Redis 小调研
一、 概况:
Redis是一款开源的、网络化的、基于内存的、可进行数据持久化的Key-Value存储系统。它的数据模型建立在外层,类似于其它结构化存储系统,是通过Key映射Value的方式来建立字典以保存数据,有别于其它结构化存储系统的是,它支持多类型存储,包括String、List、Set、Sortset和Hash等,你可以在这些数据类型上做很多原子性操作。
在操作方面,Redis基于TCP协议的特性使得它可以通过管道的方式进行数据操作,Redis本身提供了一个可连接Server的客户端,通过客户端,可方便地进行数据存取操作。
Redis具有以下优点:
a。单线程,利用redis队列技术并将访问变为串行访问,消除了传统数据库串行控制的开销
b。redis具有快速和持久化的特征,速度快,因为数据存在内存中。
c。分布式读写分离模式
d。支持丰富数据类型
e。支持事务,操作都是原子性,所谓原子性就是对数据的更改要么全部执行,要不全部不执行。
f。可用于缓存,消息,按key设置过期时间,过期后自动删除。
h。支持多种主流语言交互。
Redis最适合所有数据in-momory的场景,虽然Redis也提供持久化功能,但实际更多的是一个disk-backed的功能,跟传统意义上的持久化有比较大的差别。
二、 原理简介:
redis核心对象
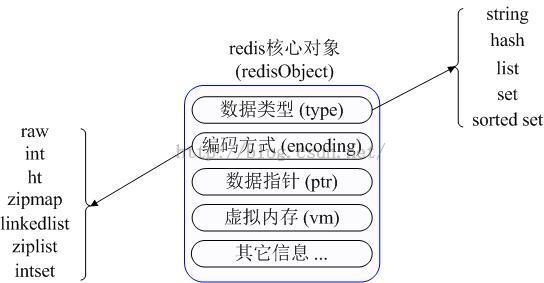
redisObject
Redis内部使用一个redisObject对象来表示所有的key和value。
redisObject最主要的信息如上图所示:
type代表一个value对象具体是何种数据类型
encoding是不同数据类型在redis内部的存储方式,比如:type=string代表value存储的是一个普通字符串,那么对应的encoding可以是raw或者是int,如果是int则代表实际redis内部是按数值型类存储和表示这个字符串的,当然前提是这个字符串本身可以用数值表示,比如:"123""456"这样的字符串。
vm字段,只有打开了Redis的虚拟内存功能,此字段才会真正的分配内存,该功能默认是关闭状态的。
五种数据类型的使用和内部实现方式:
1)String
常用命令:set/get/decr/incr/mget等;
应用场景:String是最常用的一种数据类型,普通的key/value存储都可以归为此类;
实现方式:String在redis内部存储默认就是一个字符串,被redisObject所引用,当遇到incr、decr等操作时会转成数值型进行计算,此时redisObject的encoding字段为int。
2)Hash
常用命令:hget/hset/hgetall等
应用场景:我们要存储一个用户信息对象数据,其中包括用户ID、用户姓名、年龄和生日,通过用户ID我们希望获取该用户的姓名或者年龄或者生日;
实现方式:Redis的Hash实际是内部存储的Value为一个HashMap,并提供了直接存取这个Map成员的接口。如图2所示,Key是用户ID,value是一个Map。这个Map的key是成员的属性名,value是属性值。这样对数据的修改和存取都可以直接通过其内部Map的Key(Redis里称内部Map的key为field),也就是通过key(用户ID)+field(属性标签)就可以操作对应属性数据。当前HashMap的实现有两种方式:当HashMap的成员比较少时Redis为了节省内存会采用类似一维数组的方式来紧凑存储,而不会采用真正的HashMap结构,这时对应的value的redisObject的encoding为zipmap,当成员数量增大时会自动转成真正的HashMap,此时encoding为ht。
3)List
常用命令:lpush/rpush/lpop/rpop/lrange等;
应用场景:Redislist的应用场景非常多,也是Redis最重要的数据结构之一,比如twitter的关注列表,粉丝列表等都可以用Redis的list结构来实现;
实现方式:Redislist的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销,Redis内部的很多实现,包括发送缓冲队列等也都是用的这个数据结构。
4)Set
常用命令:sadd/spop/smembers/sunion等;
应用场景:Redisset对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的;
实现方式:set的内部实现是一个value永远为null的HashMap,实际就是通过计算hash的方式来快速排重的,这也是set能提供判断一个成员是否在集合内的原因。
5)SortedSet
常用命令:zadd/zrange/zrem/zcard等;
应用场景:Redissortedset的使用场景与set类似,区别是set不是自动有序的,而sortedset可以通过用户额外提供一个优先级(score)的参数来为成员排序,并且是插入有序的,即自动排序。当你需要一个有序的并且不重复的集合列表,那么可以选择sortedset数据结构,比如twitter的publictimeline可以以发表时间作为score来存储,这样获取时就是自动按时间排好序的。
实现方式:Redissortedset的内部使用HashMap和跳跃表(SkipList)来保证数据的存储和有序,HashMap里放的是成员到score的映射,而跳跃表里存放的是所有的成员,排序依据是HashMap里存的score,使用跳跃表的结构可以获得比较高的查找效率,并且在实现上比较简单。
Redis的持久化
Redis虽然是基于内存的存储系统,但是它本身是支持内存数据持久化的,而且提供两种主要的持久化策略:RDB快照和AOF日志。
RDB快照:Redis支持将当前数据的快照存成一个数据文件的持久化机制。
但是一个持续写入的数据库如何生成快照呢?Redis借助了fork命令的copyonwrite机制。在生成快照时,将当前进程fork出一个子进程,然后在子进程中循环所有的数据,将数据写成为RDB文件。
我们可以通过Redis的save指令来配置RDB快照生成的时机,比如你可以配置当10分钟以内有100次写入就生成快照,也可以配置当1小时内有1000次写入就生成快照,也可以多个规则一起实施。这些规则的定义就在Redis的配置文件中,你也可以通过Redis的CONFIGSET命令在Redis运行时设置规则,不需要重启Redis。
Redis的RDB文件不会坏掉,因为其写操作是在一个新进程中进行的,当生成一个新的RDB文件时,Redis生成的子进程会先将数据写到一个临时文件中,然后通过原子性rename系统调用将临时文件重命名为RDB文件,这样在任何时候出现故障,Redis的RDB文件都总是可用的。同时,Redis的RDB文件也是Redis主从同步内部实现中的一环。
但是,我们可以很明显的看到,RDB有他的不足,就是一旦数据库出现问题,那么我们的RDB文件中保存的数据并不是全新的,从上次RDB文件生成到Redis停机这段时间的数据全部丢掉了。在某些业务下,这是可以忍受的,我们也推荐这些业务使用RDB的方式进行持久化,因为开启RDB的代价并不高。但是对于另外一些对数据安全性要求极高的应用,无法容忍数据丢失的应用,RDB就无能为力了,所以Redis引入了另一个重要的持久化机制:AOF日志。
AOF日志:AOF日志的全称是appendonlyfile,从名字上我们就能看出来,它是一个追加写入的日志文件。
一般数据库的binlog不同的是,AOF文件是可识别的纯文本,它的内容就是一个个的Redis标准命令。当然,并不是发送发Redis的所有命令都要记录到AOF日志里面,只有那些会导致数据发生修改的命令才会追加到AOF文件。
那么每一条修改数据的命令都生成一条日志,那么AOF文件是不是会很大?答案是肯定的,AOF文件会越来越大,所以Redis又提供了一个功能,叫做AOFrewrite。其功能就是重新生成一份AOF文件,新的AOF文件中一条记录的操作只会有一次,而不像一份老文件那样,可能记录了对同一个值的多次操作。其生成过程和RDB类似,也是fork一个进程,直接遍历数据,写入新的AOF临时文件。在写入新文件的过程中,所有的写操作日志还是会写到原来老的AOF文件中,同时还会记录在内存缓冲区中。当重完操作完成后,会将所有缓冲区中的日志一次性写入到临时文件中。然后调用原子性的rename命令用新的AOF文件取代老的AOF文件。
AOF是一个写文件操作,其目的是将操作日志写到磁盘上,所以它也同样会遇到我们上面说的写操作的5个流程。那么写AOF的操作安全性又有多高呢。实际上这是可以设置的,在Redis中对AOF调用write(2)写入后,何时再调用fsync将其写到磁盘上,通过appendfsync选项来控制,下面appendfsync的三个设置项,安全强度逐渐变强。
1)appendfsyncno
当设置appendfsync为no的时候,Redis不会主动调用fsync去将AOF日志内容同步到磁盘,所以这一切就完全依赖于操作系统的调试了。对大多数Linux操作系统,是每30秒进行一次fsync,将缓冲区中的数据写到磁盘上。
2)appendfsynceverysec
当设置appendfsync为everysec的时候,Redis会默认每隔一秒进行一次fsync调用,将缓冲区中的数据写到磁盘。但是当这一次的fsync调用时长超过1秒时。Redis会采取延迟fsync的策略,再等一秒钟。也就是在两秒后再进行fsync,这一次的fsync就不管会执行多长时间都会进行。这时候由于在fsync时文件描述符会被阻塞,所以当前的写操作就会阻塞。所以结论就是,在绝大多数情况下,Redis会每隔一秒进行一次fsync。在最坏的情况下,两秒钟会进行一次fsync操作。这一操作在大多数数据库系统中被称为groupcommit,就是组合多次写操作的数据,一次性将日志写到磁盘。
3)appednfsyncalways
当设置appendfsync为always时,每一次写操作都会调用一次fsync,这时数据是最安全的,当然,由于每次都会执行fsync,所以其性能也会受到影响。
Redis的内存管理机制
Redis的内存管理机制主要通过源码中的zmalloc.h和zmalloc.c两个文件来实现的。Redis为了方便内存的管理,在分配一块内存之后,会将这块内存的大小存入内存的头部。

如图所示,real_ptr是redis调用malloc后返回的指针。redis将内存的大小size存入头部,size所占据的内存大小是已知的,为size_t类型的长度,然后返回ret_ptr。当需要释放内存的时候,ret_ptr被传给内存管理程序。通过ret_ptr,程序可以很容易的计算出real_ptr的值,然后将real_ptr传给free释放内存。
Redis通过定义一个数组来记录所有的内存分配情况,这个数组的长度为ZMALLOC_MAX_ALLOC_STAT.数组的每一个元素代表当前程序所分配的内存块的个数,且内存块的个数,且内存块的大小为该元素的下标。
在源码中,这个数组为zmalloc_allocations。zmalloc_allocations[16]代表已经分配的长度为16bytes的内存块的个数。zmalloc.c中有一个静态变量used_memory用来记录当前分配的内存总大小。所以,总的来看,Redis采用的是包装的mallc/free,相较于Memcached的内存管理方法来说,要简单很多。
总而言之,Redis键值数据库中五种主要的数据存储结构以及它们支持的各种应用场景,使得Redis具有了强大的性能和广泛的功能,很大程度上补偿了memcached等键值数据库的不足,在很多场合对关系型数据库也起到了很好的补充作用。它支持主从结构且完全实现了发布/订阅机制,在主从服务器搭建、处理冗余数据和读写操作的可拓展性方面都具有相当的优势。
(参考http://chentian114.iteye.com/blog/2270254)
Redis 小调研的更多相关文章
- 【redis 学习系列08】Redis小功能大用处02 Pipeline、事务与Lua
3.Pipeline 3.1 Pipeline概念 Redis客户端执行一条命令分为如下四个过程: (1)发送命令 (2)命令排队 (3)命令执行 (4)返回结果 其中(1)和(4)称为Round T ...
- Level DB 小调研
一. 概况: 1. 背景: 随着信息技术的高速发展,数据存储量和流量呈现爆炸式增长.目前百度统计日 PV(日点击量)已超过 75 亿次,中国网民在百度上进行50 亿次的搜索请求,百度贴吧日 PV 十亿 ...
- Redis监控调研
1 调研目的 主要的目的是想调研各大云平台有关Redis监控功能的实现,但是最后我发现各大云平台提供的监控功能都比较基础,比如我想看诸如访问频率较高的HotKey.占用内存较大的Bigkey等指标,它 ...
- 【redis 学习系列07】Redis小功能大用处01 慢查询分析以及Redis Shell
Redis提供了5种数据结构已经足够强大,但除此之外,Redis还提供了诸如慢查询分析.功能强大的Redis Shell.Pipeline.事务与Lua脚本.Bitmaps.HyperLogLog.发 ...
- Java操作Redis小案例
1.下载jar包. http://download.csdn.net/detail/u011637069/9594840包含本案例全部代码和完整jar包. 2.连接到redis服务. package ...
- SQLite 小调研
一. 概况: SQLite 是 D. Richard Hipp 于 2000 年采用 C 语言编写的一个轻量级.跨平台的关系型数据库,支持大部分 SQL92 标准(比如视图.事务.触发器.blob 数 ...
- MySQL 小调研
一. 概况: MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,目前属于 Oracle 旗下产品.MySQL 是最流行的关系型数据库管理系统之一,在 WEB 应用方面,MySQL ...
- Fog of War小调研
看起来LOL和DOTA2都用的是格子来做的战争阴影,并且是用PP做的.
- Neo4j 小调研
一. 概况: 在图计算中,基本的数据结构表达式是:G= ( V,E ),V=vertex( 节点 ),E=edge(边) .图数据库中数据模型主要以节点和关系(边)来体现,也可以处理键值对.数据具有如 ...
随机推荐
- Spring Boot集成Mybatis双数据源
这里用到了Spring Boot + Mybatis + DynamicDataSource配置动态双数据源,可以动态切换数据源实现数据库的读写分离. 添加依赖 加入Mybatis启动器,这里添加了D ...
- Android组件内核之Activity调用栈分析(一)
阿里P7Android高级架构进阶视频免费学习请点击:https://space.bilibili.com/474380680 导语 我们陈述一下Activity,Activity是整个应用用户交互的 ...
- HashMap源码解析笔记
首先简单介绍下HashMap: 1.HashMap有三种数据结构:数组,链表,红黑树. 2.HashMap是非线程安全的 3.HashMap存储的内容是键值对(key-value)映射,key.val ...
- 3.3-Cypher语言及语法使用
Cypher是一种图数据库查询语言,表现力丰富,查询效率高,其地位和作用与关系型数据库中的SQL语言相当. Cypher具备的能力: Cypher通过模式匹配图数据库中的节点和关系,来提取信息或者修改 ...
- Android 导致OOM的常见原因
OOM主要有两种原因导致: 1. 加载大图片: 2. 内存泄漏: 一.加载大图片 在Android应用中加载Bitmap的操作是需要特别小心处理的,因为Bitmap会消耗很多内存.比如,Galaxy ...
- ssh-keyscan - 收集 ssh 公钥
总览 (SYNOPSIS) ssh-keyscan -words [-v46 ] [-p port ] [-T timeout ] [-t type ] [-f file ] [host | addr ...
- ethtool---查看网卡
ethtool 命令详解 命令描述: ethtool 是用于查询及设置网卡参数的命令. 使用概要:ethtool ethx //查询ethx网口基本设置,其中 x 是对应网卡的编号,如et ...
- shell date 格式化
https://www.tutorialkart.com/bash-shell-scripting/bash-date-format-options-examples/ DATE=`date '+%d ...
- 使用appium1.4在android8.0真机上测试程序时报错command failed shell "ps 'uiautomator'"的解决方式
appium1.4,运行自动化脚本时提示 org.openqa.selenium.SessionNotCreatedException: A new session could not be crea ...
- c# 通过地址下载流然后保存文件到本地
1.下载文件并保存文件到本地 private void GetFileFromNetUrl(string url) { try { System.Net.WebRequest req = System ...