Python3 Scrapy 框架学习
1.安装scrapy 框架
windows 打开cmd输入
pip install Scrapy2.新建一个项目:
比如这里我新建的项目名为first
scrapy startproject first然后看一些目录结构
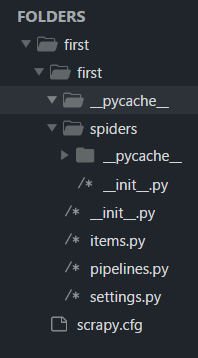
首先在项目目录下有一个scrapy.cfg 文件,这个文件是关于整个项目的一些配置,这个具体后面再说
然后是一个项目同名的文件夹,里面具体文件作用如下:
__init__.py 初始化信息
items.py 作为爬虫项目的数据容器文件,主要用来定义我们要获取的数据
pipelines.py 爬虫项目的管道文件,主要用来对items 里面定义的数据进行进一步的加工处理
settings.py 文件为爬虫项目的设置文件,主要为爬虫项目的一些设置信息
然后下一层的spiders 文件夹里面放置一些爬虫,当然现在里面什么都没有,因为我们还没有新建一个爬虫
这里介绍一下全局命令 和项目 命令
全局命令:不在scrapy项目里就可以使用的命令
项目命令:必须在scrapy项目中才可以使用的命令
全局命令:
注意网址一定要加上http://
fetch : scrapy fetch 网址(不显示调试信息可以加 --nolog 参数)
runspider: scrapy runspider 爬虫(现在项目中没有爬虫,后面具体再讲)
settings:scrapy settings --get 配置项(后面具体再讲)
shell:scrapy shell 网址(在shell终端里面处理爬下来的数据)
view:scrapy view 网址 (将网址数据趴下来并在浏览器中打开)
项目命令:
bench:scrapy bench(测试本地硬件的性能)
genspider:scrapy genspider 爬虫的文件名 定义爬取的域名(scrapy genspider baidu baidu.com)
另外:
-l :查看可以使用的模板 (scrapy genspider -l)
-d:查看模板内容 (scrapy genspider -d basic)
-t:使用模板 (scrapy genspider -t basic 爬虫名 定义爬取的域名)
check:scrapy check 爬虫名(使用合同contract的方式对爬虫进行测试)
crawl:scrapy crawl 爬虫名(启动爬虫,不显示调试信息可以加--nolog参数)
list:scrapy list(显示项目中有哪些爬虫)
edit (这个命令在windows上用不了所以我就不介绍了)
持续更新。。。。。。。。。
Python3 Scrapy 框架学习的更多相关文章
- 自己的Scrapy框架学习之路
开始自己的Scrapy 框架学习之路. 一.Scrapy安装介绍 参考网上资料,先进行安装 使用pip来安装Scrapy 在开始菜单打开cmd命令行窗口执行如下命令即可 pip install Scr ...
- scrapy框架学习之路
一.基础学习 - scrapy框架 介绍:大而全的爬虫组件. 安装: - Win: 下载:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted pip3 ...
- Scrapy框架学习 - 使用内置的ImagesPipeline下载图片
需求分析需求:爬取斗鱼主播图片,并下载到本地 思路: 使用Fiddler抓包工具,抓取斗鱼手机APP中的接口使用Scrapy框架的ImagesPipeline实现图片下载ImagesPipeline实 ...
- Scrapy框架学习笔记
1.Scrapy简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网 ...
- Scrapy框架学习(一)Scrapy框架介绍
Scrapy框架的架构图如上. Scrapy中的数据流由引擎控制,数据流的过程如下: 1.Engine打开一个网站,找到处理该网站的Spider,并向该Spider请求第一个要爬取得URL. 2.En ...
- scrapy框架学习
一.初窥Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了 页面抓取 (更确切来说, 网 ...
- Scrapy框架学习参考资料
00.Python网络爬虫第三弹<爬取get请求的页面数据> 01.jupyter环境安装 02.Python网络爬虫第二弹<http和https协议> 03.Python网络 ...
- scrapy框架学习第一天
今天是学习的第一天: 知识总结如下: 1,调试器相当于原料出口地(URL提供) 2,scrapy相当于中间加工商(具有销售权利)封装URL为request(请求) 3,下载器使用request(请求) ...
- Scrapy框架学习(三)Spider、Downloader Middleware、Spider Middleware、Item Pipeline的用法
Spider有以下属性: Spider属性 name 爬虫名称,定义Spider名字的字符串,必须是唯一的.常见的命名方法是以爬取网站的域名来命名,比如爬取baidu.com,那就将Spider的名字 ...
- Scrapy 框架 (学习笔记-1)
环境: 1.windows 10 2.Python 3.7 3.Scrapy 1.7.3 4.mysql 5.5.53 一.Scrapy 安装 1. Scrapy:是一套基于Twisted的一部处理框 ...
随机推荐
- Elasticsearch高级检索之使用单个字母数字进行分词N-gram tokenizer(不区分大小写)【实战篇】
一.前言 小编最近在做到一个检索相关的需求,要求按照一个字段的每个字母或者数字进行检索,如果是不设置分词规则的话,英文是按照单词来进行分词的. 小编以7.6.0版本做的功能哈,大家可以根据自己的版本去 ...
- 输入法词库解析(七)微软用户自定义短语.dat
详细代码:https://github.com/cxcn/dtool 前言 微软拼音和微软五笔通用的用户自定义短语 dat 格式. 解析 前 8 个字节标识文件格式 machxudp,微软五笔的 le ...
- 【原创】FFMPEG录屏入门指南
下载ffmpeg 点击 ffmpeg官网,选择windows,然后点击Windows builds from gyan.dev: 也可以直接点击 https://www.gyan.dev/ffmpeg ...
- 【项目实战】CNN手写识别复杂模型的构造
感谢视频教程:https://www.bilibili.com/video/BV1Y7411d7Ys?p=11 这里开一篇新博客不仅仅是因为教程视频单独出了1p,也是因为这是一种代码编写的套路,特在此 ...
- ProxySQL 配置ProxySQL
转载自:https://www.jianshu.com/p/212397a1be67 假定你已经对ProxySQL的架构有所了解.本文对ProxySQL的所有配置都是使用Admin管理接口完成的,该管 ...
- kvm安装windows使用virtio驱动下载地址
https://dl.fedoraproject.org/pub/alt/virtio-win/latest/images/bin/deprecated-README 老版本下载地址:https:// ...
- Prometheus中使用的告警规则
参考网站:https://awesome-prometheus-alerts.grep.to/rules 这个网站上有好多常用软件的告警规则,但是有些并不一定实用,有些使用起来会有错误,这里就把这些都 ...
- PostgreSQL 删除表格
PostgreSQL 使用 DROP TABLE 语句来删除表格,包含表格数据.规则.触发器等,所以删除表格要慎重,删除后所有信息就消失了. 语法 DROP TABLE 语法格式如下: DROP TA ...
- NSIS使用API创建工具提示条和超级链接
不再借助专用插件创建超级链接和工具提示条 !includensDialogs.nsh #编写:水晶石 Name "link_tooltips" OutFile "link ...
- Linux根据时间过滤文件
1.显示20分钟前的文件: find /sdb1/apache-tomcat-show/logs/ -type f -mmin +20 -exec ls -l {} \; 2.删除20分钟 ...