部署和使用kibana
背景
上一篇介绍了在阿里云上部署ES(www.cnblogs.com/wenBlog/p/7451696.html),本文将主要介绍ELK的可视化工具Kibana的部署和使用。主要分为三个步骤来实现最终呈现:
1.导入数据到ES;
2.部署kibana并完成配置;
3.使用kibana生成可视化数据。
废话不多说下面直接上步骤了。
部署
1.下载配置kibana
- --下载kibana
- --解压
tar xzvf kibana-5.1.2-linux-x86_64.tar.gz
--配置
在conf/kibana.yml文件中进行配置

--将内网IP地址配置到这里,如图。
--启动kibana
2.导入数据到ES这里写一个版本注意jdbc的版本
- --下载 elasticsearch-jdbc 这里测试
- wget http://xbib.org/repository/org/xbib/elasticsearch/importer/elasticsearch-jdbc/2.3.4.1/elasticsearch-jdbc-2.3.4.1-dist.zip
- --解压 elasticsearch-jdbc
- unzip elasticsearch-jdbc-2.3.4.1-dist.zip
--创建ES索引
curl -XPUT IP地址/mysql- --新建一个import_mysql.sh文件,注意json里面配置mysql的地址、账号、密码、语句、ES的IP、端口等
- Java -cp "${lib}/*" -Dlog4j.configurationFile=${bin}/log4j2.xml org.xbib.tools.Runner org.xbib.tools.JDBCImporter jdbc_mysql.json
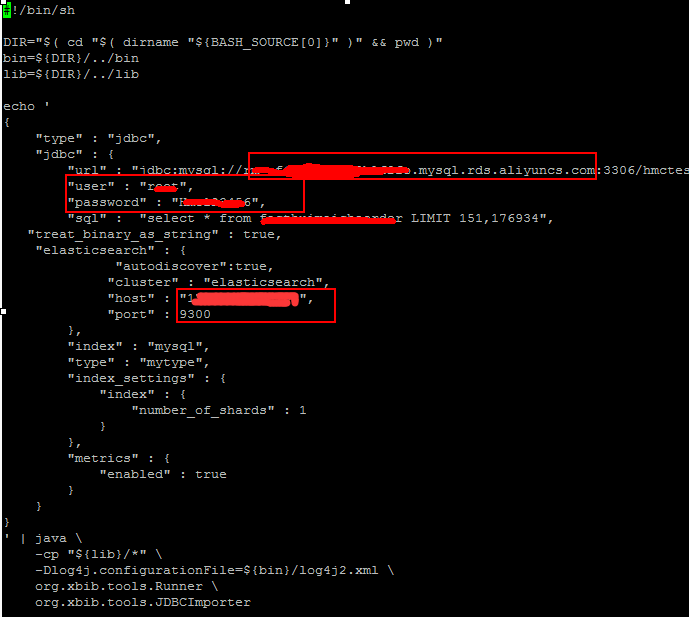
- --执行导入
- ./import_mysql.sh
使用kibana


2.Visualize页面的可视化工具能使你用好几种不同的方式展示你数据集的很多方面。
点击Visualize页面开始

3.下一步,我们打算制作一个条形图。点击New Visualization按钮,然后点击Vertical bar chart。选择From a new search,然后选定shakes*模式匹配。你将会看到单个大条形图,因为到现在为止我们还没有定义任何量值。

4.对于Y轴的刻度聚合,选择计量作为Unique
Count的字段。对于X轴的量值,选择Terms聚合和某一字段。对于排序,选择Ascending,Size保持默认值5。让其他参数保持默认值,然后点击Apply
cganges按钮

5.保存图表的名称为Bar Example。大功告成。
总结
本文完整的记录了配置kibana以及简单使用kibana,需要注意的是kibana端口号5601,使用命令保证该端口不被占用。前后两边文章介绍了ES到kibana的配置和使用。比较详细的记录了整体流程。
部署和使用kibana的更多相关文章
- kubernetes部署Fluentd+Elasticsearch+kibana 日志收集系统
一.介绍 1. Fluentd 是一个开源收集事件和日志系统,用与各node节点日志数据的收集.处理等等.详细介绍移步-->官方地址:http://fluentd.org/ 2. Elastic ...
- ELK部署详解--kibana
kibana.yml # Kibana is served by a back end server. This setting specifies the port to use.#端口server ...
- 使用docker-compose方式部署es和kibana以及cerebro
使用的镜像可以从这个网站查看最新的:https://hub.docker.com/ 参考极客时间上的教程转发来的 使用步骤:安装docker和docker-compose 运行: docker-com ...
- 【原创】运维基础之Docker(2)通过docker部署zookeeper nginx tomcat redis kibana/elasticsearch/logstash mysql kafka mesos/marathon
通过docker可以从头开始构建集群,也可以将现有集群(配置以及数据)平滑的迁移到docker部署: 1 docker部署zookeeper # usermod -G docker zookeeper ...
- 阿里云ECS部署ES
背景 最近越来越多的公司把业务搬迁到云上,公司也有这个计划,自己抽时间在阿里云和Azure上做了一些小的尝试,现在把阿里云上部署ES和kibana记录下来.为以后做一个参考,也希望对其他人有帮助. 这 ...
- ASP.NET Core Logging in Elasticsearch with Kibana
在微服务化盛行的今天,日志的收集.分析越来越重要.ASP.NET Core 提供了一个统一的,轻量级的Logining系统,并可以很方便的与第三方日志框架集成.我们也可以根据不同的场景进行扩展,因为A ...
- ELK6.6.0+filebeat6.6.0部署
elastic不能用root用户去启动,否则会报错,所以创建elastic用户ES集群部署 1.创建elastic用户 $ useradd elastic $ passwd elastic 2..部署 ...
- Docker 部署 elk + filebeat
Docker 部署 elk + filebeat kibana 开源的分析与可视化平台logstash 日志收集工具 logstash-forwarder(原名lubmberjack)elastics ...
- 利用 log-pilot + elasticsearch + kibana 搭建 kubernetes 日志解决方案
开发者在面对 kubernetes 分布式集群下的日志需求时,常常会感到头疼,既有容器自身特性的原因,也有现有日志采集工具的桎梏,主要包括: 容器本身特性: 采集目标多:容器本身的特性导致采集目标多, ...
随机推荐
- (转)IntelliJ IDEA 破解方法
1.下载破解包http://pan.baidu.com/s/1gf9fXx5 2.解压并打开选中的文件 3.如图 4.IDEA选择License Server输入 http://127.0.0.1:1 ...
- Css元素居中设置
你对DIV CSS居中的方法是否了解,这里和大家分享一下,用CSS让元素居中显示并不是件很简单的事情,让我们先来看一下CSS中常见的几种让元素水平居中显示的方法. DIV CSS居中 用CSS让元素居 ...
- iOS imageio nsurlsession 渐进式图片下载
一.图片常用加载格式分两种 一般线性式 和交错/渐进式 自上而下线性式 先模糊再清晰 就概率上而言线性式使用最多,应为他所占空间普片比渐进式小.而这两种方式对于app端开发人员无需关心,这种图片存储格 ...
- 四.GC —三分钟认识JAVA回收机制(Java Garbage Collection)
这里以jdk1.8做讲解.Jdk1.8的分代去掉了永久代,只分为新生代(有的也译为年轻代)和年老代. 名词解释: 系统吞吐量:用于处理应用程序处理事务的线程数与用于GC的线程数的比. pause ti ...
- 初学Python(三)——字典
初学Python(三)——字典 初学Python,主要整理一些学习到的知识点,这次是字典. #-*- coding:utf-8 -*- d = {1:"name",2:" ...
- 我的学习之路_第三十四章_jsp
jsp 在只有servlet时,输出页面内容比较麻烦(成本高,java代码中输出HTML标签),所以需要一种技术,主要是HTML页面的代码(HTML,css,js),可以嵌入java代码,来实现动态页 ...
- spring aop 基于schema的aop
AOP的基本概念: 连接点(Jointpoint):表示需要在程序中插入横切关注点的扩展点,连接点可能是类初始化.方法执行.方法调用.字段调用或处理异常等等,Spring只支持方法执行连接点,在AOP ...
- CentOS下安装Nginx服务器
一.nginx安装环境 nginx是C语言开发,建议在linux上运行,本教程使用Centos7作为安装环境. 1.1 gcc 安装nginx需要先将官网下载的源码进行编译,编译依赖gcc环境,如果 ...
- 4.写一个控制台应用程序,接收一个长度大于3的字符串,完成下列功能: 1)输出字符串的长度。 2)输出字符串中第一个出现字母a的位置。 3)在字符串的第3个字符后面插入子串“hello”,输出新字符串。 4)将字符串“hello”替换为“me”,输出新字符串。 5)以字符“m”为分隔符,将字符串分离,并输出分离后的字符串。 */
namespace test4 {/* 4.写一个控制台应用程序,接收一个长度大于3的字符串,完成下列功能: 1)输出字符串的长度. 2)输出字符串中第一个出现字母a的位置. 3)在字符串的第3个字符 ...
- 万能头文件#include
#include<bits/stdc++.h>包含了目前c++所包含的所有头文件!!!! 测试结果POJ不支持HDU,NYOJ支持