爬虫之robots.txt
robots是网站跟爬虫间的协议,用简单直接的txt格式文本方式告诉对应的爬虫被允许的权限,也就是说robots.txt是搜索引擎中访问网站的时候要查看的第一个文件。
当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件
不存在,所有的搜索蜘蛛将能够访问网站上所有没有被口令保护的页面。
robots简介
搜索引擎通过一种程序robot(又称spider),自动访问互联网上的网页并获取网页信息。
您可以在您的网站中创建一个纯文本文件robots.txt,在这个文件中声明该网站中不想被robot访问的部分,这样,该网站的部分或全部内容就可以不被搜索引擎收录了,或者指定搜索引擎只收录指定的内容。
robots.txt(统一小写)是一种存放于网站根目录下的ASCII编码的文本文件,它通常告诉网络搜索引擎的漫游器(又称网络蜘蛛),此网站中的哪些内容是不能被搜索引擎的漫游器获取的,哪些是可以被(漫游器)获取的。
因为一些系统中的URL是大小写敏感的,所以robots.txt的文件名应统一为小写。robots.txt应放置于网站的根目录下。如果想单独定义搜索引擎的漫游器访问子目录时的行为,那么可以将自定的设置合并到根目录下的robots.txt,
或者使用robots元数据。
Robots.txt协议并不是一个规范,而只是约定俗成的,所以并不能保证网站的隐私。注意Robots.txt是用字符串比较来确定是否获取URL,所以目录末尾有和没有斜杠“/”这两种表示是不同的URL,也不能用"Disallow: *.gif"这样
的通配符。这个协议也不是一个规范,而只是约定俗成的,通常搜索引擎会识别这个元数据,不索引这个页面,以及这个页面的链出页面
robots.txt文件应该放在网站根目录下。举例来说,当robots访问一个网站时,首先会检查该网站中是否存在这个文件,如果机器人找到这个文件,它就会根据这个文件的内容,来确定它访问权限的范围。
robots.txt文件的格式
"robots.txt"文件包含一条或更多的记录,这些记录通过空行分开(以CR,CR/NL, or NL作为结束符),每一条记录的格式如下所示:
"<field>:<optionalspace><value><optionalspace>"。
在该文件中可以使用#进行注解,具体使用方法和UNIX中的惯例一样。该文件中的记录通常以一行或多行User-agent开始,后面加上若干Disallow行,详细情况如下:
User-agent:
该项的值用于描述搜索引擎robot的名字,在"robots.txt"文件中,如果有多条User-agent记录说明有多个robot会受到该协议的限制,对该文件来说,至少要有一条User-agent记录。如果该项的值设为*,则该协议对任何机器人均有效,在"robots.txt"文件中,"User-agent:*"这样的记录只能有一条。
Disallow:
该项的值用于描述不希望被访问到的一个URL,这个URL可以是一条完整的路径,也可以是部分的,任何以Disallow开头的URL均不会被robot访问到。例如"Disallow:/help"对/help.html 和/help/index.html都不允许搜索引擎访问,而"Disallow:/help/"则允许robot访问/help.html,而不能访问/help/index.html。任何一条Disallow记录为空,说明该网站的所有部分都允许被访问,在"/robots.txt"文件中,至少要有一条Disallow记录。如果"/robots.txt"是一个空文件,则对于所有的搜索引擎robot,该网站都是开放的。
Allow:
该项的值用于描述希望被访问的一组URL,与Disallow项相似,这个值可以是一条完整的路径,也可以是路径的前缀,以Allow项的值开头的URL是允许robot访问的。例如"Allow:/hibaidu"允许robot访问/hibaidu.htm、/hibaiducom.html、/hibaidu/com.html。一个网站的所有URL默认是Allow的,所以Allow通常与Disallow搭配使用,实现允许访问一部分网页同时禁止访问其它所有URL的功能。
需要特别注意的是Disallow与Allow行的顺序是有意义的,robot会根据第一个匹配成功的Allow或Disallow行确定是否访问某个URL。
使用"*"和"$":
robots支持使用通配符"*"和"$"来模糊匹配url:
"$" 匹配行结束符。
"*" 匹配0或多个任意字符。
robots.txt语法教程
用几个最常见的情况,直接举例说明:
1. 允许所有SE收录本站:
robots.txt为空就可以,什么都不要写。
2. 禁止所有SE收录网站的某些目录:
User-agent: *
Disallow: /目录名1/
Disallow: /目录名2/
Disallow: /目录名3/
3. 禁止某个SE收录本站,例如禁止百度:
User-agent: Baiduspider
Disallow: /
4. 禁止所有SE收录本站:
User-agent: *
Disallow: /
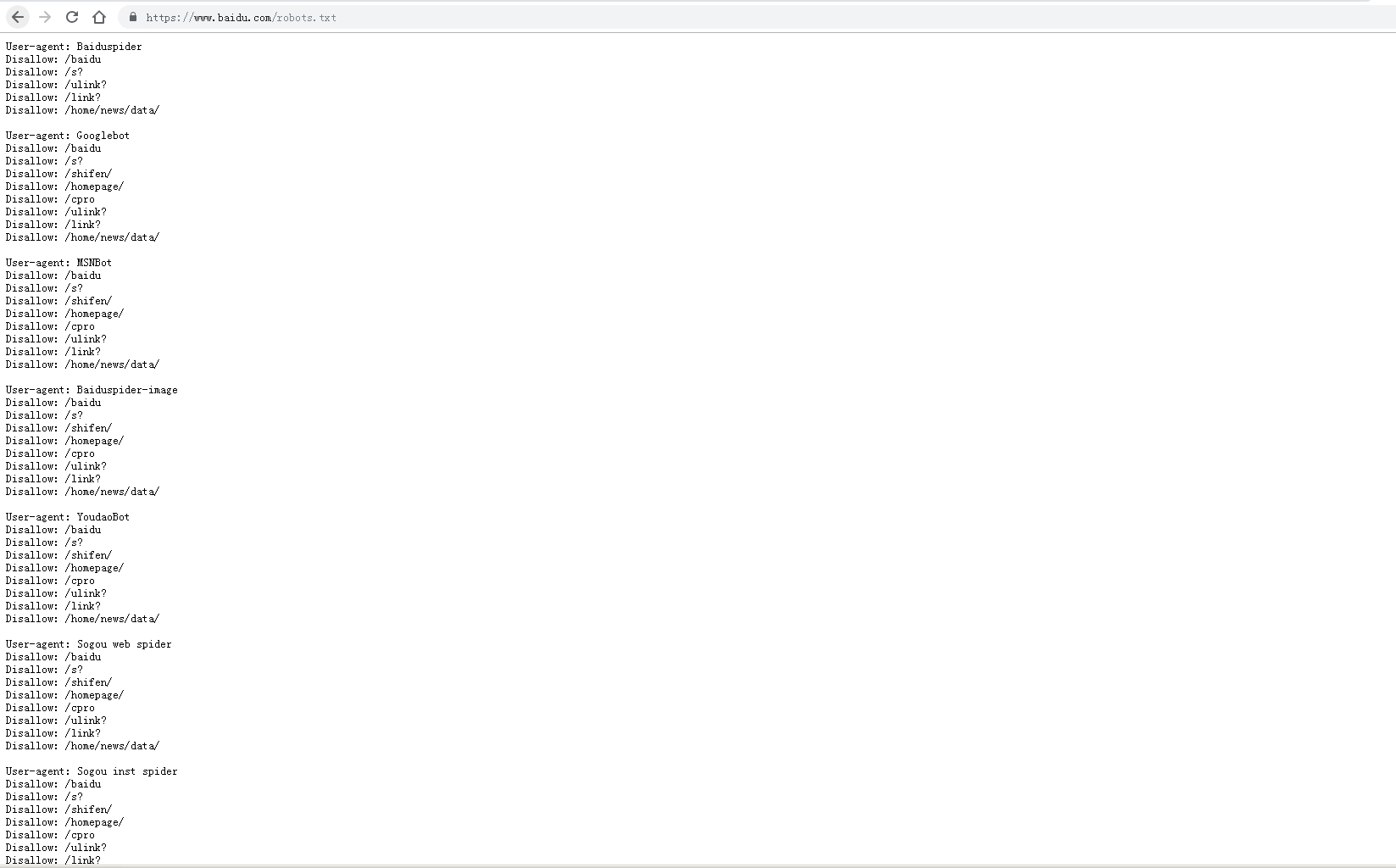
爬虫之robots.txt的更多相关文章
- Natas3 Writeup(爬虫协议robots.txt)
Natas3: 页面提示本页面什么都没有. 在源码中发现提示:无信息泄露,谷歌这次不会发现它.提到了搜索引擎,猜测爬虫协议robots.txt中存在信息泄露,访问网站爬虫协议http://natas3 ...
- Robots.txt - 禁止爬虫(转)
Robots.txt - 禁止爬虫 robots.txt用于禁止网络爬虫访问网站指定目录.robots.txt的格式采用面向行的语法:空行.注释行(以#打头).规则行.规则行的格式为:Field: v ...
- 从robots.txt開始网页爬虫之旅
做个网页爬虫或搜索引擎(下面统称蜘蛛程序)的各位一定不会陌生,在爬虫或搜索引擎訪问站点的时候查看的第一个文件就是robots.txt了.robots.txt文件告诉蜘蛛程序在server上什么文件是能 ...
- Linux企业级项目实践之网络爬虫(29)——遵守robots.txt
Robots协议(也称为爬虫协议.机器人协议等)的全称是"网络爬虫排除标准"(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以 ...
- 离robots.txt启动网络爬虫之旅
要成为一个网络爬虫或搜索引擎(在这里,共同蜘蛛)它不会陌生,在搜索引擎爬虫的第一个文件或者访问该网站上浏览robots.txt该.robots.txt文件讲述了蜘蛛server哪些文件要观看正在. 当 ...
- 如何设置让网站禁止被爬虫收录?robots.txt
robot.txt只是爬虫禁抓协议,user-agent表示禁止哪个爬虫,disallow告诉爬出那个禁止抓取的目录. 如果爬虫够友好的话,会遵守网站的robot.txt内容. 一个内部业务系统,不想 ...
- Robots.txt - 禁止爬虫
robots.txt用于禁止网络爬虫访问网站指定目录.robots.txt的格式采用面向行的语法:空行.注释行(以#打头).规则行.规则行的格式为:Field: value.常见的规则行:User-A ...
- 爬虫出现Forbidden by robots.txt(转载 https://blog.csdn.net/zzk1995/article/details/51628205)
先说结论,关闭scrapy自带的ROBOTSTXT_OBEY功能,在setting找到这个变量,设置为False即可解决. 使用scrapy爬取淘宝页面的时候,在提交http请求时出现debug信息F ...
- Scrapy 爬虫日志中出现Forbidden by robots.txt
爬取汽车之家数据的时候,日志中一直没有任何报错,开始一直不知道什么原因导致的,后来细细阅读了下日志发现日志提示“Forbidden by robots.txt”,Scrapy 设置文件中如果把ROBO ...
随机推荐
- [CF587-F]WI-FI
显然DP题... f[i][0]表示这个点不装路由器,f[i][1]表示装路由器 转移也很简单,在前面一段区间找最小值就好了 但是直接转移是$O(n*k)$的,会T掉 大佬说这个东西有单调性,但是菜鸡 ...
- Java虚拟机性能管理神器 - VisualVM(2) 入门【转】
Java虚拟机性能管理神器 - VisualVM(2) 入门[转] 标签: java插件jvm监控工具入门 2015-03-11 16:54 955人阅读 评论(0) 收藏 举报 分类: Visua ...
- thinkphp 高级模型
高级模型提供了更多的查询功能和模型增强功能,利用了模型类的扩展机制实现.如果需要使用高级模型的下面这些功能,记得需要继承Think\Model\AdvModel类或者采用动态模型. namespace ...
- Ionic3 demo TallyBook 实例2
1.添加插件 2.相关页面 消费页面: <ion-header> <ion-navbar> <ion-title> 消费记录 </ion-title> ...
- python的meshgrid用法和3D库 mpl_toolkits.mplot3d 与PolynomialFeatures多项式库学习
meshgrid import numpy as np from matplotlib import pyplot as plt from mpl_toolkits.mplot3d import Ax ...
- python 之 字符串处理
分割字符串 根据某个分割符分割 >>> a = '1,2,3,4' >>> a.split(',') ['] 根据多个分隔符分割 >>> line ...
- rsync+sersync
Environmental introduction System Kernel : -.el6.x86_64 Source Server : 192.168.7.1 Target Server : ...
- pip报错ImportError: cannot import name main
编辑pip sudo gedit /usr/bin/pip 修改pip文件: 源文件 from pip import main if __name__ == '__main__': sys.exit( ...
- 【python之路45】tornado的用法 (三)
参考:https://www.cnblogs.com/sunshuhai/articles/6253815.html 一.cookie用法补充 1.cookie的应用场景 浏览器端保存的键值对,每次访 ...
- spark dataframe 将null 改为 nan
由于我要叠加rdd某列的数据,如果加数中出现nan,结果也需要是nan,nan可以做到,但我要处理的数据源中的nan是以null的形式出现的,null不能叠加,而且我也不能删掉含null的行,于是我用 ...