bonjour”,“world”映射成“monde”。在seq2seq模型中,解码器只能隐式地从编码器的最终状态中选择相应的信息。然而,注意力机制可以将这种选择过程显式地建模。
Seq2seq模型
本节中将注意机制添加到sequence to sequence 模型中,以显式地使用权重聚合states。下图展示encoding 和decoding的模型结构,在时间步为t的时候。此刻attention layer保存着encodering看到的所有信息——即encoding的每一步输出。在decoding阶段,解码器的t时刻的隐藏状态被当作query,encoder的每个时间步的hidden states作为key和value进行attention聚合. Attetion model的输出当作成上下文信息context vector,并与解码器输入Dt拼接起来一起送到解码器:
点积注意力

代码操作:
# Save to the d2l package.
class DotProductAttention(nn.Module):
def __init__(self, dropout, **kwargs):
super(DotProductAttention, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout) # query: (batch_size, #queries, d)
# key: (batch_size, #kv_pairs, d)
# value: (batch_size, #kv_pairs, dim_v)
# valid_length: either (batch_size, ) or (batch_size, xx)
def forward(self, query, key, value, valid_length=None):
d = query.shape[-1]
# set transpose_b=True to swap the last two dimensions of key scores = torch.bmm(query, key.transpose(1,2)) / math.sqrt(d)
attention_weights = self.dropout(masked_softmax(scores, valid_length))
print("attention_weight\n",attention_weights)
return torch.bmm(attention_weights, value)
三、Transformer
在之前的章节中,我们已经介绍了主流的神经网络架构如卷积神经网络(CNNs)和循环神经网络(RNNs)。让我们进行一些回顾:
- CNNs 易于并行化,却不适合捕捉变长序列内的依赖关系。
- RNNs 适合捕捉长距离变长序列的依赖,但是却难以实现并行化处理序列。
为了整合CNN和RNN的优势,[Vaswani et al., 2017] 创新性地使用注意力机制设计了Transformer模型。该模型利用attention机制实现了并行化捕捉序列依赖,并且同时处理序列的每个位置的tokens,上述优势使得Transformer模型在性能优异的同时大大减少了训练时间。
图10.3.1展示了Transformer模型的架构,与9.7节的seq2seq模型相似,Transformer同样基于编码器-解码器架构,其区别主要在于以下三点:
- Transformer blocks:将seq2seq模型重的循环网络替换为了Transformer Blocks,该模块包含一个多头注意力层(Multi-head Attention Layers)以及两个position-wise feed-forward networks(FFN)。对于解码器来说,另一个多头注意力层被用于接受编码器的隐藏状态。
- Add and norm:多头注意力层和前馈网络的输出被送到两个“add and norm”层进行处理,该层包含残差结构以及层归一化。
- Position encoding:由于自注意力层并没有区分元素的顺序,所以一个位置编码层被用于向序列元素里添加位置信息。
多头注意力层
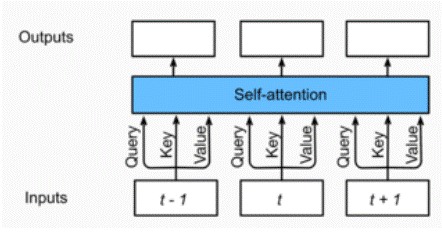
在我们讨论多头注意力层之前,先来迅速理解以下自注意力(self-attention)的结构。自注意力模型是一个正规的注意力模型,序列的每一个元素对应的key,value,query是完全一致的。如图10.3.2 自注意力输出了一个与输入长度相同的表征序列,与循环神经网络相比,自注意力对每个元素输出的计算是并行的,所以我们可以高效的实现这个模块。
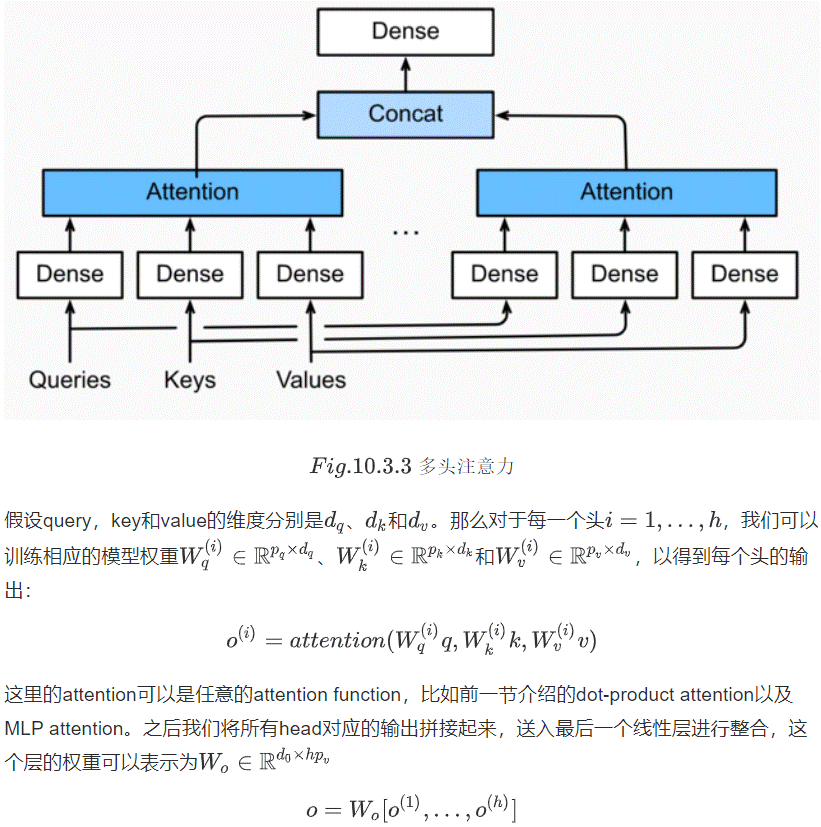
多头注意力层包含h个并行的自注意力层,每一个这种层被成为一个head。对每个头来说,在进行注意力计算之前,我们会将query、key和value用三个现行层进行映射,这h个注意力头的输出将会被拼接之后输入最后一个线性层进行整合。

基于位置的前馈网络
Transformer 模块另一个非常重要的部分就是基于位置的前馈网络(FFN),它接受一个形状为(batch_size,seq_length, feature_size)的三维张量。Position-wise FFN由两个全连接层组成,他们作用在最后一维上。因为序列的每个位置的状态都会被单独地更新,所以我们称他为position-wise,这等效于一个1x1的卷积。
下面我们来实现PositionWiseFFN:
# Save to the d2l package.
class PositionWiseFFN(nn.Module):
def __init__(self, input_size, ffn_hidden_size, hidden_size_out, **kwargs):
super(PositionWiseFFN, self).__init__(**kwargs)
self.ffn_1 = nn.Linear(input_size, ffn_hidden_size)
self.ffn_2 = nn.Linear(ffn_hidden_size, hidden_size_out) def forward(self, X):
return self.ffn_2(F.relu(self.ffn_1(X)))
与多头注意力层相似,FFN层同样只会对最后一维的大小进行改变;除此之外,对于两个完全相同的输入,FFN层的输出也将相等
Add and Norm
除了上面两个模块之外,Transformer还有一个重要的相加归一化层,它可以平滑地整合输入和其他层的输出,因此我们在每个多头注意力层和FFN层后面都添加一个含残差连接的Layer Norm层。这里 Layer Norm 与7.5小节的Batch Norm很相似,唯一的区别在于Batch Norm是对于batch size这个维度进行计算均值和方差的,而Layer Norm则是对最后一维进行计算。层归一化可以防止层内的数值变化过大,从而有利于加快训练速度并且提高泛化性能。
小匠第二周期打卡笔记-Task04的更多相关文章
- 小匠第二周期打卡笔记-Task05
一.卷积神经网络基础 知识点记录: 神经网络的基础概念主要是:卷积层.池化层,并解释填充.步幅.输入通道和输出通道之含义. 二维卷积层: 常用于处理图像数据,将输入和卷积核做互相关运算,并加上一个标量 ...
- 小匠第二周期打卡笔记-Task03
一.过拟合欠拟合及其解决方案 知识点记录 模型选择.过拟合和欠拟合: 训练误差和泛化误差: 训练误差 :模型在训练数据集上表现出的误差, 泛化误差 : 模型在任意一个测试数据样本上表现出的误差的期望, ...
- 小匠第一周期打卡笔记-Task02
一.文本预处理 预处理通常包括四个步骤: 读入文本 分词 建立字典,将每个词映射到一个唯一的索引(index) 将文本从词的序列转换为索引的序列,方便输入模型 读入文本: import collect ...
- 小匠第一周期打卡笔记-Task01
一.线性回归 知识点记录 线性回归输出是一个连续值,因此适用于回归问题.如预测房屋价格.气温.销售额等连续值的问题.是单层神经网络. 线性判别模型 判别模型 性质:建模预测变量和观测变量之间的关系,亦 ...
- 微信小程序消息通知-打卡考勤
微信小程序消息通知-打卡考勤 效果: 稍微改一下js就行,有不必要的错误,我就不改了,哈哈! index.js //index.js const app = getApp() // 填写微信小程序ap ...
- 微信小程序生命周期——小程序的生命周期及页面的生命周期。
最近在做微信小程序开发,也发现一些坑,分享一下自己踩过的坑. 生命周期是指一个小程序从创建到销毁的一系列过程. 在小程序中 ,通过App()来注册一个小程序 ,通过Page()来注册一个页面. 首先来 ...
- 微信小程序生命周期
微信小程序 生命周期 通俗的讲,生命周期就是指一个对象的生老病死. 从软件的角度来看,生命周期指程序从创建.到开始.暂停.唤起.停止.卸载的过程. 下面从一下三个方面介绍微信小程序的生命周期: 应用生 ...
- 微信小程序生命周期详解
文章出处:https://blog.csdn.net/qq_29712995/article/details/79784222 在我看来小程序的生命周期虽然简单,但是他渗透了小程序开发的整个过程,对于 ...
- [Python ]小波变化库——Pywalvets 学习笔记
[Python ]小波变化库——Pywalvets 学习笔记 2017年03月20日 14:04:35 SNII_629 阅读数:24776 标签: python库pywavelets小波变换 更多 ...
随机推荐
- PHP0015:PHP分页案例
- 【WCF Restful】Post传参示范
1.传多个参数 接口定义:(ResponseFormat与RequestFormat分别将相应参数序列化.请求参数反序列化) [OperationContract] [WebInvoke(UriTem ...
- Ubuntu 搭建phpcms
安装Apache2 $ sudo apt-get update -y $ sudo apt-get install apache2 -y $ sudo systemctl start apache2. ...
- LAMP搭建随笔
前言 这是我第一次在写博客,里面记录了我配置LAMP遇到的各种各样的细节,也许表述不够准确,希望大佬给于批评指正 环境 OS Ubuntu server 18.04.3 远程连接软件 cmder 文件 ...
- Navicat Premium15安装与激活(破解)
Navicat premium是一款数据库管理工具,是一个可多重连线资料库的管理工具,它可以让你以单一程式同时连线到 MySQL.SQLite.Oracle 及 PostgreSQL 资料库,让管理不 ...
- Uva1363(余数性质/减少枚举量)
题意: 输入正整数n和k(范围均为1e9),求∑(k mod i),i从1~n 解法: 首先这道题直接暴力亲测会超时. 之后我们写几组数据之后可以发现当k/i的商相同的时候他们的余数成一个等差数列,而 ...
- jdk8配置
Java SE Development Kit 8u241 下载 https://www.oracle.com/java/technologies/javase/javase-jdk8-downloa ...
- 项目在UAP可以直接启动,但是在eclipse上面不能直接启动
上面两个eclipse都是用友的开发人员给我的,左边是驻场开发给我的,但是没有教我怎么用和哪里好用,所以一直用UAP来做开发.右边的eclipse是提ISM问题,北京用友远程调试问题时给我的,而且终于 ...
- linux服务基础之编译安装nginx
nginx源码下载地址: http://nginx.org/download/nginx-1.16.0.tar.gz //根据需要下载其他版本 1. 下载nginx # wget http://ngi ...
- [PAT] A1018 Public Bike Management
[思路] 题目生词 figure n. 数字 v. 认为,认定:计算:是……重要部分 The stations are represented by vertices and the roads co ...