ES相关信息
搜索引擎的核心:倒排索引
elasticsearch
- 基于Lucene的,封装成一个restful的api,通过api就可进行操作(Lucene是一个apache开放源代码的全文检索引擎工具包,必须使用Java作为开发语言集成到项目中)
- 分布式
elasticsearch和DB的对应关系
DB -> Databases -> Tables -> Rows -> Columns
ES -> Indices -> Types -> Documents -> Fields
如果我们要在ES中创建一条数据,步骤为 1、首先创建document,每个文档包含响应的信息,然后赋予每个文档一种类型,为一个类型创建一条索引,最后将索引存储到es中。
1、集群的健康
在Elasticsearch集群中可以监控统计很多信息,但是只有一个是最重要的:集群健康(cluster health)。集群健康有三种状态:green、yellow或red。
GET /_cluster/health
在一个没有索引的空集群中运行如上查询,将返回这些信息:
{
"cluster_name": "elasticsearch",
"status": "yellow", <1>
"timed_out": false,
"number_of_nodes": 1,
"number_of_data_nodes": 1,
"active_primary_shards": 11,
"active_shards": 11,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 11, <2>
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 50.0
}
- <1>
status是我们最感兴趣的字段 - <2>
unassigned_shards没有启用的复制分片,原因是还没有分配给节点。同一个节点上保存相同的数据副本是没有必要的。
status字段提供一个综合的指标来表示集群的的服务状况。三种颜色各自的含义:
| 颜色 | 意义 |
|---|---|
green |
所有主要分片和复制分片都可用 |
yellow |
所有主要分片可用,但不是所有复制分片都可用 |
red |
不是所有的主要分片都可用 |
2、搜索
(以下相关搜索均以5.6版本为例,5.2.2版本之前的参考https://es.xiaoleilu.com(书籍涉及到的版本为2.x))
搜索的地址为
/索引/类型/_search
我们创建一个基于alpha数据库的ES,索引为data库,类型为entity表,所以搜索的地址为:/data/entity/_search,请求可以为GET,也可为POST,注意,两者的请求数据均在body中
tips:
- python flask中提供了request方法,可以使用
request.data获取get请求的body
可以直接发送搜索请求,不附加任何条件,默认会返回10条数据,数据内容会在响应体的hits中
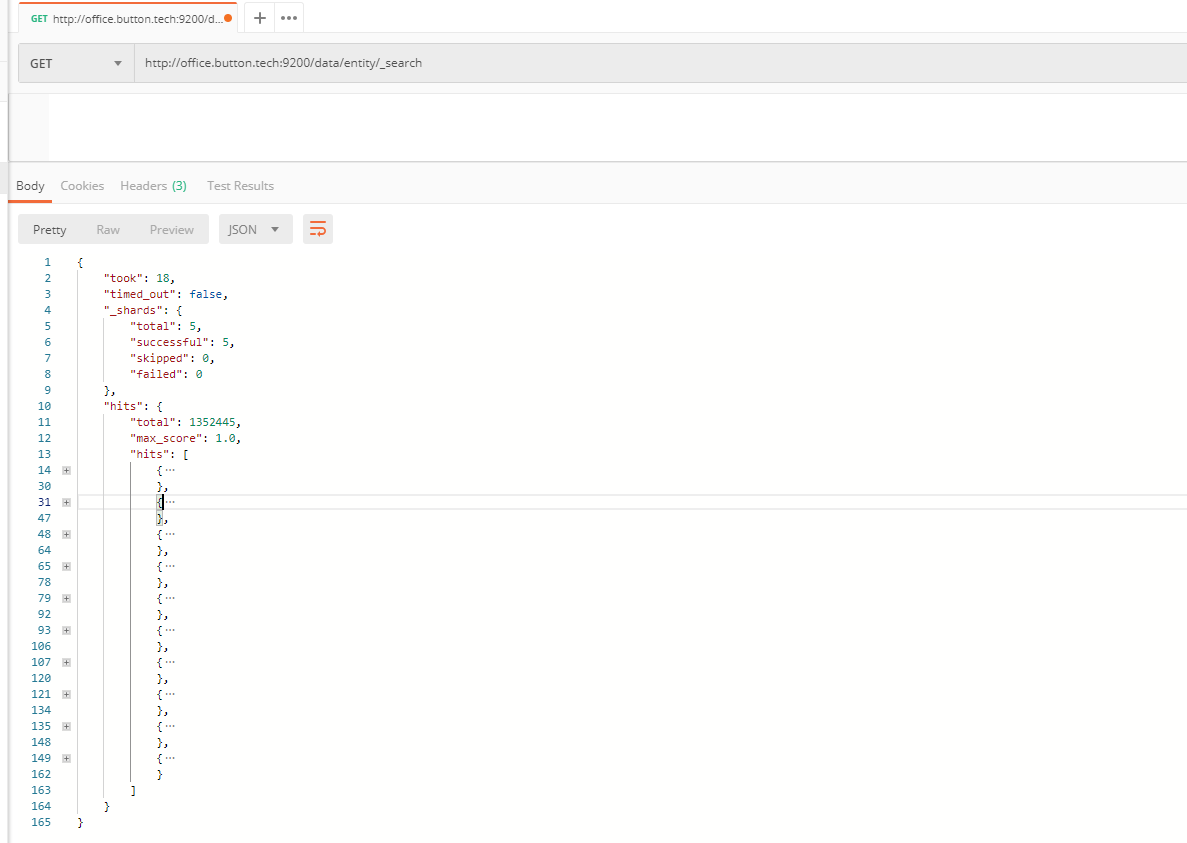
返回字段解释:
1、took Elasticsearch执行搜索的时间(以毫秒为单位)
2、timed_out 检索是否超时,可以定义超时时间GET /search?timeout=10ms
3、_shards 检索了多少分片,成功失败了多少
4、hits 检索的结果
5、hits.total 检索文档的总数
6、hits.hits 实际的检索结果,默认前10个
7、hits.sort 排序的key(如果按分值排序的话则不显示)
8、每个节点都有一个_score字段,是文档的相关性得分,衡量了文档与查询的匹配程度。返回结果默认按照_score降序排列,max_score指的是所有文档匹配查询中_score的最大值
1、普通简单查询
字符串查询
这种查询,我们只需要像一般传递URL参数的方法去传递查询语句
/data/entity/_search?q=name:张三
如果没有指定字段,查询字符串搜索使用的_all字段

短语搜索
搜索名字带有李四的数据
{
"query" : {
"match_phrase" : {
"name" : "李四"
}
}
}
高亮显示
{
"query" : {
"match_phrase" : {
"name" : "李四"
}
},
"highlight": {
"fields": {
"name":{}
}
}
}
result
{
"took": 19,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 29.54232,
"hits": [
{
"_index": "data",
"_type": "entity",
"_id": "5c7397d2ac623e001071c7b3",
"_score": 29.54232,
"_source": {
"name": "李四",
"nick": "李四",
"abs": "",
"type": 1.0,
"intro": "",
"_deleted": false
},
"highlight": {
"name": [
"<em>李</em><em>四</em>"
]
}
}
]
}
}
2、多索引查询
/_search在所有索引的所有类型中搜索/test/_search在索引test的所有类型中查找/test,us/_search在索引test和us的所有类型中搜索/t*,u*/_search在t或u开头的索引的所有类型中搜索/test/user/_search在索引test的user类型中搜索/test,u/user,class/_search在索引test和u的类型为user和class中搜索/_all/user,class/_search在所有索引的user和class类型中搜索
3、分页
传参时,接收from(默认为0)和size(默认为10)参数
如果想每页显示5个结果,页码从1到3,请求如下
GET /_search?size=5
GET /_search?size=5&from=5
GET /_search?size=5&from=10
注:假设一个有5个主分片的索引中搜索,当我们请求结果的第一页时(1-10),每个分片都会产生自己最顶端的10个结果,然后返回它们给请求节点,然后在排序这50个结果,选出顶端的10个结果
4、结构化查询
以json请求体的形式出现
1、查询子句
{
QUERY_NAME: {
ARGUMENT: VALUE,
ARGUMENT: VALUE,...
}
}
或者指向一个指定的字段
{
QUERY_NAME: {
FIELD_NAME: {
ARGUMENT: VALUE,
ARGUMENT: VALUE,...
}
}
}
完整的请求
GET /_search
{
"query": {
"match": {
"name": "张三"
}
}
}
2、合并多子句
- 叶子子句(leaf clauses)(比如
match子句) 用以在将查询字符串与一个字段(或多字段)进行比较 - 复合子句(compound) 用以合并其他的子句。例如,
bool子句允许你合并其他的合法子句,must,must_not或者should,如果可能的话:
{
"bool": {
"must": { "match": { "tweet": "elasticsearch" }},
"must_not": { "match": { "name": "mary" }},
"should": { "match": { "tweet": "full text" }}
}
}
复合子句能合并任意其他查询子句,包括其他的复合子句。 这就意味着复合子句可以相互嵌套,从而实现非常复杂的逻辑。
{
"bool": {
"must": { "match": { "email": "business opportunity" }},
"should": [
{ "match": { "starred": true }},
{ "bool": {
"must": { "folder": "inbox" }},
"must_not": { "spam": true }}
}}
],
"minimum_should_match": 1
}
}
3、match_all 查询
使用match_all 可以查询到所有文档,是没有查询条件下的默认语句。
{
"match_all": {}
}
此查询常用于合并过滤条件。 比如说你需要检索所有的邮箱,所有的文档相关性都是相同的,所以得到的_score为1
4、match 查询
使用match时,可以选择短语查找type:phrase或者operator:'and'
同时,支持slop选项,表示相隔多远时仍然将文档视为匹配(int)
match查询是一个标准查询,不管你需要全文本查询还是精确查询基本上都要用到它。
如果你使用 match 查询一个全文本字段,它会在真正查询之前用分析器先分析match一下查询字符:
{
"match": {
"tweet": "About Search"
}
}
如果用match下指定了一个确切值,在遇到数字,日期,布尔值或者not_analyzed 的字符串时,它将为你搜索你给定的值:
{ "match": { "age":26}}
{ "match": { "date":"2014-09-01"}}
{ "match": { "public": true}}
{ "match": { "tag":"full_text"}}
提示: 做精确匹配搜索时,你最好用过滤语句,因为过滤语句可以缓存数据。
match查询只能就指定某个确切字段某个确切的值进行搜索,而你要做的就是为它指定正确的字段名以避免语法错误。
5、multi_match 查询
multi_match查询允许你做match查询的基础上同时搜索多个字段:
"multi_match": {
"query": "full text search",
"fields": [ "title", "body" ]
}
type:
1.最佳字段(Best fields):
当搜索代表某些概念的单词时,例如"brown fox",几个单词合在一起表达出来的意思比单独的单词更多。类似title和body的字段,尽管它们是相关联的,但是也是互相竞争着的。文档在相同的字段中应该有尽可能多的单词(译注:搜索的目标单词),文档的分数应该来自拥有最佳匹配的字段。
2.多数字段(Most fields):
一个用来调优相关度的常用技术是将相同的数据索引到多个字段中,每个字段拥有自己的分析链(Analysis Chain)。
主要字段会含有单词的词干部分,同义词和消除了变音符号的单词。它用来尽可能多地匹配文档。
相同的文本可以被索引到其它的字段中来提供更加精确的匹配。一个字段或许会包含未被提取成词干的单词,另一个字段是包含了变音符号的单词,第三个字段则使用shingle来提供关于单词邻近度(Word Proximity)(match_phrase)的信息。
以上这些额外的字段扮演者signal的角色,用来增加每个匹配的文档的相关度分值。越多的字段被匹配则意味着文档的相关度越高。
使用most_fields存在的问题
使用most_fields方法执行实体查询有一些不那么明显的问题:
- 它被设计用来找到匹配任意单词的多数字段,而不是找到跨越所有字段的最匹配的单词。
- 它不能使用operator或者minimum_should_match参数来减少低相关度结果带来的长尾效应。
- 每个字段的词条频度是不同的,会互相干扰最终得到较差的排序结果。
3.跨字段(Cross fields):
对于一些实体,标识信息会在多个字段中出现,每个字段中只含有一部分信息:
- Person:
first_name和last_name - Book:
title,author, 和description - Address:
street,city,country, 和postcode
此时,我们希望在任意字段中找到尽可能多的单词。我们需要在多个字段中进行查询,就好像这些字段是一个字段那样。
以上这些都是多词,多字段查询,但是每种都需要使用不同的策略。我们会在本章剩下的部分解释每种策略。
- Person:
{
"query": {
"multi_match": {
"query": "张三",
"type": "best_fields",
"fields": [
"name",
"abs"
],
"minimum_should_match": "30%"
}
}
}
加权 field: ["name^2", "abs"]
字段也可以使用通配符:"fields": "*_title"
6、bool 查询
bool 查询与 bool 过滤相似,用于合并多个查询子句。不同的是,bool 过滤可以直接给出是否匹配成功, 而bool 查询要计算每一个查询子句的 _score (相关性分值)。
must: 查询指定文档一定要被包含。
must_not: 查询指定文档一定不要被包含。
should: 查询指定文档,有则可以为文档相关性加分。
以下查询将会找到 title 字段中包含 "how to make millions",并且 "tag" 字段没有被标为 spam。 如果有标识为 "starred" 或者发布日期为2014年之前,那么这些匹配的文档将比同类网站等级高:
{
"query": {
"bool": {
"must": { "match": { "title": "quick" }},
"must_not": { "match": { "title": "lazy" }},
"should": [
{ "match": { "title": "brown" }},
{ "match": { "title": "dog" }}
]
}
}
}
提示: 如果
bool查询下没有must子句,那至少应该有一个should子句。但是 如果有must子句,那么没有should子句也可以进行查询。
可以使用bool代替match
注意:term query会去倒排索引中寻找确切的term,它并不知道分词器的存在,这种查询适合keyword、numeric、date等明确值的
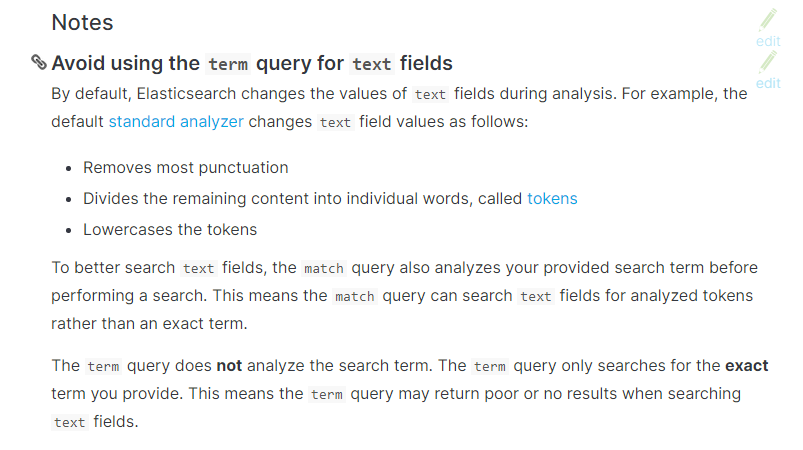
以下来自官网:
Avoid using the term query for text fields.
By default, Elasticsearch changes the values of text fields as part of analysis. This can make finding exact matches for text field values difficult.
To search text field values, use the match query instead.
{
"query": {
"match": {
"name": {
"query": "张三",
"operator": "and"
}
}
}
}
=>
{
"query": {
"bool": {
"must": [
{
"term": {
"name": "张"
}
},
{
"term": {
"name": "三"
}
}
]
}
}
}
7、多词查询
{
"query": {
"match": {
"name": {
"query": "张三",
"operator": "and"
}
}
}
}
控制精度
minimum_should_match指定必须存在的最小数量或百分比
| Type | Example | Description |
|---|---|---|
| Integer | 3 |
Indicates a fixed value regardless of the number of optional clauses. |
| Negative integer | -2 |
Indicates that the total number of optional clauses, minus this number should be mandatory. |
| Percentage | 75% |
Indicates that this percent of the total number of optional clauses are necessary. The number computed from the percentage is rounded down and used as the minimum. |
| Negative percentage | -25% |
Indicates that this percent of the total number of optional clauses can be missing. The number computed from the percentage is rounded down, before being subtracted from the total to determine the minimum. |
| Combination | 3<90% |
A positive integer, followed by the less-than symbol, followed by any of the previously mentioned specifiers is a conditional specification. It indicates that if the number of optional clauses is equal to (or less than) the integer, they are all required, but if it’s greater than the integer, the specification applies. In this example: if there are 1 to 3 clauses they are all required, but for 4 or more clauses only 90% are required. |
| Multiple combinations | 2<-25% 9<-3 |
Multiple conditional specifications can be separated by spaces, each one only being valid for numbers greater than the one before it. In this example: if there are 1 or 2 clauses both are required, if there are 3-9 clauses all but 25% are required, and if there are more than 9 clauses, all but three are required. |
{
"query": {
"bool": {
"should": [
{ "match": { "name": "Indian" }},
{ "match": { "name": "Corporaton" }},
{ "match": { "name": "of" }}
],
"minimum_should_match": 2
}
}
}
8、提交权重
boost
{
"query": {
"bool": {
"should": [
{
"match": {
"name": {
"query": "张三",
"boost": 1
}
}
},
{
"match": {
"abs":"test",
}
}
]
}
}
}
9、dis_max查询
不使用 bool 查询,可以使用 dis_max 即分离最大化查询(Disjuction Max Query)。Disjuction的意思"OR"(而Conjunction的意思是"AND"),因此Disjuction Max Query的意思就是返回匹配了任何查询的文档,并且分值是产生了最佳匹配的查询所对应的分值:
{
"query": {
"dis_max": {
"queries": [
{ "match": { "title": "Brown fox" }},
{ "match": { "body": "Brown fox" }}
]
}
}
}
它会产生我们期望的结果:
{
"hits": [
{
"_id": "2",
"_score": 0.21509302,
"_source": {
"title": "Keeping pets healthy",
"body": "My quick brown fox eats rabbits on a regular basis."
}
},
{
"_id": "1",
"_score": 0.12713557,
"_source": {
"title": "Quick brown rabbits",
"body": "Brown rabbits are commonly seen."
}
}
]
}
最佳字段查询的调优
如果用户搜索的是"quick pets",那么会发生什么呢?两份文档都包含了单词quick,但是只有文档2包含了单词pets。两份文档都没能在一个字段中同时包含搜索的两个单词。
一个像下面那样的简单dis_max查询会选择出拥有最佳匹配字段的查询子句,而忽略其他的查询子句:
{
"query": {
"dis_max": {
"queries": [
{ "match": { "title": "Quick pets" }},
{ "match": { "body": "Quick pets" }}
]
}
}
}
{
"hits": [
{
"_id": "1",
"_score": 0.12713557,
"_source": {
"title": "Quick brown rabbits",
"body": "Brown rabbits are commonly seen."
}
},
{
"_id": "2",
"_score": 0.12713557,
"_source": {
"title": "Keeping pets healthy",
"body": "My quick brown fox eats rabbits on a regular basis."
}
}
]
}
可以发现,两份文档的分值是一模一样的。
我们期望的是同时匹配了title字段和body字段的文档能够拥有更高的排名,但是结果并非如此。需要记住:dis_max查询只是简单的使用最佳匹配查询子句得到的_score。
tie_breaker
但是,将其它匹配的查询子句考虑进来也是可能的。通过指定tie_breaker参数:
{
"query": {
"dis_max": {
"queries": [
{ "match": { "title": "Quick pets" }},
{ "match": { "body": "Quick pets" }}
],
"tie_breaker": 0.3
}
}
}
它会返回以下结果:
{
"hits": [
{
"_id": "2",
"_score": 0.14757764,
"_source": {
"title": "Keeping pets healthy",
"body": "My quick brown fox eats rabbits on a regular basis."
}
},
{
"_id": "1",
"_score": 0.124275915,
"_source": {
"title": "Quick brown rabbits",
"body": "Brown rabbits are commonly seen."
}
}
]
}
现在文档2的分值比文档1稍高一些。
tie_breaker参数会让dis_max查询的行为更像是dis_max和bool的一种折中。它会通过下面的方式改变分值计算过程:
- 取得最佳匹配查询子句的
_score。 - 将其它每个匹配的子句的分值乘以
tie_breaker。 - 将以上得到的分值进行累加并规范化。
通过tie_breaker参数,所有匹配的子句都会起作用,只不过最佳匹配子句的作用更大。
NOTE
tie_breaker的取值范围是0到1之间的浮点数,取0时即为仅使用最佳匹配子句(译注:和不使用tie_breaker参数的dis_max查询效果相同),取1则会将所有匹配的子句一视同仁。它的确切值需要根据你的数据和查询进行调整,但是一个合理的值会靠近0,(比如,0.1-0.4),来确保不会压倒dis_max查询具有的最佳匹配性质。
tips
可以通过/data/entity/_validate/query来查看查询语句是否正确
{
"query": {
"bool":{
"must" : [
{ "match": { "name": "business opportunity" }}
],
"filter": { "term": { "abs": "inbox" }}}
}
}
----------------------------------
{
"valid": true,
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
}
}
===================================
{
"query": {
"name" : {
"match" : "张三"
}
}
}
-----------------------------------
{
"valid": false
}
如果想知道错误信息
/data/entity/_validate/query?explain
{
"query": {
"name" : {
"match" : "张三"
}
}
}
-----------------------------------
{
"valid": false,
"error": "org.elasticsearch.common.ParsingException: no [query] registered for [name]"
}
5、排序
- 可以使用字符串参数直接排序
GET /_search?sort=date:desc&sort=_score&q=search
- 也可以使用body进行排序
{
"query": {
"match": {"name":"张三"}
},
"sort": { "type": { "order": "desc" }},
"from": 0,
"size": 24
}
-------------------------------------
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 15,
"max_score": null,
"hits": [
{
"_index": "data",
"_type": "entity",
"_id": "5c89fa7c11b069001757a00f",
"_score": null, <1>
"_source": {
"name": "张三"
},
"sort": [
16.0
]
},
......
<1> _score 字段没有经过计算,因为没有用作排序
<2> 如果是时间字段会被转为毫秒当作排序依据。
_score 和 max_score 字段都为 null。计算 _score 是比较消耗性能的, 而且通常主要用作排序 -- 我们不是用相关性进行排序的时候,就不需要统计其相关性。 如果你想强制计算其相关性,可以设置track_scores为 true。
- 多级排序
结果集会先用第一排序字段来排序,当用用作第一字段排序的值相同的时候, 然后再用第二字段对第一排序值相同的文档进行排序,以此类推
{
"query": {
"match": {"name":"张三"}
},
"sort": [{ "type": { "order": "desc" }},
{"asset.type": {"order": "desc"}}
],
"_source": [
"name"
],
"from": 0,
"size": 24
}
=============================================
"hits": [
{
"_index": "data",
"_type": "entity",
"_id": "5c89fa7c11b069001757a00f",
"_score": null,
"_source": {
"name": "张三"
},
"sort": [
16.0,
-9223372036854775808
]
},
多值字段排序
在为一个字段的多个值进行排序的时候, 其实这些值本来是没有固定的排序的-- 一个拥有多值的字段就是一个集合, 你准备以哪一个作为排序依据呢?
对于数字和日期,你可以从多个值中取出一个来进行排序,你可以使用
min,max,avg或sum这些模式。 比说你可以在dates字段中用最早的日期来进行排序:"sort": {
"dates": {
"order": "asc",
"mode": "min"
}
}
重要
为了提高排序效率,ES会将所有字段的值加载到内存中(所有字段数据加载到内存中并不是匹配到的那部分数据,而是索引下所有文档中的值,包括所有类型)
6、过滤
1、term 过滤
term主要用于精确匹配哪些值,比如数字,日期,布尔值或 not_analyzed的字符串(未经分析的文本数据类型):
{ "term": { "age": 26 }}
{ "term": { "date": "2014-09-01" }}
{ "term": { "public": true }}
{ "term": { "tag": "full_text" }}
2、terms过滤(或者)
和term有点类似,但是terms允许指定多个匹配条件,如果某个字段指定了多个值,那么文档需要一起去做匹配
{
"terms": {
"tag": [ "search", "full_text", "nosql" ]
}
}
3、range过滤
range过滤允许我们按照指定范围查找一批数据:
{
"range": {
"age": {
"gte": 20,
"lt": 30
}
}
}
范围操作符包含:
gt : 大于
gte: 大于等于
lt : 小于
lte: 小于等于
4、exists过滤
exists 过滤可以用于查找文档中是否包含指定字段或没有某个字段,类似于SQL语句中的IS_NULL条件
不存在可以使用 bool -> must_not -> exists
{
"query": {
"exists": {"field":"asset.type"}
}
}
{
"query": {
"bool":{
"must_not":{
"exists":{"field":"asset.type" }
}
}
}
}
这两个过滤只是针对已经查出一批数据来,但是想区分出某个字段是否存在的时候使用。
5、bool过滤
bool 过滤可以用来合并多个过滤条件查询结果的布尔逻辑,它包含一下操作符:
must : 多个查询条件的完全匹配,相当于 and。
must_not : 多个查询条件的相反匹配,相当于 not。
should : 至少有一个查询条件匹配, 相当于 or。
这些参数可以分别继承一个过滤条件或者一个过滤条件的数组:
{
"bool": {
"must": { "term": { "folder": "inbox" }},
"must_not": { "term": { "tag": "spam" }},
"should": [
{ "term": { "starred": true }},
{ "term": { "unread": true }}
]
}
}
6、组合过滤
{
"query": {
"bool": {
"filter": [
{"bool": {
"must": [{"match": {"name":"张森"}}, {"match": {"type":16}}]
}}
]
}
}
}
7、包含,而不是相等
理解 term 和 terms 是包含操作,而不是相等操作,这点非常重要。这意味着什么?
假如你有一个 term 过滤器 { "term" : { "tags" : "search" } },它将匹配下面两个文档:
{ "tags" : ["search"] }
{ "tags" : ["search", "open_source"] } <1>
<1> 虽然这个文档除了 search 还有其他短语,它还是被返回了
回顾一下 term 过滤器是怎么工作的:它检查倒排索引中所有具有短语的文档,然后组成一个字节集。在我们简单的示例中,我们有下面的倒排索引:
| Token | DocIDs |
|---|---|
open_source |
2 |
search |
1,2 |
当执行 term 过滤器来查询 search 时,它直接在倒排索引中匹配值并找出相关的 ID。如你所见,文档 1 和文档 2 都包含 search,所以他们都作为结果集返回。
提示: 倒排索引的特性让完全匹配一个字段变得非常困难。你将如何确定一个文档只能包含你请求的短语?你将在索引中找出这个短语,解出所有相关文档 ID,然后扫描 索引中每一行来确定文档是否包含其他值。
由此可见,这将变得非常低效和开销巨大。因此,term 和 terms 是 必须包含 操作,而不是 必须相等。
完全匹配
假如你真的需要完全匹配这种行为,最好是通过添加另一个字段来实现。在这个字段中,你索引原字段包含值的个数。引用上面的两个文档,我们现在包含一个字段来记录标签的个数:
{ "tags" : ["search"], "tag_count" : 1 }
{ "tags" : ["search", "open_source"], "tag_count" : 2 }
一旦你索引了标签个数,你可以构造一个 bool 过滤器来限制短语个数:
GET /my_index/my_type/_search
{
"query": {
"bool" : {
"must" : [
{ "term" : { "tags" : "search" } },
{ "term" : { "tag_count" : 1 } }
]
}
}
}
<1> 找出所有包含 search 短语的文档
<2> 但是确保文档只有一个标签
这将匹配只有一个 search 标签的文档,而不是匹配所有包含了 search 标签的文档。
7、查询过滤合并
"bool":{
"must" : [
{ "match": { "name": "business opportunity" }}
],
"filter": { "term": { "abs": "inbox" }}
}
8、aggtegations(聚合分析)
聚合分析是数据库中重要的功能特性,完成对一个查询的数据集中数据的聚合计算,如:找出某字段(或计算表达式的结果)的最大值、最小值,计算和、平均值等。ES作为搜索引擎兼数据库,同样提供了强大的聚合分析能力。
对一个数据集求最大、最小、和、平均值等指标的聚合,在ES中称为指标聚合 metric
而关系型数据库中除了有聚合函数外,还可以对查询出的数据进行分组group by,再在组上进行指标聚合。在 ES 中group by 称为分桶,桶聚合 bucketing
ES中还提供了矩阵聚合(matrix)、管道聚合(pipleline),但还在完善中。
"aggregations" : {
"<aggregation_name>" : {
"<aggregation_type>" : {
<aggregation_body>
}
[,"meta" : { [<meta_data_body>] } ]?
[,"aggregations" : { [<sub_aggregation>]+ } ]?
}
[,"<aggregation_name_2>" : { ... } ]*
}
aggregations 也可简写为 aggs
1、max、min、sum、avg
- 查询type的最大值
{
"size": 0,
"aggs": {
"masssbalance": { // 这个字段名为自定义字段名,会把最中的结果以对象的形式放在里面
"max": {
"field": "type"
}
}
}
}
// ===========================
{
"took": 452,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1352448,
"max_score": 0.0,
"hits": []
},
"aggregations": {
"masssbalance": {
"value": 256.0
}
}
}
2、terms
terms根据字段值项分组聚合.field按什么字段分组,size指定返回多少个分组,shard_size指定每个分片上返回多少个分组,order排序方式.可以指定include和exclude正则筛选表达式的值,指定missing设置缺省值
{
"size": 0,
"aggs": {
"terms":{
"terms": {
"field": "type",
"size": 10
}
}
}
}
3、去重cardinality
{
"size": 0,
"aggs": {
"count_type": {
"cardinality": {
"field": "type"
}
}
}
}
4、percentiles百分比
percentiles对指定字段(脚本)的值按从小到大累计每个值对应的文档数的占比(占所有命中文档数的百分比),返回指定占比比例对应的值。默认返回[ 1, 5, 25, 50, 75, 95, 99 ]分位上的值
{
"size": 0,
"aggs": {
"age_percents":{
"percentiles": {
"field": "age",
"percents": [
1,
5,
25,
50,
75,
95,
99
]
}
}
}
}
{
"size": 0,
"aggs": {
"states": {
"terms": {
"field": "gender"
},
"aggs": {
"banlances": {
"percentile_ranks": {
"field": "balance",
"values": [
20000,
40000
]
}
}
}
}
}
5、percentiles rank
统计小于等于指定值得文档比
{
"size": 0,
"aggs": {
"tests": {
"percentile_ranks": {
"field": "age",
"values": [
10,
15
]
}
}
}
}
6、filter聚合
filter对满足过滤查询的文档进行聚合计算,在查询命中的文档中选取过滤条件的文档进行聚合,先过滤在聚合
{
"size": 0,
"aggs": {
"agg_filter":{
"filter": {
"match":{"gender":"F"}
},
"aggs": {
"avgs": {
"avg": {
"field": "age"
}
}
}
}
}
}
7、filtters聚合
多个过滤组聚合计算
{
"size": 0,
"aggs": {
"message": {
"filters": {
"filters": {
"asset": {
"exists": {
"field": "asset.type"
}
},
"Patent":{
"term": {
"asset.type": 1
}
},
"product":{
"term": {
"asset.type": 0
}
}
}
}
}
}
}
// =================================
{
"size": 0,
"aggs": {
"message": {
"filters": {
"filters": {
"asset": {
"exists": {
"field": "asset.type"
}
},
"Patent":{
"term": {
"asset.type": 1
}
},
"product":{
"term": {
"asset.type": 0
}
}
}
}
}
}
}
8、range聚合
{
"aggs": {
"agg_range": {
"range": {
"field": "cost",
"ranges": [
{
"from": 50,
"to": 70
},
{
"from": 100
}
]
},
"aggs": {
"bmax": {
"max": {
"field": "cost"
}
}
}
}
}
}
9、date_range聚合
{
"aggs": {
"date_aggrs": {
"date_range": {
"field": "accepted_time",
"format": "MM-yyy",
"ranges": [
{
"from": "now-10d/d",
"to": "now"
}
]
}
}
}
}
10、date_histogram
时间直方图聚合,就是按天、月、年等进行聚合统计。可按 year (1y), quarter (1q), month (1M), week (1w), day (1d), hour (1h), minute (1m), second (1s) 间隔聚合或指定的时间间隔聚合
{
"aggs": {
"sales_over_time": {
"date_histogram": {
"field": "accepted_time",
"interval": "quarter",
"min_doc_count" : 0, //可以返回没有数据的月份
"extended_bounds" : { //强制返回数据的范围
"min" : "2014-01-01",
"max" : "2014-12-31"
}
}
}
}
}
11、missing聚合
{
"aggs": {
"account_missing": {
"missing": {
"field": "__type"
}
}
}
}
3、映射与分析
映射(mapping)机制用于进行字段类型确认,将每个字段匹配为一种确定的数据类型(string, number, booleans, date等)。
分析(analysis)机制用于进行全文文本(Full Text)的分词,以建立供搜索用的反向索引。
在索引中处理数据时,我们注意到一些奇怪的事。有些东西似乎被破坏了:
在索引中有12个tweets,只有一个包含日期2014-09-15,但是我们看看下面查询中的total hits。
GET /_search?q=2014 # 12 个结果
GET /_search?q=2014-09-15 # 还是 12 个结果 !
GET /_search?q=date:2014-09-15 # 1 一个结果
GET /_search?q=date:2014 # 0 个结果 !
可以通过GET /data/_mapping/entity查看es是如何解读文档
{
"data": {
"mappings": {
"entity": {
"properties": {
"_deleted": {
"type": "boolean"
},
"abs": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"asset": {
"properties": {
"type": {
"type": "long"
}
}
},
"intro": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"nick": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"portfolio": {
"properties": {
"type": {
"type": "long"
}
}
},
"type": {
"type": "float"
}
}
}
}
}
}
其中,每一种的类型的索引方式是不同的,因此导致查询结果的不同
搜索中,可能需要确切值(exact values) 及 全文文本
- 确切值:准确的值,要么匹配,要么不匹配
- 全文文本
分析和分析器
字符过滤器
在标记化前处理字符串,字符过滤器能过去除HTML标记,或者转化
&为and分词器
将字符根据空格或逗号等,将单词分开
标记过滤
可以将单词统一为小写,取掉
a,and,the等词(或者增加词)
es 支持的字段类型
| 类型 | 表示的数据类型 |
|---|---|
| String | string |
| Whole number | byte, short, integer, long |
| Floating point | float, double |
| Boolean | boolean |
| Date | date |
4、相关度
查询中,可以在query外加上 "min_score" : -1 来控制返回的最小score
ElasticSearch的相似度算法被定义为 TF/IDF,即检索词频率/反向文档频率,包括一下内容:
检索词频率:
检索词在该字段出现的频率?出现频率越高,相关性也越高。 字段中出现过5次要比只出现过1次的相关性高。
反向文档频率:
每个检索词在索引中出现的频率?频率越高,相关性越低。 检索词出现在多数文档中会比出现在少数文档中的权重更低, 即检验一个检索词在文档中的普遍重要性。
字段长度准则:
字段的长度是多少?长度越长,相关性越低。 检索词出现在一个短的 title 要比同样的词出现在一个长的 content 字段高。
单个查询可以使用TF/IDF评分标准或其他方式,比如短语查询中检索词的距离或模糊查询里的检索词相似度。
相关性并不只是全文本检索的专利。也适用于yes|no的子句,匹配的子句越多,相关性评分越高。
如果多条查询子句被合并为一条复合查询语句,比如 bool 查询,则每个查询子句计算得出的评分会被合并到总的相关性评分中。
理解评分标准
当调试一条复杂的查询语句时,想要理解相关性评分 _score 是比较困难的。ElasticSearch 在 每个查询语句中都有一个explain参数,将 explain 设为 true 就可以得到更详细的信息。
GET /_search?explain <1>
{
"query" : { "match" : { "tweet" : "honeymoon" }}
}
<1> explain 参数可以让返回结果添加一个 _score 评分的得来依据。
增加一个 explain 参数会为每个匹配到的文档产生一大堆额外内容,但是花时间去理解它是很有意义的。 如果现在看不明白也没关系 -- 等你需要的时候再来回顾这一节就行。下面我们来一点点的了解这块知识点。
首先,我们看一下普通查询返回的元数据:
{
"_index" : "us",
"_type" : "tweet",
"_id" : "12",
"_score" : 0.076713204,
"_source" : { ... trimmed ... },
}
这里加入了该文档来自于哪个节点哪个分片上的信息,这对我们是比较有帮助的,因为词频率和 文档频率是在每个分片中计算出来的,而不是每个索引中:
"_shard" : 1,
"_node" : "mzIVYCsqSWCG_M_ZffSs9Q",
然后返回值中的 _explanation 会包含在每一个入口,告诉你采用了哪种计算方式,并让你知道计算的结果以及其他详情:
"_explanation": { <1>
"description": "weight(tweet:honeymoon in 0)
[PerFieldSimilarity], result of:",
"value": 0.076713204,
"details": [
{
"description": "fieldWeight in 0, product of:",
"value": 0.076713204,
"details": [
{ <2>
"description": "tf(freq=1.0), with freq of:",
"value": 1,
"details": [
{
"description": "termFreq=1.0",
"value": 1
}
]
},
{ <3>
"description": "idf(docFreq=1, maxDocs=1)",
"value": 0.30685282
},
{ <4>
"description": "fieldNorm(doc=0)",
"value": 0.25,
}
]
}
]
}
<1> honeymoon 相关性评分计算的总结
<2> 检索词频率
<3> 反向文档频率
<4> 字段长度准则
重要: 输出
explain结果代价是十分昂贵的,它只能用作调试工具 --千万不要用于生产环境。
第一部分是关于计算的总结。告诉了我们 "honeymoon" 在 tweet字段中的检索词频率/反向文档频率或 TF/IDF, (这里的文档 0 是一个内部的ID,跟我们没有关系,可以忽略。)
然后解释了计算的权重是如何计算出来的:
检索词频率:
检索词 `honeymoon` 在 `tweet` 字段中的出现次数。
反向文档频率:
检索词 `honeymoon` 在 `tweet` 字段在当前文档出现次数与索引中其他文档的出现总数的比率。
字段长度准则:
文档中 `tweet` 字段内容的长度 -- 内容越长,值越小。
复杂的查询语句解释也非常复杂,但是包含的内容与上面例子大致相同。 通过这段描述我们可以了解搜索结果是如何产生的。
提示: JSON形式的explain描述是难以阅读的 但是转成 YAML 会好很多,只需要在参数中加上
format=yaml
文档是如何被匹配到的
当explain选项加到某一文档上时,它会告诉你为何这个文档会被匹配,以及一个文档为何没有被匹配。
请求路径为 /index/type/id/_explain, 如下所示:
GET /us/tweet/12/_explain
{
"query" : {
"filtered" : {
"filter" : { "term" : { "user_id" : 2 }},
"query" : { "match" : { "tweet" : "honeymoon" }}
}
}
}
除了上面我们看到的完整描述外,我们还可以看到这样的描述:
"failure to match filter: cache(user_id:[2 TO 2])"
也就是说我们的 user_id 过滤子句使该文档不能匹配到。
附:
关键词
- query
match
match_all
multi_match
match_phrase
[field]
- bool
must
match
must_not
should
match
bool
term
...
filter
term
- [field]相关文档详情见官方文档
query -- value 支持正则
type 类型
fields 字段
tie_breaker 最佳匹配的调优
minimum_should_match 最小匹配度
boost 权重
operator or 或者 and 默认为or
- aggregate(agg)
"aggregations" : {
"<aggregation_name>" : {
"<aggregation_type>" : {
<aggregation_body>
}
[,"meta" : { [<meta_data_body>] } ]?
[,"aggregations" : { [<sub_aggregation>]+ } ]?
}
[,"<aggregation_name_2>" : { ... } ]*
}
- size
- from
- _source
ES相关信息的更多相关文章
- ManagementClass类解析和C#如何获取硬件的相关信息
在.NET的项目中,有时候需要获取计算机的硬件的相关信息,在C#语言中需要利用ManagementClass这个类来进行相关操作. 现在先来介绍一下ManagementClass类,首先看一下类的继承 ...
- MySQL查看数据库相关信息
使用MySQL时,需要了解当前数据库的情况,例如当前的数据库大小.字符集.用户等等.下面总结了一些查看数据库相关信息的命令 1:查看显示所有数据库 mysql> show databases ...
- php http头设置相关信息
HTTP 状态码 状态码用来告诉HTTP客户端,HTTP服务器是否产生了预期的Response. HTTP/1.1中定义了5类状态码, 状态码由三位数字组成,第一个数字定义了响应的类别 1XX 提示信 ...
- 在linux中查询硬件相关信息
1.查询cpu的相关 a.查询CPU的统计信息 使用命令:lscpu 得到的结果如下: Architecture: x86_64 CPU op-mode(s): -bit, -bit Byte Ord ...
- Android根据文件路径使用File类获取文件相关信息
Android通过文件路径如何得到文件相关信息,如 文件名称,文件大小,创建时间,文件的相对路径,文件的绝对路径等: 如图: 代码: public class MainActivity extends ...
- Linux sysinfo获取系统相关信息
Linux中,可以用sysinfo来获取系统相关信息. #include <stdio.h> #include <stdlib.h> #include <errno.h& ...
- C# 获取进程或线程的相关信息
信息来自: http://blog.163.com/kunkun0921@126/blog/static/169204332201293023432113/ using System; using S ...
- 获取Java系统相关信息
package com.test; import java.util.Properties; import java.util.Map.Entry; import org.junit.Test; pu ...
- 把数据保存到数据库附加表 `dede_addonarticle` 时出错,请把相关信息提交给DedeCms官方。Duplicate entry
把数据保存到数据库附加表 `dede_addonarticle` 时出错,请把相关信息提交给DedeCms官方.Duplicate entry ’3′ for key ‘PRIMARY’ 你的主键是不 ...
随机推荐
- Til the Cows Come Home(spfa做法)
题目题目描述贝茜在谷仓外的农场上,她想回到谷仓,在第二天早晨农夫约翰叫她起来挤奶之前尽可能多地睡上一觉.由于需要睡个好觉,贝茜必须尽快回到谷仓.农夫约翰的农场上有N(2≤N≤1000)个路标,每一个路 ...
- 新建一个servlet类,继承HttpServlet,但是无法导入HttpServlet包
描述: 原因:缺少tomcat的libraries(HttpServlet对应位置在tomcat的lib中====) 解决: 1. 2. 3. 4.
- 使用fastClick.js所产生的一些问题
开发h5活动页时想到移动端会有300ms的延迟,于是便打算用fastClick.js解决. 页面引入fastClick.js后,滑动H5页面的时候发现谷歌浏览器会报错,如下: Unable to pr ...
- OneDrive一直后台占用CPU的一种解决办法
系统版本:Windows 7 ultimate x64 Onedrive版本:17.3.6998.0830 最近发现Onedrive一直在后台占用15%左右的CPU,很是觉得奇怪,网上的解决方案是删除 ...
- vue之父子组件执行对方的方法
一.子组件执行父组件中的方法 1.父组件将方法名传给子组件,子组件进行调用 父组件中: <Vbutton typeBtn="success" :btnUserMethod=& ...
- Ubuntu's Software
(1)indicator-sysmonitor & acpi (2)nvidia-prime (3)sogou (4)wps (5)ubuntu-tweak
- Java——package和import关键字
1.8 package和import关键字 1.8.1 package 包其实就是目录,特别是项目比较大,java 文件特别多的情况下,我们应该分目录管理,在java 中称为分包管理,包名称通常采用小 ...
- php的字符串{}选定与{变量}
$str = "abcdefg"; echo $str{2};//输出c $a = "test"; echo "ddd{$a}";//输出d ...
- bzoj1022题解
[题意分析] 最简单的Anti-Nim博弈模型. [解题思路] 引理:SJ定理 对于一个Anti-Nim游戏,只要有以下两条条件之一,先手必胜: 1.游戏的总SG函数为0且任意子游戏的SG函数不超过1 ...
- 第k小团+bitset优化——牛客多校第2场D
模拟bfs,以空团为起点,用堆维护当前最小的团,然后进行加点更新 在加入新点时要注意判重,并且用bitset来加速判断和转移构造 #include<bits/stdc++.h> #incl ...