GAN tensorflow 实作
从2014年Ian Goodfellow提出GANs(Generative adversarial networks)以来,GANs可以说是目前深度学习领域最为热门的研究内容之一,这种可以人工生成数据的方法给我们带来了丰富的想象。有研究者已经能够自动生成相当真实的卧室、专辑封面、人脸等图像,并且在此基础上做了一些有趣的事情。当然那些工作可能会相当困难,下面我们来实现一个简单的例子,建立一个能够生成手写数字的GAN。
GAN architecture
首先回顾一下GAN的结构
Generative adversarial networks包含了两个部分,一个是生成器generator ,一个是判别器discriminator 。discriminator能够评估给定一个图像和真实图像的相似程度,或者说有多大可能性是人工生成的图像。discriminator 实质上相当于一个二分类器,在我们的例子中它是一个CNN。generator能根据随机输入的值来得到一个图像,在我们的例子中的generator是deconvolutional neural network。在整个训练迭代过程中,生成器和判别器网络的weights和biases的值依然会根据误差反向传播理论来训练得到。discriminator需要学习如何分辨real images和generator制造的fake images。同时generator会根据discriminator的反馈结果去学习如何生成更加真实的图像以至于discriminator不能分辨。

Loading MNIST data
首先导入tensorflow等需要用到的函数库,TensorFlow中提取了能够非常方便地导入MNIST数据的read_data_sets函数。
import tensorflow as tf
import numpy as np
import datetime
import matplotlib.pyplot as plt
%matplotlib inline
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/")
MNIST中每个图像的初始格式是一个784维的向量。可以使用reshape还原成28x28的图像。
sample_image = mnist.train.next_batch(1)[0]
print(sample_image.shape)
sample_image = sample_image.reshape([28, 28])
plt.imshow(sample_image, cmap='Greys')

Discriminator network
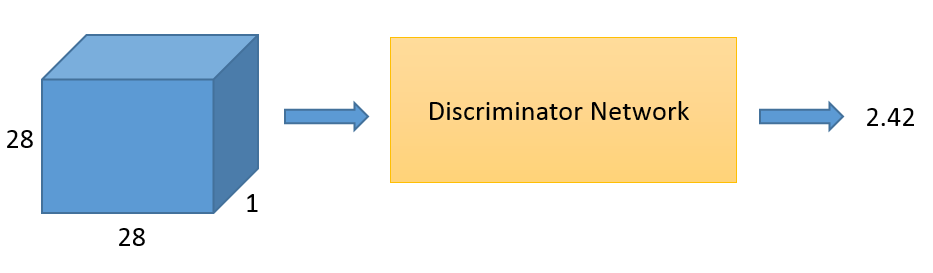
判别器网络实际上和CNN相似,包含两个卷积层和两个全连接层。
def discriminator(images, reuse_variables=None):
with tf.variable_scope(tf.get_variable_scope(), reuse=reuse_variables) as scope:
# 第一个卷积层
# 使用32个5 x 5卷积模板
d_w1 = tf.get_variable('d_w1', [5, 5, 1, 32], initializer=tf.truncated_normal_initializer(stddev=0.02))
d_b1 = tf.get_variable('d_b1', [32], initializer=tf.constant_initializer(0))
d1 = tf.nn.conv2d(input=images, filter=d_w1, strides=[1, 1, 1, 1], padding='SAME')
d1 = d1 + d_b1
d1 = tf.nn.relu(d1)
d1 = tf.nn.avg_pool(d1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# 第二个卷积层
# 使用64个5 x 5卷积模板,每个模板包含32个通道
d_w2 = tf.get_variable('d_w2', [5, 5, 32, 64], initializer=tf.truncated_normal_initializer(stddev=0.02))
d_b2 = tf.get_variable('d_b2', [64], initializer=tf.constant_initializer(0))
d2 = tf.nn.conv2d(input=d1, filter=d_w2, strides=[1, 1, 1, 1], padding='SAME')
d2 = d2 + d_b2
d2 = tf.nn.relu(d2)
d2 = tf.nn.avg_pool(d2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# 第一个全连接层
d_w3 = tf.get_variable('d_w3', [7 * 7 * 64, 1024], initializer=tf.truncated_normal_initializer(stddev=0.02))
d_b3 = tf.get_variable('d_b3', [1024], initializer=tf.constant_initializer(0))
d3 = tf.reshape(d2, [-1, 7 * 7 * 64])
d3 = tf.matmul(d3, d_w3)
d3 = d3 + d_b3
d3 = tf.nn.relu(d3)
# 第二个全连接层
d_w4 = tf.get_variable('d_w4', [1024, 1], initializer=tf.truncated_normal_initializer(stddev=0.02))
d_b4 = tf.get_variable('d_b4', [1], initializer=tf.constant_initializer(0))
d4 = tf.matmul(d3, d_w4) + d_b4
# 最后输出一个非尺度化的值
return d4
Generator network
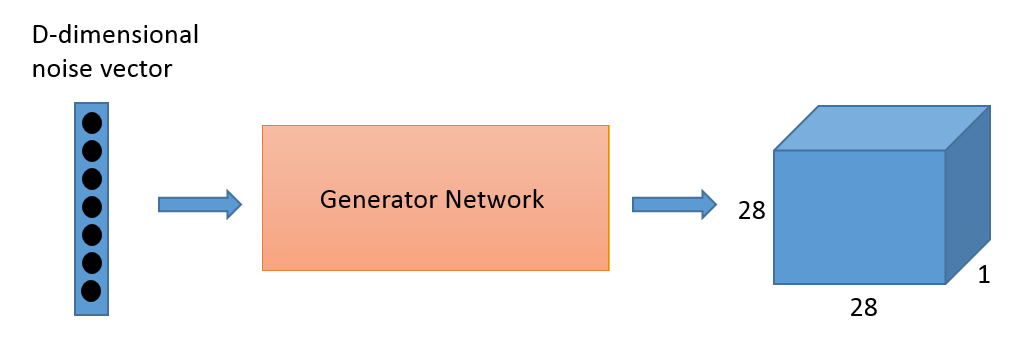
生成器根据输入的随机的d维向量,最终输出一个28 x 28图像(实际用784维向量表示)。在生成器的每层将会使用到ReLU激活函数和batch normalization。
batch normalization 可能会有两个好处:更快的训练速度和更高的全局准确率。

def generator(z, batch_size, z_dim):
g_w1 = tf.get_variable('g_w1', [z_dim, 3136], dtype=tf.float32,
initializer=tf.truncated_normal_initializer(stddev=0.02))
g_b1 = tf.get_variable('g_b1', [3136], initializer=tf.truncated_normal_initializer(stddev=0.02))
g1 = tf.matmul(z, g_w1) + g_b1
g1 = tf.reshape(g1, [-1, 56, 56, 1])
g1 = tf.contrib.layers.batch_norm(g1, epsilon=1e-5, scope='bn1')
g1 = tf.nn.relu(g1)
g_w2 = tf.get_variable('g_w2', [3, 3, 1, z_dim/2], dtype=tf.float32,
initializer=tf.truncated_normal_initializer(stddev=0.02))
g_b2 = tf.get_variable('g_b2', [z_dim/2], initializer=tf.truncated_normal_initializer(stddev=0.02))
g2 = tf.nn.conv2d(g1, g_w2, strides=[1, 2, 2, 1], padding='SAME')
g2 = g2 + g_b2
g2 = tf.contrib.layers.batch_norm(g2, epsilon=1e-5, scope='bn2')
g2 = tf.nn.relu(g2)
g2 = tf.image.resize_images(g2, [56, 56])
g_w3 = tf.get_variable('g_w3', [3, 3, z_dim/2, z_dim/4], dtype=tf.float32,
initializer=tf.truncated_normal_initializer(stddev=0.02))
g_b3 = tf.get_variable('g_b3', [z_dim/4], initializer=tf.truncated_normal_initializer(stddev=0.02))
g3 = tf.nn.conv2d(g2, g_w3, strides=[1, 2, 2, 1], padding='SAME')
g3 = g3 + g_b3
g3 = tf.contrib.layers.batch_norm(g3, epsilon=1e-5, scope='bn3')
g3 = tf.nn.relu(g3)
g3 = tf.image.resize_images(g3, [56, 56])
g_w4 = tf.get_variable('g_w4', [1, 1, z_dim/4, 1], dtype=tf.float32,
initializer=tf.truncated_normal_initializer(stddev=0.02))
g_b4 = tf.get_variable('g_b4', [1], initializer=tf.truncated_normal_initializer(stddev=0.02))
g4 = tf.nn.conv2d(g3, g_w4, strides=[1, 2, 2, 1], padding='SAME')
g4 = g4 + g_b4
g4 = tf.sigmoid(g4)
# 输出g4的维度: batch_size x 28 x 28 x 1
return g4
Training a GAN
# 清除默认图的堆栈,并设置全局图为默认图
tf.reset_default_graph()
batch_size = 50
z_placeholder = tf.placeholder(tf.float32, [None, z_dimensions], name='z_placeholder')
x_placeholder = tf.placeholder(tf.float32, shape = [None,28,28,1], name='x_placeholder')
Gz = generator(z_placeholder, batch_size, z_dimensions)
Dx = discriminator(x_placeholder)
Dg = discriminator(Gz, reuse_variables=True)
#discriminator 的loss 分为两部分
d_loss_real = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits = Dx, labels = tf.ones_like(Dx)))
d_loss_fake = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits = Dg, labels = tf.zeros_like(Dg)))
d_loss=d_loss_real + d_loss_fake
# Generator的目标是生成尽可能真实的图像,所以计算Dg和1的loss
g_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits = Dg, labels = tf.ones_like(Dg)))
上面计算了loss 函数,接下来需要定义优化器optimizer。generator的optimizer只更新generator的网络权值,训练discriminator的时候需要固定generator的网络权值同时更新discriminator的权值。
tvars = tf.trainable_variables()
#分别保存discriminator和generator的权值
d_vars = [var for var in tvars if 'd_' in var.name]
g_vars = [var for var in tvars if 'g_' in var.name]
print([v.name for v in d_vars])
print([v.name for v in g_vars])
Adam是GAN的最好的优化方法,它利用了自适应学习率和学习惯性。调用Adam's minimize function来寻找最小loss,并且通过var_list来指定需要更新的参数。
d_trainer = tf.train.AdamOptimizer(0.0003).minimize(d_loss, var_list=d_vars)
g_trainer = tf.train.AdamOptimizer(0.0001).minimize(g_loss, var_list=g_vars)
使用TensorBoard来观察训练情况,打开terminal输入
tensorboard --logdir=tensorboard/
打开TensorBoard的地址是http://localhost:6006
tf.get_variable_scope().reuse_variables()
tf.summary.scalar('Generator_loss', g_loss)
tf.summary.scalar('Discriminator_loss_real', d_loss_real)
tf.summary.scalar('Discriminator_loss_fake', d_loss_fake)
images_for_tensorboard = generator(z_placeholder, batch_size, z_dimensions)
tf.summary.image('Generated_images', images_for_tensorboard, 5)
merged = tf.summary.merge_all()
logdir = "tensorboard/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S") + "/"
writer = tf.summary.FileWriter(logdir, sess.graph)
下面进行迭代更新参数。对discriminator先进行预训练,这样对generator的训练有好处。
sess = tf.Session()
sess.run(tf.global_variables_initializer())
# 对discriminator的预训练
for i in range(300):
z_batch = np.random.normal(0, 1, size=[batch_size, z_dimensions])
real_image_batch = mnist.train.next_batch(batch_size)[0].reshape([batch_size, 28, 28, 1])
_, __, dLossReal, dLossFake = sess.run([d_trainer_real, d_trainer_fake, d_loss_real, d_loss_fake],
{x_placeholder: real_image_batch, z_placeholder: z_batch})
if(i % 100 == 0):
print("dLossReal:", dLossReal, "dLossFake:", dLossFake)
# 交替训练 generator和discriminator
for i in range(100000):
real_image_batch = mnist.train.next_batch(batch_size)[0].reshape([batch_size, 28, 28, 1])
z_batch = np.random.normal(0, 1, size=[batch_size, z_dimensions])
# 用 real and fake images对discriminator训练
_,dLossReal, dLossFake = sess.run([d_trainer,d_loss_real, d_loss_fake],
{x_placeholder: real_image_batch, z_placeholder: z_batch})
# 训练 generator
z_batch = np.random.normal(0, 1, size=[batch_size, z_dimensions])
_ = sess.run(g_trainer, feed_dict={z_placeholder: z_batch})
if i % 10 == 0:
# 更新 TensorBoard 统计
z_batch = np.random.normal(0, 1, size=[batch_size, z_dimensions])
summary = sess.run(merged, {z_placeholder: z_batch, x_placeholder: real_image_batch})
writer.add_summary(summary, i)
if i % 100 == 0:
# 每 100 iterations, 输出一个生成的图像
print("Iteration:", i, "at", datetime.datetime.now())
z_batch = np.random.normal(0, 1, size=[1, z_dimensions])
generated_images = generator(z_placeholder, 1, z_dimensions)
images = sess.run(generated_images, {z_placeholder: z_batch})
plt.imshow(images[0].reshape([28, 28]), cmap='Greys')
plt.show()
# 输出discriminator的值
im = images[0].reshape([1, 28, 28, 1])
result = discriminator(x_placeholder)
estimate = sess.run(result, {x_placeholder: im})
print("Estimate:", estimate)
More
众所周知,由于GAN的表达能力非常强,几乎能够刻画任意概率分布,GAN的训练过程是非常困难的(容易跑偏)。如果没有找到合适的超参和网络结构,并且进行合理的训练过程,容易在discriminator和generator中间出现一方压倒另一方的情况。
一种常见失败情况是discriminator压倒generator的时候,对generator生成的每个image,discriminator几乎都能认为是fake image,这时generator几乎找不到下降的梯度。因此对discriminator的输出并没有经过sigmoid 函数(sigmoid function 会将输出推向0或1)。
另一种失败情况是“mode collapse”,指的是generator发现并利用了discriminator某些漏洞。例如generator发现某个图像a能让discriminator判定为真,那么generator可能会学习到:对任意输入的noise vector z,只需要输出和a几乎相同的图像。
研究人员已经指出了一部分对建立更加稳定的GAN有帮助的GAN hacks
Resources
GAN tensorflow 实作的更多相关文章
- Generative Adversarial Nets(GAN Tensorflow)
Generative Adversarial Nets(简称GAN)是一种非常流行的神经网络. 它最初是由Ian Goodfellow等人在NIPS 2014论文中介绍的. 这篇论文引发了很多关于神经 ...
- Tensorflow[源码安装时bazel行为解析]
0. 引言 通过源码方式安装,并进行一定程度的解读,有助于理解tensorflow源码,本文主要基于tensorflow v1.8源码,并借鉴于如何阅读TensorFlow源码. 首先,自然是需要去b ...
- TensorFlow.NET机器学习入门【0】前言与目录
曾经学习过一段时间ML.NET的知识,ML.NET是微软提供的一套机器学习框架,相对于其他的一些机器学习框架,ML.NET侧重于消费现有的网络模型,不太好自定义自己的网络模型,底层实现也做了高度封装. ...
- 『cs231n』通过代码理解gan网络&tensorflow共享变量机制_上
GAN网络架构分析 上图即为GAN的逻辑架构,其中的noise vector就是特征向量z,real images就是输入变量x,标签的标准比较简单(二分类么),real的就是tf.ones,fake ...
- 『TensorFlow』通过代码理解gan网络_中
『cs231n』通过代码理解gan网络&tensorflow共享变量机制_上 上篇是一个尝试生成minist手写体数据的简单GAN网络,之前有介绍过,图片维度是28*28*1,生成器的上采样使 ...
- 利用tensorflow训练简单的生成对抗网络GAN
对抗网络是14年Goodfellow Ian在论文Generative Adversarial Nets中提出来的. 原理方面,对抗网络可以简单归纳为一个生成器(generator)和一个判断器(di ...
- TensorFlow从1到2(十二)生成对抗网络GAN和图片自动生成
生成对抗网络的概念 上一篇中介绍的VAE自动编码器具备了一定程度的创造特征,能够"无中生有"的由一组随机数向量生成手写字符的图片. 这个"创造能力"我们在模型中 ...
- GAN生成式对抗网络(二)——tensorflow代码示例
代码实现 当初学习时,主要学习的这个博客 https://xyang35.github.io/2017/08/22/GAN-1/ ,写的挺好的. 本文目的,用GAN实现最简单的例子,帮助认识GAN算法 ...
- 不要怂,就是GAN (生成式对抗网络) (三):判别器和生成器 TensorFlow Model
在 /home/your_name/TensorFlow/DCGAN/ 下新建文件 utils.py,输入如下代码: import scipy.misc import numpy as np # 保存 ...
随机推荐
- es6种for循环中let和var区别
let和var区别: for(var i=0;i<5;i++){ setTimeout(()=>{ console.log(i);//5个5 },100) } console.log(i) ...
- Django2.2 中间件的使用
中间件:AOP中间件,在Django中内置了一些项目自带的中间件,那么中间件是什么呢 这里说明一下,一开始我也不太清楚中间件到底有什么用(大家也别急,下面会有详细的例子给大家解释)--------&g ...
- 《【面试突击】— Redis篇》--Redis都有哪些数据类型?分别在哪些场景下使用比较合适?
能坚持别人不能坚持的,才能拥有别人不能拥有的.关注编程大道公众号,让我们一同坚持心中所想,一起成长!! <[面试突击]— Redis篇>--Redis都有哪些数据类型?分别在哪些场景下使用 ...
- light题目讲解 7.25模拟赛T1
心得:这一道题其实就是自己打暴力打出来的 没有想到正解真的就是暴力枚举 我的做法是这样的 就是枚举A字符串中长度为x的子串 看它是不是B串的子序列 接下来是我的绝望考试代码(100分AC) //lig ...
- Unity_Dungeonize 随机生成迷宫
本文对随机生成迷宫的实现思路进行记录,其作用在于为游戏过程提供随机性以及节省开发周期,下面是Dungeonize的结构 随机迷宫的生成主要包括几个阶段 1.生成房间体结构,为墙体,自定义房间,自定义物 ...
- Spring学习记录4——Spring对DAO的支持
Spring对DAO的支持 随着持久化技术的持续发展,Spring对多个持久化技术提供了集成支持,包括Hibernate.MyBatis.JPA.JDO:此外,还提供了一个简化JDBC API操作的S ...
- 史上最简单的vi教程,10分钟包教会
从第一次接触vi/vim到现在已经十几年了,在这个过程中,来来回回,反反复复,学习vi很多次了. 虽然关于vi的使用,我还远未达到"专家"的水平,但对于vi的使用,我有话说. 1. ...
- PHPStorm 最新版下载
2019最新版phpstorm 包含其他版下载地址 https://www.jetbrains.com/phpstorm/download/other.html
- EsClientRHL-elasticsearch java客户端开源工具
EsClientRHL是一个可基于springboot的elasticsearch 客户端调用封装工具,通过elasticsearch官网推荐的RestHighLevelClient实现,内置了es索 ...
- idea初使用之自动编译
原文地址:https://blog.csdn.net/diaomeng11/article/details/73826564/ 因为公司需要,方便使用框架以及代码整合,使用同一开发集成环境idea,因 ...