ThreadPoolExecutor 分析
一、 演示
public class ThreadPoolTest {
static class MyThread implements Runnable {
private String name;
public MyThread(String name) {
this.name = name;
}
@Override
public void run() {
try {
Thread.sleep(1000);
System.out.println(name + " finished job!") ;
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
// 创建线程池,为了更好的明白运行流程,增加了一些额外的代码
// BlockingQueue<Runnable> queue = new ArrayBlockingQueue<Runnable>(2);
BlockingQueue<Runnable> queue = new LinkedBlockingQueue<Runnable>();
// BlockingQueue<Runnable> queue = new PriorityBlockingQueue<Runnable>();
// BlockingQueue<Runnable> queue = new SynchronousQueue<Runnable>();
// AbortPolicy/CallerRunsPolicy/DiscardOldestPolicy/DiscardPolicy
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(2, 4, 5, TimeUnit.SECONDS,
queue, new ThreadPoolExecutor.AbortPolicy());
for (int i = 0; i < 10; i++) {
System.out.println("当前线程池大小[" + threadPool.getPoolSize() + "],当前队列大小[" + queue.size() + "]");
threadPool.execute(new MyThread("Thread" + i));
}
// 关闭线程池
threadPool.shutdown();
}
}
There are three general strategies for queuing:
- Direct handoffs. A good default choice for a work queue is a
SynchronousQueuethat hands off tasks to threads without otherwise holding them. Here, an attempt to queue a task will fail if no threads are immediately available to run it, so a new thread will be constructed. This policy avoids lockups when handling sets of requests that might have internal dependencies. Direct handoffs generally require unbounded maximumPoolSizes to avoid rejection of new submitted tasks. This in turn admits the possibility of unbounded thread growth when commands continue to arrive on average faster than they can be processed. - Unbounded queues. Using an unbounded queue (for example a
LinkedBlockingQueuewithout a predefined capacity) will cause new tasks to wait in the queue when all corePoolSize threads are busy. Thus, no more than corePoolSize threads will ever be created. (And the value of the maximumPoolSize therefore doesn't have any effect.) This may be appropriate when each task is completely independent of others, so tasks cannot affect each others execution; for example, in a web page server. While this style of queuing can be useful in smoothing out transient bursts of requests, it admits the possibility of unbounded work queue growth when commands continue to arrive on average faster than they can be processed. - Bounded queues. A bounded queue (for example, an
ArrayBlockingQueue) helps prevent resource exhaustion when used with finite maximumPoolSizes, but can be more difficult to tune and control. Queue sizes and maximum pool sizes may be traded off for each other: Using large queues and small pools minimizes CPU usage, OS resources, and context-switching overhead, but can lead to artificially low throughput. If tasks frequently block (for example if they are I/O bound), a system may be able to schedule time for more threads than you otherwise allow. Use of small queues generally requires larger pool sizes, which keeps CPUs busier but may encounter unacceptable scheduling overhead, which also decreases throughput.
排队有三种通用策略:
直接提交。工作队列的默认选项是
SynchronousQueue,它将任务直接提交给线程而不保持它们。在此,如果不存在可用于立即运行任务的线程,则试图把任务加入队列将失败,因此会构造一个新的线程。此策略可以避免在处理可能具有内部依赖性的请求集时出现锁(A线程需要先运行,然后是B线程,SynchronousQueue可以保证这个执行顺序)。直接提交通常要求无界 maximumPoolSizes 以避免拒绝新提交的任务。当命令以超过队列所能处理的平均数连续到达时,此策略允许无界线程具有增长的可能性。无界队列。当每个任务完全独立于其他任务,即任务执行互不影响时,适合于使用无界队列;例如,在 Web 页服务器中。这种排队可用于处理瞬态突发请求,当命令以超过队列所能处理的平均数连续到达时,此策略允许无界线程具有增长的可能性。
有界队列。当使用有限的 maximumPoolSizes 时,有界队列(如
ArrayBlockingQueue)有助于防止资源耗尽,但是可能较难调整和控制。队列大小和最大池大小可能需要相互折衷:使用大型队列和小型池可以最大限度地降低 CPU 使用率、操作系统资源和上下文切换开销,但是可能导致人工降低吞吐量。如果任务频繁阻塞(例如, I/O密集型 ),则系统可能为超过您许可的更多线程安排时间。使用小型队列通常要求较大的池大小,CPU 使用率较高,但是可能遇到不可接受的调度开销,这样也会降低吞吐量。
二、构造函数及其参数含义
1. 当线程数 < 核心线程数时,创建线程
2. 线程数 >= 核心线程数,
2.1 任务队列未满时,将任务放入任务队列。
2.2 任务队列已满
2.2.1 线程数 < 最大线程数,创建线程
2.2.2 线程数 > 最大线程数,抛出异常,拒绝任务
public ThreadPoolExecutor(int corePoolSize, //核心线程的数量
int maximumPoolSize, //最大线程数量
long keepAliveTime, //超出核心线程数量以外的线程空余存活时间
TimeUnit unit, //存活时间的单位
BlockingQueue<Runnable> workQueue, //保存待执行任务的队列
ThreadFactory threadFactory, //创建新线程使用的工厂
RejectedExecutionHandler handler // 当任务无法执行时的处理器
) {...}
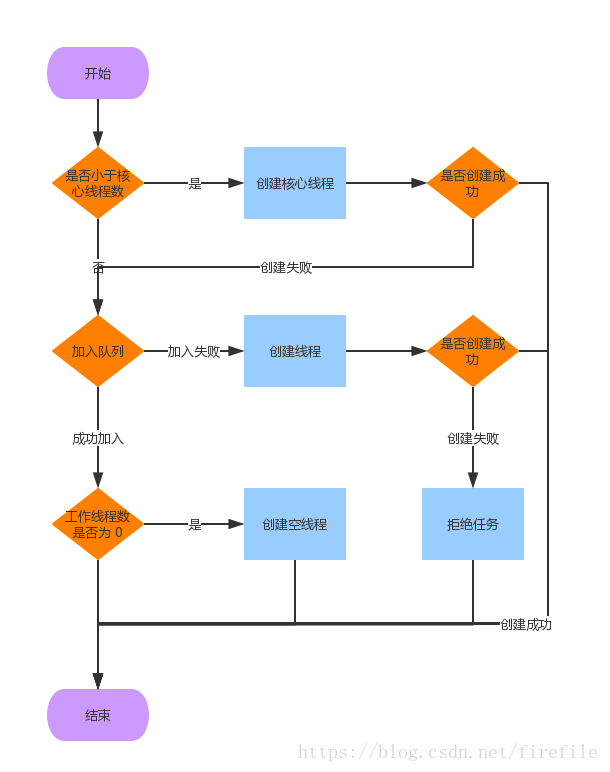
执行判断
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
//1.当前池中线程比核心数少,新建一个线程执行任务
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
//2.核心池已满,但任务队列未满,添加到队列中,所以:如果是无界队列,添加的任务超过核心线程后,不会创建非核心线程,maximumPoolSize参数无效
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command)) //如果这时被关闭了,拒绝任务
reject(command);
else if (workerCountOf(recheck) == 0) //如果之前的线程已被销毁完,新建一个线程
addWorker(null, false);
}
//3.核心池已满,队列已满,试着创建一个新线程
else if (!addWorker(command, false))
reject(command); //如果创建新线程失败了,说明线程池被关闭或者线程池完全满了,拒绝任务
}
不同类型线程池构造
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
三、如何确定系统的处理能力、线程数
1. 处理能力
利特尔法则(Little's law),在一个稳定的系统中,长时间观察到的平均顾客数量L = 长时间观察到的有效到达速率λ * 平均每个顾客在系统中花费的时间W,即L = λW。
假定我们所开发的并发服务器,并发的访问速率是:1000客户/分钟,每个客户在该服务器上将花费平均0.5分钟,根据little's law规则,
在任何时刻,服务器将承担1000×0.5=500个客户量的业务处理。假定过了一段时间,由于客户群的增大,并发的访问速率提升为2000客户/分钟。
在这样的情况下,我们该如何改进我们系统的性能?
根据little's law规则,有两种方案:
第一:提高服务器并发处理的业务量,即提高到2000×0.5=1000。 或者
2. 线程数
如果是CPU密集型应用,则线程池大小设置为N+1
如果是IO密集型应用,则线程池大小设置为2N+1
是否使用线程池就一定比使用单线程高效呢?
答案是否定的,比如Redis就是单线程的,但它却非常高效,基本操作都能达到十万量级/s。从线程这个角度来看,部分原因在于:
多线程带来线程上下文切换开销,单线程就没有这种开销
锁
更本质的原因在于:Redis基本都是内存操作,这种情况下单线程可以很高效地利用CPU。而多线程适用场景一般是:存在相当比例的IO和网络操作。
所以即使有上面的简单估算方法,也许看似合理,但实际上也未必合理,都需要结合系统真实情况(比如是IO密集型或者是CPU密集型或者是纯内存操作)
和硬件环境(CPU、内存、硬盘读写速度、网络状况等)来不断尝试达到一个符合实际的合理估算值。
四、Worker
/**
* Class Worker mainly maintains interrupt control state for
* threads running tasks, along with other minor bookkeeping.
* This class opportunistically extends AbstractQueuedSynchronizer
* to simplify acquiring and releasing a lock surrounding each
* task execution. This protects against interrupts that are
* intended to wake up a worker thread waiting for a task from
* instead interrupting a task being run. We implement a simple
* non-reentrant mutual exclusion lock rather than use
* ReentrantLock because we do not want worker tasks to be able to
* reacquire the lock when they invoke pool control methods like
* setCorePoolSize. Additionally, to suppress interrupts until
* the thread actually starts running tasks, we initialize lock
* state to a negative value, and clear it upon start (in
* runWorker).
*/
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
Worker是ThreadPoolExecutor的静态内部类,主要是对Thread对象的包装,一个Worker内部有一个Thread对象。
Worker继承自AQS来实现一个简单互斥锁,每一个任务的执行前和执行后都会分别获取和释放一次锁, 这样做是为了让线程执行任务时屏蔽中断操作。
那么为什么不用ReentrantLock呢?其实是为了避免在任务执行中修改线程池的变量和状态,不能用可重入锁。
参考:
ThreadPoolExecutor 分析的更多相关文章
- 线程池ThreadPoolExecutor分析: 线程池是什么时候创建线程的,队列中的任务是什么时候取出来的?
带着几个问题进入源码分析: 1. 线程池是什么时候创建线程的? 2. 任务runnable task是先放到core到maxThread之间的线程,还是先放到队列? 3. 队列中的任务是什么时候取出来 ...
- 线程池ThreadPoolExecutor分析
线程池.线程池是什么,说究竟,线程池是处理多线程的一种形式,管理线程的创建,任务的运行,避免了无限创建新的线程带来的资源消耗,可以提高应用的性能.非常多相关操作都是离不开的线程池的,比方android ...
- 【Java线程池】 java.util.concurrent.ThreadPoolExecutor 分析
线程池概述 线程池,是指管理一组同构工作线程的资源池. 线程池在工作队列(Work Queue)中保存了所有等待执行的任务.工作者线程(Work Thread)会从工作队列中获取一个任务并执行,然后返 ...
- 深入理解Java线程池:ThreadPoolExecutor
线程池介绍 在web开发中,服务器需要接受并处理请求,所以会为一个请求来分配一个线程来进行处理.如果每次请求都新创建一个线程的话实现起来非常简便,但是存在一个问题: 如果并发的请求数量非常多,但每个线 ...
- java多线程——线程池源码分析(一)
本文首发于cdream的个人博客,点击获得更好的阅读体验! 欢迎转载,转载请注明出处. 通常应用多线程技术时,我们并不会直接创建一个线程,因为系统启动一个新线程的成本是比较高的,涉及与操作系统的交互, ...
- Java并发编程系列-(6) Java线程池
6. 线程池 6.1 基本概念 在web开发中,服务器需要接受并处理请求,所以会为一个请求来分配一个线程来进行处理.如果每次请求都新创建一个线程的话实现起来非常简便,但是存在一个问题:如果并发的请求数 ...
- 线程池小结(JDK8)
1.线程池的好处 降低资源消耗(重复利用已创建的线程减少创建和销毁线程的开销) 提高响应速度(无须创建线程) 提高线程的可管理性 2.相关类图 JDK5以后将工作单元和执行机制分离开来,工作单元包括R ...
- ThreadPoolExcutor 原理探究
概论 线程池(英语:thread pool):一种线程使用模式.线程过多会带来调度开销,进而影响缓存局部性和整体性能.而线程池维护着多个线程,等待着监督管理者分配可并发执行的任务.这避免了在处理短时间 ...
- 【JUC】JDK1.8源码分析之ThreadPoolExecutor(一)
一.前言 JUC这部分还有线程池这一块没有分析,需要抓紧时间分析,下面开始ThreadPoolExecutor,其是线程池的基础,分析完了这个类会简化之后的分析,线程池可以解决两个不同问题:由于减少了 ...
随机推荐
- javascript优化--05模式(函数)
回调函数模式: 基本例子: var findNodes = function (callback) { ...................... if (typeof callback !== ' ...
- POJ3162 Walking Race(树形DP+尺取法+单调队列)
题目大概是给一棵n个结点边带权的树,记结点i到其他结点最远距离为d[i],问d数组构成的这个序列中满足其中最大值与最小值的差不超过m的连续子序列最长是多长. 各个结点到其他结点的最远距离可以用树形DP ...
- Sql 字符串替换
(1) 字符串替换 Update SongADD_EMH0055 SET songno = REPLACE(songno, '231', '233') where songno like '%1022 ...
- TYVJ P1045 &&洛谷 1388 最大的算式 Label:dp
描述 题目很简单,给出N个数字,不改变它们的相对位置,在中间加入K个乘号和N-K-1个加号,(括号随便加)使最终结果尽量大.因为乘号和加号一共就是N-1个了,所以恰好每两个相邻数字之间都有一个符号.例 ...
- 【BZOJ】1251: 序列终结者(splay)
http://www.lydsy.com/JudgeOnline/problem.php?id=1251 不行..为什么写个splay老是犯逗,这次又是null的mx没有赋值-maxlongint.. ...
- ubuntu下新建用户的终端不显示当前路径,不能用上下光标键得到使用过的命名解决办法
这几天我装ubuntu10.10,xubuntu12.04创建新用户的时候,总会遇到这个问题 就是打开终端的时候,没有路径了,即:xxx@xxx:~$ 找了很久,最后找到了(http://www.os ...
- 关于HTML条件注释你可能不知道的一些事儿
最近经常看到类似这样的HTML代码片段,很多前端开发人员应该都熟悉: 1 <!--[if lt IE 7]> <html class="ie6"> ...
- 在thinkphp框架模板中引用session
我已经将模板引擎配置为smarty,在模板中使用常量是写为 {$smarty.const.ADMIN_IMG} 到使用到session的值时这样写 {$smarty.session.mg_name}
- IIS7 Appcmd.exe 使用
如果您运行的是 64 位 Windows,请从 %windir%\system32\inetsrv 目录而不是 %windir%\syswow64\inetsrv 目录中使用 Appcmd.exe. ...
- 在Excel中实现查询功能
$sn = Read-Host -Prompt "请输入员工号|序列号|资产号" $xl = New-Object -ComObject "Excel.Applicati ...