Kafka Connect HDFS
概述
Kafka 的数据如何传输到HDFS?如果仔细思考,会发现这个问题并不简单。
不妨先想一下这两个问题?
1)为什么要将Kafka的数据传输到HDFS上?
2)为什么不直接写HDFS而要通过Kafka?
HDFS一直以来是为离线数据的存储和计算设计的,因此对实时事件数据的写入并不友好,而Kafka生来就是为实时数据设计的,但是数据在Kafka上无法使用离线计算框架来作批量离线分析。
那么,Kafka为什么就不能支持批量离线分析呢?想象我们将Kafka的数据按天拆分topic,并建足够多的分区,然后通过Spark-Streaming,Flink,又或者是KSql等来处理单个topic中的所有数据--这就相当于处理某一天的所有数据。这种计算的性能从原理上来说是不比Spark或者Hive离线计算差的。
而且更好的是,这样我们就不用将kafka中的数据翻来覆去的导到hdfs,而是直接在kafka上作计算。
后面我们将对此展开更多的讨论,这里先回归正题,在常见的大数据系统架构(lambda)中,通常会将kafka中的数据导入到HDFS来作离线的数据分析。在Kafka的官方wiki中提到了这样的一些方式来对接Hadoop生态。
https://cwiki.apache.org/confluence/display/KAFKA/Ecosystem

其中最常用的是Flume,尤其是在CDH集群中,能够很方便的集成Flume和Kafka。
而HortonWorks在其3.0之后的HDP版本中去掉了Flume,原因是想将Flume放到HDF(HortonWorks Data Flow)中,这个做法还是比较失策的,虽然成全了HDF,但却让HDP失去了其完整性。
本案例中使用Ambari 2.7.4+HDP3.1 由于缺少了Flume组件,因此使用Kafka Connect HDFS来连接Hadoop。
下面记录了连接过程。以下操作的基础是,有一个搭建好的Ambari集群,并安装了Kafka+HDFS。
参考安装文档:
https://docs.confluent.io/3.0.0/connect/connect-hdfs/docs/index.html
项目github地址:
https://github.com/confluentinc/kafka-connect-hdfs
一.下载软件包
[work@node2 ~]$ wget http://packages.confluent.io/archive/3.0/confluent-3.0.0-2.11.zip
[work@node2 ~]$ unzip confluent-3.0.0-2.11.zip
二.快速体验Kafka-Connect
下面的例子其实不需要下载Confluent,是Kafka2.0中自带的FileSource和FileSink,而Confluent中也包含了这些功能,如果需要用到Kafka Connect HDFS,就需要Confluent了,这里只是用最简单的例子快速了解Kafka-Connect的用法。
2.1 在主目录下写test.txt文件,内容如下
[work@node2 confluent-3.0.0]$ ls
bin etc README.archive share src test.txt
[work@node2 confluent-3.0.0]$ cat test.txt
foo
bar
New Record
New Record
2.2 修改etc/kafka/connect-standalone.properties
[work@node2 confluent-3.0.0]$ vi etc/kafka/connect-standalone.properties
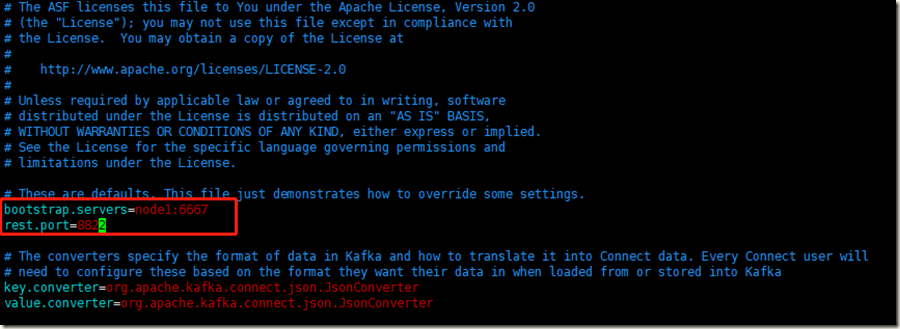
Ambari的kafka端口不是9092,而是6667。
Connector的rest.port默认是8083,和Ambari中安装的Druid的端口有冲突,所以改成8822。
2.3 运行命令
[work@node2 confluent-3.0.0]$ ./bin/connect-standalone etc/kafka/connect-standalone.properties etc/kafka/connect-file-source.properties etc/kafka/connect-file-sink.properties
2.4 生成sink文件
[work@node2 confluent-3.0.0]$ ls
bin etc logs README.archive share src test.sink.txt test.txt
[work@node2 confluent-3.0.0]$ cat test.sink.txt
foo
bar
New Record
New Record
尝试新加一行数据
[work@node2 confluent-3.0.0]$ echo "Hello World" >> test.txt
[work@node2 confluent-3.0.0]$ cat test.sink.txt
foo
bar
New Record
New Record
Hello World
2.5 分析 etc/kafka/connect-file-source.properties 和 etc/kafka/connecfile-sink.properties
etc/kafka/connect-file-source.properties 如下
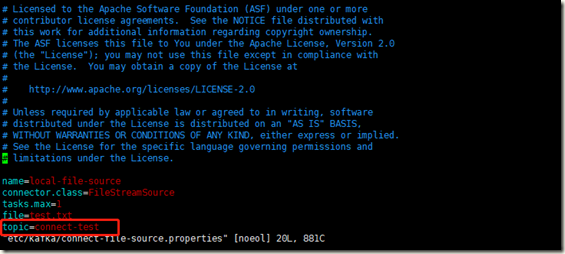
etc/kafka/connecfile-sink.properties 如下
通过Kafka Console Consumer查看 connect-test topic
[work@node2 confluent-3.0.0]$ ./bin/kafka-console-consumer --bootstrap-server node1:6667 --topic connect-test --from-beginning --new-consumer
{"schema":{"type":"string","optional":false},"payload":"foo"}
{"schema":{"type":"string","optional":false},"payload":"bar"}
{"schema":{"type":"string","optional":false},"payload":"New Record"}
{"schema":{"type":"string","optional":false},"payload":"New Record"}
{"schema":{"type":"string","optional":false},"payload":"Hello World"}
2.6 Converter
从上一节中可以看到一行行json格式的数据,其中payload是原始数据。在这里connect-test这个topic有点类似于flume中的channel的角色,用来连接source和sink缓存中间数据。
当数据量非常大的情况下,这种额外的处理会造成性能和空间的浪费。
[work@node2 confluent-3.0.0]$ vi etc/kafka/connect-standalone.properties

修改connect的配置,数据在传递过程中将不再作任何处理。StringConverter源码传送门:
key.converter=org.apache.kafka.connect.storage.StringConverter
value.converter=org.apache.kafka.connect.storage.StringConverter
key.converter.schemas.enable=false
value.converter.schemas.enable=false
internal.key.converter=org.apache.kafka.connect.storage.StringConverter
internal.value.converter=org.apache.kafka.connect.storage.StringConverter
internal.key.converter.schemas.enable=false
internal.value.converter.schemas.enable=false
三.通过Kafka将数据写入到HDFS
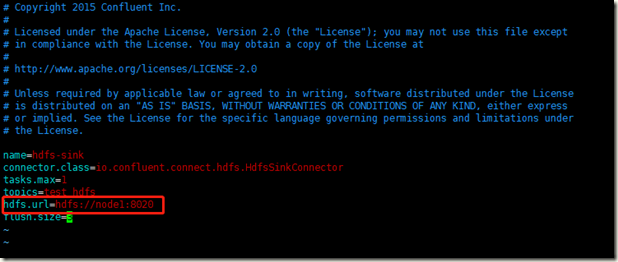
如果不使用Avro格式来存储和处理数据,那么这里要加一个配置
format.class=io.confluent.connect.hdfs.string.StringFormat
但是比较遗憾的是Confluent3.0.0的版本中不包含这个类。因此这里我使用了confluent-5.3.1的版本,然后再通过如下命令安装kafka-connect-hdfs
confluent-hub install confluentinc/kafka-connect-hdfs:latest
启动
bin/connect-standalone etc/kafka/connect-standalone.properties share/confluent-hub-components/confluentinc-kafka-connect-hdfs/etc/quickstart-hdfs.properties
所有写入到test_hdfs这个topic中的数据都会写入到hdfs中。
[work@node2 confluent-5.3.1]$ bin/kafka-console-producer --broker-list node1:6667 --topic test_hdfs
>123
>456
>789
>13
>213w
>asd
>
查看hdfs中的结果
[work@node2 ~]$ hadoop fs -ls /topics/test_hdfs/partition=0
Found 2 items
-rw-r--r-- 3 work work 12 2019-11-08 10:18 /topics/test_hdfs/partition=0/test_hdfs+0+0000000000+0000000002.txt
-rw-r--r-- 3 work work 12 2019-11-08 10:20 /topics/test_hdfs/partition=0/test_hdfs+0+0000000003+0000000005.txt
[work@node2 ~]$ hadoop fs -cat /topics/test_hdfs/partition=0/test_hdfs+0+0000000000+0000000002.txt
123
123
456
Connect HDFS完毕。
三.总结
优势:
1.操作简单,部署方便。
2.可以直接和hive的元数据集成自动生成分区。
缺点:
1.支持的数据格式少,avro在国内并不流行。
2.一个致命缺陷,不支持压缩!!不知道是confluent的疏忽还是有特地的考虑?因为不支持压缩,使用这个组件会浪费80%的存储空间,无实用性。
Kafka Connect HDFS的更多相关文章
- 使用kafka connect,将数据批量写到hdfs完整过程
版权声明:本文为博主原创文章,未经博主允许不得转载 本文是基于hadoop 2.7.1,以及kafka 0.11.0.0.kafka-connect是以单节点模式运行,即standalone. 首先, ...
- Kafka到Hdfs的数据Pipeline整理
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 找时间总结整理了下数据从Kafka到Hdfs的一些pipeline,如下 1> Kafka ...
- Streaming data from Oracle using Oracle GoldenGate and Kafka Connect
This is a guest blog from Robin Moffatt. Robin Moffatt is Head of R&D (Europe) at Rittman Mead, ...
- Build an ETL Pipeline With Kafka Connect via JDBC Connectors
This article is an in-depth tutorial for using Kafka to move data from PostgreSQL to Hadoop HDFS via ...
- Kafka+Storm+HDFS整合实践
在基于Hadoop平台的很多应用场景中,我们需要对数据进行离线和实时分析,离线分析可以很容易地借助于Hive来实现统计分析,但是对于实时的需求Hive就不合适了.实时应用场景可以使用Storm,它是一 ...
- Kafka connect快速构建数据ETL通道
摘要: 作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 业余时间调研了一下Kafka connect的配置和使用,记录一些自己的理解和心得,欢迎 ...
- [转载] Kafka+Storm+HDFS整合实践
转载自http://www.tuicool.com/articles/NzyqAn 在基于Hadoop平台的很多应用场景中,我们需要对数据进行离线和实时分析,离线分析可以很容易地借助于Hive来实现统 ...
- 打造实时数据集成平台——DataPipeline基于Kafka Connect的应用实践
导读:传统ETL方案让企业难以承受数据集成之重,基于Kafka Connect构建的新型实时数据集成平台被寄予厚望. 在4月21日的Kafka Beijing Meetup第四场活动上,DataPip ...
- kafka connect rest api
1. 获取 Connect Worker 信息curl -s http://127.0.0.1:8083/ | jq lenmom@M1701:~/workspace/software/kafka_2 ...
随机推荐
- 多对多关联懒加载导致failed to lazily initialize a collection of role: 实体类, could not initialize proxy - no Session 追加配置fetch = FetchType.EAGER解决
一篇文章需要关联很多个标签,所以他们呈一对多(多对多)的关系 org.springframework.web.util.NestedServletException: Request processi ...
- Python爬虫工程师必学——App数据抓取实战
Python爬虫工程师必学 App数据抓取实战 整个课程都看完了,这个课程的分享可以往下看,下面有链接,之前做java开发也做了一些年头,也分享下自己看这个视频的感受,单论单个知识点课程本身没问题,大 ...
- VS中warning MSB8004和error MSB4018解决方案
问题如下: warning MSB8004: Output Directory does not end with a trailing slash. This build instance wil ...
- VS2015使用Nuget安装OpenCV3.X以及Python3安装OpenCV3.X
VS2015已经自带Nuget安装工具了,所以,新建一个项目,点击管理Nuget包 搜索OpenCV3 注意,目前只有这个版本支持VS2015,也就是平台工具集可以为vs140,其他的都会报错,报错我 ...
- 01Redis入门指南笔记(简介、安装、配置)
一:简介 Redis是一个开源的高性能key-value数据库.Redis是Remote DIctionary Server(远程字典服务器)的缩写,它以字典结构存储数据,并允许其他应用通过TCP协议 ...
- Wamp 扩展Oracle Oci
参考网址: http://www.cnblogs.com/azhw/p/4599632.html
- 使用Charles在iOS6上进行抓包
抓取Web页面的网络请求很容易,Chrome和Firefox都很容易做到.iOS APP如何抓包呢?其实也很容易,我比较喜欢使用 Charles. 我用的是Mac电脑,首先建立一个热点,然后让iOS设 ...
- CodeChef--EQUAKE
题目链接 Earthquake in Bytetown! Situation is getting out of control! All buildings in Bytetown stand on ...
- scanf("%c", &ch)和scanf(" %c", &ch)和scanf("%s", str)的注意事项
scanf("%c", &ch)和scanf(" %c", &ch): %c会读取回车和空格,所以一定要使用后者,即在%c前面加一个空格. %s ...
- Mybatis+Spring实现Mysql读写分离
使用spring AbstractRoutingDatasource实现多数据源 public class DynamicDataSource extends AbstractRoutingDataS ...