Spark性能调优之Shuffle调优
Spark性能调优之Shuffle调优
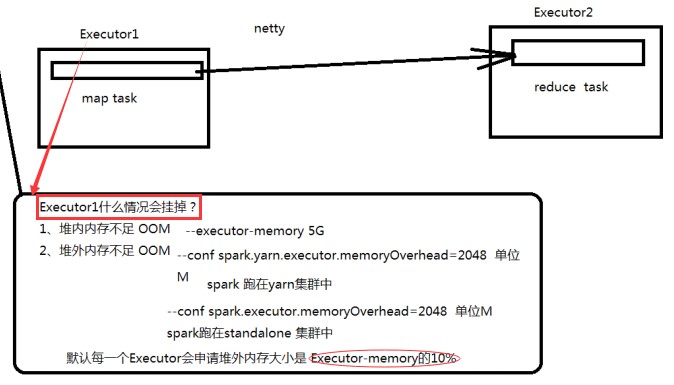
Spark性能调优之Shuffle调优的更多相关文章
- Spark性能优化:数据倾斜调优
前言 继<Spark性能优化:开发调优篇>和<Spark性能优化:资源调优篇>讲解了每个Spark开发人员都必须熟知的开发调优与资源调优之后,本文作为<Spark性能优化 ...
- Spark性能优化--数据倾斜调优与shuffle调优
一.数据倾斜发生的原理 原理:在进行shuffle的时候,必须将各个节点上相同的key拉取到某个节点上的一个task来进行处理,比如按照key进行聚合或join等操作.此时如果某个key对应的数据量特 ...
- Spark学习之路 (十)SparkCore的调优之Shuffle调优
摘抄自https://tech.meituan.com/spark-tuning-pro.html 一.概述 大多数Spark作业的性能主要就是消耗在了shuffle环节,因为该环节包含了大量的磁盘I ...
- Spark学习之路 (十)SparkCore的调优之Shuffle调优[转]
概述 大多数Spark作业的性能主要就是消耗在了shuffle环节,因为该环节包含了大量的磁盘IO.序列化.网络数据传输等操作.因此,如果要让作业的性能更上一层楼,就有必要对shuffle过程进行调优 ...
- Spark性能优化:开发调优篇
1.前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark的功能涵盖了大数据领域的离线批处理.SQL类处理.流式/实时计算.机器学习.图计算等各种不同类型的计算 ...
- spark调优——Shuffle调优
在Spark任务运行过程中,如果shuffle的map端处理的数据量比较大,但是map端缓冲的大小是固定的,可能会出现map端缓冲数据频繁spill溢写到磁盘文件中的情况,使得性能非常低下,通过调节m ...
- Spark性能调优-高级篇
前言 继基础篇讲解了每个Spark开发人员都必须熟知的开发调优与资源调优之后,本文作为<Spark性能优化指南>的高级篇,将深入分析数据倾斜调优与shuffle调优,以解决更加棘手的性能问 ...
- Spark性能调优-基础篇
前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark的功能涵盖了大数据领域的离线批处理.SQL类处理.流式/实时计算.机器学习.图计算等各种不同类型的计算操作 ...
- Spark学习之路 (八)SparkCore的调优之开发调优
摘抄自:https://tech.meituan.com/spark-tuning-basic.html 前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark ...
随机推荐
- 防盗链与token运用
为什么要防盗链? 例如手机/PC应用,如果有人知道你的api地址,和应用格式,那么他人就可以利用这个接口进行盗链:盗取/盗用里面的数据. 防盗链特性: 1.因为是非开放性的,所以所有的接口都是封闭的, ...
- js拖拽的封装
<!DOCTYPE HTML> <html> <head> <meta http-equiv="Content-Type" content ...
- Android -- NestedScrolling滑动机制
1,如今NestedScrolling运用到很多地方了,要想好看一点的滑动变换,基本上就是使用这个来完成的,让我们来简单的了解一下. 2,NestedScrolling机制能够让父View和子View ...
- strace命令详解
转自: http://www.cnblogs.com/ahuo/p/4150623.html 备注: 这篇博文学到的不仅仅是 strace 这个命令,还有前辈的排错思路,致敬! strace 命令是一 ...
- [js高手之路]html5 canvas动画教程 - 重力、摩擦力、加速、抛物线运动
上节,我们讲了匀速运动,本节分享的运动就更有意思了: 加速运动 重力加速度 抛物线运动 摩擦力 加速运动: <head> <meta charset='utf-8' /> &l ...
- 实战经验分享之C#对象XML序列化
.Net Framework提供了对应的System.Xml.Seriazliation.XmlSerializer负责把对象序列化到XML,和从XML中反序列化为对象.Serializer的使用比较 ...
- 部署 k8s Cluster(上)- 每天5分钟玩转 Docker 容器技术(118)
我们将部署三个节点的 Kubernetes Cluster. k8s-master 是 Master,k8s-node1 和 k8s-node2 是 Node. 所有节点的操作系统均为 Ubuntu ...
- Python的Django框架完成一个完整的论坛(源码以及思路)
一个完整的论坛,登录.注册.发表.头像.点赞.评论.分页.阅读排行等 使用Django2,Python3.5 开发工具:Pycharm5 需要的知识:Python基础知识,Django原理的理解以及使 ...
- AspNet Core 核心 通过依赖注入(注入服务)
说起依赖注入 相信大家已经很熟悉了,这里我在简要的描述一遍, 什么是依赖注入: 我们从字面意义上来解释一下:依赖代表着两个或者多个对象之间存在某些特定的联系:举一个不是很恰当的例子 比如说一度夫妻组成 ...
- centos 虚拟机桥接
/etc/sysconfig/network-scripts/ifcfg-eth0 配置文件 vi ifcfg-eth0 DEVICE=eth0HWADDR=00:0C:29:B8:B5:65TYPE ...