Kaggle之泰坦尼克号幸存预测估计
上次已经讲了怎么下载数据,这次就不说废话了,直接开始。首先导入相应的模块,然后检视一下数据情况。对数据有一个大致的了解之后,开始进行下一步操作。

一、分析数据
1、Survived 的情况
train_data['Survived'].value_counts()

2、Pclass 和 Survived 之间的关系
train_data.groupby('Pclass')['Survived'].mean()

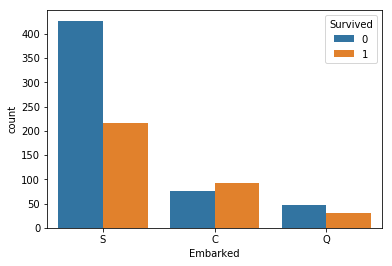
3、Embarked 和 Survived 之间的关系
train_data.groupby('Embarked')['Survived'].value_counts()
sns.countplot('Embarked',hue='Survived',data=train_data)
二、特征处理
先将 label 提取出来,然后将 train 和 test 合并起来一起处理。
y_train = train_data.pop('Survived').astype(str).values
data = pd.concat((train_data, test_data), axis=0)
1、对 numerical 数据进行处理
(1)SibSp/Parch (兄弟姐妹配偶数 / 父母孩子数)
由于这两个属性都和 Survived 没有很大的影响,将这两个属性的值相加,表示为家属个数。
data['FamilyNum'] = data['SibSp'] + data['Parch']
(2)Fare (费用)
它有一个缺失值,需要将其补充。(这里是参考别人的,大神总能发现一些潜在的信息:票价和 Pclass 和 Embarked 有关) 因此,先看一下他们之间的关系以及缺失值的情况。
train_data.groupby(by=["Pclass","Embarked"]).Fare.mean()

缺失值 Pclass = 3, Embarked = S,因此我们将其置为14.644083.
data["Fare"].fillna(14.644083,inplace=True)
还有 Age 的缺失值也需要处理,我是直接将其设置为平均值。
2、对 categorical 数据进行处理
(1)对 Cabin 进行处理
Cabin虽然有很多空值,但他的值的开头都是字母,按我自己的理解应该是对应船舱的位置,所以取首字母。考虑到船舱位置对救生是有一定影响的,虽然有很多缺失值,但还是把它保留下来,而且由于 T 开头的只有一条数据,因此将它设置成数量较小的 G。
data['Cabin'] = data['Cabin'].str[0]
data['Cabin'][data['Cabin']=='T'] = 'G'
(2)对 Ticket 进行处理
将 Ticket 的头部取出来当成新列。
data['Ticket_Letter'] = data['Ticket'].str.split().str[0]
data['Ticket_Letter'] = data['Ticket_Letter'].apply(lambda x:np.nan if x.isnumeric() else x)
data.drop('Ticket',inplace=True,axis=1)
(3)对 Name 进行处理
名字这个东西,虽然它里面的称呼可能包含了一些身份信息,但我还是打算把这一列给删掉...
data.drop('Name',inplace=True,axis=1)
(4)统一将 categorical 数据进行 One-Hot
One-Hot 大致的意思在之前的文章讲过了,这里也不再赘述。
data['Pclass'] = data['Pclass'].astype(str)
data['FamilyNum'] = data['FamilyNum'].astype(str)
dummied_data = pd.get_dummies(data)
(5)数据处理完毕,将训练集和测试集分开
X_train = dummied_data.loc[train_data.index].values
X_test = dummied_data.loc[test_data.index].values
三、构建模型
这里用到了 sklearn.model_selection 的 GridSearchCV,我主要用它来调参以及评定 score。
1、XGBoost
xgbc = XGBClassifier()
params = {'n_estimators': [100,110,120,130,140],
'max_depth':[5,6,7,8,9]}
clf = GridSearchCV(xgbc, params, cv=5, n_jobs=-1)
clf.fit(X_train, y_train)
print(clf.best_params_)
print(clf.best_score_)
{'max_depth': 6, 'n_estimators': 130}
0.835016835016835
2、Random Forest
rf = RandomForestClassifier()
params = {
'n_estimators': [100,110,120,130,140,150],
'max_depth': [5,6,7,8,9,10],
}
clf = GridSearchCV(rf, params, cv=5, n_jobs=-1)
clf.fit(X_train, y_train)
print(clf.best_params_)
print(clf.best_score_)
{'max_depth': 8, 'n_estimators': 110}
0.8294051627384961
四、模型融合
from sklearn.ensemble import VotingClassifier
xgbc = XGBClassifier(n_estimators=130, max_depth=6)
rf = RandomForestClassifier(n_estimators=110, max_depth=8) vc = VotingClassifier(estimators=[('rf', rf),('xgb',xgbc)], voting='hard')
vc.fit(X_train, y_train)
准备就绪,预测并保存模型与结果
y_test = vc.predict(X_test) # 保存模型
from sklearn.externals import joblib
joblib.dump(vc, 'vc.pkl') submit = pd.DataFrame(data= {'PassengerId' : test_data.index, 'Survived': y_test})
submit.to_csv('./input/submit.csv', index=False)
最后提交即可,提交的方式也在上一篇提到过了。Over~ 项目地址:Titanic
Kaggle之泰坦尼克号幸存预测估计的更多相关文章
- Kaggle入门——泰坦尼克号生还者预测
前言 这个是Kaggle比赛中泰坦尼克号生存率的分析.强烈建议在做这个比赛的时候,再看一遍电源<泰坦尼克号>,可能会给你一些启发,比如妇女儿童先上船等.所以是否获救其实并非随机,而是基于一 ...
- 数据挖掘竞赛kaggle初战——泰坦尼克号生还预测
1.题目 这道题目的地址在https://www.kaggle.com/c/titanic,题目要求大致是给出一部分泰坦尼克号乘船人员的信息与最后生还情况,利用这些数据,使用机器学习的算法,来分析预测 ...
- Titanic幸存预测分析(Kaggle)
分享一篇kaggle入门级案例,泰坦尼克号幸存遇难分析. 参考文章: 技术世界,原文链接 http://www.jasongj.com/ml/classification/ 案例分析内容: 通过训练集 ...
- Survival on the Titanic (泰坦尼克号生存预测)
>> Score 最近用随机森林玩了 Kaggle 的泰坦尼克号项目,顺便记录一下. Kaggle - Titanic: Machine Learning from Disaster On ...
- kaggle之泰坦尼克号乘客死亡预测
目录 前言 相关性分析 数据 数据特点 相关性分析 数据预处理 预测模型 Logistic回归训练模型 模型优化 前言 一般接触kaggle的入门题,已知部分乘客的年龄性别船舱等信息,预测其存活情况, ...
- Kaggle竞赛 —— 泰坦尼克号(Titanic)
完整代码见kaggle kernel 或 NbViewer 比赛页面:https://www.kaggle.com/c/titanic Titanic大概是kaggle上最受欢迎的项目了,有7000多 ...
- Kaggle案例泰坦尼克号问题
泰坦里克号预测生还人口问题 泰坦尼克号问题背景 - 就是那个大家都熟悉的『Jack and Rose』的故事,豪华游艇倒了,大家都惊恐逃生,可是救生艇#### 的数量有限,无法人人都有,副船长发话了l ...
- kaggle入门--泰坦尼克号之灾(手把手教你)
作者:炼己者 具体操作请看这里-- https://www.jianshu.com/p/e79a8c41cb1a 大家也可以看PDF版,用jupyter notebook写的,视觉效果上感觉会更棒 链 ...
- 【Kaggle】泰坦尼克号
引言 Kaggle官方网站 这是泰坦尼克号事件的基本介绍: 我们需要做的就是通过给出的数据集,通过对特征值的分析以及运用机器学习模型,分析什么样的人最可能存活,并给出对测试集合的预测. 对于Kaggl ...
随机推荐
- 4 Things I Wish I Would Have Known When I Started My Software Development Career【当我最开始从事软件工程师的时候我希望我知道的四件事】
英文原文:http://simpleprogrammer.com/2013/08/19/software-development-career/ My software development car ...
- servlet-后台获取form表单传的参数
前台代码: <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"> <html> & ...
- Oracle存储过程给变量赋值的方法
截止到目前我发现有三种方法可以在存储过程中给变量进行赋值: 1.直接法 := 如:v_flag := 0; 2.select into 如:假设变量名为v_flag,select count( ...
- react工具库
采用了react框架后,需要找到一些常用的库,常见的需求比如: 1)react生成二维码 2)react的轮播banner图 随着react的社区的壮大,以上的需求都有专门的库帮我们做这个: 1)re ...
- mysql的安装和下载
1.MySQL下载后的文件名为:mysql_installer_community_V5.6.21.1_setup.1418020972.msi,示意图如下: mysql下载地址: 链接:https ...
- RF学习使用记录【4】
四 Extending Robot Framework 4.1 Creating test libraries RF的测试能力由测试库支持决定,已经有许多的测试库,有一些随着RF框架安装,但是更多的需 ...
- code runner运行终端的目录设置
我的github:swarz,欢迎给老弟我++星星 该设置属性为 "code-runner.fileDirectoryAsCwd": true 设置为 true后,终端默认目录为运 ...
- 重装系统后导入raid
参考 https://ubuntuforums.org/showthread.php?t=2002217 https://www.funkypenguin.co.nz/note/importing-e ...
- vue_music:排行榜rank中top-list.vue中样式的实现:class
排行榜的歌曲列表,根据排名渲染不同的样式,同时需要考虑分辨率的2x 3x图 不同的样式--:class 考虑分辨率的2x 3x图--需要在stylu中的mixin中bgImage根据屏幕分辨率选择图片 ...
- 数据持久层(DAO)通用API的实现
在Web开发中,一般都分3层.Controller/Action 控制层,Service/Business 服务层/业务逻辑层,Dao 数据访问层/数据持久层. 在学习和工作的实践过程中,我发现很多功 ...