IntelliJ IDEA + Maven环境编写第一个hadoop程序
1. 新建IntelliJ下的maven项目
点击File->New->Project,在弹出的对话框中选择Maven,JDK选择你自己安装的版本,点击Next
2. 填写Maven的GroupId和ArtifactId
你可以根据自己的项目随便填,点击Next
这样就新建好了一个空的项目
这里程序名填写WordCount,我们的程序是一个通用的网上的范例,用来计算文件中单词出现的次数
3. 设置程序的编译版本
打开Intellij的Preference偏好设置,定位到Build, Execution, Deployment->Compiler->Java Compiler,
将WordCount的Target bytecode version修改为你的jdk版本(我的是1.8)
4. 配置依赖
编辑pom.xml进行配置
1) 添加apache源
在project内尾部添加
<repositories>
<repository>
<id>apache</id>
<url>http://maven.apache.org</url>
</repository>
</repositories>
2) 添加hadoop依赖
这里只需要用到基础依赖hadoop-core和hadoop-common;如果需要读写HDFS,
则还需要依赖hadoop-hdfs和hadoop-client;如果需要读写HBase,则还需要依赖hbase-client
在project内尾部添加
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.2</version>
</dependency>
</dependencies>
修改pom.xml完成后,Intellij右上角会提示Maven projects need to be Imported,点击Import Changes以更新依赖,或者点击Enable Auto Import
最后,我的完整的pom.xml如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>com.fun</groupId>
<artifactId>hadoop</artifactId>
<version>1.0-SNAPSHOT</version> <repositories>
<repository>
<id>apache</id>
<url>http://maven.apache.org</url>
</repository>
</repositories> <dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.2</version>
</dependency>
</dependencies> <build>
<plugins>
<plugin>
<artifactId>maven-dependency-plugin</artifactId>
<configuration>
<excludeTransitive>false</excludeTransitive>
<stripVersion>true</stripVersion>
<outputDirectory>./lib</outputDirectory>
</configuration> </plugin>
</plugins>
</build>
</project>
5. 编写主程序
WordCount.java
/**
* Created by jinshilin on 16/12/7.
*/
import java.io.IOException;
import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount { public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1);
private Text word = new Text(); public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
} public static class IntSumReducer
extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
6. 配置输入和输出结果文件夹
1) 添加和src目录同级的input文件夹到项目中
在input文件夹中放置一个或多个输入文件源
我的输入文件源如下:
test.segmented:
dfdfadgdgag
aadads
fudflcl
cckcer
fadf
dfdfadgdgag
fudflcl
fuck
fuck
fuckfuck
haha
aaa
2) 配置运行参数
在Intellij菜单栏中选择Run->Edit Configurations,在弹出来的对话框中点击+,新建一个Application配置。配置Main class为WordCount(可以点击右边的...选择),
Program arguments为input/ output/,即输入路径为刚才创建的input文件夹,输出为output
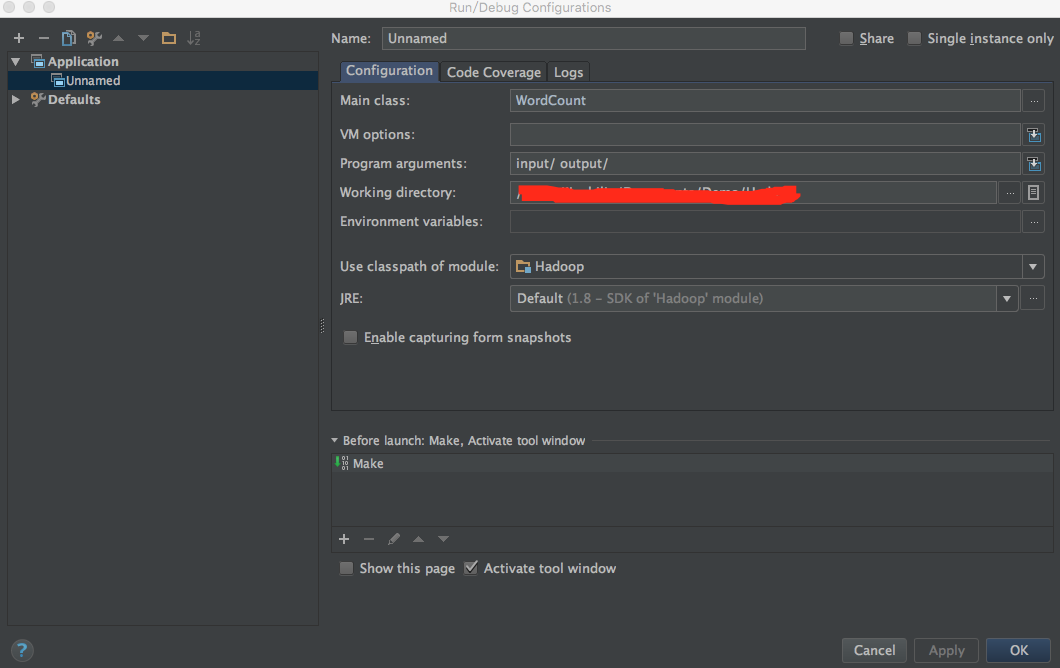
由于Hadoop的设定,下次运行时务必删除output文件夹!
好了,运行程序,结果如下:
aaa 1
aadads 1
cckcer 1
dfdfadgdgag 2
fadf 1
fuck 2
fuckfuck 1
fudflcl 2
haha 1
至此,一个简单的hadoop程序完成!
IntelliJ IDEA + Maven环境编写第一个hadoop程序的更多相关文章
- Go语言开发的第一步,安装开发环境编写第一个Go程序
关于go就不介绍了,google自己的语言.其它的百科,最近比较郁闷,处于纠结状态,不想说话,真心不想说话. 开发工具安装: 安装包下载: http://code.google.com/p/go/do ...
- 如何使用eclipse for c/c++ 配置环境编写第一个C程序
因为VS太大还要安装太多的插件,,,所以想用eclipse编写C语言... 1.下载eclipse for c/c++版本 去官网即可下载 https://www.eclipse.org/dow ...
- 搭建java开发环境、使用eclipse编写第一个java程序
搭建java开发环境.使用eclipse编写第一个java程序 一.Java 开发环境的搭建 1.首先安装java SDK(简称JDK). 点击可执行文件 jdk-6u24-windows-i586. ...
- 【安装eclipse, 配置java环境教程】 编写第一个java程序
写java通常用eclipse编写,还有一款编辑器比较流行叫IJ.这里我们只说下eclipse编写java的前期工作. 在安装eclipse之前要下载java的sdk文件,即java SE:否则无法运 ...
- 一起学Hadoop——使用IDEA编写第一个MapReduce程序(Java和Python)
上一篇我们学习了MapReduce的原理,今天我们使用代码来加深对MapReduce原理的理解. wordcount是Hadoop入门的经典例子,我们也不能免俗,也使用这个例子作为学习Hadoop的第 ...
- 【C#入门教案-02】用记事本编写第一个C#程序-Hello World
02-用记事本编写第一个C#程序-Hello World 广东职业技术学院 欧浩源 [1]进行.NET程序开发的最基本环境配备 .NET Framework + 代码编辑工具(记事本或Noetpad ...
- 假期作业02:安装JDK与文本编辑器并编写第一个Java程序
假期作业02:安装JDK与文本编辑器并编写第一个Java程序 一.安装JDK与文本编辑器并编写第一个java程序 首先在oracle官网(需要创建账号,进行登录后方可使用)按照自己的需求下载JDK(h ...
- 运行第一个Hadoop程序,WordCount
系统: Ubuntu14.04 Hadoop版本: 2.7.2 参照http://www.cnblogs.com/taichu/p/5264185.html中的分享,来学习运行第一个hadoop程序. ...
- 从零自学Java-1.编写第一个Java程序
编写第一个Java程序 完成工作:1.在文本编辑器中输入一个Java程序. 2.使用括号组织程序. 3.保存.编译和运行程序. package com.Jsample;//将程序的包名称命名为com. ...
随机推荐
- IIS7.5支持html页面包含(include)html页面
前提条件: ServerSideIncludeModule的安装: 在安装iis的时候选择上该服务(“在服务端包含文件”,选项)即可,如下: 1:处理映射程序 添加模块映射 请求路径 *.html 模 ...
- cmd
ExecuteNonQuery 返回影响的行数 ExecuteScalar 返回第一行第一列
- android listview用adapter.notifyDataSetChanged()无法刷新每项的图标
http://blog.csdn.net/caizhegnhao/article/details/41318575 今天在开发中遇到一个很奇怪的listview的问题. 这个问题情景是我的应用需要做一 ...
- 学习WCF之——wcf程序的创建
这是我参考的主要资料——wcf学习之旅:http://www.cnblogs.com/artech/archive/2007/02/26/656901.html 首先,如博客上介绍的一样,创建空白的项 ...
- haskell io模块
haskell中的io模块主要是用于读写文件屏幕的,通过import IO来导入 其中有如下常用定义 data IOMode = ReadMode | WriteMode | AppendMode | ...
- C#分布式缓存一:Couchbase的安装与简单使用
一.简介 目前C#业界使用得最多的 Cache 系统主要是 Memcached和 Redis. 这两个 Cache 系统可以说是比较成熟的解决方案,也是很多系统当然的选择. Memcache的开发团队 ...
- [MSSQL]SCOPE_IDENTITY,IDENT_CURRENT以及@@IDENTITY的区别
简单解释下SCOPE_IDENTITY函数,IDENT_CURRENT函数以及@@IDENTITY全局变量的区别 SCOPE_IDENTITY函数返回当前作用域内,返回最后一次插入数据表的标识,意思是 ...
- Bug Tracker 使用笔记(有图有真相)
目的:管理Bug,完善业务流程. 前提条件:BugTracker是基于IIS和SQL Server和Asp.Net的.相当于一个Web端的管理系统. 1.下载地址 http://sourceforge ...
- 自己动手写UI库——引入ExtJs(布局)
第一: 来看一下最终的效果 第二: 来看一下使用方法: 第三: Component类代码如下所示: public class Component { pub ...
- C#,Java,C -循环冗余检验:CRC-16-CCITT查表法
C#代码 using System; using System.Collections.Generic; using System.Linq; using System.Text; namespace ...