Hashtable、Dictionary和List 谁效率更高
一 前言
很少接触HashTable晚上回来简单看了看,然后做一些增加和移除的操作,就想和List 与 Dictionary比较下存数据与取数据的差距,然后便有了如下的一此测试,
当然我测的方法可能不是很科学,但至少是我现在觉得比较靠谱的方法。如果朋友们有什么好的方法,欢迎提出大家来交流下。
先来简单介绍这三个容器的各自特点吧
1 hashtable 散列表(也叫哈希表),是根据关键字(Key value)而直接访问在内存存储位置的数据结构。
2 List<T> 是针对特定类型、任意长度的一个泛型集合,实质其内部是一个数组。
3 Dictionary<TKey, TValue> 泛型类提供了从一组键到一组值的映射。字典中的每个添加项都由一个值及其相关联的键组成。通过键来检索值,实质其内部也是散列表
有了简单的介绍后下面开始来比较了
二 效率比较
2.1 插入效率
先以10万条为基础,然后增加到100万
细心的园友发现我代码存在不合理之处,在Hashtable 与Dictionary中都有发生装箱操作,所以重定定义了两个object类型参数以避免装箱
结果也有区别了

Hashtable hashtable = new Hashtable();
List<string> list = new List<string>();
Dictionary<string, object> dic = new Dictionary<string, object>();
object value1 =123;
object value2 =456;
var watchH = new Stopwatch();
var watchL = new Stopwatch();
var watchD = new Stopwatch();
//Hashtable
watchH.Start();
for (int i = ; i < ; i++)
{
hashtable.Add( i.ToString(), value1); }
Console.WriteLine(watchH.Elapsed);
//List
watchL.Start();
for (int i = ; i < ; i++)
{
list.Add(i.ToString());
}
Console.WriteLine(watchL.Elapsed);
//Dictionary
watchD.Start();
for (int i = ; i < ; i++)
{
dic.Add(i.ToString(), value2);
}
Console.WriteLine(watchD.Elapsed);
Console.WriteLine("插入结束!");
10万结果如下测试3次以上
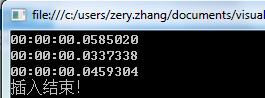
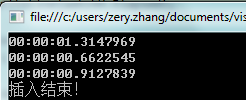
100万结果如下测试3次以上
2.2 结论
1 不管是10万还是100万List集合所用的时间总是最少的,我想这与其内部是数组有关,都是按顺序插入而且大小是一至的,在空间上应该占用是最小的
2 Hashtable在10万次时,所花时间多于List,比List时间多我想是因为要把Key做一个散列值计算 在这一步会花掉部分时间,空间上占用应该要比List大得多,因为散列值是无序的。
3 Dictionary 这个结果让我不太明白了,内部同样也是Hashtable也要做散列值计算,为什么要比原生的hashtable花的时间更少呢?
求助朋友们~~!!
2.3 查找效率
同样以10万次和100万次做测试 插入的代码就不重复贴与上面一致
var watchH = new Stopwatch();
var watchL = new Stopwatch();
var watchD = new Stopwatch();
//HashTable
watchH.Start();
object valueH = hashtable[""];
Console.WriteLine(watchH.Elapsed); //List
watchL.Start();
string valueL = list.Find(o => o == "");
Console.WriteLine(watchL.Elapsed); //Dictionary
watchD.Start();
object valurd = dic[""];
Console.WriteLine(watchD.Elapsed); Console.WriteLine("查找完毕!");
Console.Read();
在10万次的情况下
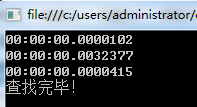
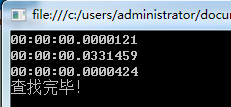
在100万次的情况下
2.4 结论
1 Hashtable 不认在10万次还是100万次的情况下在查找时速度都是惊人的快为什么会这么快呢,我用超精减的话说,hashtable在存数据时会把key通过散列函数计算出地址然后存入,那在取值同样把key通过散列函数计算出地址,然后直接取值,所以速度很快
2 Dictionary 因其内部是Hashtable所以速度也很快,但总是要比Hashtable慢一点,我猜这与Dictionary把Hashtable当做自己的数据容器时应该有相应的代码来操作,可能是这些代码花掉了时间,当然这个只是我的猜测 至于真正原因 我 再一次求助朋友们~~!!
3 List 这个就简单了要想在数组中查找一条记录唯一的办法就是遍历数组,而且我试过把查找的对象换成"0"与"999999"两者的时间差距非常大,也更足以证明了List的查找是用遍历的方式处理的
三 总结
通过对三种数据结构做插入与查找的对比,还是有亮点的,至少让我知道原来Hashtable是这么的强悍,对于需要从大量唯一数据中查找唯一值时Hashtable是很值得考虑的,
但是hashtable是用空间来换取时间的,花的时间少了点用的空间就必然大了,而List则用时间来换取空间的,总是三种数据结构各自己有各自存在的优点,我们应该在合理的情况下合理的使用这三种结构,本文也只是单一的从效率上测试而以。
另外 文章我还有两个疑问希望园子里的朋友们能指点一二 谢谢~
1 Dictionary 内部同样也是Hashtable也要做散列值计算,为什么在插入数据时要比原生的hashtable要快呢?
2 Dictionary 内部实质也是hashtable为什么在查找时总是要比原生的Hashtable要慢呢?
Hashtable、Dictionary和List 谁效率更高的更多相关文章
- RDIFramework.NET ━ .NET快速信息化系统开发框架 V3.2->WinForm版本新增新的角色授权管理界面效率更高、更规范
角色授权管理模块主要是对角色的相应权限进行集中设置.在角色权限管理模块中,管理员可以添加或移除指定角色所包含的用户.可以分配或授予指定角色的模块(菜单)的访问权限.可以收回或分配指定角色的操作(功能) ...
- RDIFramework.NET ━ .NET快速信息化系统开发框架 V3.2->Web版本新增新的角色授权管理界面效率更高、更规范
角色授权管理模块主要是对角色的相应权限进行集中设置.在角色权限管理模块中,管理员可以添加或移除指定角色所包含的用户.可以分配或授予指定角色的模块(菜单)的访问权限.可以收回或分配指定角色的操作(功能) ...
- Spring AOP中的JDK和CGLib动态代理哪个效率更高?
一.背景 今天有小伙伴面试的时候被问到:Spring AOP中JDK 和 CGLib动态代理哪个效率更高? 二.基本概念 首先,我们知道Spring AOP的底层实现有两种方式:一种是JDK动态代理, ...
- MySQL select * 和把所有的字段都列出来,哪个效率更高?
MySQL select * 和把所有的字段都列出来,哪个效率更高 答案是:如何,都不推荐使用 SELECT * FROM (1)SELECT *,需要数据库先 Query Table Metadat ...
- Http请求封装(对HttpClient类的进一步封装,使之调用更方便。另外,此类管理唯一的HttpClient对象,支持线程池调用,效率更高)
package com.ad.ssp.engine.common; import java.io.IOException; import java.util.ArrayList; import jav ...
- 在类中,调用这个类时,用$this->video_model是不是比每次调用这个类时D('Video')效率更高呢
在类中,调用这个类时,用$this->video_model是不是比每次调用这个类时D('Video')效率更高呢
- 取代 Mybatis Generator,这款代码生成神器配置更简单,开发效率更高!
作为一名 Java 后端开发,日常工作中免不了要生成数据库表对应的持久化对象 PO,操作数据库的接口 DAO,以及 CRUD 的 XML,也就是 mapper. Mybatis Generator 是 ...
- 数据库查询SQL语句的时候如何写会效率更高?
引言 以前刚开始做项目的时候,开发经验尚浅,遇到问题需求只要把结果查询出来就行,至于查询的效率可能就没有太多考虑,数据少的时候还好,数据一多,效率问题就显现出来了.每次遇到查询比较慢时,项目经理就会问 ...
- i++与++i哪个效率更高
简单的比较前缀自增运算符和后缀自增运算符的效率是片面的, 因为存在很多因素影响这个问题的答案. 首先考虑内建数据类型的情况: 如果自增运算表达式的结果没有被使用, 而是仅仅简单地用于增加一元操作数, ...
随机推荐
- 如何将消息发送给Whatsapp联系人
如何将消息发送给Whatsapp联系人 (由于本人喜欢word文档编辑,不喜欢网络编辑,所以仍然提供pdf版文档,方便查阅http://files.cnblogs.com/franksunny/sen ...
- ML 05、分类、标注与回归
机器学习算法 原理.实现与实践 —— 分类.标注与回归 1. 分类问题 分类问题是监督学习的一个核心问题.在监督学习中,当输出变量$Y$取有限个离散值时,预测问题便成为分类问题. 监督学习从数据中学习 ...
- Codeforces Round #318 [RussianCodeCup Thanks-Round] (Div. 2)C. Bear and Poker
C. Bear and Poker ...
- 【HTML5】input类型
* email <input type="email" name="user_email" /> * url <input type=&quo ...
- Android DrawerLayout 高仿QQ5.2双向侧滑菜单
1.概述 之前写了一个Android 高仿 QQ5.0 侧滑菜单效果 自定义控件来袭 ,恰逢QQ5.2又加了一个右侧菜单,刚好看了下DrawerLayout,一方面官方的东西,我都比较感兴趣:另一方面 ...
- JS插件
1.Placeholders.js 所有的浏览器都支持placeholder,唯独IE不支持.现在我们有了这款插件,IE下终于可以支持了! 2.Html5shiv.js 主要解决HTML5提出的新的元 ...
- 递推DP 赛码 1005 Game
题目传送门 /* 递推DP:官方题解 令Fi,j代表剩下i个人时,若BrotherK的位置是1,那么位置为j的人是否可能获胜 转移的时候可以枚举当前轮指定的数是什么,那么就可以计算出当前位置j的人在剩 ...
- 2015ACM/ICPC亚洲区长春站 J hdu 5536 Chip Factory
Chip Factory Time Limit: 18000/9000 MS (Java/Others) Memory Limit: 262144/262144 K (Java/Others)T ...
- BZOJ1111 : [POI2007]四进制的天平Wag
POI2007完结撒花~ 首先将n转化为四进制,从低位到高位DP f[i]表示这一位不向下一位借位 g[i]表示这一位向下一位借位,但借的那个不算在i f[0]=0,g[0]=inf f[i]=mer ...
- 【COGS & USACO】896. 圈奶牛(凸包)
http://cojs.tk/cogs/problem/problem.php?pid=896 我的计算几何入门题... 看了看白书的计算几何部分,,恩好嘛.. 乃们都用向量!!!! 干嘛非要将2个点 ...