跟我一起读postgresql源码(七)——Executor(查询执行模块之——数据定义语句的执行)
1.数据定义语句的执行
数据定义语句(也就是之前我提到的非可优化语句)是一类用于定义数据模式、函数等的功能性语句。不同于元组增删査改的操作,其处理方式是为每一种类型的描述语句调用相应的处理函数。
数据定义语句的执行流程最终会进入到ProcessUtility处理器,然后执行语句对应的不同处理过程。由于数据定义语句的种类很多,因此整个处理过程中的数据结构和方式种类繁冗、复杂,但流程相对简单、固定。这里我们以Create table为例说明数据定义语句的具体处理过程。
1.1数据定义语句执行流程
由于ProcessUtility需要处理所有类型的数据定义语句,因此ProcessUtility通过判断数据结构中NodeTag字段的值来区分各种不同节点,并引导执行流程进入相应的处理函数。
相同类别的语句处理过程涉及内容相近,实现思想和主要过程相似。例如,事务类处理主要是对于当前事务的状态的判断和转换;游标类处理的主要思想是首次将执行一个査询计划树(Plantree),将结果缓存在Portal指向的特殊结构中,然后按照要求获取元组数据;表、属性管理类主要涉及权限管理、修改相应系统表以及关系表的存储类别操作等。由于数据定义语句的种类多达上百种,我们下面将以一个创建表的例子来介绍数据定义语句的执行流程。
针对各种不同的査询树,査询编译器在执行处理前会做一些额外的处理对査询树进行分析、处理与转换。创建表的语句会用函数transformCreateStmt进行査询树的处理。这些处理过程可能会在当前操作之前和之后增加一些新的操作(例如在创建表的操作之前增加创建serial序列表操作、之后增加创建触发器用于外键约束操作等),也可能会执行对数据结构的处理操作(例如将CreateStmt节点tableElts字段中CONST_CHECK类型的Constraint节点转存到CreateStmt的ccmstraints链表中等)。由于这些处理过程会产生一些新的操作,因此最终会生成一个由多个操作构成的链表。因此,执行过程需要依次扫描该链表,为每一个原子操作调用相应的处理函数。
1.2执行实例
例 创建一个名为course的数据表,此表有三个属性:编号(no,自增属性)、姓名
(name)非空、学分(credit)非负。其中,包含了一个约束定义,主键被定义为编号(no)。对应
的SQL语句如T:
CREATE TABLE course (
no SERIAL,
name VARCHAR,
credit INT,
CONSTRAINT con1 CHECK(credit > = 0 AND name <> ''),
PRIMARY KEY(no)
);
系统首先会对査询语句进行词法和语法分析,将査询语句构造为査询树的链表。然后,针对链
表中的每一个査询树进行如下的处理过程(下例仅有一个T_CreateStmt类型的査询树):
1)分析和重写查询树。
2)生成査询计划。
3)创建及初始化Portal。
4)调用Portal执行过程。
5)调用Portal清理过程。
下面给出了上述査询语句执行时的主要函数调用流程。
pg_parse_query
|
v
pg_analyze_and_rewrite
|
v
PortalStart -> ChoosePortalStrategy
|
v
PortalRun -> PortalRunMulti -> PortalRunUtility -> ProcessUtility -> standard_ProcessUtility -> ProcessUtilitySlow
|
v
PortalDrop
在上面的例子中,査询编译器会生成一个仅包含一个T_CreateStmt类型节点的査询树链表,因此对应的Portal的stmts字段中也只包含一个T_CreateStmt类型节点。ChoosePortalStrategy函数根据stmts字段值选择策略时会选择PORTAL_MULTI_QUERY策略。在接下来的PortalRun函数中将会调用PortalRunMuti来执行PORTAL_MULTI_QUERY策略,将会把处理流程引导到ProcessUtility中。ProcessUtility将首先调用函数transformCreateStmt对T_CreateStmt节点进行转换处理,流程如下所示。该过程会做如下转换:
ProcessUtilitySlow:
case T_CreateStmt:
case T_CreateForeignTableStmt:
transformCreateStmt()
|
v
foreach(l, stmts){
if (IsA(stmt, CreateStmt)) or IsA(stmt, CreateForeignTableStmt)
...
DefineRelation
...
else
ProcessUtility
......
}
将主键约束改为创建唯一索引(T_IndexStmt节点)。
将自增类型转换为int4oid,并附加创建专用的SERIAL表(用于记录自增字段,将形成一个 T_CreateSeqStnU 节点)操作
增加CONSTR_DEFAULT类型约束作为默认值(被定义为调用函数nextval)。
创建SERIAL表(T_CreateSeqStmt节点)的操作会被放在stmts链表中T_CreateStmt节点之前的位置,创建唯一约束索引(T_IndexStmt节点)的操作被放置在T_CreateStmt节点
之后。最后还会将单独定义或与属性同时定义的CONSTR_CHECK类型约束全部转移到T_CreateStmt节点的constraints字段所指向的链表中。
最后,transformCreateStmt将原有的 T_CreateStmt操作转换为一个操作序列:依次为T_CreateSeqStmt (创建序列表)、T_CreateStmt (创建数据表)、T_IndexStmt (创建唯一约束索引)。
CREATE SERIAL TABLE course_no_seq;--用于产生自增序列
CREATE TABLE course (
noint40id DEFAULT nextval (),
nameVARCHAR,
creditINT,
CONSTRAINT coni CHECK (credit >=0 AND name <> "),
CREATE INDEX course_pkey;--用于唯一检査
之后ProcessUtility将逐个对序列中的操作进行处理。对T_CreateStmt操作将会调用DefineRelation进行数据表的创建,而其他节点则会通过递归调用ProcessUtility进人相应的处理过程。下面展示了 T_CreateStmt操作的处理过程
创建表的过程由函数DefineRelation完成,其流程如下:
- 进行权限检査,确定当前用户是否有权限创建表。
- 对表创建语句中的WITH子句进行解析(transfbrmRelOptions)。
- 调用heap_reloptions对参数进行合法性验证。
- 使用MergeAttributes,将继承的属性合并到表属性定义中。
- 调用BuildDescForRelation利用合并后的厲性定义链表创建tupleDesc结构(这个结构用于描述元组各属性结构等信息)。
- 决定是否使用系统属性OID (interpretOidsOption)。
- 对属性定义链表中的每一个属性进行处理,査看是否有默认值、表达式或约束检査。
- 使用heap_create_with_catalog创建表的物理文件并在相应的系统表中注册。
9)用StoreCataloglnheritance存储表的继承关系。
10)处理表中新增的约束与默认值(AddRleationNewConstraints)。
DefineRelation
->
Permission check
transformRelOptions()
heap_reloptions()
MergeAttributes()
BuildDescForRelation()
interpretOidsOption()
CONSTR_DEFAULT or CONSTR_CHECK
heap_create_with_catalog()
StoreCatalogInheritance()
AddRelationNewConstraints()
ObjectAddressSet()
表创建函数的主要功能是由heap_create_with_catalog完成的,之前的各种操作主要是构造heap_create_with_catalog所需要的参数。例如,WITH子句处理主要完成其中存储相关参数的处理,以便存人pg_class系统表的reloptions字段中;BuildDescForRelation主要处理表定义中属性名、类型、非空约束以便构造pg_attribute系统表相关内容。
heap_create_with_catalog函数首先会根据要创建表的属性描述信息、表的名称、命名空间等使用heap_create创建一个RelationData结构并放人RelCache,并根据这些信息通过调用RelalionCreateStorage函数创建物理文件。然后调用AddNewRelationType,向pg_type中增加一条关于该表的记录。AddNewRelationTuple则会将表的相关信息插人pg_class系统表中,而AddNewAttributeTuples将表的每个属性记录到pg_attribute系统表中。最后还需要通过调用StoreConstraints将约束和默认值分别存储到 pg_constraint 和 pg_attrdef 中。
1.3主要的功能处理函数
从创建表的例子可以看到,功能处理器(ProcessUtility)本身只作为入口选择函数,它会根据输人的节点类型调用相应的处理过程。除了创建表的处理过程之外,下面列出了几种常见的输人节点类型,并给出了其对应处理函数以及其功能简介。
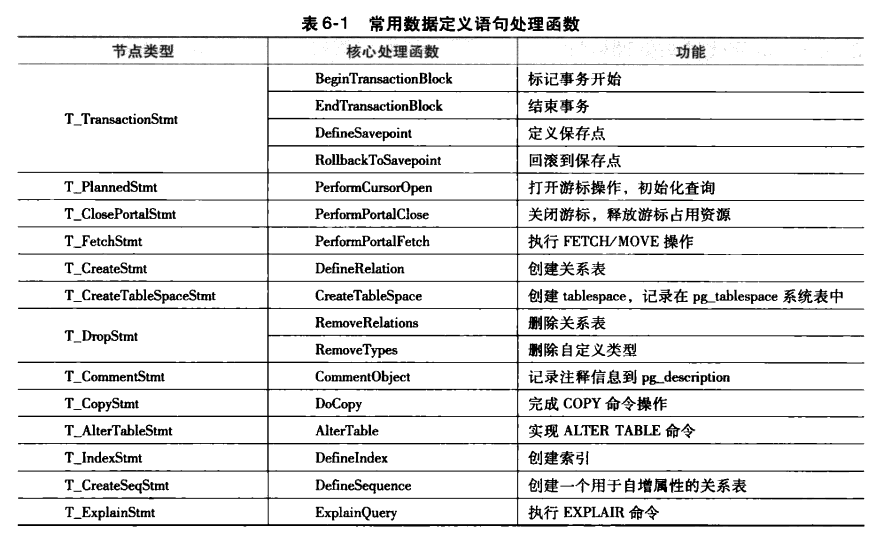
注:本文参考了《Postgresql数据库内核分析》一书。
跟我一起读postgresql源码(七)——Executor(查询执行模块之——数据定义语句的执行)的更多相关文章
- 跟我一起读postgresql源码(十)——Executor(查询执行模块之——Scan节点(下))
接前文跟我一起读postgresql源码(九)--Executor(查询执行模块之--Scan节点(上)) ,本篇把剩下的七个Scan节点结束掉. T_SubqueryScanState, T_Fun ...
- 跟我一起读postgresql源码(八)——Executor(查询执行模块之——可优化语句的执行)
2.可优化语句的执行 可优化语句的共同特点是它们被查询编译器处理后都会生成査询计划树,这一类语句由执行器(Executor)处理.该模块对外提供了三个接口: ExecutorStart.Executo ...
- 跟我一起读postgresql源码(四)——Planer(查询规划模块)(上)
时间一晃周末就过完了,时间过得太快,不由得让人倍加珍惜.时间真是不够用哈~ 好的不废话,这次我们开始看查询规划模块的源码吧. 查询规划部分的在整个查询处理模块应该是在一个非常重要的地位上,这一步直接决 ...
- 跟我一起读postgresql源码(九)——Executor(查询执行模块之——Scan节点(上))
从前面介绍的可优化语句处理相关的背景知识.实现思想和执行流程,不难发现可优化语句执行的核心内容是对于各种计划节点的处理,由于使用了节点表示.递归调用.统一接口等设计,计划节点的功能相对独立.代码总体流 ...
- 跟我一起读postgresql源码(五)——Planer(查询规划模块)(下)
上一篇我们介绍了查询规划模块的总体流程和预处理部分的源码.查询规划模块再执行完预处理之后,可以进入正式的查询规划处理流程了. 查询规划的主要工作由grouping_planner函数完成.在具体实现的 ...
- 跟我一起读postgresql源码(三)——Rewrite(查询重写模块)
上一篇博文我们阅读了postgresql中查询分析模块的源码.查询分析模块对前台送来的命令进行词法分析.语法分析和语义分析后获得对应的查询树(Query).在获得查询树之后,程序开始对查询树进行查询重 ...
- 跟我一起读postgresql源码(二)——Parser(查询分析模块)
上篇博客简要的介绍了下psql命令行客户端的前台代码.这一次,我们来看看后台的代码吧. 十分不好意思的是,上篇博客我们只说明了前台登陆的代码,没有介绍前台登陆过程中,后台是如何工作的.即:后台接到前台 ...
- 跟我一起读postgresql源码(十一)——Executor(查询执行模块之——Materialization节点(上))
物化节点 顾名思义,物化节点是一类可缓存元组的节点.在执行过程中,很多扩展的物理操作符需要首先获取所有的元组后才能进行操作(例如聚集函数操作.没有索引辅助的排序等),这时要用物化节点将元组缓存起来.下 ...
- 跟我一起读postgresql源码(十三)——Executor(查询执行模块之——Join节点(上))
Join节点 JOIN节点有以下三种: T_NestLoopState, T_MergeJoinState, T_HashJoinState, 连接类型节点对应于关系代数中的连接操作,PostgreS ...
随机推荐
- Uncaught TypeError: download is not a function at HTMLAnchorElement.onclick (index.html:25)
前段时间调试html报了这样的一个错误 Uncaught TypeError: download is not a function at HTMLAnchorElement.onclick ...
- Web前端学习——HTML
HTML其实还是蛮容易学习的,无非就是一些标签.格式的填写,大学的时候也做过网站设计,所以这里主要记录一些常用的HTML标签.属性以及书写方法等. 一.常见HTML格式 主要包含文件type,html ...
- zkw模板
水平有限,前缀和的前缀和什么的,rbq 两个操作: 1.区间l到r加上一个数x 2.查询区间[l,r]的区间和 #include<iostream> #include<cstdio& ...
- 小白的Python之路 day1 模块初识
模块初识 Python的强大之处在于他有非常丰富和强大的标准库和第三方库,几乎你想实现的任何功能都有相应的Python库支持,以后的课程中会深入讲解常用到的各种库,现在,我们先来象征性的学2个简单的. ...
- day5、文件乱码怎么解决
1.1 Linux下,如何将一个乱码的文件进行重命名 方法一: 命令格式:mv $(ls |egrep "[^a-zA-Z0-9.-]") tandao.tx [root@nb ...
- Java笔记 (持续更新ing)
目录: 1 . GC是什么,为什么要有GC? 1. GC是什么,为什么要有GC? GC是垃圾回收的意思,内存处理是编程人员容易出现问题的地方,忘记或者错误的内存回收会导致程序或系统的不稳定甚至崩溃 ...
- hdu4893 Wow! Such Sequence!
线段树结点上保存一个一般的sum值,再同一时候保存一个fbsum,表示这个结点表示的一段数字若为斐波那契数时的和 当进行3操作时,仅仅用将sum = fbsum就可以 其它操作照常进行,仅仅是单点更新 ...
- 【MySQL】(4)操作数据表中的记录
1. 插入记录INSERT 方法一: INSERT [INTO] tbl_name [(clo_name,...)] {VALUES | VALUE} ({expr | DEFAULT},...),( ...
- js判断一些时间范围是否有重复时间段
function isHasRepeatTime(data) { var startTimeArr = []; var endTimeArr = []; (data || []).map(functi ...
- IEEE1588 verision2 报文介绍
PTP报文 PTP verision2报文是由 报头,主体 和 报尾 (header, body, and suffix)组成,报尾长度可能为0. PTP verision2报文在verision1的 ...