Apache Spark源码走读之14 -- Graphx实现剖析
欢迎转载,转载请注明出处,徽沪一郎。
概要
图的并行化处理一直是一个非常热门的话题,这里头的重点有两个,一是如何将图的算法并行化,二是找到一个合适的并行化处理框架。Spark作为一个非常优秀的并行处理框架,将一些并行化的算法移到其上面就成了一个很自然的事情。
Graphx是一些图的常用算法在Spark上的并行化实现,同时提供了丰富的API接口。本文就Graphx的代码架构及pagerank在graphx中的具体实现做一个初步的学习。
Google为什么赢得了搜索引擎大战
当Google还在起步的时候,在搜索引擎领域,Yahoo正如日中天,红的发紫。显然,在Google面前的是一堵让人几乎没有任何希望的墙。
但世事难料,现在“外事问谷歌”成了不争的事实,Yahoo应也陪客了。
这种转换到底是如何形成的了,有一个因素是这样的,那就是Google发明了显著提高搜索准确率的PageRank算法。如果说PageRank算法的提出让谷歌牢牢站稳了搜索引擎大战的脚跟,这是毫不夸张的。
搜索引擎有几个要考虑的关键因素(个人观点而已)。
- 要想吸引用户,就必须要有出色的搜索准确率
- 有了用户,才能做广告投放,提高广告投放的针对性就可以盈利
上述两个方面都有非常优秀的算法。
废话少述,回到正题。PageRank算法是图论的一个具体应用,ok, 转到图论。
图论简介
图的组成
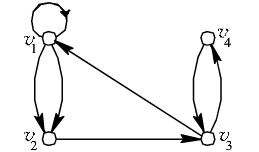
离散数学中非常重要的一个部分就是图论,下面是一个无向连通图

顶点(vertex)
上图中的A,B,C,D,E称为图的顶点。
边
顶点与顶点之间的连线称之为边。
图的数学表示
读大学的时候,一直没有想明白为什么要学劳什子的线性代数。直到这两天看《数学之美》一书时,才发觉,线性代数在一些计算机应用领域,那简直就是不可或缺啊。
我们比较容易理解的平面几何和立体几何(一个是二维,一个是三维),而线性代数解决的其实是一个高维问题,由于无法直觉的感受到,所以很难。如果想比较通俗的理解一下数学为什么有这么多的分支及其内在关联,强烈推荐读一下《数学桥 对高等数学的一次观赏之旅》。
在数学中,用什么来表示图呢,答案就是线性代数里面的矩阵,想想看,图的关联矩阵,图的邻接矩阵。总之就是矩阵啦,线性代数一下子有用了。下面是一个具体的例子。

图的并行化处理
刚才说到图可以用矩阵来表示,图的并行化问题在某种程度上就被转化为矩阵运算的并行化问题。
那么以矩阵的乘法为例,看看其是否可以并行化处理。
以矩阵 A X B 为例,说明并行化处理过程。
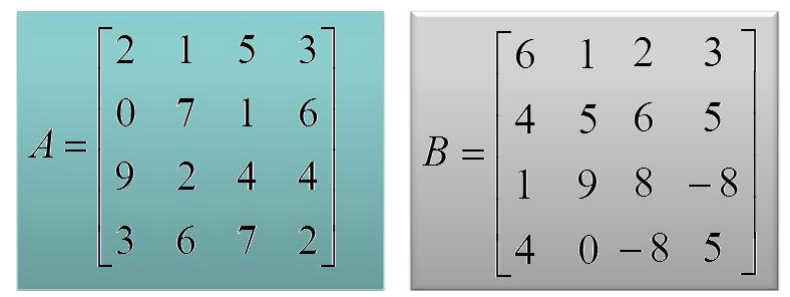
将上述的矩阵A和B划分为四个部分,如下图所示
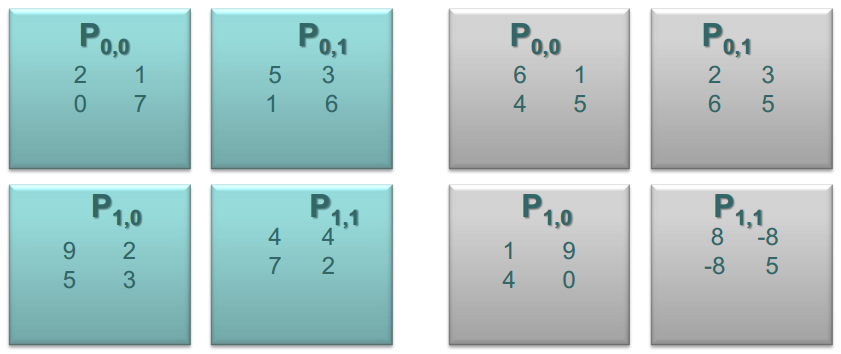
首次对齐之后
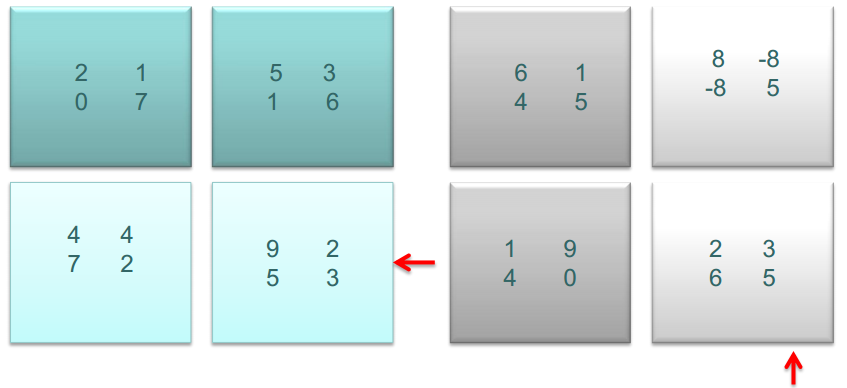
子矩阵相乘

相乘之后,A的子矩阵左移,B的子矩阵上移
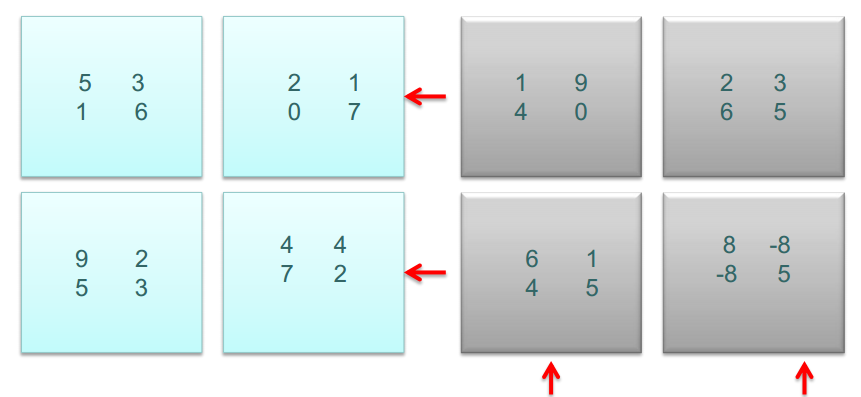
计算结果合并

图的并行化处理框架,从Pregel说起
上一节的重点有两点
- 图用矩阵来表示,对图的运算就是矩阵的运算
- 矩阵乘法运算可以并行化,动态演示其并行化的原理
你说ok,我明白了。哪有没有一种合适的并行化处理框架可以用来进行图的计算呢,那你肯定想到了MapReduce。
MapReduce尽管也是一个不错的并行化处理框架,但在图计算方面,有许多缺点,主要是计算的中间过程需要存储到硬盘,效率很低。
Google针对图的并行处理,专门提出了一个了不起的框架Pregel。其执行时的动态视图如下所示。
Pregel有如下优点
- 级联可扩性好 scalability
- 容错性强
- 能够很好的表示各种图的常用算法

Pregel的计算模型
计算模型如下图所示,重要的有三个
- 作用于每个顶点的处理逻辑 vertexProgram
- 消息发送,用于相邻节点间的通讯 sendMessage
- 消息合并逻辑 messageCombining

Pregel在Spark中的实现
非常感谢你能坚持看到现在,这篇博客内容很多,有点难。我想还是上一幅图将其内在逻辑整一下再继续说下去。
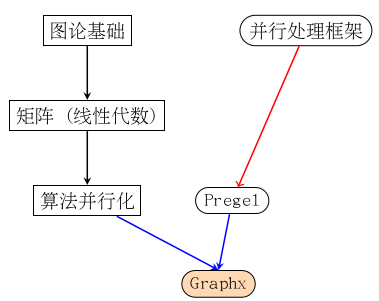
该图要表示的意思是这样的,Graphx利用了Spark这样了一个并行处理框架来实现了图上的一些可并行化执行的算法。
本篇博客要表达的意思就是上面加红的这句话,请诸位看官仔细理解。
- 算法是否能够并行化与Spark本身无关
- 算法并行化与否的本身,需要通过数学来证明
- 已经证明的可并行化算法,利用Spark来实现会是一个错的选择,因为Graphx支持pregel的图计算模型
Graphx中的重要概念
Graph
毫无疑问,图本身是graphx中一个非常重要的概念。
成员变量
graph中重要的成员变量分别为
- vertices
- edges
- triplets
为什么要引入triplets呢,主要是和Pregel这个计算模型相关,在triplets中,同时记录着edge和vertex. 具体代码就不罗列了。
成员函数
函数分成几大类
- 对所有顶点或边的操作,但不改变图结构本身,如mapEdges, mapVertices
- 子图,类似于集合操作中的filter subGraph
- 图的分割,即paritition操作,这个对于Spark计算来说,很关键,正是因为有了不同的Partition,才有了并行处理的可能, 不同的PartitionStrategy,其收益不同。最容易想到的就是利用Hash来将整个图分成多个区域。
- outerJoinVertices 顶点的外连接操作
图的运算和操作 GraphOps
图的常用算法是集中抽象到GraphOps这个类中,在Graph里作了隐式转换,将Graph转换为GraphOps
implicit def graphToGraphOps[VD: ClassTag, ED: ClassTag]
(g: Graph[VD, ED]): GraphOps[VD, ED] = g.ops
支持的操作如下
- collectNeighborIds
- collectNeighbors
- collectEdges
- joinVertices
- filter
- pickRandomVertex
- pregel
- pageRank
- staticPageRank
- connectedComponents
- triangleCount
- stronglyConnectedComponents
RDD
RDD是Spark体系的核心,那么Graphx中引入了哪些新的RDD呢,有俩,分别为
- VertexRDD
- EdgeRDD
较之EdgeRdd,VertexRDD更为重要,其上的操作也很多,主要集中于Vertex之上属性的合并,说到合并就不得不扯到关系代数和集合论,所以在VertexRdd中能看到许多类似于sql中的术语,如
- leftJoin
- innerJoin
至于leftJoin, innerJoin, outerJoin的区别,建议谷歌一下,不再赘述。
Graphx场景分析
图的存储和加载
在进行数学计算的时候,图用线性代数中的矩阵来表示,那么如何进行存储呢?
学数据结构的时候,老师肯定说过好多的办法,不再啰嗦了。
不过在大数据的环境下,如果图很巨大,表示顶点和边的数据不足以放在一个文件中怎么办? 用HDFS
加载的时候,一台机器的内存不足以容下怎么办? 延迟加载,在真正需要数据时,将数据分发到不同机器中,采用级联方式。
一般来说,我们会将所有与顶点相关的内容保存在一个文件中vertexFile,所有与边相关的信息保存在另一个文件中edgeFile。
生成某一个具体的图时,用edge就可以表示图中顶点的关联关系,同时图的结构也表示出来了。
GraphLoader
graphLoader是graphx中专门用于图的加载和生成,最重要的函数就是edgeListFile,定义如下。
def edgeListFile(
sc: SparkContext,
path: String,
canonicalOrientation: Boolean = false,
minEdgePartitions: Int = 1,
edgeStorageLevel: StorageLevel = StorageLevel.MEMORY_ONLY,
vertexStorageLevel: StorageLevel = StorageLevel.MEMORY_ONLY)
: Graph[Int, Int] =
{
val startTime = System.currentTimeMillis
// Parse the edge data table directly into edge partitions
val lines = sc.textFile(path, minEdgePartitions).coalesce(minEdgePartitions)
val edges = lines.mapPartitionsWithIndex { (pid, iter) =>
val builder = new EdgePartitionBuilder[Int, Int]
iter.foreach { line =>
if (!line.isEmpty && line(0) != '#') {
val lineArray = line.split("\\s+")
if (lineArray.length < 2) {
logWarning("Invalid line: " + line)
}
val srcId = lineArray(0).toLong
val dstId = lineArray(1).toLong
if (canonicalOrientation && srcId > dstId) {
builder.add(dstId, srcId, 1)
} else {
builder.add(srcId, dstId, 1)
}
}
}
Iterator((pid, builder.toEdgePartition))
}.persist(edgeStorageLevel).setName("GraphLoader.edgeListFile - edges (%s)".format(path))
edges.count()
logInfo("It took %d ms to load the edges".format(System.currentTimeMillis - startTime))
GraphImpl.fromEdgePartitions(edges, defaultVertexAttr = 1, edgeStorageLevel = edgeStorageLevel,
vertexStorageLevel = vertexStorageLevel)
} // end of edgeListFile
应用举例之PageRank
什么是PageRank
pageRank的核心思想
”在互联网上,如果一个网页被很多其它网页所链接,说明它受到普遍的承认和依赖,那么它的排名就很高。“ (摘自数学之美第10章)
你说这也太简单了吧,不是跟没说一个样吗,怎么用数学来表示呢?
呵呵,起初我也这么想的,后来多看了几遍之后,明白了一点点。分析步骤用文字表述如下,
- 网页和网页之间的关系用图来表示
- 网页A和网页B之间的连接关系表示任意一个用户从网页A到转到网页B的可能性(概率)
- 所有网页的排名用一维向量来B来表示
所有网页之间的连接用矩阵A来表示,所有网页排名用B来表示。

pageRank如何进行并行化
好了,上面的数学阐述说明了“网页排名的计算可以最终抽象为矩阵相乘”,而在开始的时候已经证明过矩阵相乘可以并行化处理。
理论研究结束了,接下来的就是工程实现了,借用Pregel模型,PageRank中定义的各主要函数分别如下。
vertexProgram
def vertexProgram(id: VertexId, attr: (Double, Double), msgSum: Double): (Double, Double) = {
val (oldPR, lastDelta) = attr
val newPR = oldPR + (1.0 - resetProb) * msgSum
(newPR, newPR - oldPR)
}
sendMessage
def sendMessage(edge: EdgeTriplet[(Double, Double), Double]) = {
if (edge.srcAttr._2 > tol) {
Iterator((edge.dstId, edge.srcAttr._2 * edge.attr))
} else {
Iterator.empty
}
}
messageCombiner
def messageCombiner(a: Double, b: Double): Double = a + b
一点点启示
通过pageRank这个例子,我们能够搞清楚如何将平素学习的数学理论用以解决实际问题。
“学习的东西总是有价值的,至于用的上用不上,全靠造化了”
完整代码
// Connect to the Spark cluster
val sc = new SparkContext("spark://master.amplab.org", "research")
// Load my user data and parse into tuples of user id and attribute list
val users = (sc.textFile("graphx/data/users.txt")
.map(line => line.split(",")).map( parts => (parts.head.toLong, parts.tail) ))
// Parse the edge data which is already in userId -> userId format
val followerGraph = GraphLoader.edgeListFile(sc, "graphx/data/followers.txt")
// Attach the user attributes
val graph = followerGraph.outerJoinVertices(users) {
case (uid, deg, Some(attrList)) => attrList
// Some users may not have attributes so we set them as empty
case (uid, deg, None) => Array.empty[String]
}
// Restrict the graph to users with usernames and names
val subgraph = graph.subgraph(vpred = (vid, attr) => attr.size == 2)
// Compute the PageRank
val pagerankGraph = subgraph.pageRank(0.001)
// Get the attributes of the top pagerank users
val userInfoWithPageRank = subgraph.outerJoinVertices(pagerankGraph.vertices) {
case (uid, attrList, Some(pr)) => (pr, attrList.toList)
case (uid, attrList, None) => (0.0, attrList.toList)
}
println(userInfoWithPageRank.vertices.top(5)(Ordering.by(_._2._1)).mkString("\n"))
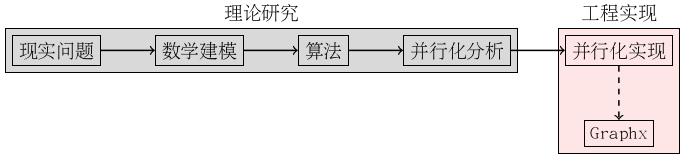
小结
本篇讲来讲去就在强调一个问题,Spark是一个分布式并行计算框架。能不能用Spark,其实大体取决于问题的数学模型本身,如果可以并行化处理,则用之,切不可削足适履。
另一个用张图来总结一下提到的数学知识吧。

再一次强烈推荐《数学桥》
参考资料
- 《数学之美》
- 《数学桥 高等数学的观赏之旅》
- 《大数据》
Apache Spark源码走读之14 -- Graphx实现剖析的更多相关文章
- Apache Spark源码走读之7 -- Standalone部署方式分析
欢迎转载,转载请注明出处,徽沪一郎. 楔子 在Spark源码走读系列之2中曾经提到Spark能以Standalone的方式来运行cluster,但没有对Application的提交与具体运行流程做详细 ...
- Apache Spark源码走读之16 -- spark repl实现详解
欢迎转载,转载请注明出处,徽沪一郎. 概要 之所以对spark shell的内部实现产生兴趣全部缘于好奇代码的编译加载过程,scala是需要编译才能执行的语言,但提供的scala repl可以实现代码 ...
- Apache Spark源码走读之13 -- hiveql on spark实现详解
欢迎转载,转载请注明出处,徽沪一郎 概要 在新近发布的spark 1.0中新加了sql的模块,更为引人注意的是对hive中的hiveql也提供了良好的支持,作为一个源码分析控,了解一下spark是如何 ...
- Apache Spark源码走读之23 -- Spark MLLib中拟牛顿法L-BFGS的源码实现
欢迎转载,转载请注明出处,徽沪一郎. 概要 本文就拟牛顿法L-BFGS的由来做一个简要的回顾,然后就其在spark mllib中的实现进行源码走读. 拟牛顿法 数学原理 代码实现 L-BFGS算法中使 ...
- Apache Spark源码走读之18 -- 使用Intellij idea调试Spark源码
欢迎转载,转载请注明出处,徽沪一郎. 概要 上篇博文讲述了如何通过修改源码来查看调用堆栈,尽管也很实用,但每修改一次都需要编译,花费的时间不少,效率不高,而且属于侵入性的修改,不优雅.本篇讲述如何使用 ...
- Apache Spark源码走读之6 -- 存储子系统分析
欢迎转载,转载请注明出处,徽沪一郎. 楔子 Spark计算速度远胜于Hadoop的原因之一就在于中间结果是缓存在内存而不是直接写入到disk,本文尝试分析Spark中存储子系统的构成,并以数据写入和数 ...
- Apache Spark源码走读之17 -- 如何进行代码跟读
欢迎转载,转载请注明出处,徽沪一郎 概要 今天不谈Spark中什么复杂的技术实现,只稍为聊聊如何进行代码跟读.众所周知,Spark使用scala进行开发,由于scala有众多的语法糖,很多时候代码跟着 ...
- Apache Spark源码走读之5 -- DStream处理的容错性分析
欢迎转载,转载请注明出处,徽沪一郎,谢谢. 在流数据的处理过程中,为了保证处理结果的可信度(不能多算,也不能漏算),需要做到对所有的输入数据有且仅有一次处理.在Spark Streaming的处理机制 ...
- Apache Spark源码走读之11 -- sql的解析与执行
欢迎转载,转载请注明出处,徽沪一郎. 概要 在即将发布的spark 1.0中有一个新增的功能,即对sql的支持,也就是说可以用sql来对数据进行查询,这对于DBA来说无疑是一大福音,因为以前的知识继续 ...
随机推荐
- Android之Bundle类
API文档说明 1.介绍 用于不同Activity之间的数据传递 1.重要方法 clear():清除此Bundle映射中的所有保存的数据. clone():克隆当前Bundle containsKey ...
- grep -C n "匹配字符串" 匹配字符串上下N行
[root@xxxxx ~]# grep -C 'ip_whitelist' /etc/gitlab/gitlab.rb # 'PATH' => "/opt/gitlab/bin:/o ...
- Unity3D入门之GUI基础以及常用GUI控件使用(2)
1.GUI基础 (1)GUI部分是每帧擦除重绘的,只应该在OnGUI中绘制GUI,按钮:GUILayout.Button(“Hello”); 只读标签:GUILayout.Label() (2)修改控 ...
- js打印html中的内容
js打印方法 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www. ...
- [原]DbHelper-SQL数据库访问助手
using System; using System.Data; using System.Data.SqlClient; namespace Whir.Software.Framework.Ulti ...
- http://jingyan.baidu.com/article/f3ad7d0ffc061a09c3345bf0.html
http://jingyan.baidu.com/article/f3ad7d0ffc061a09c3345bf0.html
- Real Adaboost总结
Real Adaboost分类器是对经典Adaboost分类器的扩展和提升,经典Adaboost分类器的每个弱分类器仅输出{1,0}或{+1,-1},分类能力较弱,Real Adaboost的每个弱分 ...
- A C[HDU1570]
A C Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Submiss ...
- BZOJ4068 : [Ctsc2015]app
对于一个所选任务集合,如果对于任意时刻$i$,$i$前面所选任务数都不超过i的话,那么这些任务可以全选. 维护一棵线段树$T$,第$i$个位置一开始为$i$,每使用一个任务,$[t,T]$都要减$1$ ...
- BZOJ2062 : 素颜2(face2)
写个cmp然后sort就好了. cmp的话,需要快速知道两个串的lcp,于是倍增+Hash即可. #include<cstdio> #include<algorithm> ty ...