net.sz.framework 框架 ORM 消消乐超过亿条数据排行榜分析 天王盖地虎
序言
天王盖地虎,
老婆马上生孩子了,在家待产,老婆喜欢玩消消乐类似的休闲游戏,闲置状态,无聊的分析一下消消乐游戏的一些技术问题;
由于我主要是服务器研发,客户端属于半吊子,所以就分析一下消消乐排行榜问题;
第一章
消消乐排行榜大致分为好友排行榜和全国排行榜;
好友排行榜和全国排行榜的其实是重合的只是需要从全国排行榜中提取出来而已;
那么就需要记录所有玩家的通关记录已进行查询;
也许你说全国排行榜只显示前xxx名就好;但是你的好友记录必须要的吧?你的好友不可能全部进入全国排行榜吧;
而好友排行榜基本都是要去全部显示出来排名;
所有那么问题来了:
我们加入400万用户,那么每一关卡都会有400万记录;
目前消消乐关卡开始1200关,那么就是400万 x 1200 = 48亿条数据;这他妈的吓死人啊;
消消乐游戏,最大的技术关键是排行榜查询问题,反而写入速度,和频率却不高;
还有重要的一点是每一关卡的玩家流失率大约:0.xx%;
由于我在家休息中,家里开发环境限制所以设定数据存在是sqlite、mysql数据库,其他数据库有待研究;如果redis 牵涉排序问题,搜索问题,么有想到好的方案;
第二章
我首先设计通关记录存储表结构模型;
需要,玩家id,通关关卡,通关星级,通关积分,通关时间
class TopList extends DataBaseModel implements Serializable, Cloneable {
/*玩家id*/
private long pid;
/*关卡*/
private int point;
/*星级*/
private int star;
/*通关时间*/
private long time;
/*积分*/
private int integral;
public long getPid() {
return pid;
}
public void setPid(long pid) {
this.pid = pid;
}
public int getPoint() {
return point;
}
public void setPoint(int point) {
this.point = point;
}
public int getStar() {
return star;
}
public void setStar(int star) {
this.star = star;
}
public long getTime() {
return time;
}
public void setTime(long time) {
this.time = time;
}
public int getIntegral() {
return integral;
}
public void setIntegral(int integral) {
this.integral = integral;
}
@Override
public Object clone() {
try {
return super.clone(); //To change body of generated methods, choose Tools | Templates.
} catch (CloneNotSupportedException ex) {
}
return null;
}
}
测试代码
public static void main(String[] args) throws Exception {
SqliteDaoImpl sdi = new SqliteDaoImpl("/home/toplist.db");
TopList topList = new TopList();
CUDThread cudt = new CUDThread(sdi, "top-list-thread");
/*设置异步操作的缓冲容量*/
cudt.setMaxTaskCount(500000);
/*设置单次写入的数据量*/
cudt.setGetTaskMax(5000);
/*创建表*/
sdi.createTable(topList);
/*id生成器*/
LongId0 longId0 = new LongId0();
/*模拟5万个玩家*/
for (int i = 0; i < 50000; i++) {
long id = longId0.getId();
/*模拟500关卡*/
for (int j = 1; j <= 500; j++) {
TopList clone = (TopList) topList.clone();
clone.setPid(id);
clone.setTime(System.currentTimeMillis());
clone.setPoint(j);
clone.setStar(3);
/*随机积分*/
clone.setIntegral(RandomUtils.random(20000, 400000));
cudt.insert_Sync(clone);
}
}
}
sqlite插入速度非常快,
[07-25 11:28:20:368:DEBUG:CUDThread.run():219] 新增数据插入影响行数:5000 耗时:115 [07-25 11:28:20:368:DEBUG:CUDThread.run():246] 当前待处理剩余数量:7257 [07-25 11:28:20:524:DEBUG:CUDThread.run():219] 新增数据插入影响行数:5000 耗时:155 [07-25 11:28:20:524:DEBUG:CUDThread.run():246] 当前待处理剩余数量:8342 [07-25 11:28:20:696:DEBUG:CUDThread.run():219] 新增数据插入影响行数:5000 耗时:172 [07-25 11:28:20:696:DEBUG:CUDThread.run():246] 当前待处理剩余数量:9129 [07-25 11:28:20:818:DEBUG:CUDThread.run():219] 新增数据插入影响行数:5000 耗时:122 [07-25 11:28:20:818:DEBUG:CUDThread.run():246] 当前待处理剩余数量:8188 [07-25 11:28:20:973:DEBUG:CUDThread.run():219] 新增数据插入影响行数:5000 耗时:154 [07-25 11:28:20:973:DEBUG:CUDThread.run():246] 当前待处理剩余数量:8424
我们查询一下数据库;
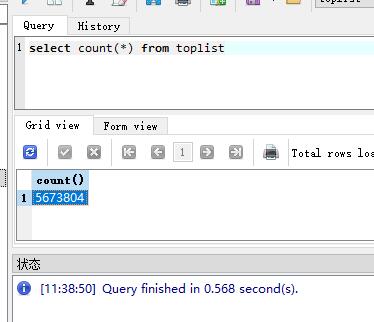
总数据是560多万行数据;
查询一下关卡数据
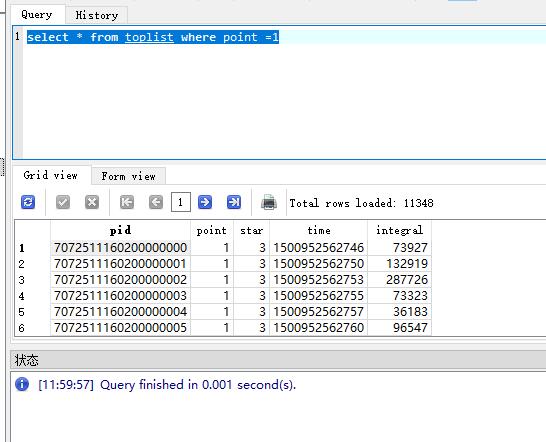
查询关卡数据很快;
但是我需要排序
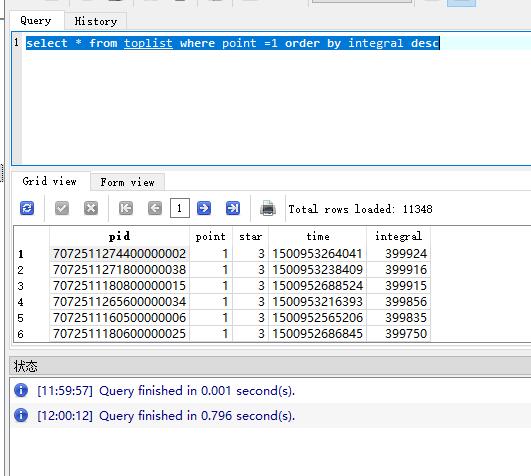
这些就看出对比了吧,这仅仅只有不到600万条数据呢;而且我们仅仅是查询了全国总排行,还么有牵涉好友排行榜,多条件搜索;
第三章
数据库可以增加索引的,加入索引后,查询会快很多;
那么接下来我们修改模型,测试
class TopList extends DataBaseModel implements Serializable, Cloneable {
/*玩家id*/
@AttColumn(index = true)
private long pid;
/*关卡*/
@AttColumn(index = true)
private int point;
/*积分*/
@AttColumn(index = true)
private int integral;
/*星级*/
private int star;
/*通关时间*/
private long time;
public long getPid() {
return pid;
}
public void setPid(long pid) {
this.pid = pid;
}
public int getPoint() {
return point;
}
public void setPoint(int point) {
this.point = point;
}
public int getStar() {
return star;
}
public void setStar(int star) {
this.star = star;
}
public long getTime() {
return time;
}
public void setTime(long time) {
this.time = time;
}
public int getIntegral() {
return integral;
}
public void setIntegral(int integral) {
this.integral = integral;
}
@Override
public Object clone() {
try {
return super.clone(); //To change body of generated methods, choose Tools | Templates.
} catch (CloneNotSupportedException ex) {
}
return null;
}
}
修改模型,在玩家id,分数,关卡,这三个地方加入索引;
[07-25 13:11:04:759:DEBUG:CUDThread.run():219] 新增数据插入影响行数:5000 耗时:662 [07-25 13:11:04:760:DEBUG:CUDThread.run():246] 当前待处理剩余数量:22525 [07-25 13:11:05:549:DEBUG:CUDThread.run():219] 新增数据插入影响行数:5000 耗时:787 [07-25 13:11:05:550:DEBUG:CUDThread.run():246] 当前待处理剩余数量:24975 [07-25 13:11:06:437:DEBUG:CUDThread.run():219] 新增数据插入影响行数:5000 耗时:885 [07-25 13:11:06:438:DEBUG:CUDThread.run():246] 当前待处理剩余数量:27030 [07-25 13:11:07:198:DEBUG:CUDThread.run():219] 新增数据插入影响行数:5000 耗时:759 [07-25 13:11:07:199:DEBUG:CUDThread.run():246] 当前待处理剩余数量:27454 [07-25 13:11:08:023:DEBUG:CUDThread.run():219] 新增数据插入影响行数:5000 耗时:823 [07-25 13:11:08:027:DEBUG:CUDThread.run():246] 当前待处理剩余数量:27449 [07-25 13:11:08:966:DEBUG:CUDThread.run():219] 新增数据插入影响行数:5000 耗时:936 [07-25 13:11:08:967:DEBUG:CUDThread.run():246] 当前待处理剩余数量:27900 [07-25 13:11:09:945:DEBUG:CUDThread.run():219] 新增数据插入影响行数:5000 耗时:977
数据库数据越来越多的时候,插入速度就会越来越慢;看下图,是不是很吓人?
[07-25 13:15:06:511:DEBUG:CUDThread.run():246] 当前待处理剩余数量:23473 [07-25 13:15:10:948:DEBUG:CUDThread.run():219] 新增数据插入影响行数:5000 耗时:4434 [07-25 13:15:10:950:DEBUG:CUDThread.run():246] 当前待处理剩余数量:42028 [07-25 13:15:14:666:DEBUG:CUDThread.run():219] 新增数据插入影响行数:5000 耗时:3715 [07-25 13:15:14:668:DEBUG:CUDThread.run():246] 当前待处理剩余数量:49338
也许与我当前笔记本硬盘有关系;电脑性能占用问题;

插入速度是慢了,我们来看看查询速度吧,
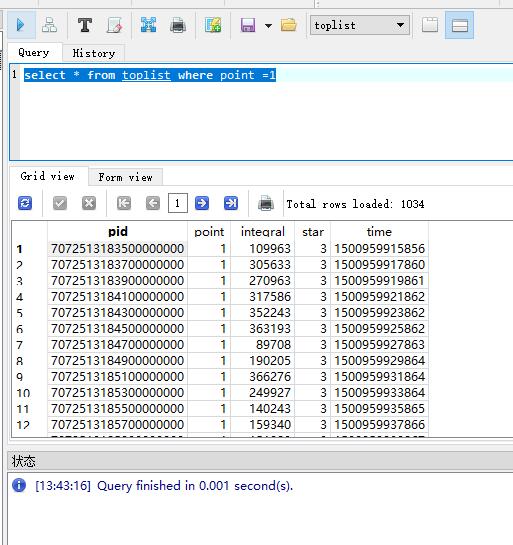
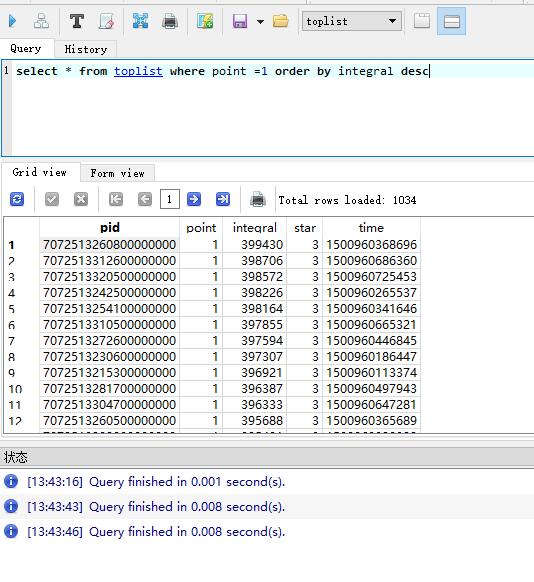
我们可以看到插入速度快很多;
当然此时的数据量确实么有之前的多,因为测试问题,插入的数据的确实很慢,
如果是mysql 数据库,还需要加入联合索引查询才会翻倍提升性能;mysql插入速度会比sqlite好一点,因为sqlie本身就不适用于大型数据集合;
第四章
其实以上工作只是做到了索引优化问题;但是也抵不住越来越多的数据;对不对?
所以还是的寻求其他方式来解决问题;
我们先来分析情况
可以建立分区表形式;但是建立分区表,数据也只是在一个表内大hash集合,然后区分的小hash集合,然后就算mysql这种官方建议的分区表都是200万条数据;
所以没有尝试过;有兴趣的同学可以研究研究;
我想到的第二种方式,分表,之前在做游戏运营后台,接受来之多个游戏的运营日志数据,就采用了这种方式,分表,每一天一张表,来划分;
所以我很快又想到了这种方式,我以每一个关卡划分通关数据记录,
可是仔细一想肯定不行啊,因为按照现在消消乐这种游戏来说1200关,1000多张表,维护都得忙死;而且越往后越更新越多,依然不可行!
任何游戏只要在生存周期内,就有有人加入,有人流失;
那么消消乐这种关卡类的游戏,那么数据量永远都在前面关卡,越往后越少,就跟我前面说的一样,每一关卡都会流失0.xxx%;
那么我们可以设计30张表,30张总能接受了吧?
起码我是能接受了;
可是如何优雅的利用30张表数据的呢?
我们分析可得越靠前的关卡,数据越多,
那么我们设计前800关卡的数据存入20张表;
后面的所以表记录到剩余的10张表中;
创建表,获取表名的简易算法;
/**
* 获取表名
*
* @param point
* @return
*/
static String getTableName(int point) {
int tableId = 0;
if (point < 300) {
/*第一段前300关存入15张表*/
tableId = 1000 + point % 15;
} else if (point < 800) {
/*第二段后500关卡存入5张表*/
tableId = 2000 + point % 5;
} else {
/*800关卡以后的数据存入剩余10张表*/
tableId = 3000 + point % 10;
}
return TopList.class.getSimpleName().toLowerCase() + tableId;
}
创建表
int points = 1200;
TopList topList = new TopList();
for (int i = 1; i <= points; i++) {
topList.setDataTableName(getTableName(i));
/*创建表*/
sdi.createTable(topList);
}
表自动创建完成;
/*模拟5万个玩家*/
for (int i = 1; i <= 50000; i++) {
long id = longId0.getId();
/*模拟关卡*/
int j = 1;
for (; j <= points; j++) {
TopList clone = (TopList) topList.clone();
clone.setDataTableName(getTableName(j));
clone.setPid(id);
clone.setTime(System.currentTimeMillis());
clone.setPoint(j);
clone.setStar(3);
/*随机积分*/
clone.setIntegral(RandomUtils.random(20000, 400000));
cudt.insert_Sync(clone);
}
log.info("总共写入数据量:" + (i * (j - 1)));
Thread.sleep(1000);
}
写入速度,已经得到提升了,
[07-25 14:24:12:293:DEBUG:CUDThread.run():219] 新增数据插入影响行数:3000 耗时:2750 [07-25 14:24:12:294:DEBUG:CUDThread.run():246] 当前待处理剩余数量:3600 [07-25 14:24:12:605:INFO :TopTest.main():68] 总共写入数据量:222185 [07-25 14:24:13:619:INFO :TopTest.main():68] 总共写入数据量:223386 [07-25 14:24:14:647:INFO :TopTest.main():68] 总共写入数据量:224587 [07-25 14:24:14:757:DEBUG:CUDThread.run():219] 新增数据插入影响行数:3000 耗时:2463 [07-25 14:24:14:758:DEBUG:CUDThread.run():246] 当前待处理剩余数量:4200 [07-25 14:24:15:690:INFO :TopTest.main():68] 总共写入数据量:225788 [07-25 14:24:16:709:INFO :TopTest.main():68] 总共写入数据量:226989 [07-25 14:24:17:502:DEBUG:CUDThread.run():219] 新增数据插入影响行数:3000 耗时:2744 [07-25 14:24:17:502:DEBUG:CUDThread.run():246] 当前待处理剩余数量:3600 [07-25 14:24:17:743:INFO :TopTest.main():68] 总共写入数据量:228190 [07-25 14:24:18:755:INFO :TopTest.main():68] 总共写入数据量:229391 [07-25 14:24:19:783:INFO :TopTest.main():68] 总共写入数据量:230592 [07-25 14:24:20:250:DEBUG:CUDThread.run():219] 新增数据插入影响行数:3000 耗时:2748 [07-25 14:24:20:250:DEBUG:CUDThread.run():246] 当前待处理剩余数量:4200 [07-25 14:24:20:824:INFO :TopTest.main():68] 总共写入数据量:231793 [07-25 14:24:21:843:INFO :TopTest.main():68] 总共写入数据量:232994
查询速度在第三章已经验证了,就不在验证;
总结
像消消乐这类型游戏重点就在于排行榜数据存储和读取,然后写入和读取相比,写入的需求远远小于读取的需求;
我做的是实时数据排行榜区分;
当然我们还可以利用mysql的主从关系,提供读写分离情况,做非实时排行榜数据;
也可以利用非滑动缓存来做非实时排行榜,解决写入和读取的性能平衡问题,缓存可以设置比如每5分钟或者每10分钟更新一次排行榜数据来完成;
以上分析就不再做代码测试;
这是我分析和我的解决方案,不知道屌大的园友们还要更好的解决方案吗?



net.sz.framework 框架 ORM 消消乐超过亿条数据排行榜分析 天王盖地虎的更多相关文章
- net.sz.framework 框架 轻松搭建数据服务中心----读写分离数据一致性,滑动缓存
前言 前文讲述了net.sz.framework 框架的基础实现功能,本文主讲 net.sz.framework.db 和 net.sz.framework.szthread; net.sz.fram ...
- net.sz.framework 框架 轻松搭建服务---让你更专注逻辑功能---初探
前言 在之前的文章中,讲解过 threadmodel,socket tcp ,socket http,log,astart ,scripts: 都是分片讲解,从今天开始,将带大家,一窥 net.sz. ...
- net.sz.framework 框架 登录服务器架构 单服2 万 TPS(QPS)
前言 无论我们做什么系统,95%的系统都离不开注册,登录: 而游戏更加关键,频繁登录,并发登录,导量登录:如果登录承载不起来,那么游戏做的再好,都是徒然,进不去啊: 序言 登录所需要的承载,包含程序和 ...
- Android多媒体框架总结(1) - 利用MediaMuxer合成音视频数据流程分析
场景介绍: 设备端通过服务器传向客户端(Android手机)实时发送视频数据(H.264)和音频数据(g711a或g711u), 需要在客户端将音视频数据保存为MP4文件存放在本地,用户可以通过APP ...
- orm 查询数据库随机返回一条数据的解决办法用models.User.objests.all().order_by('?').first()
- Git.Framework 框架随手记--ORM条件组合
在上一篇<Git.Framework 框架随手记--ORM新增操作>中简单记录了如何对数据进行删除和修改,其用法都非常简单,在文章中提到了Where()方法,本文将详述Where() 等条 ...
- Git.Framework 框架随手记--ORM编辑删除
前面一篇文章<Git.Framework 框架随手记--ORM新增操作>主要讲解了如何使用Git.Framework往数据库中添加数据.其操作过程相对简单,本章主要记录如何编辑数据和修改数 ...
- Git.Framework 框架随手记--ORM新增操作
本篇主要记录具体如何新增数据,废话不多说,开始进入正文. 一. 生成工程结构 上一篇已经说到了如何生成工程结构,这里在累述一次. 1. 新建项目总体结构 使用VS新建项目结构,分层结构可以随意.我们使 ...
- Git.Framework 框架随手记--ORM项目工程
前面已经简单介绍过了该框架(不一定是框架),本文开始重点记录其使用过程.可能记录的内容不是太详尽,框架也可能非常烂,但是里面的代码句句是实战项目所得.本文非教唆之类的文章,也非批判之类的文章,更不是炫 ...
随机推荐
- 最基础的mybatis入门demo
demo结构 数据库情况 (不会转sql语句 骚瑞) 数据库连接信息 jdbc.properties jdbc.driver=com.mysql.jdbc.Driver jdbc.url=jdbc:m ...
- 基于redis实现tomcat8及以上版本的tomcat集群的session持久化实现(tomcat-redis-session-manager二次开发)
前言: 本项目是基于jcoleman的tomcat-redis-session-manager二次开发版本 1.修改了小部分实现逻辑 2.去除对juni.jar包的依赖 3.去除无效代码和老版本tom ...
- ap.net core 教程(三) - 新建项目
ASP.NET Core - 新建项目 在这一章,我们将讨论如何在Visual Studio中创建一个新项目. 只要你安装了Visual Studio 2015的.net core工具,您就可以开始构 ...
- react 基础
一.组件 函数式定义的无状态组件 es5原生方式React.createClass定义的组件 es6形式的extends React.Component定义的组件 React.Component是以E ...
- 使用hashCode()和equals()方法 - Java
在这篇文章中,我将指出我对hashCode()和equals()方法的理解.我将讨论它们的默认实现以及如何正确地覆盖它们.我还将使用Apache Commons包中的实用工具类来实现这些方法. has ...
- Bash中的数学计算
一.整数计算 1.整数 $delare -i num$num=5+5$echo $num10 $num="5 + 8"$echo $num13注意:算式中如果有空格,需要用引号引起 ...
- mysql基于binlog回滚工具_flashback(python版本)
update.delete的条件写错甚至没有写,导致数据操作错误,需要恢复被误操作的行记录.这种情形,其实时有发生,可以选择用备份文件+binlog来恢复到测试环境,然后再做数据修复,但是这样 ...
- [编织消息框架][netty源码分析]6 ChannelPipeline 实现类DefaultChannelPipeline职责与实现
ChannelPipeline 负责channel数据进出处理,如数据编解码等.采用拦截思想设计,经过A handler处理后接着交给next handler ChannelPipeline 并不是直 ...
- 移动端APP CSS Reset及注意事项CSS重置
@charset "utf-8"; * { -webkit-box-sizing: border-box; box-sizing: border-box; } //禁止文本缩放 h ...
- memcache常用命令
一.memcached的基本命令(安装.卸载.启动.配置相关): -p 监听的端口 -l 连接的IP地址, 默认是本机 -d start 启动memcached服务 -d restart 重起m ...