Spring-Blog:个人博客(一)-Mybatis 读写分离
概述:
2018,在平(tou)静(lan)了一段时间后,开始找点事情来做。这一次准备开发一个个人博客,在开发过程之中完善一下自己的技术。本系列博客只会提出一些比较有价值的技术思路,不会像写流水账一样记录开发过程。
技术栈方面,会采用Spring Boot 2.0 作为底层框架,主要为了后续能够接入Spring Cloud 进行学习拓展。并且Spring Boot 2.0基于Spring5,也可以提前预习一些Spring5的新特性。后续技术会在相应博客中提出。
项目GitHub地址:https://github.com/jaycekon/Spring-Blog
介绍一下目录结构:
- Spring-Blog( Parent 项目)
- Spring-Blog-common( Util 模块)
- Spring-Blog-business(Repository模块)
- Spring-Blog-api (Web 模块)
- Spring-Blog-webflux (基于Spring Boot 2.0 的 Web模块)
为了让各位朋友能够更好理解这一模块的内容,演示代码将存放在Spring Boot 项目下:
Github 地址:https://github.com/jaycekon/SpringBoot
1、DataSource
在开始讲解前,我们需要先构建后我们的运行环境。Spring Boot 引入 Mybatis 的教程 可以参考 传送门 。这里我们不细述了,首先来看一下我们的目录结构:
有使用过Spring Boot 的童鞋应该清楚,当我们在application.properties 配置好了我们的数据库连接信息后,Spring Boot 将会帮我们自动装载好 DataSource 。但如果我们需要进行读写分离操作是,如何配置自己的数据源,是我们必须掌握的。
首先我们来看一下配置文件中的信息:
spring.datasource.url=jdbc:mysql://localhost:3306/charles_blog2
spring.datasource.username=root
spring.datasource.password=root
spring.datasource.driver-class-name=com.mysql.jdbc.Driver #别名扫描目录
mybatis.type-aliases-package=com.jaycekon.demo.model
#Mapper.xml扫描目录
mybatis.mapper-locations=classpath:mybatis-mappers/*.xml #tkmapper 帮助工具
mapper.mappers=com.jaycekon.demo.MyMapper
mapper.not-empty=false
mapper.identity=MYSQL
1.1 DataSourceBuilder
我们首先来看一下使用 DataSourceBuilder 来构建出DataSource:
@Configuration
@MapperScan("com.jaycekon.demo.mapper")
@EnableTransactionManagement
public class SpringJDBCDataSource { /**
* 通过Spring JDBC 快速创建 DataSource
* 参数格式
* spring.datasource.master.jdbcurl=jdbc:mysql://localhost:3306/charles_blog
* spring.datasource.master.username=root
* spring.datasource.master.password=root
* spring.datasource.master.driver-class-name=com.mysql.jdbc.Driver
*
* @return DataSource
*/
@Bean
@ConfigurationProperties(prefix = "spring.datasource.master")
public DataSource dataSource() {
return DataSourceBuilder.create().build();
}
}
从代码中我们可以看出,使用DataSourceBuilder 构建DataSource 的方法非常简单,但是需要注意的是:
- DataSourceBuilder 只能自动识别配置文件中的 jdbcurl,username,password,driver-class-name等命名,因此我们需要在方法体上加上 @ ConfigurationProperties 注解。
- 数据库连接地址变量名需要使用 jdbcurl
- 数据库连接池使用 com.zaxxer.hikari.HikariDataSource
执行单元测试时,我们可以看到 DataSource 创建以及关闭的过程。

1.2 DruidDataSource
除了使用上述的构建方法外,我们可以选择使用阿里提供的 Druid 数据库连接池创建 DataSource
@Configuration
@EnableTransactionManagement
public class DruidDataSourceConfig { @Autowired
private DataSourceProperties properties; @Bean
public DataSource dataSoucre() throws Exception {
DruidDataSource dataSource = new DruidDataSource();
dataSource.setUrl(properties.getUrl());
dataSource.setDriverClassName(properties.getDriverClassName());
dataSource.setUsername(properties.getUsername());
dataSource.setPassword(properties.getPassword());
dataSource.setInitialSize(5);
dataSource.setMinIdle(5);
dataSource.setMaxActive(100);
dataSource.setMaxWait(60000);
dataSource.setTimeBetweenEvictionRunsMillis(60000);
dataSource.setMinEvictableIdleTimeMillis(300000);
dataSource.setValidationQuery("SELECT 'x'");
dataSource.setTestWhileIdle(true);
dataSource.setTestOnBorrow(false);
dataSource.setTestOnReturn(false);
dataSource.setPoolPreparedStatements(true);
dataSource.setMaxPoolPreparedStatementPerConnectionSize(20);
dataSource.setFilters("stat,wall");
return dataSource;
}
}
使用 DruidDataSource 作为数据库连接池可能看起来会比较麻烦,但是换一个角度来说,这个更加可控。我们可以通过 DataSourceProperties 来获取 application.properties 中的配置文件:
spring.datasource.url=jdbc:mysql://localhost:3306/charles_blog2
spring.datasource.username=root
spring.datasource.password=root
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
需要注意的是,DataSourceProperties 读取的配置文件 前缀是 spring.datasource ,我们可以进入到 DataSourceProperties 的源码中观察:
@ConfigurationProperties(prefix = "spring.datasource")
public class DataSourceProperties
implements BeanClassLoaderAware, EnvironmentAware, InitializingBean
可以看到,在源码中已经默认标注了前缀的格式。
除了使用 DataSourceProperties 来获取配置文件 我们还可以使用通用的环境变量读取类:
@Autowired
private Environment env;
env.getProperty("spring.datasource.write")
2、多数据源配置
配置多数据源主要需要以下几个步骤:
2.1 DatabaseType 数据源名称
这里直接使用枚举类型区分,读数据源和写数据源
public enum DatabaseType {
master("write"), slave("read");
DatabaseType(String name) {
this.name = name;
}
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "DatabaseType{" +
"name='" + name + '\'' +
'}';
}
}
2.2 DatabaseContextHolder
该类主要用于记录当前线程使用的数据源,使用 ThreadLocal 进行记录数据
public class DatabaseContextHolder {
private static final ThreadLocal<DatabaseType> contextHolder = new ThreadLocal<>();
public static void setDatabaseType(DatabaseType type) {
contextHolder.set(type);
}
public static DatabaseType getDatabaseType() {
return contextHolder.get();
}
}
2.3 DynamicDataSource
该类继承 AbstractRoutingDataSource 用于管理 我们的数据源,主要实现了 determineCurrentLookupKey 方法。
后续细述这个类是如何进行多数据源管理的。
public class DynamicDataSource extends AbstractRoutingDataSource {
@Nullable
@Override
protected Object determineCurrentLookupKey() {
DatabaseType type = DatabaseContextHolder.getDatabaseType();
logger.info("====================dataSource ==========" + type);
return type;
}
}
2.4 DataSourceConfig
最后一步就是配置我们的数据源,将数据源放置到 DynamicDataSource 中:
@Configuration
@MapperScan("com.jaycekon.demo.mapper")
@EnableTransactionManagement
public class DataSourceConfig { @Autowired
private DataSourceProperties properties; /**
* 通过Spring JDBC 快速创建 DataSource
* 参数格式
* spring.datasource.master.jdbcurl=jdbc:mysql://localhost:3306/charles_blog
* spring.datasource.master.username=root
* spring.datasource.master.password=root
* spring.datasource.master.driver-class-name=com.mysql.jdbc.Driver
*
* @return DataSource
*/
@Bean(name = "masterDataSource")
@Qualifier("masterDataSource")
@ConfigurationProperties(prefix = "spring.datasource.master")
public DataSource masterDataSource() {
return DataSourceBuilder.create().build();
} /**
* 手动创建DruidDataSource,通过DataSourceProperties 读取配置
* 参数格式
* spring.datasource.url=jdbc:mysql://localhost:3306/charles_blog
* spring.datasource.username=root
* spring.datasource.password=root
* spring.datasource.driver-class-name=com.mysql.jdbc.Driver
*
* @return DataSource
* @throws SQLException
*/
@Bean(name = "slaveDataSource")
@Qualifier("slaveDataSource")
public DataSource slaveDataSource() throws SQLException {
DruidDataSource dataSource = new DruidDataSource();
dataSource.setUrl(properties.getUrl());
dataSource.setDriverClassName(properties.getDriverClassName());
dataSource.setUsername(properties.getUsername());
dataSource.setPassword(properties.getPassword());
dataSource.setInitialSize(5);
dataSource.setMinIdle(5);
dataSource.setMaxActive(100);
dataSource.setMaxWait(60000);
dataSource.setTimeBetweenEvictionRunsMillis(60000);
dataSource.setMinEvictableIdleTimeMillis(300000);
dataSource.setValidationQuery("SELECT 'x'");
dataSource.setTestWhileIdle(true);
dataSource.setTestOnBorrow(false);
dataSource.setTestOnReturn(false);
dataSource.setPoolPreparedStatements(true);
dataSource.setMaxPoolPreparedStatementPerConnectionSize(20);
dataSource.setFilters("stat,wall");
return dataSource;
} /**
* 构造多数据源连接池
* Master 数据源连接池采用 HikariDataSource
* Slave 数据源连接池采用 DruidDataSource
* @param master
* @param slave
* @return
*/
@Bean
@Primary
public DynamicDataSource dataSource(@Qualifier("masterDataSource") DataSource master,
@Qualifier("slaveDataSource") DataSource slave) {
Map<Object, Object> targetDataSources = new HashMap<>();
targetDataSources.put(DatabaseType.master, master);
targetDataSources.put(DatabaseType.slave, slave); DynamicDataSource dataSource = new DynamicDataSource();
dataSource.setTargetDataSources(targetDataSources);// 该方法是AbstractRoutingDataSource的方法
dataSource.setDefaultTargetDataSource(slave);// 默认的datasource设置为myTestDbDataSourcereturn dataSource;
} @Bean
public SqlSessionFactory sqlSessionFactory(@Qualifier("masterDataSource") DataSource myTestDbDataSource,
@Qualifier("slaveDataSource") DataSource myTestDb2DataSource) throws Exception {
SqlSessionFactoryBean fb = new SqlSessionFactoryBean();
fb.setDataSource(this.dataSource(myTestDbDataSource, myTestDb2DataSource));
fb.setTypeAliasesPackage(env.getProperty("mybatis.type-aliases-package"));
fb.setMapperLocations(new PathMatchingResourcePatternResolver().getResources(env.getProperty("mybatis.mapper-locations")));
return fb.getObject();
}
}
上述代码块比较长,我们来解析一下:
masterDataSource 和 slaveDataSource 主要是用来创建数据源的,这里分别使用了 hikaridatasource 和 druidDataSource 作为数据源
DynamicDataSource 方法体中,我们主要是将两个数据源都放到 DynamicDataSource 中进行统一管理
SqlSessionFactory 方法则是将所有数据源(DynamicDataSource )统一管理
2.5 UserMapperTest
接下来我们来简单观察一下 DataSource 的创建过程:
首先我们可以看到我们的两个数据源以及构建好了,分别使用的是HikariDataSource 和 DruidDataSource,然后我们会将两个数据源放入到 targetDataSource 中,并且这里讲我们的 slave 作为默认数据源 defaultTargetDataSource
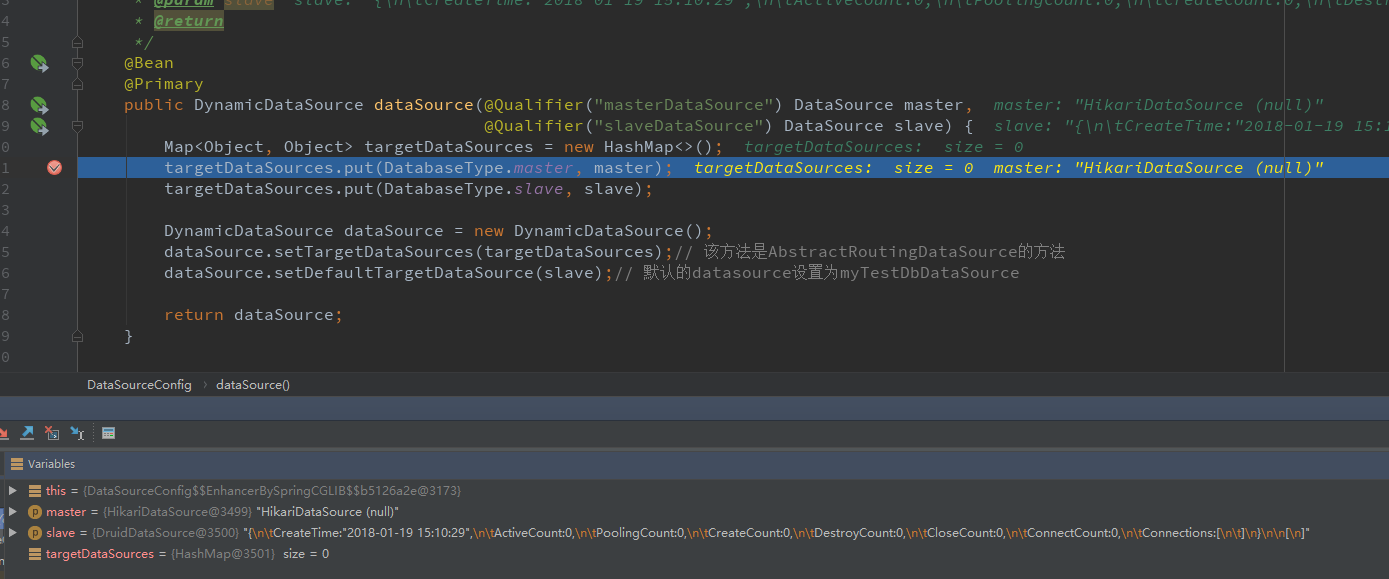
然后到获取数据源这一块:
主要是从 AbstractRoutingDataSource 这个类中的 determineTargetDataSource( ) 方法中进行判断,这里会调用到我们再 DynamicDataSource 中的方法, 去判断需要使用哪一个数据源。如果没有设置数据源,将采用默认数据源,就是我们刚才设置的DruidDataSource 数据源。
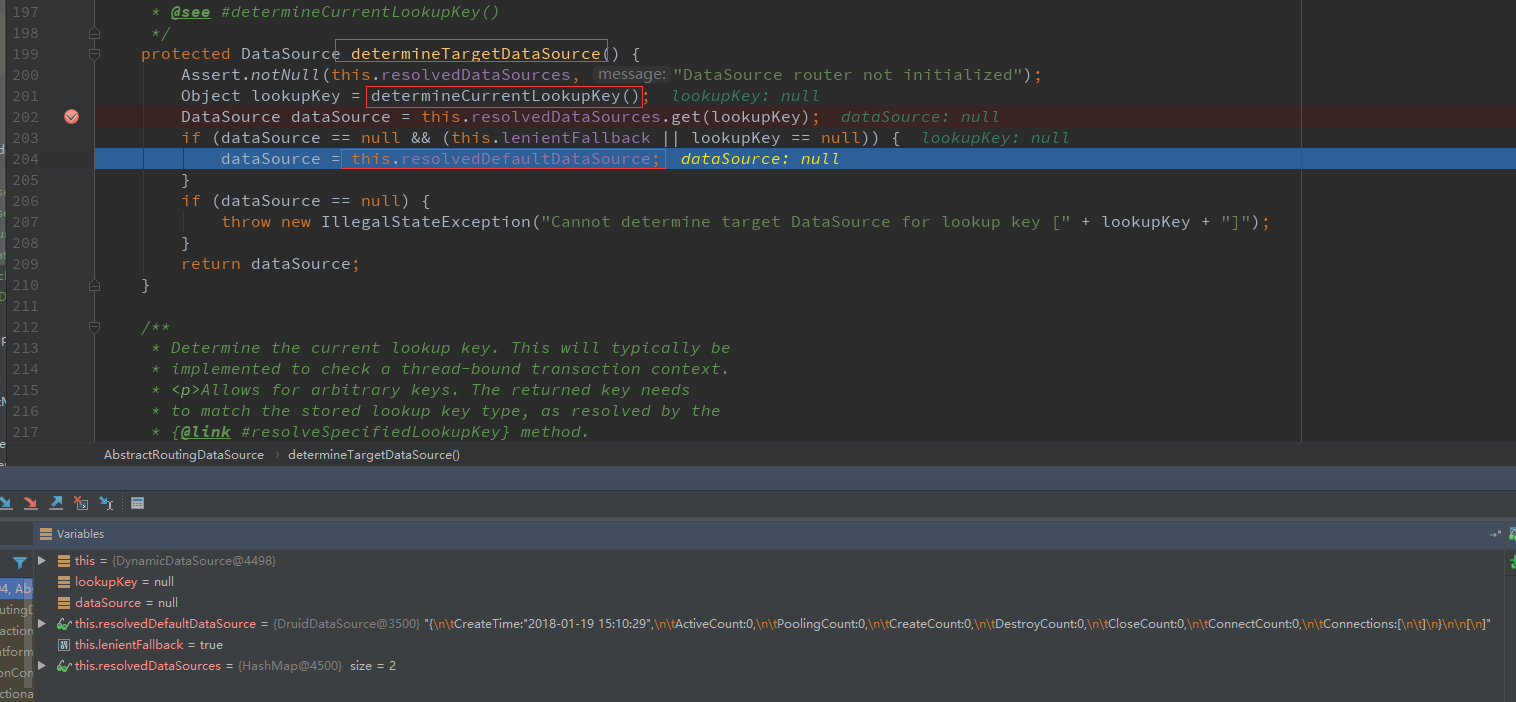
在最后的代码运行结果中:
我们可以看到确实是使用了我们设置的默认数据源。

3、读写分离
在经历了千山万水后,终于来到我们的读写分离模块了,首先我们需要添加一些我们的配置信息:
spring.datasource.read = get,select,count,list,query
spring.datasource.write = add,create,update,delete,remove,insert
这两个变量主要用于切面判断中,区分哪一些部分是需要使用 读数据源,哪些是需要使用写的。
3.1 DynamicDataSource 修改
public class DynamicDataSource extends AbstractRoutingDataSource {
static final Map<DatabaseType, List<String>> METHOD_TYPE_MAP = new HashMap<>();
@Nullable
@Override
protected Object determineCurrentLookupKey() {
DatabaseType type = DatabaseContextHolder.getDatabaseType();
logger.info("====================dataSource ==========" + type);
return type;
}
void setMethodType(DatabaseType type, String content) {
List<String> list = Arrays.asList(content.split(","));
METHOD_TYPE_MAP.put(type, list);
}
}
在这里我们需要添加一个Map 进行记录一些读写的前缀信息。
3.2 DataSourceConfig 修改
在DataSourceConfig 中,我们再设置DynamicDataSource 的时候,将前缀信息设置进去。
@Bean
@Primary
public DynamicDataSource dataSource(@Qualifier("masterDataSource") DataSource master,
@Qualifier("slaveDataSource") DataSource slave) {
Map<Object, Object> targetDataSources = new HashMap<>();
targetDataSources.put(DatabaseType.master, master);
targetDataSources.put(DatabaseType.slave, slave); DynamicDataSource dataSource = new DynamicDataSource();
dataSource.setTargetDataSources(targetDataSources);// 该方法是AbstractRoutingDataSource的方法
dataSource.setDefaultTargetDataSource(slave);// 默认的datasource设置为myTestDbDataSource String read = env.getProperty("spring.datasource.read");
dataSource.setMethodType(DatabaseType.slave, read); String write = env.getProperty("spring.datasource.write");
dataSource.setMethodType(DatabaseType.master, write); return dataSource;
}
3.3 DataSourceAspect
在配置好读写的方法前缀后,我们需要配置一个切面,监听在进入Mapper 方法前将数据源设置好:
主要的操作点在于 DatabaseContextHolder.setDatabaseType(type); 结合我们上面多数据源的获取数据源方法,这里就是我们设置读或写数据源的关键了。
@Aspect
@Component
@EnableAspectJAutoProxy(proxyTargetClass = true)
public class DataSourceAspect {
private static Logger logger = LoggerFactory.getLogger(DataSourceAspect.class); @Pointcut("execution(* com.jaycekon.demo.mapper.*.*(..))")
public void aspect() { } @Before("aspect()")
public void before(JoinPoint point) {
String className = point.getTarget().getClass().getName();
String method = point.getSignature().getName();
String args = StringUtils.join(point.getArgs(), ",");
logger.info("className:{}, method:{}, args:{} ", className, method, args);
try {
for (DatabaseType type : DatabaseType.values()) {
List<String> values = DynamicDataSource.METHOD_TYPE_MAP.get(type);
for (String key : values) {
if (method.startsWith(key)) {
logger.info(">>{} 方法使用的数据源为:{}<<", method, key);
DatabaseContextHolder.setDatabaseType(type);
DatabaseType types = DatabaseContextHolder.getDatabaseType();
logger.info(">>{}方法使用的数据源为:{}<<", method, types);
}
}
}
} catch (Exception e) {
logger.error(e.getMessage(), e);
}
}
}
3.4 UserMapperTest
方法启动后,先进入切面中,根据methodName 设置数据源类型。
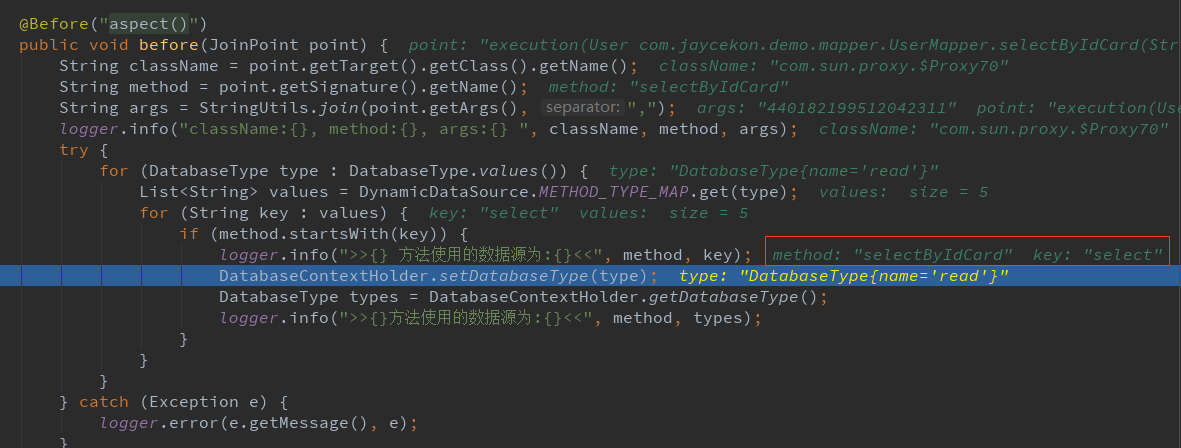
然后进入到determineTargetDataSource 方法中 获取到数据源:
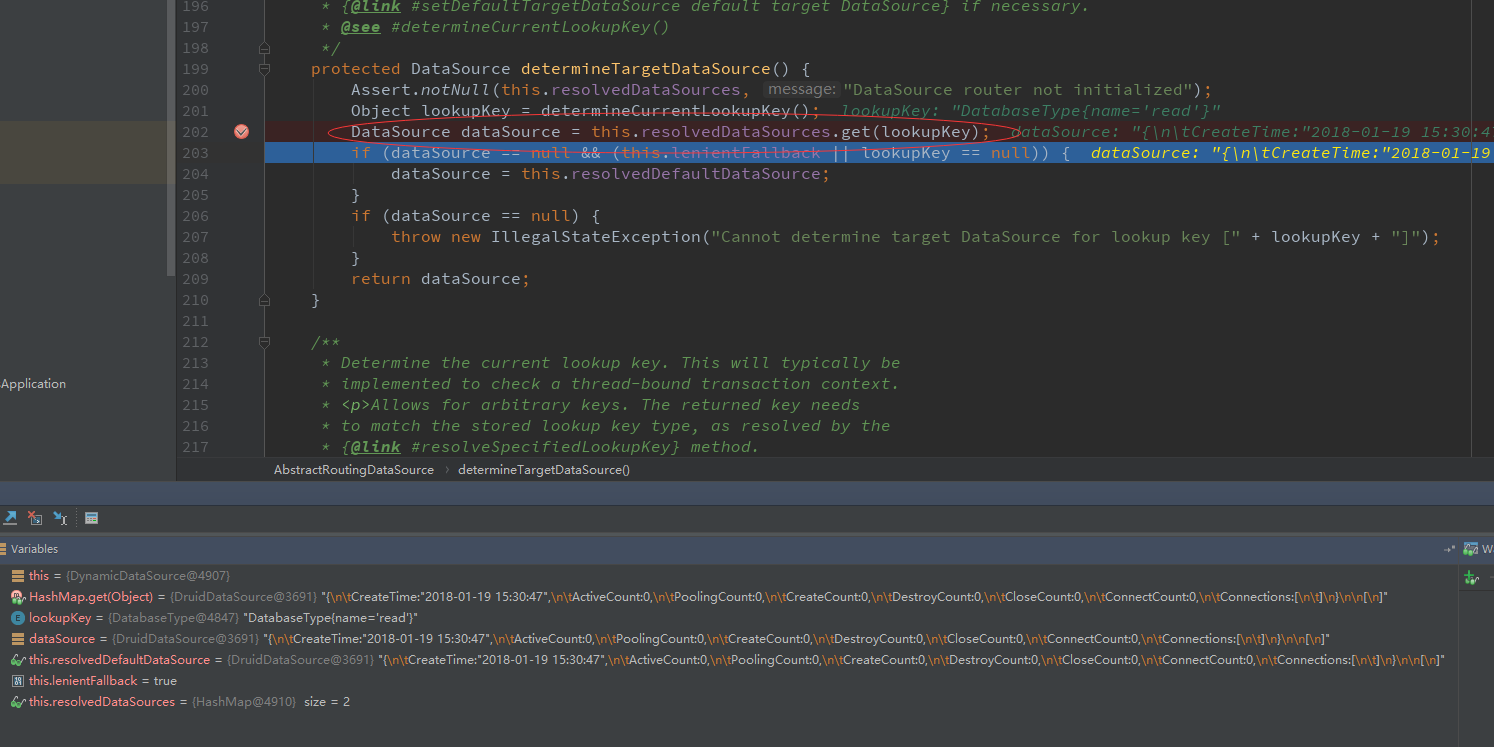
运行结果:

4、写在最后
希望看完后觉得有帮助的朋友,帮博主到github 上面点个Start 或者 fork
Spring-Blog 项目GitHub地址:https://github.com/jaycekon/Spring-Blog
示例代码 Github 地址:https://github.com/jaycekon/SpringBoot
我的博客即将搬运同步至腾讯云+社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan
Spring-Blog:个人博客(一)-Mybatis 读写分离的更多相关文章
- Mybatis MapperScannerConfigurer 自动扫描 将Mapper接口生成代理注入到Spring - 大新博客 - 推酷 - 360安全浏览器 7.1
Mybatis MapperScannerConfigurer 自动扫描 将Mapper接口生成代理注入到Spring - 大新博客 时间 2014-02-11 21:08:00 博客园-所有随笔区 ...
- [转]软件测试 Top 120 Blog (博客)
[转]软件测试 Top 120 Blog (博客) 2015-06-08 转自: 软件测试 Top 120 Blog (博客) # Site Author Memo DevelopSense M ...
- 关于Spring Boot的博客集合
掘金: 关于Spring Boot的博客集合 CSDN: Spring Boot教程 掘金: SpringBoot2 简书: Spring Boot 核心技术 天码营 Spring Data JPA: ...
- mybatis读写分离
mybatis读写分离实现方式有很多种,当然如果没有太过复杂的处理,可以使用阿里云数据库自带的读写分离连接,那样会更加简洁.本文主要对mybatis实现读写分离.主要的实现方式有一下四种: 方案1 通 ...
- WordPress搭建Personal Blog 个人博客
早就想搭建一个专属于自己的博客了,用来记录自己生活.学习的点点滴滴.之所以选WordPress,主要是因为它可以支持Latex,而且特别喜欢其简约的风格. WordPress有个the famous ...
- Spring定时任务解决博客缓存数据更新问题
最近在做博客系统的时候,由于很多页面都有右边侧边栏,内容包括博客分类信息,归档日志,热门文章,标签列表等,为了不想每次访问页面都去查询数据库,因为本身这些东西相对来说是比较固定的,但是也有可能在网站后 ...
- Spring + Mybatis 读写分离
项目背景:项目开发中数据库使用了读写分离,所有查询语句走从库,除此之外走主库. 实现思路是: 第一步,实现动态切换数据源:配置两个DataSource,配置两个SqlSessionFactory指向两 ...
- 搭建 springboot 2.0 mybatis 读写分离 配置区分不同环境
最近公司打算使用springboot2.0, springboot支持HTTP/2,所以提前先搭建一下环境.网上很多都在springboot1.5实现的,所以还是有些差异的.接下来咱们一块看一下. 文 ...
- SpringBoot Mybatis 读写分离配置(山东数漫江湖)
为什么需要读写分离 当项目越来越大和并发越来大的情况下,单个数据库服务器的压力肯定也是越来越大,最终演变成数据库成为性能的瓶颈,而且当数据越来越多时,查询也更加耗费时间,当然数据库数据过大时,可以采用 ...
随机推荐
- 关于scrapy的piplines
1.进入setting中把ITEM_piplines文件注销去掉 2.在piplines中写好代码 # -*- coding: utf- -*- # Define your item pipeline ...
- 救援模式(Rescue Mode)、单用户模式(Single-User Mode)、紧急模式(Emergency Mode)的区别与联系
前天聚餐的时候一航和启飞学长讲到RUCTF中更改root密码要进入单用户模式,我插了一句"有的系统显示的是救援模式",说完后心里一直很虚...(技术上的事还是想好再说)今天查了一下 ...
- 快收藏!高手Linux运维管理必备工具大全,你会吗?
一.统一账号管理 1.LDAP 统一管理各种平台帐号和密码,包括但不限于各种操作系统(Windows.Linux),Linux系统sudo集成,系统用户分组,主机登入限制等:可与Apache,HTTP ...
- 《ActiveMQ in Action》【PDF】下载
内容介绍TheApache ActiveMQ message broker is an open source implementation ofthe Java Message Service sp ...
- iOS tableview和 Collection复用机制
TableView的重用机制,为了做到显示和数据分离, tableView的实现并且不是为每个数据项创建一个tableCell.而是只创建屏幕可显示最大个数的cell,然后重复使用这些cell,对ce ...
- ArcGIS API for JavaScript 4.2学习笔记[16] 弹窗自定义功能按钮及为要素自定义按钮(第五章完结)
这节对Popups这一章的最后两个例子进行介绍和解析. 第一个[Popup Actions]介绍了弹窗中如何自定义工具按钮(名为actions),以PopupTemplate+FeatureLayer ...
- php多语言切换---转载
文件内容: /include/language.php <?php $languages = array (); $languages ['zh-cn'] ["name"] ...
- LVS-DR集群搭建
安装LVS 下载源码包,安装时需要根据自己的内核,下载 ipvsadm-1.26.tar.gz的源码包,在进行编译安装以后,我们需要检查必需包是否安装: 1.对内核文件做链接 # uname -r 2 ...
- Python:监控ASM剩余空间
#!/usr/bin/env python # -*- coding:utf-8 -*- __author__ = 'Jipu FANG' version = 0.1 import cx_Oracle ...
- Django2.0中文文档
title: Django2.0中文文档 tags: Python,Django,入沐三分 grammar_cjkRuby: true --- Django2.0版本已经发布了,我们先来看一个图片 从 ...