Python-基础-day6
1、二进制
前言:计算机一共就能做两件事:计算和通信
2、字符编码
生活中的数字要想让计算机理解就必须转换成二进制。十进制到二进制的转换只能解决计算机理解数字的问题,那么文字要怎么让计算机理解呢?
于是我们就选择了一种方式,既然数字可以转换成十进制,我们只要想办法吧文字,转换成数字,这样文字不就可以表示成二进制了么?

那么问题来了:怎么把文字转换成数字呢?就是强制转换
我们自己强行约定了一个表,把文字和数字对应上,这张表就相当于翻译,我们可以拿着一个数字来对比对应表找到相应的文字,反之亦然。
ASCII码
我们先来看一张图片,在了解ascii码
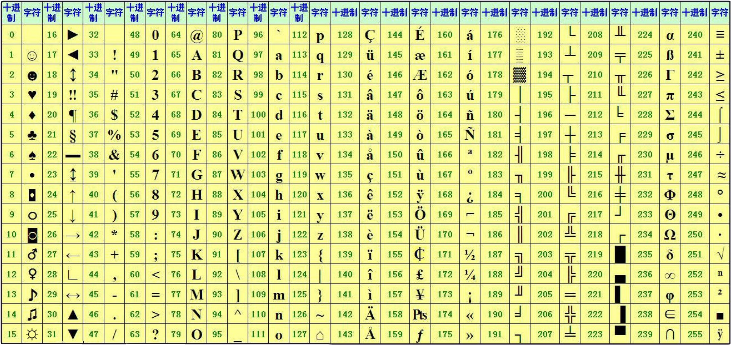
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。它是现今最通用的单字节编码系统,并等同于国际标准ISO/IEC 646。
由于计算机是美国人发明的,因此,最早只有127个字母被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母 A的编码是65,小写字母 z的编码是122。后128个称为扩展ASCII码。
那现在我们就知道了上面的字母符号和数字对应的表是早就存在的。那么根据现在有的一些十进制,我们就可以转换成二进制的编码串。
比如:
| 假如我们要打印两个空格一个对勾 写作二进制就应该是 0011111011但是 但是问题来了,我们怎么知道从哪儿到哪儿是一个字符呢? |
正是由于这些字符串长的长,短的短,写在一起让我们难以分清每一个字符的起止位置,所以聪明的人类就想出了一个解决办法,既然一共就这255个字符,那最长的也不过是11111111八位,不如我们就把所有的二进制都转换成8位的,不足的用0来替换。
这样一来,刚刚的两个空格一个对勾就写作000000000000000011111011,读取的时候只要每次读8个字符就能知道每个字符的二进制值啦。
在这里,每一位0或者1所占的空间单位为bit(比特),这是计算机中最小的表示单位
每8个bit组成一个字符,这是计算机中最小的存储单位(毕竟你是没有办法存储半个字符的)
bit 位,计算机中最小的表示单位
8bit = 1bytes 字节,最小的存储单位,1bytes缩写为1B
1KB=1024B
1MB=1024KB
1GB=1024MB
1TB=1024GB
1PB=1024TB
1EB=1024PB
1ZB=1024EB
1YB=1024ZB
1BB=1024YB
GBK和GB2312
显然,对于我们来说能在计算机中显示中文字符是至关重要的,然而刚学习的ASCII表里连一个偏旁部首也没有。所以我们还需要一张关于中文和数字对应的关系表。之前我们已经看到了,一个字节只能最多表示256个字符,要处理中文显然一个字节是不够的,所以我们需要采用两个字节来表示,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
你可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,
各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
现在,捋一捋ASCII编码和Unicode编码的区别:
ASCII编码是1个字节,而Unicode编码通常是2个字节。
字母A用ASCII编码是十进制的65,二进制的01000001;
字符0用ASCII编码是十进制的48,二进制的00110000;
汉字“中”已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
你可以猜测,如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是00000000 01000001。
问题又出现了:
如果统都编辑成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
| 字符 | ASCII | unicode | UTF-8 |
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 | 11100100 10111000 10101101 |
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
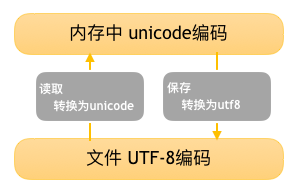
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件。
文件存取编码转换图:
常用编码技术一览表
| 编码 | 制定时间 | 作用 | 所占字节数 |
| ASCII | 1967年 | 表示英语及西欧语言 | 8bit/1bytes |
| GB2312 | 1980年 | 国家简体中文字符集,兼容ASCII | 2bytes |
| Unicode | 1991年 | 国际标准组织统一标准字符集 | 2bytes |
| GBK | 1995年 | GB2312的扩展字符集,支持繁体字,兼容GB2312 | 2bytes |
| UTF-8 | 1992年 | 不定长编码 | 1-3bytes |
Python-基础-day6的更多相关文章
- Python基础Day6
一.代码块 一个模块(模块就是py文件),一个函数,一个类,一个文件都是一个代码块,一个整体是一个代码块. 交互模式的每一行都是一个代码块(交互模式:命令提示符),相当于每行都在不同的文件 二.id ...
- python基础 Day6
python Day6 id 可以获得python的内存地址 id的举例子 a=100 print(id(a)) #140712544153072 这里就是该对象的内存地址 is 判断的是比较内存地址 ...
- Python基础学习总结(持续更新)
https://www.cnblogs.com/jin-xin/articles/7459977.html 嗯,学完一天,白天上班,眼睛要瞎了= = DAY1 1,计算机基础. CPU:相当于人的大脑 ...
- Python基础 小白[7天]入门笔记
笔记来源 Day-1 基础知识(注释.输入.输出.循环.数据类型.随机数) #-*- codeing = utf-8 -*- #@Time : 2020/7/11 11:38 #@Author : H ...
- python之最强王者(2)——python基础语法
背景介绍:由于本人一直做java开发,也是从txt开始写hello,world,使用javac命令编译,一直到使用myeclipse,其中的道理和辛酸都懂(请容许我擦干眼角的泪水),所以对于pytho ...
- Python开发【第二篇】:Python基础知识
Python基础知识 一.初识基本数据类型 类型: int(整型) 在32位机器上,整数的位数为32位,取值范围为-2**31-2**31-1,即-2147483648-2147483647 在64位 ...
- Python小白的发展之路之Python基础(一)
Python基础部分1: 1.Python简介 2.Python 2 or 3,两者的主要区别 3.Python解释器 4.安装Python 5.第一个Python程序 Hello World 6.P ...
- Python之路3【第一篇】Python基础
本节内容 Python简介 Python安装 第一个Python程序 编程语言的分类 Python简介 1.Python的由来 python的创始人为吉多·范罗苏姆(Guido van Rossum) ...
- 进击的Python【第三章】:Python基础(三)
Python基础(三) 本章内容 集合的概念与操作 文件的操作 函数的特点与用法 参数与局部变量 return返回值的概念 递归的基本含义 函数式编程介绍 高阶函数的概念 一.集合的概念与操作 集合( ...
- 进击的Python【第二章】:Python基础(二)
Python基础(二) 本章内容 数据类型 数据运算 列表与元组的基本操作 字典的基本操作 字符编码与转码 模块初探 练习:购物车程序 一.数据类型 Python有五个标准的数据类型: Numbers ...
随机推荐
- Python - Datacamp - Introduction to Matplotlib
Python - Datacamp - Introduction to Matplotlib Datacamp: https://www.datacamp.com/ # 1.py 基本matplotl ...
- 实战:一、使用mongo做一个注册的小demo
思路:1.使用mongoose 进行 数据库的链接 2.使用Schema来进行传输字段的定义 3.安装koa-router进行数据处理4.安装koa-bodyparser 进行post数据交互5.解决 ...
- 1、认识和安装MongoDB
MongoDB简介:MongoDB是一个基于分布式文件存储的数据库,由C++语言编写.目的是为WEB应用提供扩展的高性能的数据存储解决方案.MongoDB是一个介于关系型数据库和非关系型数据库之间的产 ...
- 最大团&稳定婚姻系列
[HDU] 1530 Maximum Clique 1435 Stable Match 3585 maximum shortest distance 二分+最大团 1522 Marriage is ...
- nodejs-app.js
设置静态目录 1 2 app.use(express.static(path.join(__dirname, 'public'))); //设置模版渲染的js,css,images的静态文件目录 设置 ...
- lim的日常生活
- etymology-R
1)vor = to eat devour vt. 狼吞虎咽地吃光: 吞没,毁灭: 目不转睛地看[de-向下+vour-吃] voracity n.贪食,贪婪.拉丁词根vor-,vorac-表示吞食 ...
- POJ 3709
简单的单调队列优化,注意是哪些点加入队列即可. #include <iostream> #include <cstdio> #include <algorithm> ...
- Java 嵌套类和内部类演示样例<三>
<span style="font-family: Arial, Helvetica, sans-serif;"><span style="font-s ...
- 路由器wiff设置
1.将一根网线连接至路由wankou 2.将另外一根网页连接1.2.3.4口中一个,另外一个连接至电脑 3.登录192.168.1.1,进行设置向导选择ppoe,然后登录网络设置无线名称+密码 4.保 ...