Autoencoders and Sparsity(一)
An autoencoder neural network is an unsupervised learning algorithm that applies backpropagation, setting the target values to be equal to the inputs. I.e., it uses 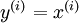 .
.
Here is an autoencoder:
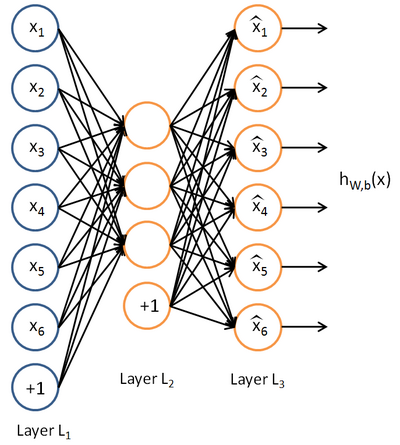
The autoencoder tries to learn a function 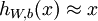 . In other words, it is trying to learn an approximation to the identity function, so as to output
. In other words, it is trying to learn an approximation to the identity function, so as to output 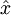 that is similar to
that is similar to  . The identity function seems a particularly trivial function to be trying to learn; but by placing constraints on the network, such as by limiting the number of hidden units, we can discover interesting structure about the data.
. The identity function seems a particularly trivial function to be trying to learn; but by placing constraints on the network, such as by limiting the number of hidden units, we can discover interesting structure about the data.
例子&用途
As a concrete example, suppose the inputs
image (100 pixels) so
, and there are
hidden units in layer
. Note that we also have
. Since there are only 50 hidden units, the network is forced to learn a compressed representation of the input. I.e., given only the vector of hidden unit activations
, it must try to reconstruct the 100-pixel input
comes from an IID Gaussian independent of the other features---then this compression task would be very difficult. But if there is structure in the data, for example, if some of the input features are correlated, then this algorithm will be able to discover some of those correlations. In fact, this simple autoencoder often ends up learning a low-dimensional representation very similar to PCAs
约束
Our argument above relied on the number of hidden units
being small. But even when the number of hidden units is large (perhaps even greater than the number of input pixels), we can still discover interesting structure, by imposing other constraints on the network. In particular, if we impose a sparsity constraint on the hidden units, then the autoencoder will still discover interesting structure in the data, even if the number of hidden units is large.
Recall that
denotes the activation of hidden unit
in the autoencoder. However, this notation doesn't make explicit what was the input
to denote the activation of this hidden unit when the network is given a specific input
be the average activation of hidden unit
where
is a sparsity parameter, typically a small value close to zero (say
). In other words, we would like the average activation of each hidden neuron
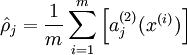
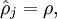
To achieve this, we will add an extra penalty term to our optimization objective that penalizes
deviating significantly from
Here,
where
is the Kullback-Leibler (KL) divergence between a Bernoulli random variable with mean
偏离,惩罚
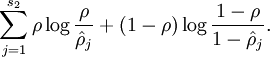
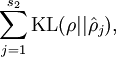
损失函数
无稀疏约束时网络的损失函数表达式如下:
带稀疏约束的损失函数如下:
where
is as defined previously, and
controls the weight of the sparsity penalty term. The term
also, because it is the average activation of hidden unit
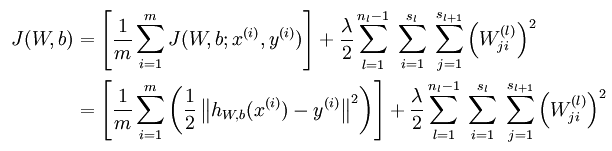
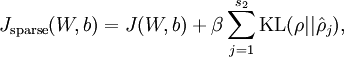
损失函数的偏导数的求法
而加入了稀疏性后,神经元节点的误差表达式由公式:
变成公式:

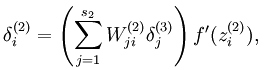
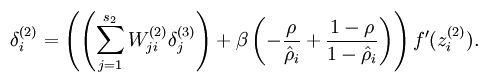
梯度下降法求解
有了损失函数及其偏导数后就可以采用梯度下降法来求网络最优化的参数了,整个流程如下所示:
从上面的公式可以看出,损失函数的偏导其实是个累加过程,每来一个样本数据就累加一次。这是因为损失函数本身就是由每个训练样本的损失叠加而成的,而按照加法的求导法则,损失函数的偏导也应该是由各个训练样本所损失的偏导叠加而成。从这里可以看出,训练样本输入网络的顺序并不重要,因为每个训练样本所进行的操作是等价的,后面样本的输入所产生的结果并不依靠前一次输入结果(只是简单的累加而已,而这里的累加是顺序无关的)。
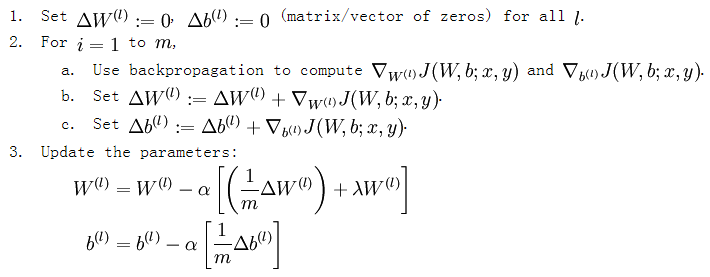
转自:http://www.cnblogs.com/tornadomeet/archive/2013/03/19/2970101.html
Autoencoders and Sparsity(一)的更多相关文章
- (六)6.4 Neurons Networks Autoencoders and Sparsity
BP算法是适合监督学习的,因为要计算损失函数,计算时y值又是必不可少的,现在假设有一系列的无标签train data: ,其中 ,autoencoders是一种无监督学习算法,它使用了本身作为标签以 ...
- CS229 6.4 Neurons Networks Autoencoders and Sparsity
BP算法是适合监督学习的,因为要计算损失函数,计算时y值又是必不可少的,现在假设有一系列的无标签train data: ,其中 ,autoencoders是一种无监督学习算法,它使用了本身作为标签以 ...
- Autoencoders and Sparsity(二)
In this problem set, you will implement the sparse autoencoder algorithm, and show how it discovers ...
- 【DeepLearning】UFLDL tutorial错误记录
(一)Autoencoders and Sparsity章节公式错误: s2 应为 s3. 意为从第2层(隐藏层)i节点到输出层j节点的误差加权和. (二)Support functions for ...
- Deep Learning 教程翻译
Deep Learning 教程翻译 非常激动地宣告,Stanford 教授 Andrew Ng 的 Deep Learning 教程,于今日,2013年4月8日,全部翻译成中文.这是中国屌丝军团,从 ...
- 三层神经网络自编码算法推导和MATLAB实现 (转载)
转载自:http://www.cnblogs.com/tornadomeet/archive/2013/03/20/2970724.html 前言: 现在来进入sparse autoencoder的一 ...
- DL二(稀疏自编码器 Sparse Autoencoder)
稀疏自编码器 Sparse Autoencoder 一神经网络(Neural Networks) 1.1 基本术语 神经网络(neural networks) 激活函数(activation func ...
- Sparse Autoencoder(二)
Gradient checking and advanced optimization In this section, we describe a method for numerically ch ...
- 【DeepLearning】Exercise:Learning color features with Sparse Autoencoders
Exercise:Learning color features with Sparse Autoencoders 习题链接:Exercise:Learning color features with ...
随机推荐
- IDL build
For Developers > Design Documents > IDL build 目录 1 Steps 2 GYP 3 Performance 3.1 Details ...
- Windows下安装Scrapy方法及常见安装问题总结——Scrapy安装教程
这几天,很多朋友在群里问Scrapy安装的问题,其实问题方面都差不多,今天小编给大家整理一下Scrapy的安装教程,希望日后其他的小伙伴在安装的时候不再六神无主,具体的教程如下. Scrapy是Pyt ...
- [POI2005]DWU-Double-row(图论?)
题意 2n 个数站成两排(每个数在 2n个数中最多出现两遍),一次操作可以交换任意一列中两个数,求使每行数不重复的最少操作数. (n<=50000) 题解 说实话,我真没想到图论.(我太菜了) ...
- CF 986A Fair(多源BFS)
题目描述 一些公司将在Byteland举办商品交易会(or博览会?).在Byteland有 nnn 个城市,城市间有 mmm 条双向道路.当然,城镇之间两两连通. Byteland生产的货物有 kkk ...
- .NET 将 .config 文件嵌入到程序集
原文:.NET 将 .config 文件嵌入到程序集 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/Iron_Ye/article/details/ ...
- 洛谷——P1019 单词接龙(NOIP2000 T3)
https://www.luogu.org/problem/show?pid=1019#sub 题目描述 单词接龙是一个与我们经常玩的成语接龙相类似的游戏,现在我们已知一组单词,且给定一个开头的字母, ...
- spring定时器中如何获取servletcontext
spring定时器中如何获取servletcontext 学习了:https://zhidao.baidu.com/question/406212574.html @Scheduled(cron = ...
- 一起talk C栗子吧(第八十一回:C语言实例--进程停止)
各位看官们,大家好,上一回中咱们说的是进程相互排斥的样例,这一回咱们说的样例是:进程停止.闲话休提,言归正转. 让我们一起talk C栗子吧! 我们在前面的章回中介绍了怎样创建进程,只是没有介绍停止进 ...
- cocos2d-x《农场模拟经营养成》游戏完整源代码
cocos2d-x农场模拟经营养成游戏完整源代码,cocos2d-x引擎开发,使用JSON交互,支持IOS与 Android,解压后1016MB. 非常强大的游戏源代码 完整游戏源代码 ...
- php中对象转数组有哪些方法(总结测试)
php中对象转数组有哪些方法(总结测试) 一.总结 一句话总结:json_decode(json_encode($array),true)和array强制转换(或带递归) 1.array方式强制转换对 ...