python简单爬豆瓣电影排名
爬豆瓣电影
网站分析:
1 打开https://movie.douban.com,选择 【排行榜】,然后随便选择一类型,我这里选择科幻
2 一直浏览网页,发现没有下一的标签,是下滑再加载的,可以判定使用了 ajax 请求,进行异步的加载

检查请求信息:
1.右键【检查】>【Network】
2 找url
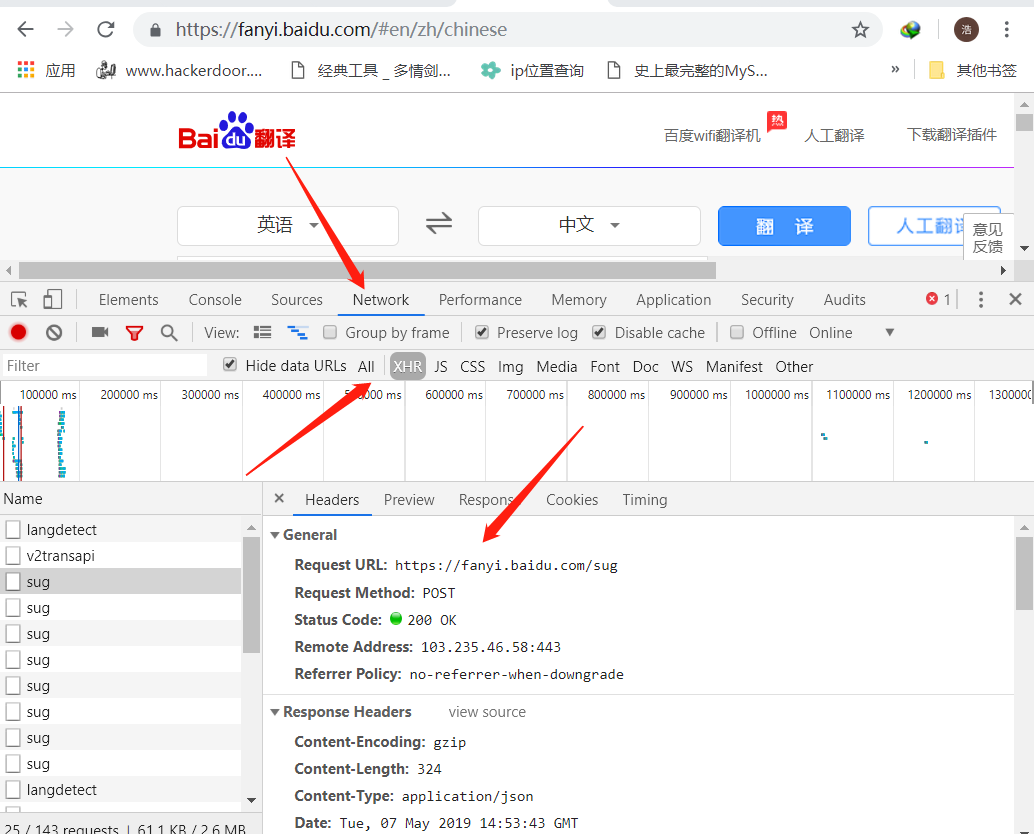
简单实现代码
from urllib import request
import json
import time headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36"}
# url 信息:interval_id 表示排名段 可修改 ,limit 限制20个,就是每页请求多少个
url = "https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&start=20&limit=20" rsp = request.urlopen(url)
data = rsp.read().decode() data = json.loads(data) print(data)
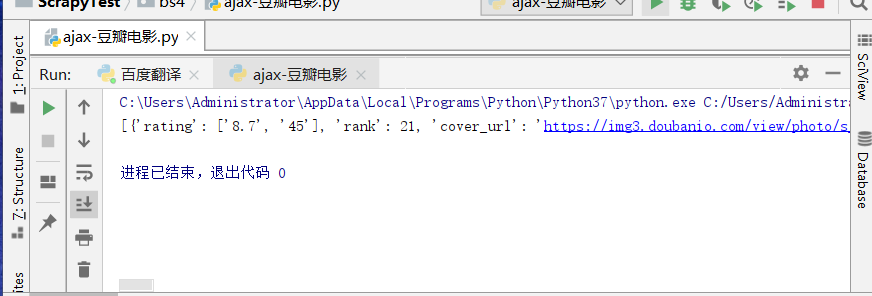
运行效果
优化输出格式,代码
from urllib import request
import json url = "https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=20&limit=20" rsp = request.urlopen(url)
data = rsp.read().decode() data = json.loads(data) #遍历输出每个'k'和‘v’的值
for item in data:
print("排名:", item['rank'],"\n",
"名称:",item['title'],"\n",
"类型:",item['types'],"\n",
"主演:",item['actors'],"\n",
"国家:",item['regions'],"\n",
"分数:",item['score'],"\n",
"图片:",item['cover_url'],"\n---------------")
优化效果

好了,这样的效果,看起来更顺眼了
python简单爬豆瓣电影排名的更多相关文章
- Python:python抓取豆瓣电影top250
一直对爬虫感兴趣,学了python后正好看到某篇关于爬取的文章,就心血来潮实战一把吧. 实现目标:抓取豆瓣电影top250,并输出到文件中 1.找到对应的url:https://movie.douba ...
- Python抓取豆瓣电影top250!
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理.作者:404notfound 一直对爬虫感兴趣,学了python后正好看到 ...
- Scala学习之爬豆瓣电影
简单使用Scala和Jsoup对豆瓣电影进行爬虫,技术比較简单易学. 写文章不易,欢迎大家採我的文章,以及给出实用的评论,当然大家也能够关注一下我的github:多谢. 1.爬虫前期准备 找好须要抓取 ...
- 2_爬豆瓣电影_ajax动态加载
爬豆瓣 什么是 AJAX ? AJAX 是一种在无需重新加载整个网页的情况下,能够更新部分网页的技术. AJAX = Asynchronous JavaScript and XML(AJAX = 异步 ...
- Python简单爬取Amazon图片-其他网站相应修改链接和正则
简单爬取Amazon图片信息 这是一个简单的模板,如果需要爬取其他网站图片信息,更改URL和正则表达式即可 1 import requests 2 import re 3 import os 4 de ...
- python爬虫--用xpath爬豆瓣电影
步骤 将目标网站下的页面抓取下来 将抓取下来的数据根据一定规则进行提取 具体流程 将目标网站下的页面抓取下来 1. 倒库 import requests 2.头信息(有时候可不写) headers ...
- 一、python简单爬取静态网页
一.简单爬虫框架 简单爬虫框架由四个部分组成:URL管理器.网页下载器.网页解析器.调度器,还有应用这一部分,应用主要是NLP配合相关业务. 它的基本逻辑是这样的:给定一个要访问的URL,获取这个ht ...
- python 简单爬取今日头条热点新闻(一)
今日头条如今在自媒体领域算是比较强大的存在,今天就带大家利用python爬去今日头条的热点新闻,理论上是可以做到无限爬取的: 在浏览器中打开今日头条的链接,选中左侧的热点,在浏览器开发者模式netwo ...
- Python简单爬取图书信息及入库
课堂上老师布置了一个作业,如下图所示: 就是简单写一个借书系统. 大概想了一下流程,登录-->验证登录信息-->登录成功跳转借书界面-->可查看自己的借阅书籍以及数量... 登录可以 ...
随机推荐
- System.Web.HttpCookie.cs
ylbtech-System.Web.HttpCookie.cs 1.程序集 System.Web, Version=4.0.0.0, Culture=neutral, PublicKeyToken= ...
- Docker系列(四):Docker容器互联
基于Volume的互联 为什么需要Volume docker文件系统是分层的,下面的是全部是只读的,最上面的是可写层,容器中的进程如果修改了某个文件,比如修改了下层的某个文件,其实是在最顶层复制下层文 ...
- 基于token的验证
认证.权限和限制 身份验证是将传入请求与一组标识凭据(例如请求来自的用户或其签名的令牌)相关联的机制.然后 权限 和 限制 组件决定是否拒绝这个请求. 简单来说就是: 认证确定了你是谁 权限确定你能不 ...
- visual studio 2017--括号自动补全
---恢复内容开始--- 平常在visual studio中编写C++代码,一般括号之类的都是自动补全的,最近想用来编写Python,发现括号不能补全了,很不适应. Python编写时好像括号好像默认 ...
- login-Linux必学的60个命令
1.作用 login的作用是登录系统,它的使用权限是所有用户. 2.格式 login [name][-p ][-h 主机名称] 3.主要参数 -p:通知login保持现在的环境参数. -h:用来向远程 ...
- 输出内容 document.write() 可用于直接向 HTML 输出流写内容。简单的说就是直接在网页中输出内容
输出内容(document.write) document.write() 可用于直接向 HTML 输出流写内容.简单的说就是直接在网页中输出内容. 第一种:输出内容用""括起,直 ...
- sqllocaldb
创建实例 sqllocaldb create v12.0 启动实例 sqllocaldb start v12.0
- 廖雪峰Java13网络编程-2Email编程-2接收Email
1接收Email协议类型 接收Email:收件人通过MUA软件把邮件从MDA抓取到本地计算机的过程. 1.1 POP3 从MUA到MDA使用最广泛的是协议是POP3 Post Office Proto ...
- Python基础笔记_Number类型
import random import math import operator # 数字 # # 1. Python math 模块.cmath 模块 ''' Python math 模块.cma ...
- 0821NOIP模拟测试赛后总结
60分rank20.挂.完. 赛时状态 不是很好.老眼混花看错无数题目信息. 倒不是很困.尽管昨天晚上为了某个该死的s-h-s-j活动报告忙到了今天,但我不得不说车上的睡眠还是挺好的. 照例通读三道题 ...