Lasso回归算法: 坐标轴下降法与最小角回归法小结
前面的文章对线性回归做了一个小结,文章在这: 线性回归原理小结。里面对线程回归的正则化也做了一个初步的介绍。提到了线程回归的L2正则化-Ridge回归,以及线程回归的L1正则化-Lasso回归。但是对于Lasso回归的解法没有提及,本文是对该文的补充和扩展。以下都用矩阵法表示,如果对于矩阵分析不熟悉,推荐学习张贤达的《矩阵分析与应用》。
1. 回顾线性回归
首先我们简要回归下线性回归的一般形式:
\(h_\mathbf{\theta}(\mathbf{X}) = \mathbf{X\theta}\)
需要极小化的损失函数是:
\(J(\mathbf\theta) = \frac{1}{2}(\mathbf{X\theta} - \mathbf{Y})^T(\mathbf{X\theta} - \mathbf{Y})\)
如果用梯度下降法求解,则每一轮\(\theta\)迭代的表达式是:
\(\mathbf\theta= \mathbf\theta - \alpha\mathbf{X}^T(\mathbf{X\theta} - \mathbf{Y})\)
其中\(\alpha\)为步长。
如果用最小二乘法,则\(\theta\)的结果是:
\( \mathbf{\theta} = (\mathbf{X^{T}X})^{-1}\mathbf{X^{T}Y} \)
2. 回顾Ridge回归
由于直接套用线性回归可能产生过拟合,我们需要加入正则化项,如果加入的是L2正则化项,就是Ridge回归,有时也翻译为脊回归。它和一般线性回归的区别是在损失函数上增加了一个L2正则化的项,和一个调节线性回归项和正则化项权重的系数\(\alpha\)。损失函数表达式如下:
\(J(\mathbf\theta) = \frac{1}{2}(\mathbf{X\theta} - \mathbf{Y})^T(\mathbf{X\theta} - \mathbf{Y}) + \frac{1}{2}\alpha||\theta||_2^2\)
其中\(\alpha\)为常数系数,需要进行调优。\(||\theta||_2\)为L2范数。
Ridge回归的解法和一般线性回归大同小异。如果采用梯度下降法,则每一轮\(\theta\)迭代的表达式是:
\(\mathbf\theta= \mathbf\theta - (\beta\mathbf{X}^T(\mathbf{X\theta} - \mathbf{Y}) + \alpha\theta)\)
其中\(\beta\)为步长。
如果用最小二乘法,则\(\theta\)的结果是:
\(\mathbf{\theta = (X^TX + \alpha E)^{-1}X^TY}\)
其中E为单位矩阵。
模型变量多的缺点呢?有,这就是下面说的Lasso回归。
3. 初识Lasso回归
Lasso回归有时也叫做线性回归的L1正则化,和Ridge回归的主要区别就是在正则化项,Ridge回归用的是L2正则化,而Lasso回归用的是L1正则化。Lasso回归的损失函数表达式如下:
\(J(\mathbf\theta) = \frac{1}{2n}(\mathbf{X\theta} - \mathbf{Y})^T(\mathbf{X\theta} - \mathbf{Y}) + \alpha||\theta||_1\)
其中n为样本个数,\(\alpha\)为常数系数,需要进行调优。\(||\theta||_1\)为L1范数。
4. 用坐标轴下降法求解Lasso回归
坐标轴下降法顾名思义,是沿着坐标轴的方向去下降,这和梯度下降不同。梯度下降是沿着梯度的负方向下降。不过梯度下降和坐标轴下降的共性就都是迭代法,通过启发式的方式一步步迭代求解函数的最小值。
坐标轴下降法的数学依据主要是这个结论(此处不做证明):一个可微的凸函数\(J(\theta)\), 其中\(\theta\)是nx1的向量,即有n个维度。如果在某一点\(\overline\theta\),使得\(J(\theta)\)在每一个坐标轴\(\overline\theta_i\)(i = 1,2,...n)上都是最小值,那么\(J(\overline\theta_i)\)就是一个全局的最小值。
于是我们的优化目标就是在\(\theta\)的n个坐标轴上(或者说向量的方向上)对损失函数做迭代的下降,当所有的坐标轴上的\(\theta_i\)(i = 1,2,...n)都达到收敛时,我们的损失函数最小,此时的\(\theta\)即为我们要求的结果。
下面我们看看具体的算法过程:
1. 首先,我们把\(\theta\)向量随机取一个初值。记为\(\theta^{(0)}\) ,上面的括号里面的数字代表我们迭代的轮数,当前初始轮数为0.
2. 对于第k轮的迭代。我们从\(\theta_1^{(k)}\)开始,到\(\theta_n^{(k)}\)为止,依次求\(\theta_i^{(k)}\)。\(\theta_i^{(k)}\)的表达式如下:
\( \theta_i^{(k)} \in \underbrace{argmin}_{\theta_i} J(\theta_1^{(k)}, \theta_2^{(k)}, ... \theta_{i-1}^{(k)}, \theta_i, \theta_{i+1}^{(k-1)}, ..., \theta_n^{(k-1)})\)
也就是说\( \theta_i^{(k)} \)是使\(J(\theta_1^{(k)}, \theta_2^{(k)}, ... \theta_{i-1}^{(k)}, \theta_i, \theta_{i+1}^{(k-1)}, ..., \theta_n^{(k-1)})\)最小化时候的\(\theta_i\)的值。此时\(J(\theta)\)只有\( \theta_i^{(k)} \)是变量,其余均为常量,因此最小值容易通过求导求得。
如果上面这个式子不好理解,我们具体一点,在第k轮,\(\theta\)向量的n个维度的迭代式如下:
\( \theta_1^{(k)} \in \underbrace{argmin}_{\theta_1} J(\theta_1, \theta_2^{(k-1)}, ... , \theta_n^{(k-1)})\)
\( \theta_2^{(k)} \in \underbrace{argmin}_{\theta_2} J(\theta_1^{(k)}, \theta_2, \theta_3^{(k-1)}... , \theta_n^{(k-1)})\)
...
\( \theta_n^{(k)} \in \underbrace{argmin}_{\theta_n} J(\theta_1^{(k)}, \theta_2^{(k)}, ... , \theta_{n-1}^{(k)}, \theta_n)\)
3. 检查\(\theta^{(k)}\)向量和\(\theta^{(k-1)}\)向量在各个维度上的变化情况,如果在所有维度上变化都足够小,那么\(\theta^{(k)}\)即为最终结果,否则转入2,继续第k+1轮的迭代。
以上就是坐标轴下降法的求极值过程,可以和梯度下降做一个比较:
5. 用最小角回归法求解Lasso回归
第四节介绍了坐标轴下降法求解Lasso回归的方法,此处再介绍另一种常用方法, 最小角回归法(Least Angle Regression, LARS)。
在介绍最小角回归前,我们先看看两个预备算法,好吧,这个算法真没有那么好讲。
5.1 前向选择(Forward Selection)算法
第一个预备算法是前向选择(Forward Selection)算法。
前向选择算法的原理是是一种典型的贪心算法。要解决的问题是对于:
\(\mathbf{Y = X\theta}\)这样的线性关系,如何求解系数向量\(\mathbf{\theta}\)的问题。其中\(\mathbf{Y}\)为 mx1的向量,\(\mathbf{X}\)为mxn的矩阵,\(\mathbf{\theta}\)为nx1的向量。m为样本数量,n为特征维度。
把 矩阵\(\mathbf{X}\)看做n个mx1的向量\(\mathbf{X_i}\)(i=1,2,...n),在\(\mathbf{Y}\)的\(\mathbf{X}\)变量\(\mathbf{X_i}\)(i =1,2,...m)中,选择和目标\(\mathbf{Y}\)最为接近(余弦距离最小)的一个变量\(\mathbf{X_k}\),用\(\mathbf{X_k}\)来逼近\(\mathbf{Y}\),得到下式:
\(\overline{\mathbf{Y}} = \mathbf{X_k\theta_k}\)
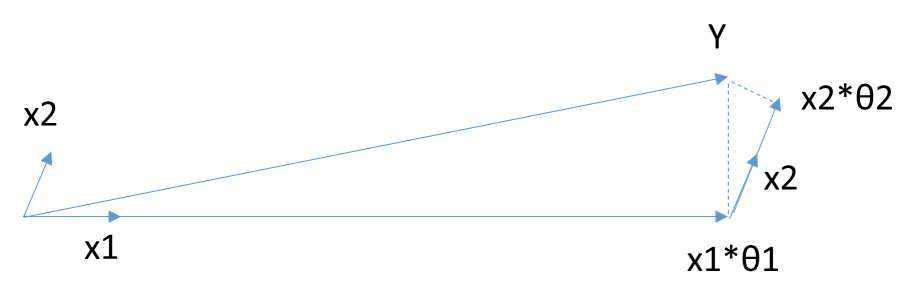
当\(\mathbf{X}\)只有2维时,例子如上图,和\(\mathbf{Y}\)最接近的是\(\mathbf{X_1}\),首先在\(\mathbf{X_1}\)上面投影,残差如上图长虚线。此时\(X_1\theta_1\)模拟了\(\mathbf{Y}\),\(\theta_1\)模拟了\(\mathbf{ \theta}\)(仅仅模拟了一个维度)。接着发现最接近的是\(\mathbf{X_2}\),此时用残差接着在\(\mathbf{X_2}\)投影,残差如图中短虚线。由于没有其他自变量了,此时\(X_1\theta_1+X_2\theta_2\)模拟了\(\mathbf{Y}\),对应的模拟了两个维度的\(\theta\)即为最终结果,此处\(\theta\)计算设计较多矩阵运算,这里不讨论。
5.2 前向梯度(Forward Stagewise)算法
第二个预备算法是前向梯度(Forward Stagewise)算法。
前向梯度算法和前向选择算法有类似的地方,也是在\(\mathbf{Y}\)的\(\mathbf{X}\)变量\(\mathbf{X_i}\)(i =1,2,...n)中,选择和目标\(\mathbf{Y}\)最为接近(余弦距离最小)的一个变量\(\mathbf{X_k}\),用\(\mathbf{X_k}\)来逼近\(\mathbf{Y}\),但是前向梯度算法不是粗暴的用投影,而是每次在最为接近的自变量\(\mathbf{X_t}\)的方向移动一小步,然后再看残差\(\mathbf{Y_{yes}}\)和哪个\(\mathbf{X_i}\)(i =1,2,...n)最为接近。此时我们也不会把\(\mathbf{X_t}\) 去除,因为我们只是前进了一小步,有可能下面最接近的自变量还是\(\mathbf{X_t}\)。如此进行下去,直到残差\(\mathbf{Y_{yes}} \)减小到足够小,算法停止。
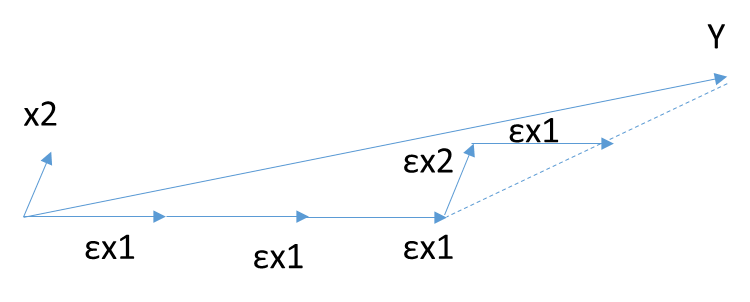
有没有折中的办法可以综合前向梯度算法和前向选择算法的优点,做一个折中呢?有!这就是终于要出场的最小角回归法。
5.3 最小角回归(Least Angle Regression, LARS)算法
好吧,最小角回归(Least Angle Regression, LARS)算法终于出场了。最小角回归法对前向梯度算法和前向选择算法做了折中,保留了前向梯度算法一定程度的精确性,同时简化了前向梯度算法一步步迭代的过程。具体算法是这样的:
首先,还是找到与因变量\(\mathbf{Y}\)最接近或者相关度最高的自变量\(\mathbf{X_k}\),使用类似于前向梯度算法中的残差计算方法,得到新的目标\(\mathbf{Y_{yes}}\),此时不用和前向梯度算法一样小步小步的走。而是直接向前走直到出现一个\(\mathbf{X_t}\),使得\(\mathbf{X_t}\)和\(\mathbf{Y_{yes}}\)的相关度和\(\mathbf{X_k}\)与\(\mathbf{Y_{yes}}\)的相关度是一样的,此时残差\(\mathbf{Y_{yes}}\)就在\(\mathbf{X_t}\)和\(\mathbf{X_k}\)的角平分线方向上,此时我们开始沿着这个残差角平分线走,直到出现第三个特征\(\mathbf{X_p}\)和\(\mathbf{Y_{yes}}\)的相关度足够大的时候,即\(\mathbf{X_p}\)到当前残差\(\mathbf{Y_{yes}}\)的相关度和\(\theta_t\),\(\theta_k\)与\(\mathbf{Y_{yes}}\)的一样。将其也叫入到\(\mathbf{Y}\)的逼近特征集合中,并用\(\mathbf{Y}\)的逼近特征集合的共同角分线,作为新的逼近方向。以此循环,直到\(\mathbf{Y_{yes}}\)足够的小,或者说所有的变量都已经取完了,算法停止。此时对应的系数\(\theta\)即为最终结果。
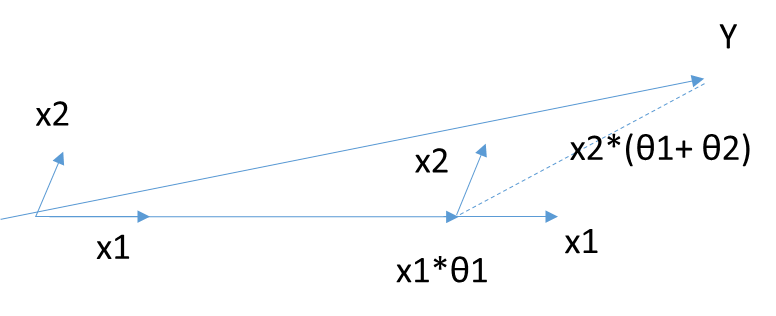
当\(\theta\)只有2维时,例子如上图,和\(\mathbf{Y}\)最接近的是\(\mathbf{X_1}\),首先在\(\mathbf{X_1}\)上面走一段距离,一直到残差在\(\mathbf{X_1}\)和\(\mathbf{X_2}\)的角平分线上,此时沿着角平分线走,直到残差最够小时停止,此时对应的系数\(\beta\)即为最终结果。此处\(\theta\)计算设计较多矩阵运算,这里不讨论。
最小角回归法是一个适用于高维数据的回归算法,其主要的优点有:
1)特别适合于特征维度n 远高于样本数m的情况。
2)算法的最坏计算复杂度和最小二乘法类似,但是其计算速度几乎和前向选择算法一样
3)可以产生分段线性结果的完整路径,这在模型的交叉验证中极为有用
主要的缺点是:
由于LARS的迭代方向是根据目标的残差而定,所以该算法对样本的噪声极为敏感。
6. 总结
Lasso回归是在ridge回归的基础上发展起来的,如果模型的特征非常多,需要压缩,那么Lasso回归是很好的选择。一般的情况下,普通的线性回归模型就够了。
另外,本文对最小角回归法怎么求具体的\(\theta\)参数值没有提及,仅仅涉及了原理,如果对具体的算计推导有兴趣,可以参考Bradley Efron的论文《Least Angle Regression》,网上很容易找到。
(欢迎转载,转载请注明出处。欢迎沟通交流: pinard.liu@ericsson.com)
Lasso回归算法: 坐标轴下降法与最小角回归法小结的更多相关文章
- 机器学习方法:回归(三):最小角回归Least Angle Regression(LARS),forward stagewise selection
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 希望与志同道合的朋友一起交流,我刚刚设立了了一个技术交流QQ群:433250724,欢迎对算法.技术.应用感 ...
- A-06 最小角回归法
目录 最小角回归法 一.举例 二.最小角回归法优缺点 2.1 优点 2.2 缺点 三.小结 更新.更全的<机器学习>的更新网站,更有python.go.数据结构与算法.爬虫.人工智能教学等 ...
- 最小角回归 LARS算法包的用法以及模型参数的选择(R语言 )
Lasso回归模型,是常用线性回归的模型,当模型维度较高时,Lasso算法通过求解稀疏解对模型进行变量选择.Lars算法则提供了一种快速求解该模型的方法.Lars算法的基本原理有许多其他文章可以参考, ...
- 回归算法比较(线性回归,Ridge回归,Lasso回归)
代码: # -*- coding: utf-8 -*- """ Created on Mon Jul 16 09:08:09 2018 @author: zhen &qu ...
- LARS 最小角回归算法简介
最近开始看Elements of Statistical Learning, 今天的内容是线性模型(第三章..这本书东西非常多,不知道何年何月才能读完了),主要是在看变量选择.感觉变量选择这一块领域非 ...
- 从最小角回归(LARS)中学到的一个小知识(很短)
[转载请注明出处]http://www.cnblogs.com/mashiqi (居然有朋友说内容不接地气,那么我就再加一段嘛,请喜欢读笑话的同学直接看第二段)假设这里有一组向量$\left\{ x_ ...
- Lasso回归的坐标下降法推导
目标函数 Lasso相当于带有L1正则化项的线性回归.先看下目标函数:RSS(w)+λ∥w∥1=∑Ni=0(yi−∑Dj=0wjhj(xi))2+λ∑Dj=0∣wj∣RSS(w)+λ∥w∥1=∑i=0 ...
- SparkMLlib学习分类算法之逻辑回归算法
SparkMLlib学习分类算法之逻辑回归算法 (一),逻辑回归算法的概念(参考网址:http://blog.csdn.net/sinat_33761963/article/details/51693 ...
- SparkMLlib分类算法之逻辑回归算法
SparkMLlib分类算法之逻辑回归算法 (一),逻辑回归算法的概念(参考网址:http://blog.csdn.net/sinat_33761963/article/details/5169383 ...
随机推荐
- Django 权限管理
对于Django而言,虽然自带了一些基本的通用权限限制,但现实中,可能我们更希望自己去定义业务权限划分 Django对于权限这块的部分验证方法 user = request.user user.is_ ...
- 39个让你受益的HTML5教程
1. 五分钟入门HTML5 (Learn HTML5 in 5 Minutes!) By Jennifer Marsman 毫无疑问,HTML5是一个热门话题.如果你需要一个迅速了解HTML基础的速成 ...
- STM32之待机唤醒
前段时间我稍微涉及节能减排大赛..倡导节能的社会..没错了.你真是太聪明了..知道了我今天要讲关于STM32节能方面的模块..没错..这标题已经告诉你了是吧..哦,对,标题有写..所以..言归正传.至 ...
- Solve VS2010 Error "Exceptions has been thrown by the target of an invocation"
Sometimes when you open a VS2010 project, an error window will pop up with the error message "E ...
- Javascript中call和apply的区别和用法
JavaScript中有一个call和apply方法,其作用基本相同,但也有略微的区别.其实就是更改对象的内部指针,即改变对象的this指向的内容.这在面向对象的js编程过程中有时是很有用的.call ...
- java 遍历arrayList的四种方法
package com.test; import java.util.ArrayList;import java.util.Iterator;import java.util.List; public ...
- IOS 真机调试
真机调试的步骤: 1.注册成为苹果开发者(99$) 2.登陆苹果开发者主页 https://developer.apple.com/membercenter/index.action 3.点击 Cer ...
- mac显示和隐藏文件
封装了一下显示和隐藏的脚本,方便mac上的文件隐藏和显示 if [ `defaults read com.apple.finder AppleShowAllFiles` = "1" ...
- 开发必备的Windows小技巧
在Windows中我们经常会遇到各种小问题,而这些小问题又确实在影响着工作效率,如果能解决这些小问题,那么就能在一定程度上提高工作效率,保证心情愉悦.今天我就来分享一下几个自认为比较有用的小技巧. 保 ...
- Redis 主从配置和参数详解
安装redis 下载redis wget http://download.redis.io/releases/redis-3.0.7.tar.gz 解压redis tar -xvf redis-.ta ...