使用JAX构建强化学习agent并借助TensorFlowLite将其部署到Android应用中

- Flaxhttps://flax.readthedocs.io/
- JAXhttps://jax.readthedocs.io/
- tensorflow/exampleshttps://github.com/tensorflow/examples/blob/master/lite/examples/reinforcement_learning/ml/tf_and_jax/training_jax.py
简单回顾一下游戏规则: 我们基于强化学习 agent 需要根据真人玩家棋盘位置预测击打位置,以便能早于真人玩家完成游戏。如需进一步了解游戏规则,请参阅我们之前发布文章。

JAX 是一个与 NumPy 类似内容库,由 Google Research 部门专为实现高性能计算而开发。JAX 使用 XLA 针对 GPU 和 TPU 优化程序进行编译。
- JAXhttps://github.com/google/jax
- XLAhttps://tensorflow.google.cn/xla
- TPUhttps://cloud.google.com/tpu
而 Flax 则是在 JAX 基础上构建一款热门神经网络库。研究人员一直在使用 JAX/Flax 来训练包含数亿万个参数超大模型 (如用于语言理解和生成 PaLM,或者用于图像生成 Imagen),以便充分利用现代硬件。
- Flaxhttps://github.com/google/flax
- PaLMhttps://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html
- Imagenhttps://imagen.research.google/
如果您不熟悉 JAX 和 Flax,可以先从 JAX 101 教程和 Flax 入门示例开始。
- JAX 101 教程https://jax.readthedocs.io/en/latest/jax-101/index.html
- Flax 入门示例https://flax.readthedocs.io/en/latest/getting_started.html
2015 年底,TensorFlow 作为 Machine Learning (ML) 内容库问世,现已发展为一个丰富生态系统,其中包含用于实现 ML 流水线生产化 (TFX)、数据可视化 (TensorBoard),和将 ML 模型部署到边缘设备 (TensorFlow Lite) 工具,以及在网络浏览器上运行装置,或能够执行 JavaScript (TensorFlow.js) 任何装置。
- TFXhttps://tensorflow.google.cn/tfx
- TensorBoardhttps://tensorboard.dev/
- TensorFlow Litehttps://tensorflow.google.cn/lite
- TensorFlow.jshttps://tensorflow.google.cn/js
在 JAX 或 Flax 中开发模型也可以利用这一丰富生态系统。方法是首先将此类模型转换为 TensorFlow SavedModel 格式,然后使用与它们在 TensorFlow 中原生开发相同工具。
- SavedModelhttps://tensorflow.google.cn/guide/saved_model
如果您已经拥有经 JAX 训练模型并希望立即进行部署,我们整合了一份资源列表供您参考:
- 频 “使用 TensorFlow Serving 为 JAX 模型提供服务”,展示了如何使用 TensorFlow Serving 部署 JAX 模型:
- 文章《借助 TensorFlow.js 在网络上使用 JAX》,对如何将 JAX 模型转换为 TFJS,并在网络应用中运行进行了详细讲解:
https://blog.tensorflow.org/2022/08/jax-on-web-with-tensorflowjs.html
- 本篇文章演示了如何将 Flax/JAX 模型转换为 TFLite,并在原生 Android 应用中运行该模型。
总而言之,无论您部署目标是服务器、网络还是移动设备,我们都会为您提供相应帮助。使用 Flax/JAX 实现游戏 agent
将目光转回到棋盘游戏。为了实现强化学习 agent,我们将会利用与之前相同 OpenAI gym 环境。这次,我们将使用 Flax/JAX 训练相同策略梯度模型。回想一下,在数学层面上策略梯度定义是: 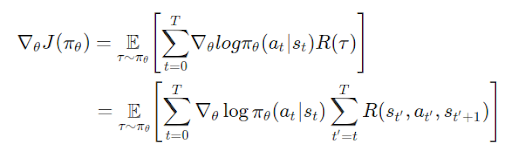
- OpenAI gymhttps://github.com/tensorflow/examples/tree/master/lite/examples/reinforcement_learning/ml/tf_and_jax/gym_planestrike/gym_planestrike/envs
其中:
- T: 每段时步数,各段时步数可能有所不同
- st: 时步上状态 t
- at: 时步上所选操作 t 指定状态 s
- πθ: 参数为 θ 策略
- R(*): 在指定策略下,收集到奖励
我们定义了一个 3 层 MLP 作为策略网络,该网络可以预测 agent 下一个击打位置。 class PolicyGradient(nn.Module):
“””Neural network to predict the next strike position.”””
@nn.compact
def __call__(self, x):
dtype = jnp.float32
x = x.reshape((x.shape[0], -1))
x = nn.Dense(
features=2 * common.BOARD_SIZE**2, name=’hidden1′, dtype=dtype)(
x)
x = nn.relu(x)
x = nn.Dense(features=common.BOARD_SIZE**2, name=’hidden2′, dtype=dtype)(x)
x = nn.relu(x)
x = nn.Dense(features=common.BOARD_SIZE**2, name=’logits’, dtype=dtype)(x)
policy_probabilities = nn.softmax(x)
return policy_probabilities
在我们训练循环每次迭代中,我们都会使用神经网络玩一局游戏、收集轨迹信息 (游戏棋盘位置、采取操作和奖励)、对奖励进行折扣,然后使用相应轨迹训练模型。for i in tqdm(range(iterations)):
predict_fn = functools.partial(run_inference, params)
board_log, action_log, result_log = common.play_game(predict_fn)
rewards = common.compute_rewards(result_log)
optimizer, params, opt_state = train_step(optimizer, params, opt_state,
board_log, action_log, rewards)在 train_step() 方法中,我们首先会使用轨迹计算损失,然后使用 jax.grad() 计算梯度,最后,使用 Optax (用于 JAX 梯度处理和优化库) 来更新模型参数。def compute_loss(logits, labels, rewards):
one_hot_labels = jax.nn.one_hot(labels, num_classes=common.BOARD_SIZE**2)
loss = -jnp.mean(
jnp.sum(one_hot_labels * jnp.log(logits), axis=-1) * jnp.asarray(rewards))
return loss
def train_step(model_optimizer, params, opt_state, game_board_log,
predicted_action_log, action_result_log):
“””Run one training step.”””
def loss_fn(model_params):
logits = run_inference(model_params, game_board_log)
loss = compute_loss(logits, predicted_action_log, action_result_log)
return loss
def compute_grads(params):
return jax.grad(loss_fn)(params)
grads = compute_grads(params)
updates, opt_state = model_optimizer.update(grads, opt_state)
params = optax.apply_updates(params, updates)
return model_optimizer, params, opt_state
@jax.jit
def run_inference(model_params, board):
logits = PolicyGradient().apply({‘params’: model_params}, board)
return logits
- Optaxhttps://github.com/deepmind/optax
这就是训练循环。如下图所示,我们可以在 TensorBoard 中观察训练进度;其中,我们使代理指标 “game_length” (完成游戏所需步骤数) 来跟踪进度: 若 agent 变得更聪明,它便能以更少步骤完成游戏。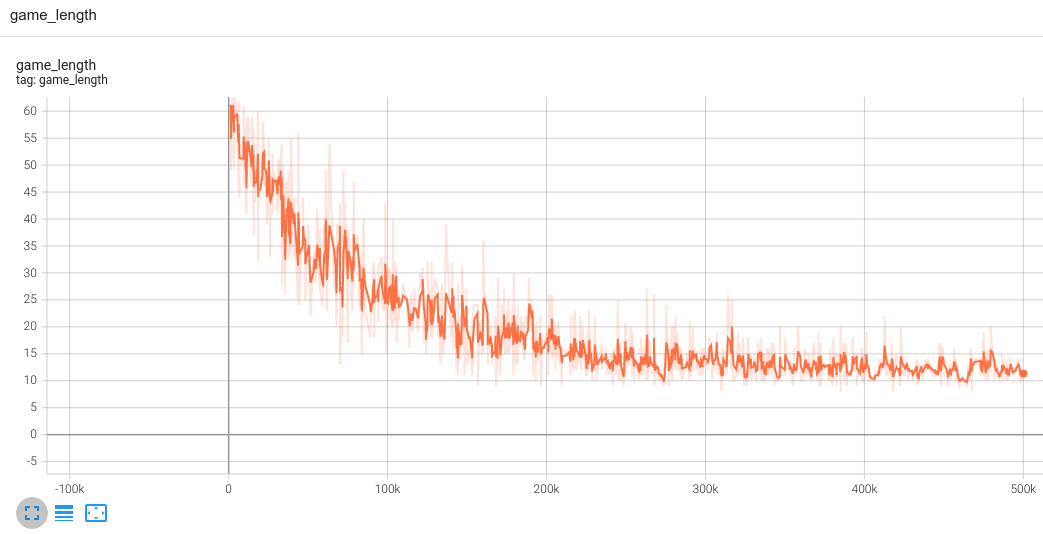 将 Flax/JAX 模型转换为 TensorFlow Lite 并与 Android 应用集成
将 Flax/JAX 模型转换为 TensorFlow Lite 并与 Android 应用集成
完成模型训练后,我们使用 jax2tf (一款 TensorFlow-JAX 互操作工具),将 JAX 模型转换为
TensorFlow concrete function。最后一步是调用 TensorFlow Lite 转换器来将 concrete
function 转换为 TFLite 模型。
# Convert to tflite model
model = PolicyGradient()
jax_predict_fn = lambda input: model.apply({‘params’: params}, input)
if_predict = tf.function(
jax2tf.convert(jax_predict_fn, enable_xla=False),
input_signature=[
tf.TensorSpec(
shape=[1, common.BOARD_SIZE, common.BOARD_SIZE],
dtype=tf.float32,
name=’input’)
],
autograph=False,
)
converter = tf.lite.TFLiteConverter.from_concrete_functions(
[tf_predict.get_concrete_function()], tf_predict)
tflite_model = converter.convert()
# Save the model
with open(os.path.join(modeldir, ‘planestrike.tflite’), ‘wb’) as f:
f.write(tflite_model)
- jax2tf
https://github.com/google/jax/tree/main/jax/experimental/jax2tf
经 JAX 转换 TFLite 模型与任何经 TensorFlow 训练 TFLite 模型会有完全一致行为。您可以使用 Netron 进行可视化:

我们可以使用与之前完全一样 Java 代码来调用模型并获取预测结果。
convertBoardStateToByteBuffer(board);
tflite.run(boardData, outputProbArrays);
float[] probArray = outputProbArrays[0];
int agentStrikePosition = -1;
float maxProb = 0;
for (int i = 0; i < probArray.length; i++) {
int x = i / Constants.BOARD_SIZE;
int y = i % Constants.BOARD_SIZE;
if (board[x][y] == BoardCellStatus.UNTRIED && probArray[i] > maxProb) {
agentStrikePosition = i;
maxProb = probArray[i];
}
}
总结
本文详细介绍了如何使用 Flax/JAX 训练简单强化学习模型、利用 jax2tf 将其转换为 TensorFlow Lite,以及将转换后模型集成到 Android 应用。
现在,您已经了解了如何使用 Flax/JAX 构建神经网络模型,以及如何利用强大 TensorFlow 生态系统,在几乎任何您想要位置部署模型。我们十分期待看到您使用 JAX 和 TensorFlow 构建出色应用!
使用JAX构建强化学习agent并借助TensorFlowLite将其部署到Android应用中的更多相关文章
- 【Shell学习笔记3》实践项目自动部署脚本】shell中获取返回值、获取当前sh文件路径
原创部分: 1.获取返回值 #This is a shell to Deploy Project #!/bin/bashcheck_results=`ps -ef | grep "java& ...
- 强化学习之七:Visualizing an Agent’s Thoughts and Actions
本文是对Arthur Juliani在Medium平台发布的强化学习系列教程的个人中文翻译,该翻译是基于个人分享知识的目的进行的,欢迎交流!(This article is my personal t ...
- 基于Keras的OpenAI-gym强化学习的车杆/FlappyBird游戏
强化学习 课程:Q-Learning强化学习(李宏毅).深度强化学习 强化学习是一种允许你创造能从环境中交互学习的AI Agent的机器学习算法,其通过试错来学习.如上图所示,大脑代表AI Agent ...
- David Silver强化学习Lecture3:动态规划
课件:Lecture 3: Planning by Dynamic Programming 视频:David Silver强化学习第3课 - 动态规划(中文字幕) 动态规划 动态(Dynamic): ...
- 强化学习(Reinforcement Learning)中的Q-Learning、DQN,面试看这篇就够了!
1. 什么是强化学习 其他许多机器学习算法中学习器都是学得怎样做,而强化学习(Reinforcement Learning, RL)是在尝试的过程中学习到在特定的情境下选择哪种行动可以得到最大的回报. ...
- 论文:利用深度强化学习模型定位新物体(VISUAL SEMANTIC NAVIGATION USING SCENE PRIORS)
这是一篇被ICLR 2019 接收的论文.论文讨论了如何利用场景先验知识 (scene priors)来定位一个新场景(novel scene)中未曾见过的物体(unseen objects).举例来 ...
- 强化学习之六:Deep Q-Network and Beyond
本文是对Arthur Juliani在Medium平台发布的强化学习系列教程的个人中文翻译,该翻译是基于个人分享知识的目的进行的,欢迎交流!(This article is my personal t ...
- 强化学习之五:基于模型的强化学习(Model-based RL)
本文是对Arthur Juliani在Medium平台发布的强化学习系列教程的个人中文翻译,该翻译是基于个人分享知识的目的进行的,欢迎交流!(This article is my personal t ...
- 强化学习之四:基于策略的Agents (Policy-based Agents)
本文是对Arthur Juliani在Medium平台发布的强化学习系列教程的个人中文翻译,该翻译是基于个人分享知识的目的进行的,欢迎交流!(This article is my personal t ...
- 强化学习之三点五:上下文赌博机(Contextual Bandits)
本文是对Arthur Juliani在Medium平台发布的强化学习系列教程的个人中文翻译,该翻译是基于个人分享知识的目的进行的,欢迎交流!(This article is my personal t ...
随机推荐
- cc1
基础 cc接口及类介绍 Transformer接口 Defines a functor interface implemented by classes that transform one obje ...
- 7. C语言科学计数法表示int
c语言10的n次方写用e表示: 比如int a=10e2 表示10*10的2次方=1000: 注意:10e6, 代表10*10^6 不代表10^6. 10^6为1^6
- Java基础之基本运算符
基本运算符 算数运算符:+.-.*./.%.++.-- 赋值运算符:= 关系运算符:>.<.>=.<=.==.!= instanceof 逻辑运算符:&&.|| ...
- 学习canvas的vscode提示问题
在代码中加入/** @type {HTMLCanvasElement} */ 即可 1 <script> 2 /** @type {HTMLCanvasElement} */ 3 let ...
- 小程序中使用less
小程序中使用Less 原生小程序不支持less,其他基于小程序的框架大体都支持,如wepy,mpvue,taro等.但是仅仅因为一个less功能,而且引入一个框架,肯定是不可取的.因此可以用以下方式来 ...
- 044_Schedule Job 间隔时间自动执行
需求:系统上的标准功能是能够设置间隔一天的执行,或者是写完代码着急测试我们写个5分钟后执行的: 但是遇到要求没间隔一小时或者十分钟执行,该怎么处理呢? global class **_Retrieve ...
- fail-fast简介
转载请注明出处:http://www.cnblogs.com/skywang12345/p/3308762.html fail-fast简介(使用concurrentHashMap可以完美避免这个问题 ...
- uniapp使用rich-text内容过长在真机无法滚动
解决方案:在rich-text标签上加scroll-view解决 <scroll-view scroll-y="true" style="height: 745rp ...
- 使用vite创建vue3+ts项目完整流程
1.创建项目 npm init vite@latest 依次输入项目名称.选择vue.选择ts 2.引入依赖 cd 项目名称 npm install 3.启动项目 npm run dev 4.引入vu ...
- 夜神模拟器连接不上adb的解决办法
1.夜神模拟器连接不上adb的解决办法 转自 (https://www.jianshu.com/p/6041e64518a8) 最近给模拟器升级了版本,用了一段时间后,突然发现通过adb device ...