Caffe学习系列(4):激活层(Activiation Layers)及参数
在激活层中,对输入数据进行激活操作(实际上就是一种函数变换),是逐元素进行运算的。从bottom得到一个blob数据输入,运算后,从top输入一个blob数据。在运算过程中,没有改变数据的大小,即输入和输出的数据大小是相等的。
输入:n*c*h*w
输出:n*c*h*w
常用的激活函数有sigmoid, tanh,relu等,下面分别介绍。
1、Sigmoid
对每个输入数据,利用sigmoid函数执行操作。这种层设置比较简单,没有额外的参数。
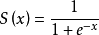
层类型:Sigmoid
示例:
layer {
name: "encode1neuron"
bottom: "encode1"
top: "encode1neuron"
type: "Sigmoid"
}
2、ReLU / Rectified-Linear and Leaky-ReLU
ReLU是目前使用最多的激活函数,主要因为其收敛更快,并且能保持同样效果。
标准的ReLU函数为max(x, 0),当x>0时,输出x; 当x<=0时,输出0
f(x)=max(x,0)
层类型:ReLU
可选参数:
negative_slope:默认为0. 对标准的ReLU函数进行变化,如果设置了这个值,那么数据为负数时,就不再设置为0,而是用原始数据乘以negative_slope
layer {
name: "relu1"
type: "ReLU"
bottom: "pool1"
top: "pool1"
}
RELU层支持in-place计算,这意味着bottom的输出和输入相同以避免内存的消耗。
3、TanH / Hyperbolic Tangent
利用双曲正切函数对数据进行变换。
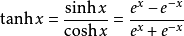
层类型:TanH
layer {
name: "layer"
bottom: "in"
top: "out"
type: "TanH"
}
4、Absolute Value
求每个输入数据的绝对值。
f(x)=Abs(x)
层类型:AbsVal
layer {
name: "layer"
bottom: "in"
top: "out"
type: "AbsVal"
}
5、Power
对每个输入数据进行幂运算
f(x)= (shift + scale * x) ^ power
层类型:Power
可选参数:
power: 默认为1
scale: 默认为1
shift: 默认为0
layer {
name: "layer"
bottom: "in"
top: "out"
type: "Power"
power_param {
power: 2
scale: 1
shift: 0
}
}
6、BNLL
binomial normal log likelihood的简称
f(x)=log(1 + exp(x))
层类型:BNLL
layer {
name: "layer"
bottom: "in"
top: "out"
type: “BNLL”
}
Caffe学习系列(4):激活层(Activiation Layers)及参数的更多相关文章
- Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数 本文只讲解视觉层(Vision La ...
- 转 Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数 本文只讲解视觉层(Vision La ...
- Caffe 学习系列
学习列表: Google protocol buffer在windows下的编译 caffe windows 学习第一步:编译和安装(vs2012+win 64) caffe windows学习:第一 ...
- Caffe学习系列(23):如何将别人训练好的model用到自己的数据上
caffe团队用imagenet图片进行训练,迭代30多万次,训练出来一个model.这个model将图片分为1000类,应该是目前为止最好的图片分类model了. 假设我现在有一些自己的图片想进行分 ...
- Caffe学习系列(12):训练和测试自己的图片
学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测试模型的整个流程. 一.准备数据 有条件的同学,可以去 ...
- 转 Caffe学习系列(12):训练和测试自己的图片
学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测试模型的整个流程. 一.准备数据 有条件的同学,可以去 ...
- Caffe学习系列——工具篇:神经网络模型结构可视化
Caffe学习系列——工具篇:神经网络模型结构可视化 在Caffe中,目前有两种可视化prototxt格式网络结构的方法: 使用Netscope在线可视化 使用Caffe提供的draw_net.py ...
- Caffe学习系列(12):训练和测试自己的图片--linux平台
Caffe学习系列(12):训练和测试自己的图片 学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测 ...
- Caffe学习系列(22):caffe图形化操作工具digits运行实例
上接:Caffe学习系列(21):caffe图形化操作工具digits的安装与运行 经过前面的操作,我们就把数据准备好了. 一.训练一个model 右击右边Models模块的” Images" ...
- Caffe学习系列(21):caffe图形化操作工具digits的安装与运行
经过前面一系列的学习,我们基本上学会了如何在linux下运行caffe程序,也学会了如何用python接口进行数据及参数的可视化. 如果还没有学会的,请自行细细阅读: caffe学习系列:http:/ ...
随机推荐
- iOS 准确计算某个时间点距现在的时间差的代码 如"几分钟,几小时,几秒之前" ,
利用时间戳来进行计算 ,需要给它一个时间: NSString *countTime = [self intervalSinceNow:@"2015-10-29 17:00:00" ...
- iOS开发中常用方法调用顺序
- C# 3个线程A B C 依次打印123123123..
C#经典面试题: 有3个线程,A线程打印1,B线程打印2,C线程打印3,请用程序实现依次打印123123123... class Program { static void Main(string[] ...
- Spring web.xml配置文件解析
概要解析
- cocos2d-x之计时器初试
bool HelloWorld::init() { if ( !Layer::init() ) { return false; } Size visibleSize = Director::getIn ...
- 怎么直接让火狐输入json数据,而不是弹出文件保存对话框?
一.问题再现: 我需要浏览器输出的是json数据,但是浏览器弹出的是一个文件保存的对话框,这样的体验有点差.所以想怎么让浏览器直接输出到浏览器的页面上面,并且格式的输出,还可以编辑. 测试数据: ht ...
- Tip和菜单的实现方式
Tip和菜单有类似的功能,即鼠标光标移上去的时候显示指定元素,鼠标光标离开的时候隐藏该元素.如下 示例1:下拉菜单(鼠标移动到“客户服务”上时出现,离开则隐藏) 示例2:水平菜单(鼠标移动到“餐饮美食 ...
- POJ 2823 Sliding Window
Sliding Window Time Limit: 12000MSMemory Limit: 65536K Case Time Limit: 5000MS Description An array ...
- HADOOP namenode HA
参考的文章:http://www.cnblogs.com/smartloli/p/4298430.html 当然,在操作的过程中,发现与上述文章中描述的还是有一些小小的区别. 配置好后,start-d ...
- Hive get table rows count batch
项目中需要比对两种方法计算生成的数据情况,需要做两件事情,比对生成的中间表的行数是否相同,比对最后一张表的数据是否一致. 在获取表的数据量是一条一条地使用select count(*) from ta ...