python第十一周:RabbitMQ、Redis
Rabbit Mq消息队列
RabbitMQ能为你做些什么?
消息系统允许软件、应用相互连接和扩展.这些应用可以相互链接起来组成一个更大的应用,或者将用户设备和数据进行连接.消息系统通过将消息的发送和接收分离来实现应用程序的异步和解偶.
或许你正在考虑进行数据投递,非阻塞操作或推送通知。或许你想要实现发布/订阅,异步处理,或者工作队列。所有这些都可以通过消息系统实现。
RabbitMQ是一个消息代理 - 一个消息系统的媒介。它可以为你的应用提供一个通用的消息发送和接收平台,并且保证消息在传输过程中的安全。
技术亮点
*可靠性
RabbitMQ提供了多种技术可以让你在性能和可靠性之间进行权衡。这些技术包括持久性机制、投递确认、发布者证实和高可用性机制。
*灵活的路由
消息在到达队列前是通过交换机进行路由的。RabbitMQ为典型的路由逻辑提供了多种内置交换机类型。如果你有更复杂的路由需求,可以将这些交换机组合起来使用,你甚至可以实现自己的交换机类型,并且当做RabbitMQ的插件来使用。
*集群
在相同局域网中的多个RabbitMQ服务器可以聚合在一起,作为一个独立的逻辑代理来使用。
*联合
对于服务器来说,它比集群需要更多的松散和非可靠链接。为此RabbitMQ提供了联合模型。
*高可用的队列
在同一个集群里,队列可以被镜像到多个机器中,以确保当其中某些硬件出现故障后,你的消息仍然安全。
*多协议
RabbitMQ 支持多种消息协议的消息传递。
*广泛的客户端
只要是你能想到的编程语言几乎都有与其相适配的RabbitMQ客户端。
*可视化管理工具
RabbitMQ附带了一个易于使用的可视化管理工具,它可以帮助你监控消息代理的每一个环节。
*追踪
如果你的消息系统有异常行为,RabbitMQ还提供了追踪的支持,让你能够发现问题所在。
*插件系统
RabbitMQ附带了各种各样的插件来对自己进行扩展。你甚至也可以写自己的插件来使用。
远程连接Rabbit MQ server
首先要在rabbitmq server上创建一个用户
sudo rabbitmqct1 add_user alex alex3714
同时还要配置权限,允许从外面访问
sudo rabbimqct1 set_permissions -p / alex ".*" ".*" ".*"
set_permissions [-p vhost] {user} {write} {read}
vhost
The name of the virtual host to which to grant the user access, defaulting to /.
user
The name of the user to grant access to the specified virtual host.
conf
A regular expression matching resource names for which the user is granted configure permissions.
write
A regular expression matching resource names for which the user is granted write permissions.
read
A regular expression matching resource names for which the user is granted read permissions.
客户端连接的时候需要配置认证参数
credentials = pika.PlainCredentials("alex","alex3374")
connencion = pika.BlockingConnection(pika.ConnectionParameters(
"10.211.55.5",5627,"/",credentials))
channel = connection.channel()
实现一个最简单的队列通信:hello world程序
producer ------ consumer 通信过程
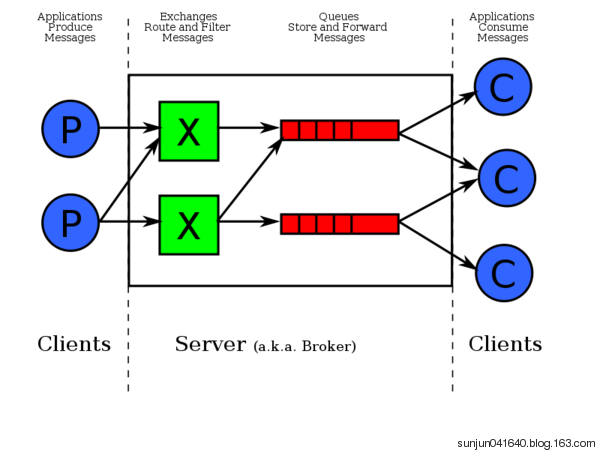
producer
# -*- coding:utf-8 -*-
#!/user/bin/env.python
#Author:Mr Wu import pika
#先建立连接
connection = pika.BlockingConnection(
pika.ConnectionParameters(
host="localhost"
)
)
#建立管道
channel = connection.channel()
#声明队列
queue = channel.queue_declare(queue="alex") #队列的名字叫做alex
#发送消息
channel.basic_publish(
exchange="", #转发器
routing_key="alex", #将消息发送到叫做alex的队列里面
body="hello world", #消息的内容
)
print("send message: hello world")
#关闭连接
connection.close() #output:
#send message: hello world
consumer:
# -*- coding:utf-8 -*-
#!/user/bin/env.python
#Author:Mr Wu import pika
#建立连接
connection = pika.BlockingConnection(
pika.ConnectionParameters(
host="localhost"
)
)
#建立管道
channel = connection.channel()
#声明一个queue
#由于生产者和消费者程序启动的顺序可能不同,如果哪一方先启动且
#没有声明一个queue,那么这方的程序就会报错,所以为了保险起见,
#在两方都声明一个相同的queue
queue = channel.queue_declare(queue="alex") #alex是queue的名字 def callback(ch,method,properties,body):
'''回调函数,如果收到消息就会调用此函数
ch:管道对象的内存地址
method:消息、及传送对象的相关参数
properties:消息持久化及返回队列等参数信息
body:消息的内容
'''
print("receive message: %s"%body)
print("ch: %s"%ch)
print("method: %s"%method)
channel.basic_consume(
callback,
queue="alex", #从叫做alex的队列中去消息
)
print("waiting message from alex......")
channel.start_consuming() #开始消费,若没有消息则会阻塞 #output:
'''
waiting message from alex......
receive message: b'hello world'
ch: <BlockingChannel impl=<Channel number=1 OPEN conn=<SelectConnection OPEN socket=('::1', 11957, 0, 0)->('::1', 5672, 0, 0) params=<ConnectionParameters host=localhost port=5672 virtual_host=/ ssl=False>>>>
method: <Basic.Deliver(['consumer_tag=ctag1.7c8c5280a34144d7b961405f8150ee9d', 'delivery_tag=1', 'exchange=', 'redelivered=False', 'routing_key=alex'])>
'''
消息持久化
一般情况下,如果Rabbit Mq的服务突然中断的话,那么已经声明的队列、发送的消息等都会丢失,如果想要保存队列和消息的话,就要用到消息持久化。
producer:
import pika
#先建立连接
connection = pika.BlockingConnection(
pika.ConnectionParameters(
host="localhost"
)
)
#建立管道
channel = connection.channel()
#声明队列
queue = channel.queue_declare(queue="alex",durable=True) #队列的名字叫做alex,
#durable=True:make queue persistent
#发送消息
channel.basic_publish(
exchange="", #转发器
routing_key="alex", #将消息发送到叫做alex的队列里面
body="hello world", #消息的内容
properties=pika.BasicProperties(
delivery_mode=2, #make message persistent
)
)
print("send message: hello world")
#关闭连接
connection.close()
consumer:
import pika
#建立连接
connection = pika.BlockingConnection(
pika.ConnectionParameters(
host="localhost"
)
)
#建立管道
channel = connection.channel()
#声明一个queue
#由于生产者和消费者程序启动的顺序可能不同,如果哪一方先启动且
#没有声明一个queue,那么这方的程序就会报错,所以为了保险起见,
#在两方都声明一个相同的queue
queue = channel.queue_declare(queue="alex",durable=True) #alex是queue的名字
#durable=True:make queue persistent def callback(ch,method,properties,body):
'''回调函数,如果收到消息就会调用此函数
ch:管道对象的内存地址
method:消息、及传送对象的相关参数
properties:消息持久化及返回队列等参数信息
body:消息的内容
'''
print("receive message: %s"%body)
#print("ch: %s"%ch)
#print("method: %s"%method)
ch.basic_ack(delivery_tag=method.delivery_tag) #处理完消息后发送确认给生产者
channel.basic_consume(
callback,
queue="alex", #从叫做alex的队列中去消息
)
print("waiting message from alex......")
channel.start_consuming() #开始消费,若没有消息则会阻塞
消息公平分发
当有多个消费者时,在默认情况下,Rabbit Mq会按顺序将消息发送给各个消费者。这样做有一个缺点:当多个消费者的性能不等的情况下,性能高的消费者很快就能处理完消息从而无事可做,而性能低下的消费者处理不完消息从而积压的消息越来越多。
RabbitMq提出的解决办法就是在各个消费者端配置perfetch=1,意思就是告诉生产者这个消费者端的消息没有处理完,不要往这个消费者发送消息。
consumer:
import pika
#建立连接
connection = pika.BlockingConnection(
pika.ConnectionParameters(
host="localhost"
)
)
#建立管道
channel = connection.channel()
#声明一个queue
#由于生产者和消费者程序启动的顺序可能不同,如果哪一方先启动且
#没有声明一个queue,那么这方的程序就会报错,所以为了保险起见,
#在两方都声明一个相同的queue
queue = channel.queue_declare(queue="alex",durable=True) #alex是queue的名字
#durable=True:make queue persistent def callback(ch,method,properties,body):
'''回调函数,如果收到消息就会调用此函数
ch:管道对象的内存地址
method:消息、及传送对象的相关参数
properties:消息持久化及返回队列等参数信息
body:消息的内容
'''
#print("receive message: %s"%body)
#print("ch: %s"%ch)
print("method: %s"%method)
ch.basic_ack(delivery_tag=method.delivery_tag) #处理完消息后发送确认给生产者
channel.basic_qos(prefetch_count=1) #只要消费者消息没有处理完,生产者就不会往这个消费者发送消息
channel.basic_consume(
callback,
queue="alex", #从叫做alex的队列中去消息
)
print("waiting message from alex......")
channel.start_consuming() #开始消费,若没有消息则会阻塞
Publish\Subscribe 消息发布、订阅
消息的发布订阅模式简单的来说就是广播模式:一个生产者---->多个消费者,一个生产者生产消息而很多消费者能够消费这个消息。
而实现这一功能是通过Exchange(交换器)实现的,而exchange在定义的时候是有类别的,来决定那些queue符合,可以接收消息。
exchange模式:
fanout:所有绑定到此exchange的queue都可以接收到消息
publiser:
# -*- coding:utf-8 -*-
#!/user/bin/env.python
#Author:Mr Wu import pika
#建立连接
connection = pika.BlockingConnection(
pika.ConnectionParameters(
host="localhost"
)
)
#声明管道
channel = connection.channel()
#声明转发器
channel.exchange_declare(
exchange="alex",
exchange_type="fanout",
)
#生产消息
channel.basic_publish(
exchange="alex",
routing_key="",
body="hello world",
)
print("send message: hello world")
connection.close()
subscriber:
# -*- coding:utf-8 -*-
#!/user/bin/env.python
#Author:Mr Wu import pika
#建立连接
connection = pika.BlockingConnection(
pika.ConnectionParameters(
host="localhost",
)
)
#建立管道
channel = connection.channel()
#声明转发器
channel.exchange_declare(
exchange="alex",
exchange_type="fanout",
)
#生成一个随机队列
result = channel.queue_declare(exclusive=True) #在此queue的消费者断开后,会自动删除这个queue
#获取生成的queue的名字
queue_name = result.method.queue
channel.queue_bind(
queue=queue_name,
exchange="alex",
) def callback(ch,method,properties,body):
print("receive message: ",body) channel.basic_consume(
callback,
queue=queue_name,
)
print("wait for message from %s"%queue_name)
channel.start_consuming()
有选择的接收消息(exchange_type=direct)
RabbitMq还支持根据关键字发送,即队列绑定关键字,发送者将根据关键字发送消息到exchange,exchange根据关键字判断将数据发送至指定队列。
简单点说:通过routingKey和exchange决定哪个queue可以接收消息
publisher:
# -*- coding:utf-8 -*-
#!/user/bin/env.python
#Author:Mr Wu import pika,random
#建立连接
connection = pika.BlockingConnection(
pika.ConnectionParameters(
host="localhost"
)
)
#声明管道
channel = connection.channel()
#声明转发器
channel.exchange_declare(
exchange="DJ",
exchange_type="direct",
)
key = "" #routingKey
message = input(">>>:")
#生产消息
channel.basic_publish(
exchange="DJ",
routing_key=key,
body=message,
)
print("send message: %s"%message)
connection.close()
subscriber:
# -*- coding:utf-8 -*-
#!/user/bin/env.python
#Author:Mr Wu import pika
#建立连接
connection = pika.BlockingConnection(
pika.ConnectionParameters(
host="localhost",
)
)
#建立管道
channel = connection.channel()
#声明转发器
channel.exchange_declare(
exchange="DJ",
exchange_type="direct",
)
#生成一个随机队列
result = channel.queue_declare(exclusive=True) #在此queue的消费者断开后,会自动删除这个queue
#获取生成的queue的名字
queue_name = result.method.queue
channel.queue_bind(
queue=queue_name,
exchange="DJ",
routing_key=""
) def callback(ch,method,properties,body):
print("receive message: ",body)
print("routingKey: %s"%method.routing_key) channel.basic_consume(
callback,
queue=queue_name,
)
print("wait for message from %s"%queue_name)
channel.start_consuming()
更细致的消息过滤(exchange_type=topic)
所有符合routingKey(此时可以是一个表达式)的routingKey所bind的queue可以接收消息
表达式符号说明:
#:代表一个或多个字符
*:代表任何字符
例如:#.a会匹配a.a ab.a abc.a
*a会匹配a.a b.a c.a
publisher:
# -*- coding:utf-8 -*-
#!/user/bin/env.python
#Author:Mr Wu import pika,sys
#建立连接
connection = pika.BlockingConnection(
pika.ConnectionParameters(
host="localhost"
)
)
#声明管道
channel = connection.channel()
#声明转发器
channel.exchange_declare(
exchange="sss",
exchange_type="topic",
)
key = sys.argv[1] if len(sys.argv) > 1 else "animal.info"
message = " ".join(sys.argv[2:]) or "hello world"
#生产消息
channel.basic_publish(
exchange="sss",
routing_key=key,
body=message,
)
print("send message: %s"%message)
connection.close()
subscriber:
# -*- coding:utf-8 -*-
#!/user/bin/env.python
#Author:Mr Wu import pika,sys
#建立连接
connection = pika.BlockingConnection(
pika.ConnectionParameters(
host="localhost",
)
)
#建立管道
channel = connection.channel()
#声明转发器
channel.exchange_declare(
exchange="sss",
exchange_type="topic",
)
#生成一个随机队列
result = channel.queue_declare(exclusive=True) #在此queue的消费者断开后,会自动删除这个queue
#获取生成的queue的名字
queue_name = result.method.queue
bind_keys = sys.argv[1:]
if not bind_keys:
sys.stderr.write("Usage:%s [binding_key]...\n"%sys.argv[0])
sys.exit(1)
for bind_key in bind_keys:
channel.queue_bind(
exchange="sss",
queue=queue_name,
routing_key=bind_key,
)
def callback(ch,method,properties,body):
print("receive message: ",body)
print("routingKey: %s"%method.routing_key) channel.basic_consume(
callback,
queue=queue_name,
)
print("wait for message from %s"%queue_name)
channel.start_consuming()
headers
通过headers来决定把消息发给那些queue
代码暂定。。。。。。。。。。
远程过程调用:RPC(remote procedure call)
简单来说就是客户端发送命令-----》服务端处理命令,结果-----》客户端
程序逻辑:
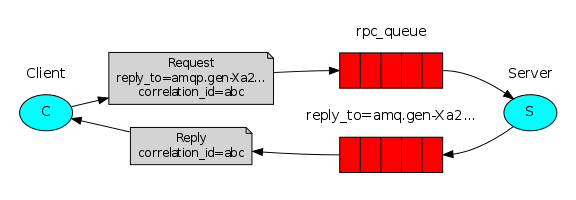
client
# -*- coding:utf-8 -*-
#!/user/bin/env.python
#Author:Mr Wu import pika,time,uuid class RpcClient(object):
def __init__(self):
self.connection = pika.BlockingConnection(
pika.ConnectionParameters(
host="localhost",
)
)
self.channel = self.connection.channel()
self.result = self.channel.queue_declare(exclusive=True)
self.callback_queue = self.result.method.queue
self.channel.basic_consume(
self.on_response,
queue=self.callback_queue,
)
def on_response(self,ch,method,properties,body):
if properties.correlation_id == self.corr_id:
self.response = body.decode() def on_request(self,command):
self.response = None
self.corr_id = str(uuid.uuid4())
self.channel.basic_publish(
exchange="",
routing_key="rpc_queue",
properties=pika.BasicProperties(
reply_to=self.callback_queue,
correlation_id=self.corr_id,
),
body=command,
)
while self.response is None:
self.connection.process_data_events() #相当于非阻塞版的start_consume()
print("waiting for message......")
time.sleep(0.5)
return self.response
obj = RpcClient()
command = input(">>>:")
result = obj.on_request(command)
print(result)
'''
output:
>>>:ipconfig
waiting for message......
waiting for message...... Windows IP 配置 以太网适配器 以太网: 媒体状态 . . . . . . . . . . . . : 媒体已断开连接
连接特定的 DNS 后缀 . . . . . . . : 无线局域网适配器 本地连接* 3: 媒体状态 . . . . . . . . . . . . : 媒体已断开连接
连接特定的 DNS 后缀 . . . . . . . : 无线局域网适配器 本地连接* 12: 媒体状态 . . . . . . . . . . . . : 媒体已断开连接
连接特定的 DNS 后缀 . . . . . . . : 以太网适配器 VMware Network Adapter VMnet1: 连接特定的 DNS 后缀 . . . . . . . :
本地链接 IPv6 地址. . . . . . . . : fe80::7ddd:a3e4:9673:512e%7
IPv4 地址 . . . . . . . . . . . . : 192.168.74.1
子网掩码 . . . . . . . . . . . . : 255.255.255.0
默认网关. . . . . . . . . . . . . : 以太网适配器 VMware Network Adapter VMnet8: 连接特定的 DNS 后缀 . . . . . . . :
本地链接 IPv6 地址. . . . . . . . : fe80::4cc1:5dc2:37f:7e7b%16
IPv4 地址 . . . . . . . . . . . . : 192.168.43.1
子网掩码 . . . . . . . . . . . . : 255.255.255.0
默认网关. . . . . . . . . . . . . : 无线局域网适配器 WLAN: 连接特定的 DNS 后缀 . . . . . . . :
IPv6 地址 . . . . . . . . . . . . : 2001:da8:215:8f01:8d1d:db29:3fd2:c6d6
临时 IPv6 地址. . . . . . . . . . : 2001:da8:215:8f01:1d2a:e364:2e17:ffa3
本地链接 IPv6 地址. . . . . . . . : fe80::8d1d:db29:3fd2:c6d6%10
IPv4 地址 . . . . . . . . . . . . : 10.122.252.64
子网掩码 . . . . . . . . . . . . : 255.255.192.0
默认网关. . . . . . . . . . . . . : fe80::274:9cff:fe7d:fadb%10
10.122.192.1
'''
server
# -*- coding:utf-8 -*-
#!/user/bin/env.python
#Author:Mr Wu import pika,os class RpcServer(object):
def __init__(self):
self.connection = pika.BlockingConnection(
pika.ConnectionParameters(
host="localhost",
)
)
self.channel = self.connection.channel()
self.channel.queue_declare(queue="rpc_queue")
self.channel.basic_consume(
self.on_response,
queue="rpc_queue",
)
def on_request(self,command):
result = os.popen(command).read()
return result
def on_response(self,ch,method,properties,body):
command = body.decode()
return_result = self.on_request(command)
self.channel.basic_publish(
exchange="",
routing_key=properties.reply_to,
properties=pika.BasicProperties(
correlation_id=properties.correlation_id,
),
body=return_result,
)
obj = RpcServer()
obj.channel.start_consuming()
Redis缓存数据库
介绍
Redis是完全开源免费的,遵守BSD协议,是一个高性能的key-value数据库。
Redis与其他key-value缓存产品有以下三个特点:
*Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
*Redis不仅仅支持简单的key-value类型的数据,同时还提供list、set、zset、hash等数据结构的存储。
*Redis支持数据的备份,即master-slave模式的数据备份。
优势
*性能极高,Redis能读的速度是110000次/s,写的速度是81000次/s。
*丰富的数据类型,Redis支持二进制案例的strings,lists,hashes,sets,ordered sets数据类
型操作。
*原子性,Redis的所有操作操作都是原子性的,意思是要么成功执行要么失败完全不执行。单个
操作是原子性的。多个操作也支持事物,即原子性,通过MULTI和EXEC指令包起来。
*丰富的特性,Redis还支持publish/subscribe,通知,key过期等等特性。
Redis与其他的key-value存储有什么不同?
*Redis有着更为复杂的数据结构并且提供对他们的原子性操作,这是一个不同于其他数据库的进
化路径。Redis的数据类型都是基于基本数据结构的同时对程序员透明,无需额外的抽象。
*Redis运行在内存中但是可以持久化到磁盘,所以对不同数据集进行高速读写时需要权衡内存因
为数据量不能大于硬件内存。在内存数据库方面的另一个优点是,相比在磁盘上相同的复杂的数
据结构,在内存中操作起来非常简单,这样Redis可以做很多内部复杂性很强的事情。同时,在
磁盘格式方面他们是紧凑的以追加的方式产生的,因为他们并不需要进行随机访问。
名词注释
什么是 BSD 协议?
BSD开源协议是一个给于使用者很大自由的协议。可以自由的使用,修改源代码,也可以将修改后的代码作为开源或者专有软件再发布。当你发布使用了BSD协议的代码,或者以BSD协议代码为基础做二次开发自己的产品时,需要满足三个条件:
- 如果再发布的产品中包含源代码,则在源代码中必须带有原来代码中的BSD协议。
- 如果再发布的只是二进制类库/软件,则需要在类库/软件的文档和版权声明中包含原来代码中的BSD协议。
- 不可以用开源代码的作者/机构名字和原来产品的名字做市场推广。
BSD代码鼓励代码共享,但需要尊重代码作者的著作权。BSD由于允许使用者修改和重新发布代码,也允许使用或在BSD代码上开发商业软件发布和销 售,因此是对商业集成很友好的协议。
很多的公司企业在选用开源产品的时候都首选BSD协议,因为可以完全控制这些第三方的代码,在必要的时候可以修改或者 二次开发。
什么是原子性,什么是原子性操作?
举个例子:
A想要从自己的帐户中转1000块钱到B的帐户里。那个从A开始转帐,到转帐结束的这一个过程,称之为一个事务。在这个事务里,要做如下操作:
- 1. 从A的帐户中减去1000块钱。如果A的帐户原来有3000块钱,现在就变成2000块钱了。
- 2. 在B的帐户里加1000块钱。如果B的帐户如果原来有2000块钱,现在则变成3000块钱了。
如果在A的帐户已经减去了1000块钱的时候,忽然发生了意外,比如停电什么的,导致转帐事务意外终止了,而此时B的帐户里还没有增加1000块钱。那么,我们称这个操作失败了,要进行回滚。回滚就是回到事务开始之前的状态,也就是回到A的帐户还没减1000块的状态,B的帐户的原来的状态。此时A的帐户仍然有3000块,B的帐户仍然有2000块。
我们把这种要么一起成功(A帐户成功减少1000,同时B帐户成功增加1000),要么一起失败(A帐户回到原来状态,B帐户也回到原来状态)的操作叫原子性操作。
如果把一个事务可看作是一个程序,它要么完整的被执行,要么完全不执行。这种特性就叫原子性。
什么是 key value 存储?
JAVA 中的 map 就是 key=>value 存储的。
键 => 值(key=>value)对,键唯一,对应一个值,值的形式多样。
Redis API的使用连接方式
1.操作模式
redis-py提供了两个类Redis和StrictRedis用于实现Redis的命令,StrictRedis用于实现大部分官方的命令,并使用官方的语法和命令,Redis是StrictRedis的子类,用于向后兼容旧版本的redis-py.
import redis r = redis.Redis()
r.set("alex","pig")
print(r.get("alex"))
2.连接池
redis-py使用connection pool来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。默认,每个Redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis共享一个连接池。
import redis pool = redis.ConnectionPool()
r = redis.Redis(connection_pool=pool)
r.set("alex","pig")
print(r.get("alex"))
String操作
Redis中的String在内存中按照一个name对应一个value来存储。
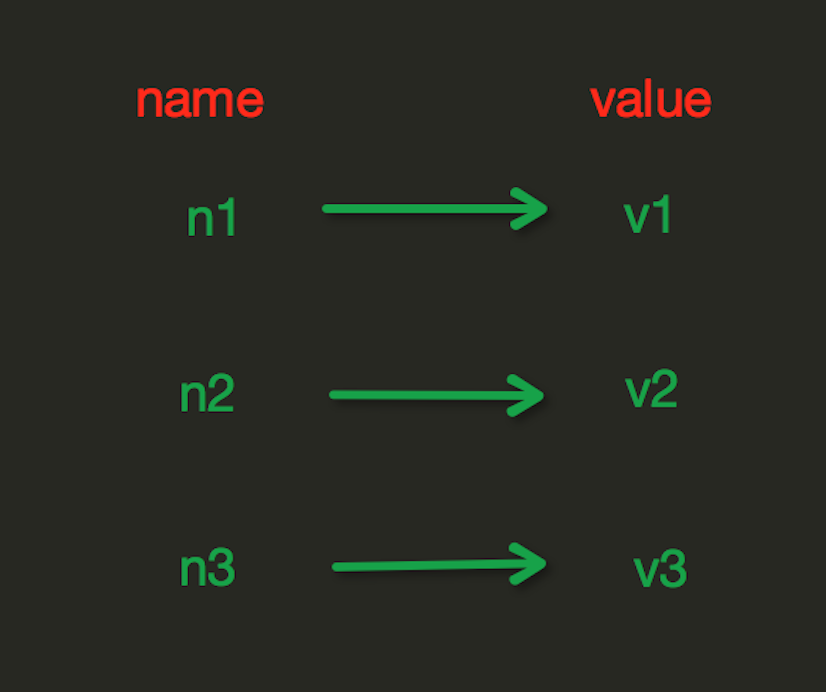
*set(name,value,ex=None,px=None,nx=False,xx=False)
在Redis中设置值,默认不存在则创建,存在则修改
参数:ex:过期时间(秒)
px:过期时间(毫秒)
nx:如果设置为True,则只有name不存在时,当前set操作才执行
xx:如果设置为True,则只有name存在时,当前set操作才执行
*setnx(name,value)
设置值,只有name不存在时,执行设置操作(添加)
*setex(name,time,value)
设置值
参数:time:过期时间(数字秒或timedelta对象)
*psetex(name,time_ms,value)
设置值
参数:time_ms:过期时间(数字毫秒或timedelta对象)
*mset(mapping)
批量设置值
如:r.mset({"k1" : "v1","k2" : "v2"})
或
mset(k1="v1",k2="v2")
*get(name)
获取值
*getset(name,value)
设置新值并获取原来的值
*mget(keys,*args)
批量获取
如:mget("ylr","wupeiqi")
或:
r.mget(["ylr","wupeiqi"])
*getrange(key,start,end)
获取子序列(根据字节获取,非字符)
参数:start:起始位置(字节)
end:结束位置(字节)
如:"吴佩其",0-3表示"吴"
*setrange(name,offset,value)
修改字符串内容,从指定字符串索引开始向后替换(新值太长时,则向后添加)
参数:offset:字符串的索引,字节(一个汉字三字节)
value:要设置的值
*setbit(name,offset,value)
对name对应值的二进制表示的位进行操作
参数:offset:位的索引(将值换成二进制后再进行索引)
value:只能是1 或 0
注:如果在Redis中有一个对应:n1="foo",
那么字符串foo的二进制表示为:01100110 01101111 01101111
所以,如果执行setbit("n1",7,1),则就会将第7位设置为1,
那么最终二进制则变成 01100111 01101111 01101111,即:“goo”
扩展,转换成二进制表示:
source = "foo"
for i in sourse:
num = ord(i)
print(bin(num).replace("b",""))
特别的,如果source是汉子"吴佩其"怎么办?
答:对于utf-8,每一个汉字站3字节,那么"吴佩其"则有9字节
对于汉字,for循环的时候会按照字节迭代,那么在迭代时,将每一个字节转换成十进
制数,然后在讲十进制数转换成二进制
用途举例:用最省空间的方式,存储在线用户数及分别是哪些用户在线。
答:使用setbit()函数即可实现这个功能
*getbit(name,offset)
获取name对应的值的二进制表示的某位的值(0或1)
*bitcount(key,start=None,end=None)
获取name对应的值的二进制表示中1的个数
参数:key:Redis的name
start:位起始位置
end:位结束操作
*strlen(name)
返回name对应值的字节长度(一个汉字三个字节)
*incr(name,amount=1)
自增name对应的值,当name不存在时,则创建name=amount,否则,则自增
参数:amount:自增数(必须是整数)
注:同incrby
*decr(self,name,amount=1)
自减name对应的值,当name不存在时,则创建name=amount,否则,则自减
参数:amount:自减数(整数)
*incrbyfloat(self,name,amount=1.0)
自增name对应的值,当name不存在时,则创建name=amount,否则,则自增
参数:amount:自增数(浮点型)
*append(key,value)
在name对应的值后面追加内容
参数:value:要追加的字符串
Hash操作
hash可以存储一组关联性较强的数据,redis中Hash在内存中的存储格式如下图:
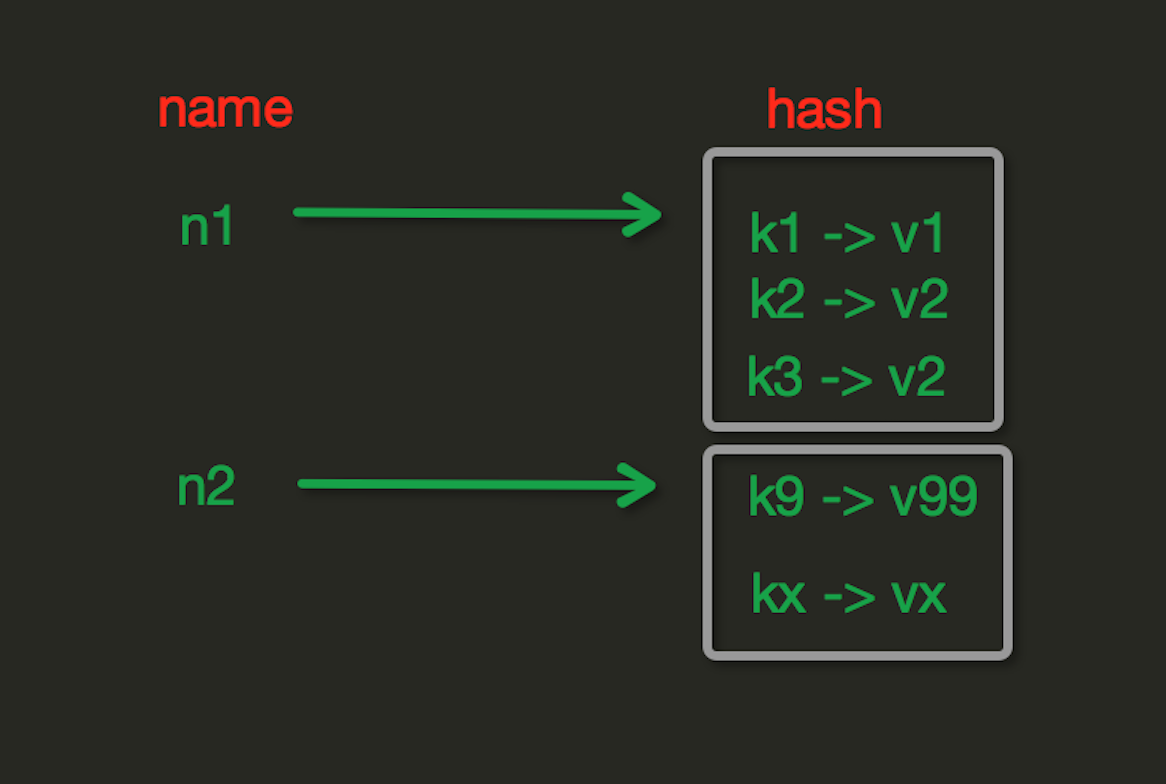
*hset(name,key,value)
name对应的hash中设置一个键值对(不存在则创建,否则 则修改)
参数:name:redis的name
key:name对应的hash中的key
value:name对应hash中的value
注:hsetnx(name,key,value),当name对应的hash中不存在当前key时则创建
*hmset(name,mapping)
在name对应的hash操作中批量设置键值对
参数:mapping:字典
*hget(name,key)
在name对应的hash中根据key获取value
*hmget(name,keys,*args)
在name对应的hash中获取多个key的值
参数:keys:要获取的key集合
*args:要获取的key
*hgetall(name)
获取name对应的hash的所有的键值
*hlen(name)
获取name对应的hash中键值对的个数
*hkeys(name)
获取name对应的hash中所有的key的值
*hvals(name)
获取name对应的hash中所有的value的值
*hexists(name,*keys)
检查name对应的hash是否存在当前传入的key
*hdel(name,*keys)
将name对应的hash中制定key的键值对删除
*hincrby(name,key,amount=1)
自增name对应的hash中的指定key的值,不存在则创建key=amount
参数:amount:自增数(整数)
*hincrybyfloat(name,key,amount=1.0)
自增name对应的hash中的制定的key的值,不存在则创建key=amount
参数:amount:则增数(浮点数)
*hscan(name,coursor=0,match=None,count=None)
Start a full hash scan with:
HSCAN myhash 0
Start a hash scan with fields matching a pattern with:
HSCAN myhash 0 MATCH order_*
Start a hash scan with fields matching a pattern and forcing the scan command to do
more scanning with:
HSCAN myhash 0 MATCH order_* COUNT 1000
增量式迭代获取,对于数据量大的数据非常有用,hscan可以实现分片的获取数据,并非一次性
将数据全部获取完,从而放置内存被撑爆。
参数:coursor:游标(基于游标分批获取数据)
match:匹配指定key,默认None 表示所有的key
count:每次分片最少获取个数,默认None表示采用Redis的默认分片个数
如:第一次:coursor1,data1=r.hscan("xx",coursor=0,match=None,count=None)
第二次:coursor2,data2=r.hscan("xx",cursor=coursor1,match=None,count=None)
............
直到返回值coursor的值为0时,表示数据已经通过分片获取完毕
*hscan_iter(name,match=None,count=None)
利用yield封装hscan创建生成器,实现分批去redis中获取数据
参数:match:匹配指定key,默认为None,表示所有的key
count:每次分片最少获取个数,默认None表示采用Redis的默认分片个数
如:for item in r.hscan_iter("xx")
print(item)
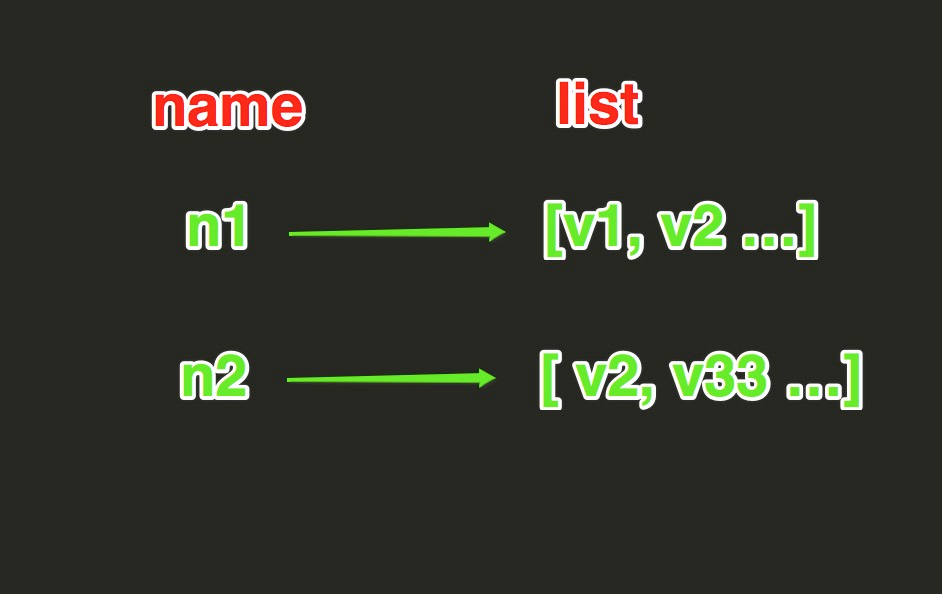
ListList操作,redis中的List在内存中按照一个name 对应一个List来存储。如下:
*lpush(name,values)
在name对应的list中添加元素,每个新的元素都添加到列表的最左边
如:r.lpush("oo",11,22,33)
保存顺序为:33,22,11
扩展:rpush(name,values)表示从右到左操作
*lpushx(name,value)
在name对应的list中添加元素,只有name已经存在时,值添加到最左边
*rpushx(name,value) 表示从右到左操作
*llen(name)
list中元素的个数
*linsert(name,where,refvalue,value)
参数:where:before或after
refvalue:标杆值,即:在它前后插入数据
value:要插入的数据
*r.lset(name,index,value)
对name对应的list中的某一个索引位置重新赋值
参数:index:list的索引位置
value:要设置的值
*r.lrem(name,value,num)
在name对应的list中删除指定的值
参数:value:要删除的值
num:num=0,删除列表中所有的指定值
num=2,从前到后删除两个
num=-2,从后到前删除两个
*lpop(name)
在name对应的列表的左侧获取第一个元素并在列表中移除,返回值则是第一个元素
更多:rpop(name)表示从右向左操作
*lindex(name,index)
在name对应的列表中根据索引获取列表元素
*lrange(name,start,end)
在name对应的列表分片获取数据
参数:start:索引的起始位置
end:索引结束位置
*ltrim(name,start,end)
在name对应的列表中移除在start-end索引之间的值
参数:start:索引起始位置
end:索引结束位置
*rpoplpush(src,dst)
从一个列表取出最右边的元素,同时将其添加另一个列表的最左边
参数:src:要取数据的列表的name
dst:要添加数据的列表的name
*blpop(keys,timeout)
将多个列表排列,按照从左到右去pop对应列表的元素
参数:keys:redis的那么的集合
timeout:超时时间,当所有列表的元素获取完之后,阻塞等待列表内有数据的时间
(秒),0表示永远阻塞
注:r.brpop(keys,timeout)从右到左获取数据
*brpoplpush(src,dst,timeout=0)
*brpoplpush(src,dst,timeout=0)
从一个列表的右侧移除一个元素并将其添加到另一个列表的左侧
参数:src:取出并要移除元素的列表对应的name
dst:要插入元素的列表对应的name
timeout:当src对应的列表中没有数据时,阻塞并等待其有数据的超时时间(秒),0表
示永远阻塞
集合操作Set集合操作,set集合是不允许重复的列表
*sadd(names,values)
name对应的集合中添加元素
*scard(name)
获取name对应的集合中的元素个数
*sdiff(keys,*args)
在第一个name对应的集合中且不在其他name对应的集合的元素集合
*sdiffstore(dest,keys,*args)
获取第一个name对应的集合中且不在不在其他name对应的集合,再将其新加入到dest对应的集
合中
*sinter(keys,*args)
获取多个name对应集合的交集
*sinterstore(dest,keys,*args)
获取多一个name对应集合的交集,再将其加入到dest对应的集合中
*sismember(name,value)
获取name对应的集合的所有成员
*smembers(name)
获取name对应的集合的所有成员
*smove(src,dst,value)
将某个成员从一个集合中移动到另外一个集合
*spop(name)
从集合的右侧移除一个成员,并将其返回
*srandmember(name,numbers)
从name对应的集合中随机获取numbers个元素
*srem(name,values)
从name对应的集合中删除某些值
*sunion(keys,values)
获取多个name对应集合的并集
*sunionstore(dest,keys,*args)
获取多个name对应的集合的并集,并将结果保存到dest对应的集合中
*sscan(name,coursor,match=None,count=None)
*sscan_iter(name,match=None,count=None)
同字符串的操作,用于增量迭代分批获取元素,避免内存消耗太大
Zset有序集合有序集合,在集合的基础上,为每个元素排序;元素的排序需要根据另外一个值来比较,所以,对于有序集合,每一个元素有两个值,即:值和分数,分数专门用来做排序。
*zadd(name,*args,**kwargs)
在name对应的有序集合中添加元素
如:zadd("zz","n1",1,"m=n2",2)或zadd("zz",n1=11,n2=22)
*zcard(name)
获取name对应的有序集合元素的数量
*zcount(name,min,max)
获取name对应的有序集合中分数在[min,max]之间的个数
*zincryby(name,amount,value)
自增name对应的有序集合的name对应的分数
*zrange(name,start,end,desc=False,withscores=False,score_cast_func=float)
按照索引范围获取name对应的有序集合的元素
参数:start:有序集合索引起始位置(非分数)
end:有序集合索引结束位置(非分数)
desc:排序规则,默认按照分数从小到大排序
withscores:是否获取元素的分数,默认只获取元素的值
score_cast_func:对分数进行数据转换的函数
附注:从大到小排序:
zrevrange(name,start,end,withscores=False,score_cast_func=floar)
按照分数从小到大范围获取name对应的有序集合的元素: zrangebyscore(name,min,max,start=None,num=None,withscores=False,score_cast_func=float)
按照分数从大到小排序: zreverangebyscore(name,max,min,start=None,num=None,withscores=False,score_cast_func=float)
*zrem(name,values)
删除name对应的有序集合中值是values的成员
如:zrem("zz",["s1","s2"])
*zremrangebyrank(name,min,max)
根据排行范围删除
*zremrangebyscore(name,min,max)
根据分数范围删除
*zscore(name,value)
获取name对应有序集合中value对应的分数
*zrank(name,value)
获取某个值在name对应的有序集合中的排行(从0开始)
更多:zrevrank(name,value),从大到小排序
*zinterstore(dest,keys,aggregate=None)
获取两个有序集合的交集,如果遇到相同值不同分数,则按照aggregate进行操作
aggregate的值为:SUM、MIN、MAX
*zscan(name,cursor,match=None,count=None,score_func=float)
*zscan_iter(name,match=None,count=None,score_cast_func=float)
同字符串相似,相较于字符串新增score_cast_func,用来对分数进行操作
其他常用操作 *delete(*names)
删除redis中的任意数据类型
*exists(name)
监测redis中的name是否存在
*keys(pattern=*)
根据模型获取redis的name
更多:keys * 匹配数据库中所有的key
keys h?llo 匹配hallo、hello等
keys h*llo 匹配hllo和heeeeello
keys h[ae]llo 匹配hello和hallo,但不匹配hillo
*expire(name,time)
为某个redis中的某个name设置超时时间
*rename(src,dst)
对redis的name重命名为
*move(name,db)
将redis的某个值移动到指定的db下
*randomkey()
随机获取一个redis的name(不删除)
*type(name)
获取name对应值的类型
*scan(cursor=0,match=None,count=None)
*scan_iter(match=None,count=None)
同字符串操作,用于增量迭代获取key
管道技术
redis-py默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作,如果想要在一次请求中指定多个命令,则可以使用popline实现一次请求指定多个命令,并且默认情况下一次pipline是原子性操作。
# -*- coding:utf-8 -*-
#!/user/bin/env.python
#Author:Mr Wu import redis pool = redis.ConnectionPool()
r = redis.Redis(connection_pool=pool)
pipe = r.pipeline(transaction=True)
pipe.set("name","alex")
pipe.set("role","sb")
pipe.execute()
发布订阅(publisher/subscriber)

Helper
# -*- coding:utf-8 -*-
#!/user/bin/env.python
#Author:Mr Wu import redis
class RedisHelper(object):
def __init__(self):
self.__conn = redis.Redis() #redis实例
self.radio_pub = "fm104.105" #发送频道
self.radio_sub = "fm104.105" #接收频道 def publish(self,msg):
self.__conn.publish(self.radio_pub,msg) #msg:发送消息
return True #发送成功 def subscribe(self):
sub = self.__conn.pubsub() #打开收音机
sub.subscribe(self.radio_sub) #调频道
sub.parse_response() #等待消息,阻塞状态
return sub #消息来了,返回收音机
subscriber
from RedisHelper import RedisHelper
r = RedisHelper()
sub = r.subscribe() #收音机
while True:
msg = sub.parse_response() #等待消息
print(msg[2])
pulisher
# -*- coding:utf-8 -*-
#!/user/bin/env.python
#Author:Mr Wu from RedisHelper import RedisHelper r = RedisHelper()
while True:
msg = input("input message>>>:")
if r.publish(msg) is True:
print("\033[1;35m发送消息成功...\033[0m")
else:
print("\033[1;33m发送消息失败...\033[0m")
python第十一周:RabbitMQ、Redis的更多相关文章
- Python之异步IO&RabbitMQ&Redis
协程: 1.单线程运行,无法实现多线程. 2.修改数据时不需要加锁(单线程运行),子程序切换是线程内部的切换,耗时少. 3.一个cpu可支持上万协程,适合高并发处理. 4.无法利用多核资源,因为协程只 ...
- 消息队列介绍、RabbitMQ&Redis的重点介绍与简单应用
消息队列介绍.RabbitMQ&Redis的重点介绍与简单应用 消息队列介绍.RabbitMQ.Redis 一.什么是消息队列 这个概念我们百度Google能查到一大堆文章,所以我就通俗的讲下 ...
- python命令行下安装redis客户端
1. 安装文件: https://pypi.python.org/pypi/setuptools 直接下载然后拷贝到python目录下同下面步骤 下载 ez_setup.py>>> ...
- 第十一周PSP
第十一周PSP 工作周期:11.24-12.1 本周PSP: C类型 C内容 S开始时间 ST结束时间 I中断时间 T净时间(分) 11月29 文档 写随笔 19:00min 19:30min ...
- python课程第二周重点记录
python课程第二周重点记录 1.元组的元素不可被修改,元组的元素的元素可以被修改(字典在元组中,字典的值可以被修改) 2.个人感觉方便做加密解密 3.一些方法的使用 sb = "name ...
- 初学 Python(十一)——切片
初学 Python(十一)--切片 初学 Python,主要整理一些学习到的知识点,这次是切片. #-*- coding:utf-8 -*- ''''' 切片 ''' L = ['name','age ...
- 201521123061 《Java程序设计》第十一周学习总结
201521123061 <Java程序设计>第十一周学习总结 1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结多线程相关内容. 本周学习的是如何解决多线程访问中的互斥 ...
- 201521123072《java程序设计》第十一周学习总结
201521123072<java程序设计>第十一周学习总结 1. 本周学习总结 2. 书面作业 本次PTA作业题集多线程 互斥访问与同步访问 完成题集4-4(互斥访问)与4-5(同步访问 ...
- 201521123038 《Java程序设计》 第十一周学习总结
201521123038 <Java程序设计> 第十一周学习总结 1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结多线程相关内容. 2. 书面作业 本次PTA作业题集多 ...
随机推荐
- Jmeter压测问题_Non HTTP response code: org.apache.http.conn.ConnectTimeoutException
负载机压测,线程500,服务器根本无压力,负载机本身发的请求都是失败的 Sample result如下: Thread Name: 考勤(考勤提交) 1-134 Sample Start: 2018- ...
- [ACM] ZOJ 3819 Average Score (水题)
Average Score Time Limit: 2 Seconds Memory Limit: 65536 KB Bob is a freshman in Marjar Universi ...
- HTML5开发移动web应用——SAP UI5篇(7)
SAPUI5中支持利用Component对组件进行封装.想封装一个组件,Component的基本代码例如以下: sap.ui.define([ "sap/ui/core/UIComponen ...
- T4语法
阅读目录 阅读目录 1.什么是T4? 2.vs插件的安装 3.T4初体验 4.T4语法 其实对于“T4模板”的学习,讲得最详细的还是MSDN,下面给出对应的链接,可以点开深入的了解. 回到顶部 1 ...
- Linux Framebuffer驱动框架之二软件架构(未完待续)【转】
本文转载自:http://blog.csdn.net/gqb_driver/article/details/12918547 /************************************ ...
- C# datagridview 删除行(转 学会、放弃博客)
原文引入:http://zhangyanyansy.blog.163.com/blog/static/13530509720106171252978/ datagridview 删除行 2010-07 ...
- Codeforces--630E--A rectangle(规律)
E - A rectangle Crawling in process... Crawling failed Time Limit:500MS Memory Limit:65536KB ...
- Python开发利器PyCharm 2.7附注册码
PyCharm 2.7 下载 http://download.jetbrains.com/python/pycharm-2.7.2.exe 激活注册 user name:EMBRACE key: 14 ...
- VBA 字符串处理函数集
转自:http://blog.csdn.net/jyh_jack/article/details/2315345 mid(字符串,从第几个开始,长度) 在[字符串]中[从第几个开始]取出[长度个字符 ...
- 动态title
<html><head><meta charset="uft8"><title>测试title</title></ ...