hive下UDF函数的使用
1、编写函数
[java] view plaincopyprint?
package com.example.hive.udf;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
public final class LowerCase extends UDF {
public Text evaluate(final Text s) {
if (s == null) { return null; }
return new Text(s.toString().toLowerCase());
}
}
package com.example.hive.udf;
i
import org.apache.hadoop.hive.ql.exec.UDF;
i
import org.apache.hadoop.io.Text;
p
public final class LowerCase extends UDF {
public Text evaluate(final Text s) {
if (s == null) { return null; }
return new Text(s.toString().toLowerCase());
}
}
}
2、用eclipse下的fatjar插件进行打包
先下载net.sf.fjep.fatjar_0.0.31.jar插件包,cp至eclipse/plugins目录下,重启eclipse,右击项目选Export,选择用fatjar导出(可以删掉没用的包,不然导出的jar包很大)
3、将导出的hiveudf.jar复制到hdfs上
hadoop fs -copyFromLocal hiveudf.jar hiveudf.jar
4、进入hive,添加jar,
add jar hdfs://localhost:9000/user/root/hiveudf.jar
5、创建一个临时函数
create temporary function my_lower as 'com.example.hive.udf.LowerCase';
6、调用
select LowerCase(name) from teacher;
注:这种方法只能添加临时的函数,每次重新进入hive的时候都要再执行4-6,要使得这个函数永久生效,要将其注册到hive的函数列表
添加函数文件$HIVE_HOME/src/ql/src/java/org/apache/hadoop/hive/ql/udf/UDFLowerCase.java
修改$HIVE_HOME/src/ql/src/java/org/apache/hadoop/hive/ql/exec/FunctionRegistry.java文件
import org.apache.hadoop.hive.ql.udf.UDFLowerCase;
registerUDF(“LowerCase”, UDFLowerCase.class,false);
(上面这个方法未测试成功)
为了避免每次都有add jar 可以设置hive的'辅助jar路径'
在hive-env.sh中 export HIVE_AUX_JARS_PATH=/home/ckl/workspace/mudf/mudf_fat.jar;
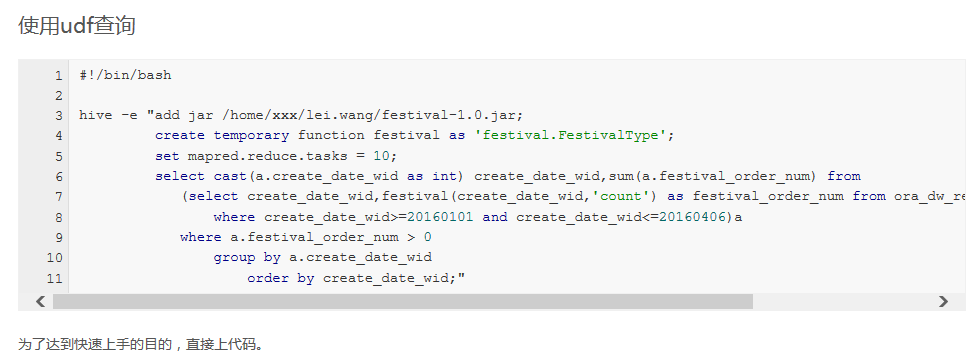
hive下UDF函数的使用的更多相关文章
- 如何编写自定义hive UDF函数
Hive可以允许用户编写自己定义的函数UDF,来在查询中使用.Hive中有3种UDF: UDF:操作单个数据行,产生单个数据行: UDAF:操作多个数据行,产生一个数据行. UDTF:操作一个数据行, ...
- hive UDF函数
虽然Hive提供了很多函数,但是有些还是难以满足我们的需求.因此Hive提供了自定义函数开发 自定义函数包括三种UDF.UADF.UDTF UDF(User-Defined-Function) ...
- hive 中简单的udf函数编写
.注册函数,使用using jar方式在hdfs上引用udf库. $hive.注销函数,只需要删除mysql的hive数据记录即可. delete from func_ru ; delete from ...
- Hadoop生态圈-Hive的自定义函数之UDF(User-Defined-Function)
Hadoop生态圈-Hive的自定义函数之UDF(User-Defined-Function) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- Hive的UDF(用户自定义函数)开发
当 Hive 提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函数(UDF:user-defined function). 测试各种内置函数的快捷方法: 创建一个 dual 表 ...
- Hive扩展功能(三)--使用UDF函数将Hive中的数据插入MySQL中
软件环境: linux系统: CentOS6.7 Hadoop版本: 2.6.5 zookeeper版本: 3.4.8 主机配置: 一共m1, m2, m3这五部机, 每部主机的用户名都为centos ...
- Hive UDF函数构建
1. 概述 UDF函数其实就是一个简单的函数,执行过程就是在Hive转换成MapReduce程序后,执行java方法,类似于像MapReduce执行过程中加入一个插件,方便扩展.UDF只能实现一进一出 ...
- [转] Hive 内置函数
原文见:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF 1.内置运算符1.1关系运算符 运算符 类型 说明 A ...
- hive中UDF、UDAF和UDTF使用
Hive进行UDF开发十分简单,此处所说UDF为Temporary的function,所以需要hive版本在0.4.0以上才可以. 一.背景:Hive是基于Hadoop中的MapReduce,提供HQ ...
随机推荐
- VS代码生成工具ReSharper使用手册:配置快捷键(转)
原文:http://blog.csdn.net/fhzh520/article/details/46364603 VS代码生成工具ReSharper提供了丰富的快捷键,可以极大地提高你的开发效率. 配 ...
- SecureCRT 历史版本下载
最近在使用SecureCRT时,存在网络卡顿现象,然而.同事的SecureCRT工具却一点都不卡,我的SecureCRT是比较老的版本6,同事使用的是版本7,所以就更换下自己的SecureCRT版本. ...
- JS输出26个英文大小写字母
JS中可以利用ASCII值 for(var i=0;i<26;i++){ console.log(String.fromCharCode(65+i));//输出A-Z 26个大写字母 } for ...
- css半透明边框
html <div class="parent"> <div class="translucent">I am Bob</div& ...
- 又趟一个坑,IO卡信号DI和DO的信号类型
工控IO卡可以感应到各种电信号,传感器的状态变化. DI信号包括数字开关信号(ture,false\0,1),光信号的变化(上升沿,下降沿). DO信号包括脉宽和数字开关信号(ture,false\0 ...
- OwinHost.exe用法
简介 OwinHost.exe是微软提供的自宿主host,如果自己不想写owin的host,可以用这个. 官方对OwinHost的描述为:Provides a stand-alone executab ...
- WPF自定义Window样式(1)
1. 引言 WPF是制作界面的一大利器.最近在做一个项目,用的就是WPF.既然使用了WPF了,那么理所当然的,需要自定义窗体样式.所使用的代码是在网上查到的,遗憾的是,整理完毕后,再找那篇帖子却怎么也 ...
- CI_SMOKE配置手册
1.1. SVN安装 安装TortoiseSVN,并检出AutoScript目录至本地 1.2. Java环境安装 确认测试环境安装了JDK,在cmd下键入java -version 检查JDK是 ...
- Android 中adb 命令(实用)
1. 用命令的方式打开关闭mtklog adb shell am broadcast -a com.mediatek.mtklogger.ADB_CMD -e cmd_name start/stop ...
- sprintf的用法
正文:printf 可能是许多程序员在开始学习C 语言时接触到的第二个函数(我猜第一个是main),说起来,自然是老朋友了,可是,你对这个老朋友了解多吗?你对它的那个孪生兄弟sprintf 了解多吗? ...