Flume基本概念
1 Apache Flume
1.1 概述
Flume是Cloudera提供的一个高可用,高可靠的,分布式的海量日志采集、聚合和传输的软件。
Flume的核心是把数据从数据源(source)收集过来,再将收集到的数据送到指定的目的地(sink)。为了保证输送的过程一定成功,在送到目的地(sink)之前,会先缓存数据(channel),待数据真正到达目的地(sink)后,flume再删除自己缓存的数据。
Flume支持定制各类数据发送方,用于收集各类型数据:同时,Flume支持定制各种数据接受放,用于最终存储数据。一般的采集需求,通过对flume的简单配置即可实现。针对特殊场景也具备良好的自定义扩展能力。因此,flume可以适用于大部分的日常数据采集场景。
当前Flume有两个版本。Flume0.9X版本的通常Flume OG(original generation),Flume1.X版本的统称Flume NG(next generation)。由于Flume NG经过核心组件、核心配置以及代码架构重构,与Flume OG有很大不同,使用时请注意区分。改动的另一个原因是将Flume纳入Apache旗下,Cloudera Flume改名为Apache Flume。
1.2 运行机制
Flume日志采集传输系统中核心的角色是agent,agent本身是一个java进程,一般运行在日志收集节点,当然也可以运行在数据下沉的节点。Source、Sink、Channel三个组件是Flume运行的核心。
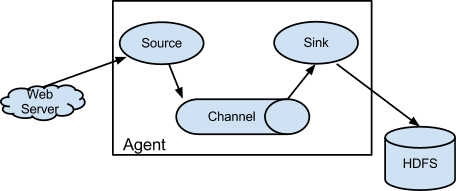
每一个agent相当于一个数据传递员,关于三个组件的介绍:
Source:采集源,用于跟数据源对接,以获取数据;
Sink:下沉地,采集数据的传送目的,用于往下一级agent传递数据或者往最终存储系统传递数据;
Channel:agent内部的数据传输通道,用于从source将数据传递到sink;
在整个数据的传输的过程中,流动的是event,它是Flume内部数据传输的最基本的单元。event将传输的数据进行封装。如果是文本文件,通常是一行记录,event也是事务的基本单位。event从source,流向channel,再到sink,本身为一个字节数组,并可携带headers(头信息)信息。event代表着一个数据的最小完整单元,从外部数据源来,向外部的目的地去。
一个完整的event包括:event headers、event body、event信息,其中event信息就是flume收集到的日记记录。
1.3 Flume采集系统结构图
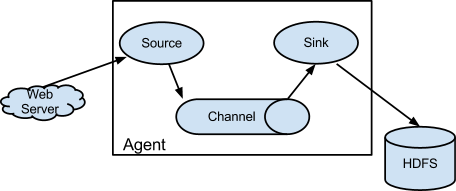
1.3.1 简单结构
单个agent采集数据
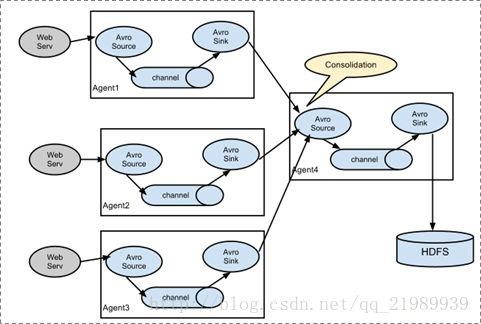
1.3.2 复杂结构
多级agent之间串联。
我们知道Flume一个很重要的功能就是应用于大数据环境中采集日志信息,那么对于分布式系统就需要用到下面这种复杂结构的Flume采集系统。在每一台服务器上都部署一个agent进程进行数据采集,再通过一个agent进程对所有采集到的数据进行汇总,并下沉到数据存储系统。
1.4 官网
documentation-> Flume User Guide页面左边菜单的Configuration下面我们可以看到Flume Sources、Flume Sinks、Flume Channels。这里所列举的数据源、下沉地和传输通道基本上包含了大数据领域常用的软件,能满足大部分的需求,特殊情况下Flume也支持自定义。
由此我们也可以知道,Flume使用起来重点在于采集方案的配置。针对采集需求使用的是什么样的source、sink和channel,把服务配置好并启动起来,就可以进行数据采集、数据的传输和数据的下沉。
Flume基本概念的更多相关文章
- flume基本概念及相关参数详解
1.flume是分布式的日志收集系统,把手机来的数据传送到目的地去 2.flume传输的数据的基本单位是 event,如果是文本文件,通常是一行记录. event代表着一个数据流的最小完整 ...
- 基于Flume+LOG4J+Kafka的日志采集架构方案
本文将会介绍如何使用 Flume.log4j.Kafka进行规范的日志采集. Flume 基本概念 Flume是一个完善.强大的日志采集工具,关于它的配置,在网上有很多现成的例子和资料,这里仅做简单说 ...
- Flume+LOG4J+Kafka
基于Flume+LOG4J+Kafka的日志采集架构方案 本文将会介绍如何使用 Flume.log4j.Kafka进行规范的日志采集. Flume 基本概念 Flume是一个完善.强大的日志采集工具, ...
- 利用Flume将MySQL表数据准实时抽取到HDFS
转自:http://blog.csdn.net/wzy0623/article/details/73650053 一.为什么要用到Flume 在以前搭建HAWQ数据仓库实验环境时,我使用Sqoop抽取 ...
- Flume架构以及应用介绍[转]
在具体介绍本文内容之前,先给大家看一下Hadoop业务的整体开发流程: 从Hadoop的业务开发流程图中可以看出,在大数据的业务处理过程中,对于数据的采集是十分重要的一步,也是不可避免的一步,从而引出 ...
- Flume架构以及应用介绍
在具体介绍本文内容之前,先给大家看一下Hadoop业务的整体开发流程: 从Hadoop的业务开发流程图中可以看出,在大数据的业务处理过程中,对于数据的采集是十分重要的一步,也是不可避免的一步,从而引 ...
- Flume日志收集系统介绍
转自:http://blog.csdn.net/a2011480169/article/details/51544664 在具体介绍本文内容之前,先给大家看一下Hadoop业务的整体开发流程: 从Ha ...
- 吴超老师课程--Flume的安装和介绍
常用的分布式日志收集系统
- flume介绍及应用
版权声明:本文为yunshuxueyuan原创文章.如需转载请标明出处: http://www.cnblogs.com/sxt-zkys/QQ技术交流群:299142667 flume的概念 1. ...
随机推荐
- JAVA Swing 组件演示***
下面是Swing组件的演示: package a_swing; import java.awt.BorderLayout; import java.awt.Color; import java.awt ...
- PCB MS SQL SERVER 字段含小写字母更新为大写字母
今天在预审完成时报如下错误,此错误原因是由于SQL Server数据字段存在小写,而Oracle数据库需大写导致的, 怎么解决这个问题了,非常简单 .这里将SQL贴出来 . 1.将生产型号中含有小写字 ...
- Knights of the Round Table(Tarjan+奇圈)
http://poj.org/problem?id=2942 题意:n个武士,某些武士之间相互仇视,如果在一起容易发生争斗事件.所以他们只有满足一定的条件才能参加圆桌会议:(1)相互仇视的两个武士不能 ...
- 9.9 NOIP模拟题
9.9 NOIP模拟题 T1 两个圆的面积求并 /* 计算圆的面积并 多个圆要用辛普森积分解决 这里只有两个,模拟计算就好 两圆相交时,面积并等于中间两个扇形面积减去两个三角形面积 余弦定理求角度,算 ...
- P3194 [HNOI2008]水平可见直线
传送门 我们把所有的直线按斜率从小到大排序,然后用单调栈维护 发现,如果当前直线与\(st[top-1]\)直线的交点的横坐标大于等于与\(st[top]\)的交点的横坐标,当前直线可以覆盖掉\(st ...
- python值函数名的使用以及闭包,迭代器
一.函数名的运用 函数名就是一个变量名,但它是一个特殊的变量名,是一个后面加括号可以执行函数的变量名. def func(): print("我是一个小小的函数") a = fun ...
- ACM_题目这么难,来局愉快的昆特牌吧
题目这么难,来局愉快的昆特牌吧 Time Limit: 2000/1000ms (Java/Others) Problem Description: 小Z打比赛,然而比赛太难了,他坐在电脑面前被题淹没 ...
- SpringAop--系统日志简例
通过Spring的Aop我们可以声明式的配置事务管理,那么同样可以通过SpringAop来进行处理的系统日志该如何实现呢? 一.数据表和实体类的准备 我们要管理系统日志,那么数据表和实体类是必不可少的 ...
- java DDD 基于maven开发的探讨
对于DDD我目前的理解是 1.除了数据的基本操作,也可以把一些公用的方法或者类迁移到Infrastructrue 2.对于domain层可以声明各个聚合根的操作接口:例:IXXXRepository ...
- Win32基础知识整理
1.定义字符串 在资源新建String table,增加新字符串: (win32加载) TCHAR tcIDName[255]=_T(""); LoadString(hInstan ...