STL总结 (C++)
一、一般介绍
STL(Standard Template Library),即标准模板库,是一个具有工业强度的,高效的C++程序库。它被容纳于C++标准程序库(C++ Standard Library)中,是ANSI/ISO C++标准中最新的也是极具革命性的一部分。该库包含了诸多在计算机科学领域里所常用的基本数据结构和基本算法。为广大C++程序员们提供了一个可扩展的应用框架,高度体现了软件的可复用性。
从逻辑层次来看,在STL中体现了泛型化程序设计的思想(generic programming),引入了诸多新的名词,比如像需求(requirements),概念(concept),模型(model),容器(container),算法(algorithmn),迭代子(iterator)等。与OOP(object-oriented programming)中的多态(polymorphism)一样,泛型也是一种软件的复用技术;
从实现层次看,整个STL是以一种类型参数化(type parameterized)的方式实现的,这种方式基于一个在早先C++标准中没有出现的语言特性--模板(template)。如果查阅任何一个版本的STL源代码,你就会发现,模板作为构成整个STL的基石是一件千真万确的事情。除此之外,还有许多C++的新特性为STL的实现提供了方便;
在C++标准中,STL被组织为下面的17个头文件:<algorithm>、<deque>、<functional>、<iterator>、<array>、<vector>、<list>、<forward_list>、<map>、<unordered_map>、<memory>、<numeric>、<queue>、<set>、<unordered_set>、<stack>和<utility>。
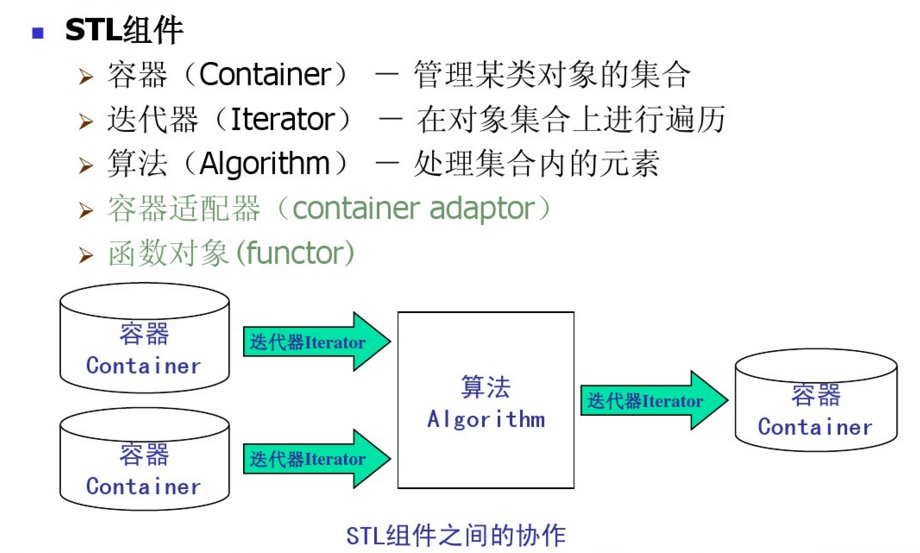
二、STL的六大组件
- 容器(Container),是一种数据结构,如list,vector,和deques ,以模板类的方法提供。为了访问容器中的数据,可以使用由容器类输出的迭代器;
- 迭代器(Iterator),提供了访问容器中对象的方法。例如,可以使用一对迭代器指定list或vector中的一定范围的对象。迭代器就如同一个指针。事实上,C++的指针也是一种迭代器。但是,迭代器也可以是那些定义了operator*()以及其他类似于指针的操作符地方法的类对象;
- 算法(Algorithm),是用来操作容器中的数据的模板函数。例如,STL用sort()来对一个vector中的数据进行排序,用find()来搜索一个list中的对象,函数本身与他们操作的数据的结构和类型无关,因此他们可以在从简单数组到高度复杂容器的任何数据结构上使用;
- 仿函数(Function object,仿函数(functor)又称之为函数对象(function object),其实就是重载了()操作符的struct,没有什么特别的地方
- 迭代适配器(Adaptor)
- 空间配制器(allocator)其中主要工作包括两部分1.对象的创建与销毁 2.内存的获取与释放
以下主要讨论:容器,迭代器,算法,适配器。如欲详加了解 参见C++ Primer
1.STL容器
1)序列式容器(Sequence containers),每个元素都有固定位置--取决于插入时机和地点,和元素值无关,vector、deque、list;
Vectors:将元素置于一个动态数组中加以管理,可以随机存取元素(用索引直接存取),数组尾部添加或移除元素非常快速。但是在中部或头部安插元素比较费时;
Deques:是“double-ended queue”的缩写,可以随机存取元素(用索引直接存取),数组头部和尾部添加或移除元素都非常快速。但是在中部或头部安插元素比较费时;
Lists:双向链表,不提供随机存取(按顺序走到需存取的元素,O(n)),在任何位置上执行插入或删除动作都非常迅速,内部只需调整一下指针;
2)关联式容器(Associated containers),元素位置取决于特定的排序准则,和插入顺序无关,set、multiset、map、multimap;
Sets/Multisets:内部的元素依据其值自动排序,Set内的相同数值的元素只能出现一次,Multisets内可包含多个数值相同的元素,内部由二叉树实现(实际上基于红黑树(RB-tree)实现),便于查找;
Maps/Multimaps:Map的元素是成对的键值/实值,内部的元素依据其值自动排序,Map内的相同数值的元素只能出现一次,Multimaps内可包含多个数值相同的元素,内部由二叉树实现(实际上基于红黑树(RB-tree)实现),便于查找;
另外有其他容器hash_map,hash_set,hash_multiset,hash_multimap。
容器的比较:
| Vector | Deque | List | Set | MultiSet | Map | MultiMap | |
| 内部结构 | dynamic array | array of arrays | double linked list | binary tree | binary tree | binary tree | binary tree |
| 随机存取 | Yes | Yes | No | No | No | Yes(key) | No |
| 搜索速度 | 慢 | 慢 | 很慢 | 快 | 快 | 快 | 快 |
| 快速插入移除 | 尾部 | 首尾 | 任何位置 | -- | -- | -- | -- |
2.STL迭代器
Iterator(迭代器)模式又称Cursor(游标)模式,用于提供一种方法顺序访问一个聚合对象中各个元素,
而又不需暴露该对象的内部表示。或者这样说可能更容易理解:Iterator模式是运用于聚合对象的一种模式,通过运用该模式,使得我们可以在不知道对象内部表示的情况下,按照一定顺序(由iterator提供的方法)访问聚合对象中的各个元素。
迭代器的作用:能够让迭代器与算法不干扰的相互发展,最后又能无间隙的粘合起来,重载了*,++,==,!=,=运算符。用以操作复杂的数据结构,容器提供迭代器,算法使用迭代器;
常见的一些迭代器类型:iterator、const_iterator、reverse_iterator和const_reverse_iterator
迭代器一般声明使用示例
vector<T>::iterator it;
list<T>::iterator it;
deque<T>::iterator it;

input output
\ /
forward
|
bidirectional
|
random access
要注意,上面这图表并不是表明它们之间的继承关系:而只是描述了迭代器的种类和接口。处于图表下层的迭代器都是相对于处于图表上层迭代器的扩张集。例如:forward迭代器不但拥有input和output迭代器的所有功能,还拥有更多的功能。
各个迭代器的功能如下:
|
迭代器类别 |
说明 |
|
输入 |
从容器中读取元素。输入迭代器只能一次读入一个元素向前移动,输入迭代器只支持一遍算法,同一个输入迭代器不能两遍遍历一个序列 |
|
输出 |
向容器中写入元素。输出迭代器只能一次一个元素向前移动。输出迭代器只支持一遍算法,统一输出迭代器不能两次遍历一个序列 |
|
正向 |
组合输入迭代器和输出迭代器的功能,并保留在容器中的位置 |
|
双向 |
组合正向迭代器和逆向迭代器的功能,支持多遍算法 |
|
随机访问 |
组合双向迭代器的功能与直接访问容器中任何元素的功能,即可向前向后跳过任意个元素 |
迭代器的操作:
每种迭代器均可进行包括表中前一种迭代器可进行的操作。
|
迭代器操作 |
说明 |
|
所有迭代器 |
|
|
p++ |
后置自增迭代器 |
|
++p |
前置自增迭代器 |
|
输入迭代器 |
|
|
*p |
复引用迭代器,作为右值 |
|
p=p1 |
将一个迭代器赋给另一个迭代器 |
|
p==p1 |
比较迭代器的相等性 |
|
p!=p1 |
比较迭代器的不等性 |
|
输出迭代器 |
|
|
*p |
复引用迭代器,作为左值 |
|
p=p1 |
将一个迭代器赋给另一个迭代器 |
|
正向迭代器 |
提供输入输出迭代器的所有功能 |
|
双向迭代器 |
|
|
--p |
前置自减迭代器 |
|
p-- |
后置自减迭代器 |
|
随机迭代器 |
|
|
p+=i |
将迭代器递增i位 |
|
p-=i |
将迭代器递减i位 |
|
p+i |
在p位加i位后的迭代器 |
|
p-i |
在p位减i位后的迭代器 |
|
p[i] |
返回p位元素偏离i位的元素引用 |
|
p<p1 |
如果迭代器p的位置在p1前,返回true,否则返回false |
|
p<=p1 |
p的位置在p1的前面或同一位置时返回true,否则返回false |
|
p>p1 |
如果迭代器p的位置在p1后,返回true,否则返回false |
|
p>=p1 |
p的位置在p1的后面或同一位置时返回true,否则返回false |
只有顺序容器和关联容器支持迭代器遍历,各容器支持的迭代器的类别如下:
|
容器 |
支持的迭代器类别 |
说明 |
|
vector |
随机访问 |
一种随机访问的数组类型,提供了对数组元素进行快速随机访问以及在序列尾部进行快速的插入和删除操作的功能。可以再需要的时候修改其自身的大小 |
|
deque |
随机访问 |
一种随机访问的数组类型,提供了序列两端快速进行插入和删除操作的功能。可以再需要的时候修改其自身的大小 |
|
list |
双向 |
一种不支持随机访问的数组类型,插入和删除所花费的时间是固定的,与位置无关。 |
|
set |
双向 |
一种随机存取的容器,其关键字和数据元素是同一个值。所有元素都必须具有惟一值。 |
|
multiset |
双向 |
一种随机存取的容器,其关键字和数据元素是同一个值。可以包含重复的元素。 |
|
map |
双向 |
一种包含成对数值的容器,一个值是实际数据值,另一个是用来寻找数据的关键字。一个特定的关键字只能与一个元素关联。 |
|
multimap |
双向 |
一种包含成对数值的容器,一个值是实际数据值,另一个是用来寻找数据的关键字。一个关键字可以与多个数据元素关联。 |
|
stack |
不支持 |
适配器容器类型,用vector,deque或list对象创建了一个先进后出容器 |
|
queue |
不支持 |
适配器容器类型,用deque或list对象创建了一个先进先出容器 |
|
priority_queue |
不支持 |
适配器容器类型,用vector或deque对象创建了一个排序队列 |
3.STL算法
STL算法部分主要由头文件<algorithm>,<numeric>,<functional>组成。要使用 STL中的算法函数必须包含头文件<algorithm>,对于数值算法须包含<numeric>,<functional>中则定义了一些模板类,用来声明函数对象。
STL中算法大致分为四类:
1)、非可变序列算法:指不直接修改其所操作的容器内容的算法。
2)、可变序列算法:指可以修改它们所操作的容器内容的算法。
3)、排序算法:包括对序列进行排序和合并的算法、搜索算法以及有序序列上的集合操作。
4)、数值算法:对容器内容进行数值计算。
以下对所有算法进行细致分类并标明功能:
<一>查找算法(13个):判断容器中是否包含某个值
adjacent_find: 在iterator对标识元素范围内,查找一对相邻重复元素,找到则返回指向这对元素的第一个元素的ForwardIterator。否则返回last。重载版本使用输入的二元操作符代替相等的判断。
binary_search: 在有序序列中查找value,找到返回true。重载的版本实用指定的比较函数对象或函数指针来判断相等。
count: 利用等于操作符,把标志范围内的元素与输入值比较,返回相等元素个数。
count_if: 利用输入的操作符,对标志范围内的元素进行操作,返回结果为true的个数。
equal_range: 功能类似equal,返回一对iterator,第一个表示lower_bound,第二个表示upper_bound。
find: 利用底层元素的等于操作符,对指定范围内的元素与输入值进行比较。当匹配时,结束搜索,返回该元素的一个InputIterator。
find_end: 在指定范围内查找"由输入的另外一对iterator标志的第二个序列"的最后一次出现。找到则返回最后一对的第一个ForwardIterator,否则返回输入的"另外一对"的第一个ForwardIterator。重载版本使用用户输入的操作符代替等于操作。
find_first_of: 在指定范围内查找"由输入的另外一对iterator标志的第二个序列"中任意一个元素的第一次出现。重载版本中使用了用户自定义操作符。
find_if: 使用输入的函数代替等于操作符执行find。
lower_bound: 返回一个ForwardIterator,指向在有序序列范围内的可以插入指定值而不破坏容器顺序的第一个位置。重载函数使用自定义比较操作。
upper_bound: 返回一个ForwardIterator,指向在有序序列范围内插入value而不破坏容器顺序的最后一个位置,该位置标志一个大于value的值。重载函数使用自定义比较操作。
search: 给出两个范围,返回一个ForwardIterator,查找成功指向第一个范围内第一次出现子序列(第二个范围)的位置,查找失败指向last1。重载版本使用自定义的比较操作。
search_n: 在指定范围内查找val出现n次的子序列。重载版本使用自定义的比较操作。
<二>排序和通用算法(14个):提供元素排序策略
inplace_merge: 合并两个有序序列,结果序列覆盖两端范围。重载版本使用输入的操作进行排序。
merge: 合并两个有序序列,存放到另一个序列。重载版本使用自定义的比较。
nth_element: 将范围内的序列重新排序,使所有小于第n个元素的元素都出现在它前面,而大于它的都出现在后面。重载版本使用自定义的比较操作。
partial_sort: 对序列做部分排序,被排序元素个数正好可以被放到范围内。重载版本使用自定义的比较操作。
partial_sort_copy: 与partial_sort类似,不过将经过排序的序列复制到另一个容器。
partition: 对指定范围内元素重新排序,使用输入的函数,把结果为true的元素放在结果为false的元素之前。
random_shuffle: 对指定范围内的元素随机调整次序。重载版本输入一个随机数产生操作。
reverse: 将指定范围内元素重新反序排序。
reverse_copy: 与reverse类似,不过将结果写入另一个容器。
rotate: 将指定范围内元素移到容器末尾,由middle指向的元素成为容器第一个元素。
rotate_copy: 与rotate类似,不过将结果写入另一个容器。
sort: 以升序重新排列指定范围内的元素。重载版本使用自定义的比较操作。
stable_sort: 与sort类似,不过保留相等元素之间的顺序关系。
stable_partition: 与partition类似,不过不保证保留容器中的相对顺序。
<三>删除和替换算法(15个)
copy: 复制序列
copy_backward: 与copy相同,不过元素是以相反顺序被拷贝。
iter_swap: 交换两个ForwardIterator的值。
remove: 删除指定范围内所有等于指定元素的元素。注意,该函数不是真正删除函数。内置函数不适合使用remove和remove_if函数。
remove_copy: 将所有不匹配元素复制到一个制定容器,返回OutputIterator指向被拷贝的末元素的下一个位置。
remove_if: 删除指定范围内输入操作结果为true的所有元素。
remove_copy_if: 将所有不匹配元素拷贝到一个指定容器。
replace: 将指定范围内所有等于vold的元素都用vnew代替。
replace_copy: 与replace类似,不过将结果写入另一个容器。
replace_if: 将指定范围内所有操作结果为true的元素用新值代替。
replace_copy_if: 与replace_if,不过将结果写入另一个容器。
swap: 交换存储在两个对象中的值。
swap_range: 将指定范围内的元素与另一个序列元素值进行交换。
unique: 清除序列中重复元素,和remove类似,它也不能真正删除元素。重载版本使用自定义比较操作。
unique_copy: 与unique类似,不过把结果输出到另一个容器。
<四>排列组合算法(2个):提供计算给定集合按一定顺序的所有可能排列组合
next_permutation: 取出当前范围内的排列,并重新排序为下一个排列。重载版本使用自定义的比较操作。
prev_permutation: 取出指定范围内的序列并将它重新排序为上一个序列。如果不存在上一个序列则返回false。重载版本使用自定义的比较操作。
<五>算术算法(4个)
accumulate: iterator对标识的序列段元素之和,加到一个由val指定的初始值上。重载版本不再做加法,而是传进来的二元操作符被应用到元素上。
partial_sum: 创建一个新序列,其中每个元素值代表指定范围内该位置前所有元素之和。重载版本使用自定义操作代替加法。
inner_product: 对两个序列做内积(对应元素相乘,再求和)并将内积加到一个输入的初始值上。重载版本使用用户定义的操作。
adjacent_difference: 创建一个新序列,新序列中每个新值代表当前元素与上一个元素的差。重载版本用指定二元操作计算相邻元素的差。
<六>生成和异变算法(6个)
fill: 将输入值赋给标志范围内的所有元素。
fill_n: 将输入值赋给first到first+n范围内的所有元素。
for_each: 用指定函数依次对指定范围内所有元素进行迭代访问,返回所指定的函数类型。该函数不得修改序列中的元素。
generate: 连续调用输入的函数来填充指定的范围。
generate_n: 与generate函数类似,填充从指定iterator开始的n个元素。
transform: 将输入的操作作用与指定范围内的每个元素,并产生一个新的序列。重载版本将操作作用在一对元素上,另外一个元素来自输入的另外一个序列。结果输出到指定容器。
<七>关系算法(8个)
equal: 如果两个序列在标志范围内元素都相等,返回true。重载版本使用输入的操作符代替默认的等于操作符。
includes: 判断第一个指定范围内的所有元素是否都被第二个范围包含,使用底层元素的<操作符,成功返回true。重载版本使用用户输入的函数。
lexicographical_compare: 比较两个序列。重载版本使用用户自定义比较操作。
max: 返回两个元素中较大一个。重载版本使用自定义比较操作。
max_element: 返回一个ForwardIterator,指出序列中最大的元素。重载版本使用自定义比较操作。
min: 返回两个元素中较小一个。重载版本使用自定义比较操作。
min_element: 返回一个ForwardIterator,指出序列中最小的元素。重载版本使用自定义比较操作。
mismatch: 并行比较两个序列,指出第一个不匹配的位置,返回一对iterator,标志第一个不匹配元素位置。如果都匹配,返回每个容器的last。重载版本使用自定义的比较操作。
<八>集合算法(4个)
set_union: 构造一个有序序列,包含两个序列中所有的不重复元素。重载版本使用自定义的比较操作。
set_intersection: 构造一个有序序列,其中元素在两个序列中都存在。重载版本使用自定义的比较操作。
set_difference: 构造一个有序序列,该序列仅保留第一个序列中存在的而第二个中不存在的元素。重载版本使用自定义的比较操作。
set_symmetric_difference: 构造一个有序序列,该序列取两个序列的对称差集(并集-交集)。
<九>堆算法(4个)
make_heap: 把指定范围内的元素生成一个堆。重载版本使用自定义比较操作。
pop_heap: 并不真正把最大元素从堆中弹出,而是重新排序堆。它把first和last-1交换,然后重新生成一个堆。可使用容器的back来访问被"弹出"的元素或者使用pop_back进行真正的删除。重载版本使用自定义的比较操作。
push_heap: 假设first到last-1是一个有效堆,要被加入到堆的元素存放在位置last-1,重新生成堆。在指向该函数前,必须先把元素插入容器后。重载版本使用指定的比较操作。
sort_heap: 对指定范围内的序列重新排序,它假设该序列是个有序堆。重载版本使用自定义比较操作。
4.适配器
STL提供了三个容器适配器:queue、priority_queue、stack。这些适配器都是包装了vector、list、deque中某个顺序容器的包装器。注意:适配器没有提供迭代器,也不能同时插入或删除多个元素。下面对各个适配器进行概括总结。
(1)stack用法
#include <stack>
template < typename T, typename Container=deque > class stack;
可以使用三个标准顺序容器vecotr、deque(默认)、list中的任何一个作为stack的底层模型。
bool stack<T>::empty() //判断堆栈是否为空
void stack<T>::pop() //弹出栈顶数据
stack<T>::push(T x) //压入一个数据
stack<T>::size_type stack<T>::size() //返回堆栈长度
T stack<T>::top() //得到栈顶数据
代码示例:
stack<int> intDequeStack;
stack<int,vector<int>> intVectorStack;
stack<int,list<int>> intListStack;
(2)queue用法
#include <queue>
template<typename T, typename Container = deque<T> > class queue;
第一个参数指定要在queue中存储的类型,第二个参数规定queue适配的底层容器,可供选择的容器只有dequeue和list。对大多数用途使用默认的dequeue。

queue<T>::push(T x)
void queue<T>::pop()
T queue<T>::back()
T queue<T>::front()
queue<T>::size_type
queue<T>::size()
bool queue<T>::empty()
代码示例:
queue<int> intDequeQueue;
queue<int,list<int>> intListQueue;
(3)priority_queue用法
#include <queue>
template <typename T, typename Container = vector<T>, typename Compare = less<T> > class priority_queue;
priority_queue也是一个队列,其元素按有序顺序排列。其不采用严格的FIFO顺序,给定时刻位于队头的元素正是有最高优先级的元素。如果两个元素有相同的优先级,那么它们在队列中的顺序就遵循FIFO语义。默认适配的底层容器是vector,也可以使用deque,list不能用,因为priority_queue要求能对元素随机访问以便进行排序。
priority_queue<T>::push(T x)
void priority_queue<T>::pop()
T priority_queue<T>::top()
priority_queue<T>::size_type
priority_queue<T>::size()
bool priority_queue<T>::empty()
代码示例:
priority_queue< int, vector<int>, greater<int> >
priority_queue< int, list<int>, greater<int> >
标准库默认使用元素类型的<操作符来确定它们之间的优先级关系,用法有三:(下文转自http://www.cnblogs.com/vvilp/articles/1504436.html)
优先队列第一种用法,通过默认使用的<操作符可知在整数中元素大的优先级高。
priority_queue<int> qi;
示例中输出结果为:9 6 5 3 2
优先队列第二种用法,建立priority_queue时传入一个比较函数,使用functional.h函数对象作为比较函数。
priority_queue<int, vector<int>, greater<int> >qi2;
示例2中输出结果为:2 3 5 6 9
优先队列第三种用法,是自定义优先级。
struct node
{
friend bool operator< (node n1, node n2)
{
return n1.priority < n2.priority;
}
int priority;
int value;
};
priority_queue<node> qn;
在示例3中输出结果为:
优先级 值
9 5
8 2
6 1
2 3
1 4
在该结构中,value为值,priority为优先级。通过自定义operator<操作符来比较元素中的优先级。注意:必须是自定义<操作符才行,把上述的结构中的<操作符改成>编译不通过。
STL总结 (C++)的更多相关文章
- 详细解说 STL 排序(Sort)
0 前言: STL,为什么你必须掌握 对于程序员来说,数据结构是必修的一门课.从查找到排序,从链表到二叉树,几乎所有的算法和原理都需要理解,理解不了也要死记硬背下来.幸运的是这些理论都已经比较成熟,算 ...
- STL标准模板库(简介)
标准模板库(STL,Standard Template Library)是C++标准库的重要组成部分,包含了诸多在计算机科学领域里所常见的基本数据结构和基本算法,为广大C++程序员提供了一个可扩展的应 ...
- STL的std::find和std::find_if
std::find是用来查找容器元素算法,但是它只能查找容器元素为基本数据类型,如果想要查找类类型,应该使用find_if. 小例子: #include "stdafx.h" #i ...
- STL: unordered_map 自定义键值使用
使用Windows下 RECT 类型做unordered_map 键值 1. Hash 函数 计算自定义类型的hash值. struct hash_RECT { size_t operator()(c ...
- C++ STL简述
前言 最近要找工作,免不得要有一番笔试,今年好像突然就都流行在线笔试了,真是搞的我一塌糊涂.有的公司呢,不支持Python,Java我也不会,C有些数据结构又有些复杂,所以是时候把STL再看一遍了-不 ...
- codevs 1285 二叉查找树STL基本用法
C++STL库的set就是一个二叉查找树,并且支持结构体. 在写结构体式的二叉查找树时,需要在结构体里面定义操作符 < ,因为需要比较. set经常会用到迭代器,这里说明一下迭代器:可以类似的把 ...
- STL bind1st bind2nd详解
STL bind1st bind2nd详解 先不要被吓到,其实这两个配接器很简单.首先,他们都在头文件<functional>中定义.其次,bind就是绑定的意思,而1st就代表fir ...
- STL sort 函数实现详解
作者:fengcc 原创作品 转载请注明出处 前几天阿里电话一面,被问到STL中sort函数的实现.以前没有仔细探究过,听人说是快速排序,于是回答说用快速排序实现的,但听电话另一端面试官的声音,感觉不 ...
- STL的使用
Vector:不定长数组 Vector是C++里的不定长数组,相比传统数组vector主要更灵活,便于节省空间,邻接表的实现等.而且它在STL中时间效率也很高效:几乎与数组不相上下. #include ...
- [C/C++] C/C++延伸学习系列之STL及Boost库概述
想要彻底搞懂C++是很难的,或许是不太现实的.但是不积硅步,无以至千里,所以抽时间来坚持学习一点,总结一点,多多锻炼几次,相信总有一天我们会变得"了解"C++. 1. C++标准库 ...
随机推荐
- nginx ip配置反向代理为本地域名
#### gitlab反向代理 server { listen ; server_name gitlab.hp.com; location / { proxy_pass http://192.168. ...
- TD - 输入框
模板1:TD - 普通输入框 <input dojoType="bootstrap.form.ValidationTextBox" dojoAttachPoint=" ...
- 安卓开发中遇到java.net.SocketException: Permission denied
仅需在AndroidManifest.xml添加 <uses-permission android:name="android.permission.INTERNET" /& ...
- Python标准库之时间模块time与datatime模块详解
时间模块time与datatime 时间表示方式: 时间戳 格式化时间字符串 元组 时间戳格式: time.time()#输出1581664531.749063 元组格式: time.localtim ...
- python爬虫模拟登录的图片验证码处理和会话维持
目标网站:古诗文网 登录界面显示: 打开控制台工具,输入账号密码,在ALL栏目中进行抓包 数据如下: 登录请求的url和请求方式 登录所需参数 参数分析: __VIEWSTATE和__VIEWSTAT ...
- 回环屏障CyclicBarrier
上一篇说的CountDownLatch是一个计数器,类似线程的join方法,但是有一个缺陷,就是当计数器的值到达0之后,再调用CountDownLatch的await和countDown方法就会立刻返 ...
- python3 读取串口数据
python3 读取串口数据 demo import serial import time ser = serial.Serial("COM3",115200,timeout = ...
- LED Holiday Light -Picking LED Christmas Lights, 4 Things
LED Christmas lights are not very cheap, but you should know that LED lights can be used for more th ...
- AspxDashBorad_OnDashboardLoaded 获取对应的DashboardParameter
protected void ASPxDashboardViewerThrend_OnDashboardLoaded(object sender, DashboardLoadedWebEventArg ...
- Laravel中如何做数据库迁移
总的来说,做一次独立数据库迁移只需要三步,分别是创建迁移文件.修改迁移文件.运行迁移 1.创建数据库迁移文件php artisan make:migration create_articles_tab ...