基于 ZooKeeper 搭建 Spark 高可用集群
一、集群规划
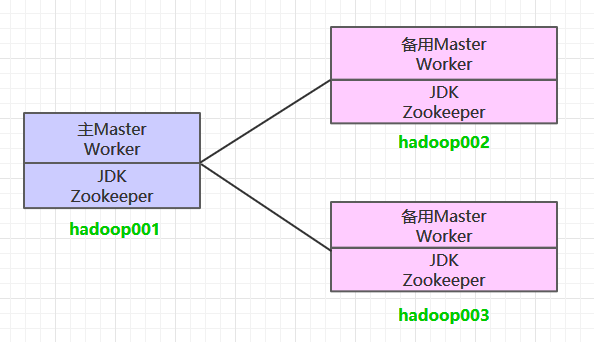
这里搭建一个3节点的Spark集群,其中三台主机上均部署Worker服务。同时为了保证高可用,除了在hadoop001上部署主Master服务外,还在hadoop002和hadoop003上分别部署备用的Master服务,Master服务由Zookeeper集群进行协调管理,如果主Master不可用,则备用Master会成为新的主Master。
二、前置条件
搭建Spark集群前,需要保证JDK环境、Zookeeper集群和Hadoop集群已经搭建,相关步骤可以参阅:
三、Spark集群搭建
3.1 下载解压
下载所需版本的Spark,官网下载地址:http://spark.apache.org/downloads.html
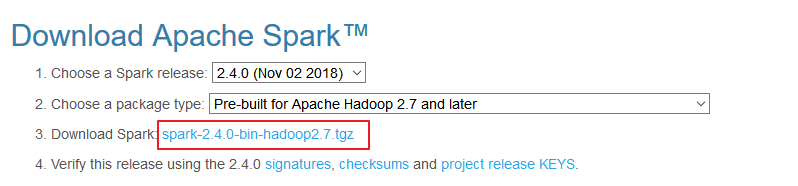
下载后进行解压:
# tar -zxvf spark-2.2.3-bin-hadoop2.6.tgz3.2 配置环境变量
# vim /etc/profile添加环境变量:
export SPARK_HOME=/usr/app/spark-2.2.3-bin-hadoop2.6
export PATH=${SPARK_HOME}/bin:$PATH使得配置的环境变量立即生效:
# source /etc/profile3.3 集群配置
进入${SPARK_HOME}/conf目录,拷贝配置样本进行修改:
1. spark-env.sh
cp spark-env.sh.template spark-env.sh# 配置JDK安装位置
JAVA_HOME=/usr/java/jdk1.8.0_201
# 配置hadoop配置文件的位置
HADOOP_CONF_DIR=/usr/app/hadoop-2.6.0-cdh5.15.2/etc/hadoop
# 配置zookeeper地址
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop001:2181,hadoop002:2181,hadoop003:2181 -Dspark.deploy.zookeeper.dir=/spark"2. slaves
cp slaves.template slaves配置所有Woker节点的位置:
hadoop001
hadoop002
hadoop0033.4 安装包分发
将Spark的安装包分发到其他服务器,分发后建议在这两台服务器上也配置一下Spark的环境变量。
scp -r /usr/app/spark-2.4.0-bin-hadoop2.6/ hadoop002:usr/app/
scp -r /usr/app/spark-2.4.0-bin-hadoop2.6/ hadoop003:usr/app/四、启动集群
4.1 启动ZooKeeper集群
分别到三台服务器上启动ZooKeeper服务:
zkServer.sh start4.2 启动Hadoop集群
# 启动dfs服务
start-dfs.sh
# 启动yarn服务
start-yarn.sh4.3 启动Spark集群
进入hadoop001的${SPARK_HOME}/sbin目录下,执行下面命令启动集群。执行命令后,会在hadoop001上启动Maser服务,会在slaves配置文件中配置的所有节点上启动Worker服务。
start-all.sh分别在hadoop002和hadoop003上执行下面的命令,启动备用的Master服务:
# ${SPARK_HOME}/sbin 下执行
start-master.sh4.4 查看服务
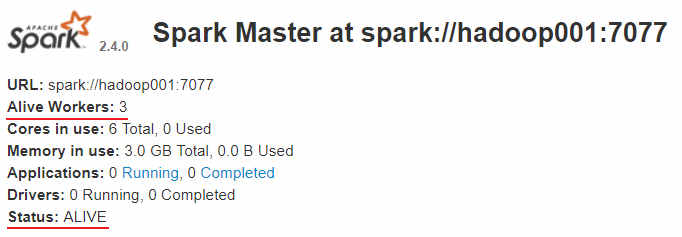
查看Spark的Web-UI页面,端口为8080。此时可以看到hadoop001上的Master节点处于ALIVE状态,并有3个可用的Worker节点。
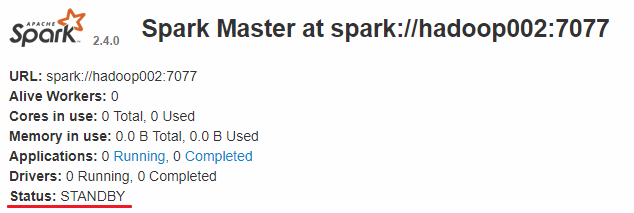
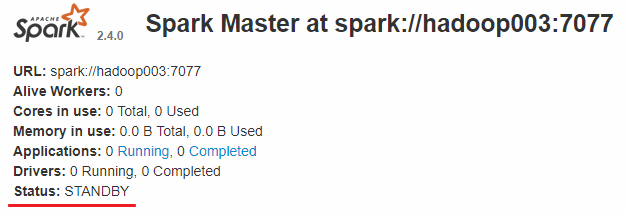
而hadoop002和hadoop003上的Master节点均处于STANDBY状态,没有可用的Worker节点。
五、验证集群高可用
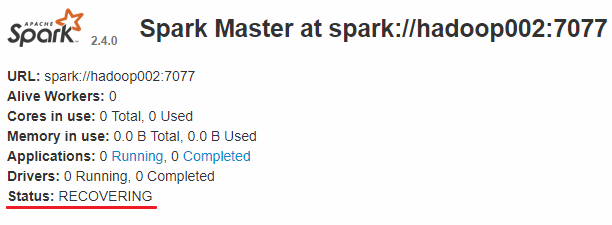
此时可以使用kill命令杀死hadoop001上的Master进程,此时备用Master会中会有一个再次成为主Master,我这里是hadoop002,可以看到hadoop2上的Master经过RECOVERING后成为了新的主Master,并且获得了全部可以用的Workers。
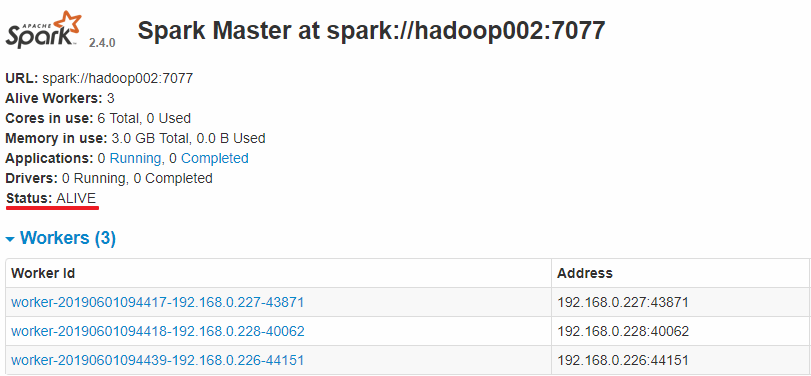
Hadoop002上的Master成为主Master,并获得了全部可以用的Workers。
此时如果你再在hadoop001上使用start-master.sh启动Master服务,那么其会作为备用Master存在。
六、提交作业
和单机环境下的提交到Yarn上的命令完全一致,这里以Spark内置的计算Pi的样例程序为例,提交命令如下:
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
--executor-memory 1G \
--num-executors 10 \
/usr/app/spark-2.4.0-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.4.0.jar \
100更多大数据系列文章可以参见个人 GitHub 开源项目: 大数据入门指南
基于 ZooKeeper 搭建 Spark 高可用集群的更多相关文章
- Spark学习之路(七)—— 基于ZooKeeper搭建Spark高可用集群
一.集群规划 这里搭建一个3节点的Spark集群,其中三台主机上均部署Worker服务.同时为了保证高可用,除了在hadoop001上部署主Master服务外,还在hadoop002和hadoop00 ...
- Spark 系列(七)—— 基于 ZooKeeper 搭建 Spark 高可用集群
一.集群规划 这里搭建一个 3 节点的 Spark 集群,其中三台主机上均部署 Worker 服务.同时为了保证高可用,除了在 hadoop001 上部署主 Master 服务外,还在 hadoop0 ...
- 入门大数据---基于Zookeeper搭建Spark高可用集群
一.集群规划 这里搭建一个 3 节点的 Spark 集群,其中三台主机上均部署 Worker 服务.同时为了保证高可用,除了在 hadoop001 上部署主 Master 服务外,还在 hadoop0 ...
- 基于 ZooKeeper 搭建 Hadoop 高可用集群
一.高可用简介 二.集群规划 三.前置条件 四.集群配置 五.启动集群 六.查看集群 七.集群的二次启动 一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS ...
- Hadoop 学习之路(八)—— 基于ZooKeeper搭建Hadoop高可用集群
一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求 ...
- Hadoop 系列(八)—— 基于 ZooKeeper 搭建 Hadoop 高可用集群
一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求 ...
- Kafka —— 基于 ZooKeeper 搭建 Kafka 高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本Zookeep ...
- Kafka 学习之路(二)—— 基于ZooKeeper搭建Kafka高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本Zookeep ...
- Kafka 系列(二)—— 基于 ZooKeeper 搭建 Kafka 高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper 集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本 Zooke ...
随机推荐
- Android客户端后台发送邮件(JMail)
今天在做项目的时候要处理用户注册问题,里面有个邮箱验证,网上找了一下果然有人做过,但是我拿过来都运行不起来,或者是发送不了邮件.后来我对这个浅浅的研究了一下,贴出来和大家共享. Activity pa ...
- WPF 使用 Edge 浏览器
原文:WPF 使用 Edge 浏览器 版权声明:博客已迁移到 http://lindexi.gitee.io 欢迎访问.如果当前博客图片看不到,请到 http://lindexi.gitee.io 访 ...
- Java并发编程:synchronized和Lock
转自 : http://www.tuicool.com/articles/qYFzUjf
- 微信公众平台消息接口开发(12)消息接口Bug
微信公众平台开发模式 微信公众平台消息接口 微信公众平台API 微信开发模式 Bug 方倍工作室 原文:http://www.cnblogs.com/txw1958/archive/2013/03/1 ...
- HPC —— 高性能计算
CUDA,目前只有 NVIDIA 支持: OpenCL,CUDA Tesla 卡很贵: 1. 术语及概念 SMP:"对称多处理"(Symmetrical Multi-Process ...
- 给WPF示例图形加上方便查看大小的格子之完善版本
原文:给WPF示例图形加上方便查看大小的格子之完善版本 去年10月份, 我曾写过一篇"给WPF示例图形加上方便查看大小的格子"的BLOG(http://blog.csdn.net/ ...
- c语言bit倒置最好的算法-离msb-lsb至lsb-msb
问题 什么是例如最好的算法,下面的转换? 0010 0000 => 0000 0100 从详细的转换MSB->LSB至LSB->MSB, 所有的Bit必须扭转,着.这并非字节顺序的交 ...
- IIS IP地址与端口
IP地址 全部未分配,则以下所有IP对应端口都可以访问网站指定IP,则只有指定IP可以访问网站 1 端口 可以在建立网站之后继续添加端口,则所有添加的端口均可以访问 2 3
- 用MVVM模式开发中遇到的零散问题总结(5)——将动态加载的可视元素保存为图片的控件,Binding刷新的时机
原文:用MVVM模式开发中遇到的零散问题总结(5)--将动态加载的可视元素保存为图片的控件,Binding刷新的时机 在项目开发中经常会遇到这样一种情况,就是需要将用户填写的信息排版到一张表单中,供打 ...
- Python标准库(3.x): itertools库扫盲
itertools functions accumulate() compress() groupby() starmap() chain() count() islice() takewhile() ...