记一次spark数据倾斜实践
参考文章:
大数据项目——倾斜数据的分区优化
数据倾斜概念
什么是数据倾斜
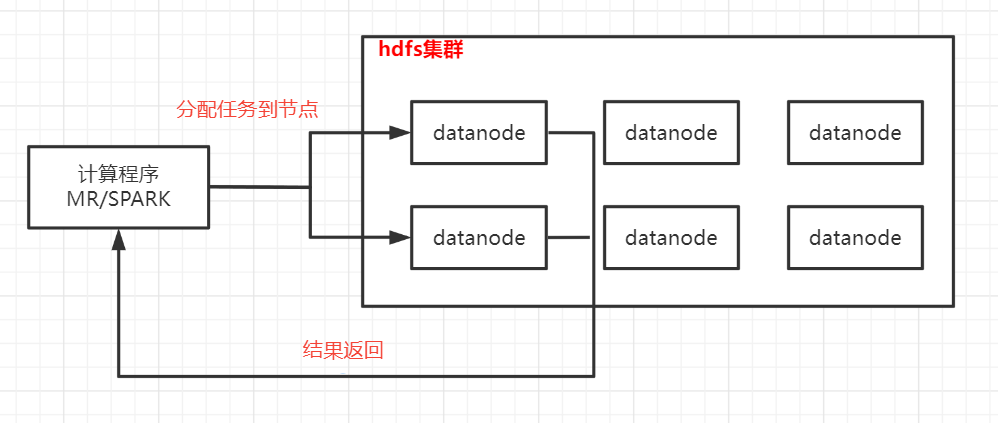
大数据下大部分框架的处理原理都是参考mapreduce的思想:分而治之和移动计算,即提前将计算程序生成好然后发送到不同的节点起jvm进程执行任务,每个任务处理一小部分数据,最终将每个任务的处理结果汇总,完成一次计算。
如果在分配任务的时候,数据分配不均,导致一个任务要处理的数据量远远大于其他任务,那么整个作业一直在等待这个任务完成,而其他机器的资源完全没利用起来,导致效率极差;如果数据量过大,可能发生倾斜的任务会出现OOM(内存溢出)的异常,使得整个作业失败。因此对于数据倾斜要能改则改
案例现象
案例为日志数据,已做清洗,字段如第一行,重点字段是client_ip和target_ip,需求是求不同target_ip的UV。
实现方式大致是:
1.读取文件,按,切分取2个目标字段client_ip和target_ip
2.按target_ip分组,汇总所有client_ip到一个列表
3.对client_ip列表统计去重数量,输出 <target_ip,UV>
因为是倾斜案例,在1中可以过滤出几个样例ip模拟倾斜场景。

代码
package skew
import org.apache.spark.{SparkConf, SparkContext}
import java.util
object SkewSample {
def main(args: Array[String]): Unit = {
skew1()
}
def skew1():Unit = {
// val conf = new SparkConf().setAppName("DataSkewTest01").setMaster("local[4]")
val conf = new SparkConf().setAppName("DataSkewTest01")
val spark = new SparkContext(conf)
val rawRDD = spark.textFile("/root/data/skewdata.csv")//读取数据源
/**筛选满足需要的数据,已到达数据倾斜的目的*/
val filteredRDD = rawRDD.filter(line => {
val array = line.split(",")
val target_ip = array(3)
target_ip.equals("106.38.176.185") || target_ip.equals("106.38.176.117") || target_ip.equals("106.38.176.118") || target_ip.equals("106.38.176.116")
})
/**根据目的ip进行汇总,将访问同一个目的ip的所有客户端ip进行汇总*/
val reducedRDD = filteredRDD.map(line => {
val array = line.split(",")
val target_ip = array(3)
val client_ip = array(0)
val index = client_ip.lastIndexOf(".")
val subClientIP = client_ip.substring(0, index) //为了让后续聚合后的value数据量尽可能的少,只取ip的前段部分
(target_ip,Array(subClientIP))
}).reduceByKey(_++_,4)//将Array中的元素进行合并,然后将分区调整为已知的4个
//reducedRDD.foreach(x => println(x._1, x._2.length)) //查看倾斜key
/**将访问同一个目的ip的客户端,再次根据客户端ip进行进一步统计*/
val targetRDD = reducedRDD.map(kv => {
val map = new util.HashMap[String,Int]()
val target_ip = kv._1
val clientIPArray = kv._2
clientIPArray.foreach(clientIP => {
if (map.containsKey(clientIP)) {
val sum = map.get(clientIP) + 1
map.put(clientIP,sum)
}
else map.put(clientIP,1)
})
(target_ip,map)
})
targetRDD.foreach(x => println(x._1, x._2.size()))
// targetRDD.saveAsTextFile("tmp/DataSkew01") //结果数据保存目录
// Thread.sleep(600000)
}
}
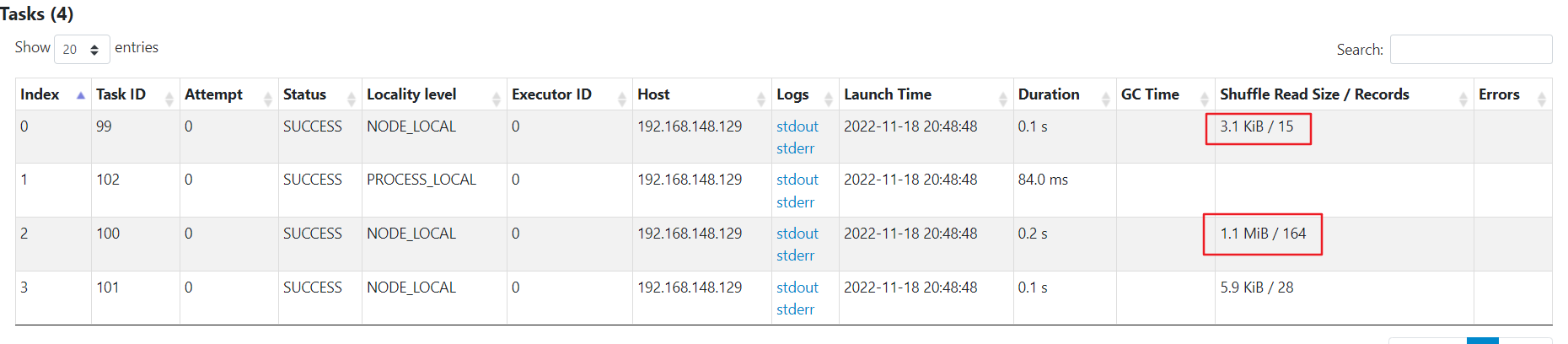
倾斜现象
因为数据量小,所以没有执行很长的时间,但是可以看到有一个任务处理的数据量是其他的百倍左右。
问题分析
案例中最终的分区数量,以及分区键,还有倾斜键都是一个确定的值,因此可以考虑两种优化方式:
单独处理:案例只有一个倾斜键,可以考虑将这个倾斜键和非倾斜键的数据过滤到2个RDD中,单独处理。这种方式会生成2个JOB,读两次源数据,虽然可以用缓存来提速,但是数据量大了以后缓存也是要落盘的,所以不是特别好
加盐减盐:对于倾斜键进行加盐,即在倾斜键本身后加上0-100的数字,改变它的hash值以便将数据分散到不同的分区中,然后对结果进行聚合,这样可以显著改善倾斜情况,最终还要对加盐的数据进行去盐,即将倾斜键后面的0-100数字去掉,然后再一次汇总,得到最终结果。 实践的时候又可以将去盐分为两步由100->10,10->1这样,降低数据波动,后续有一次去盐和二次去盐的结果对比。
优化结果对比
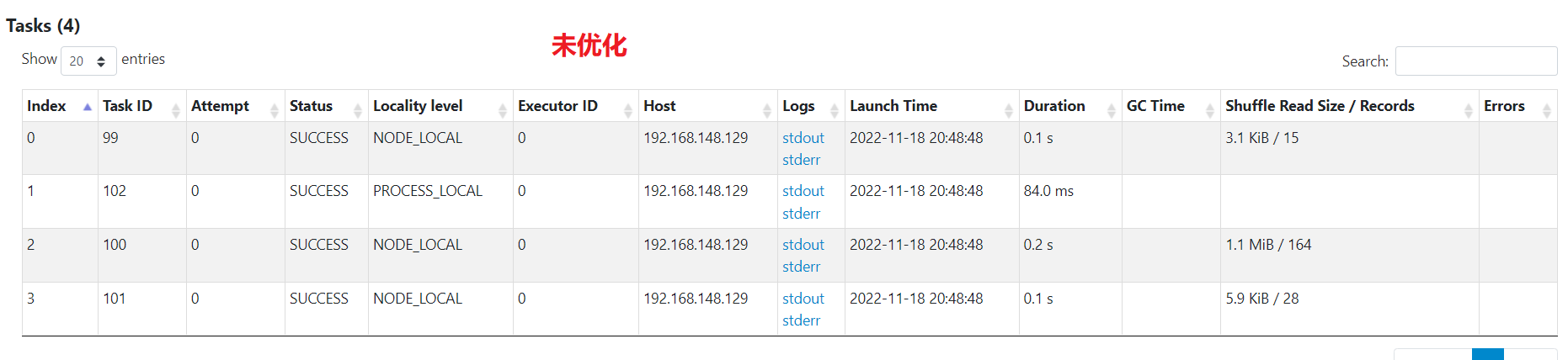
未优化
单个任务处理的最大数据量为1M
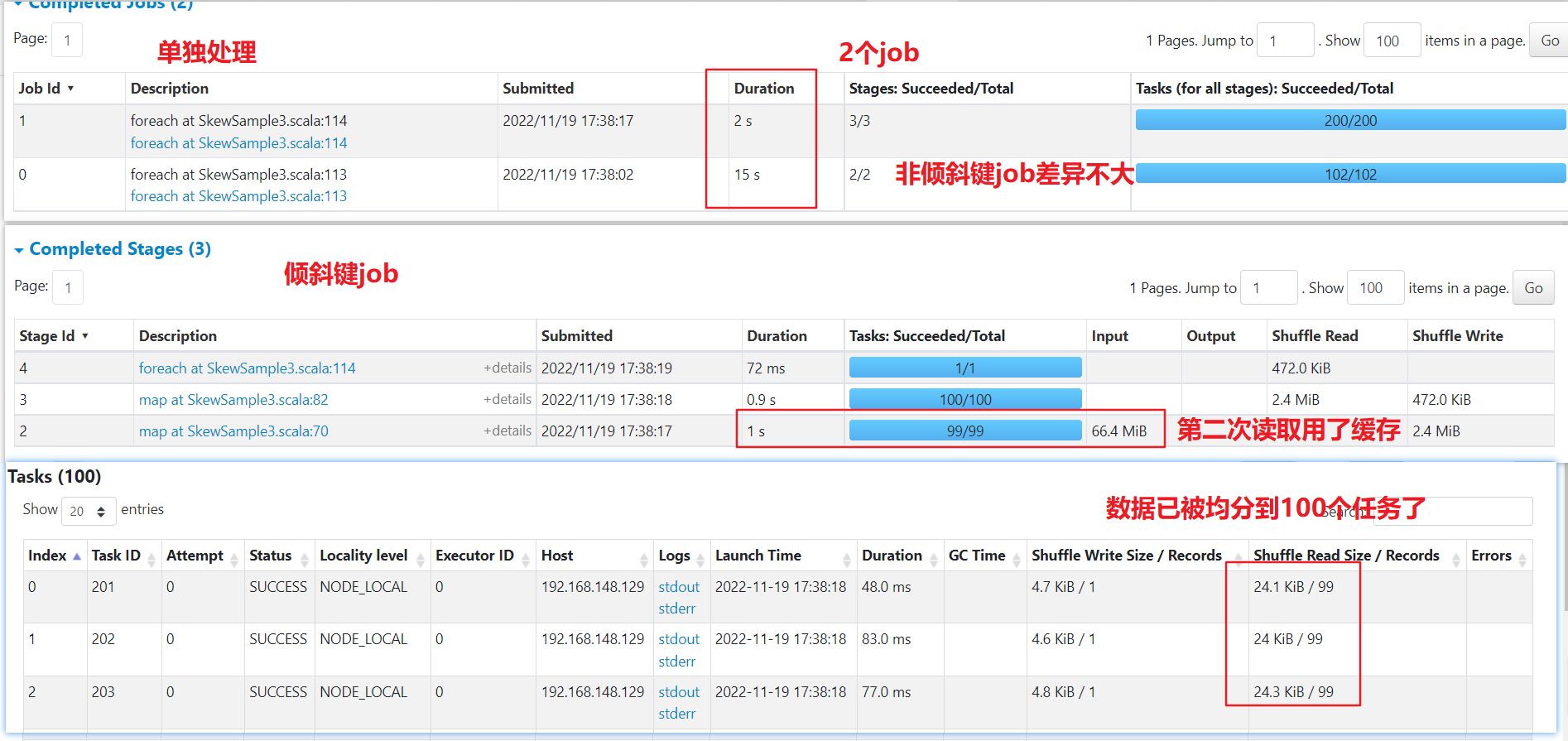
单独处理
可以看到spark起了2个job来处理,倾斜键的job已经将数据均匀分散到多个任务了。如果数据量很大,即使用了缓存,效果也不一定好,可能还更差。
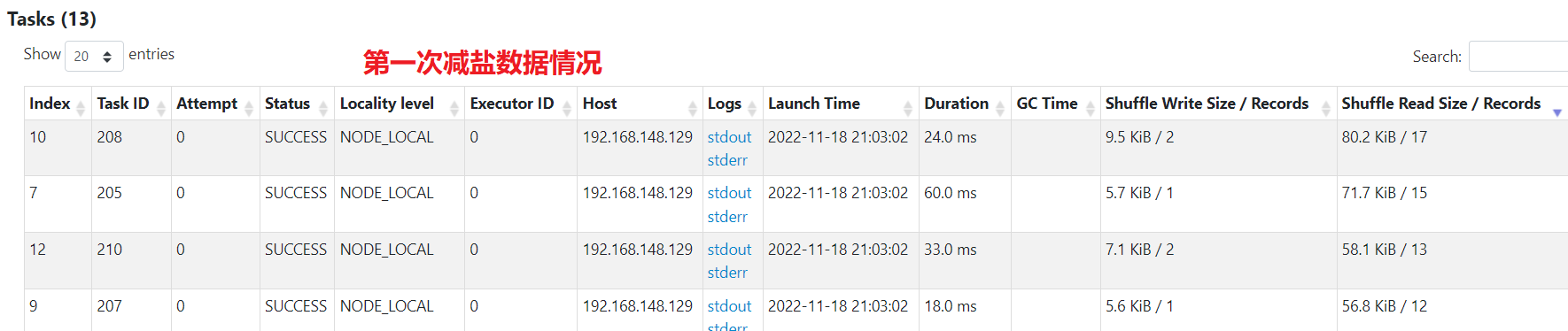
一次减盐
数据已经被均分到多个任务,不再倾斜。不过最后汇总还是单个任务汇总,处理的最大数据量为400kb
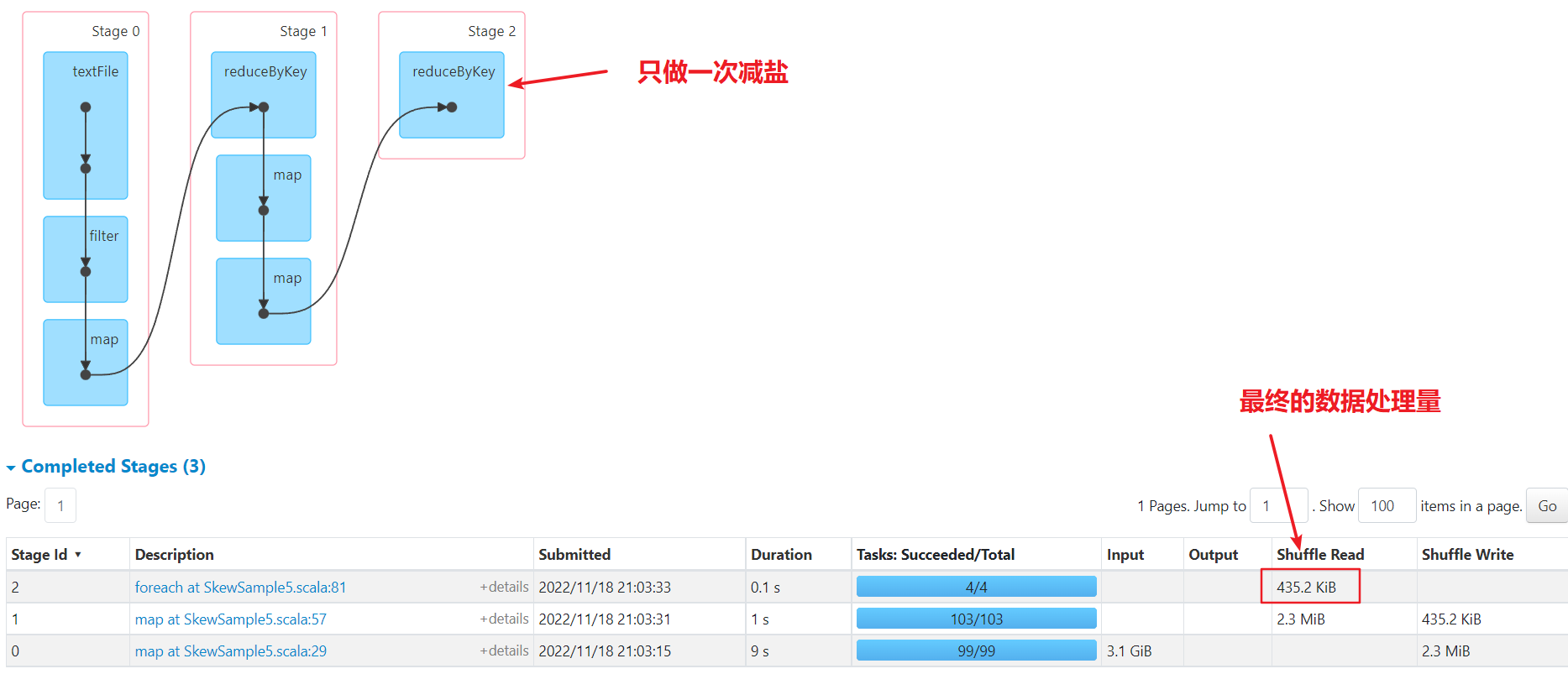
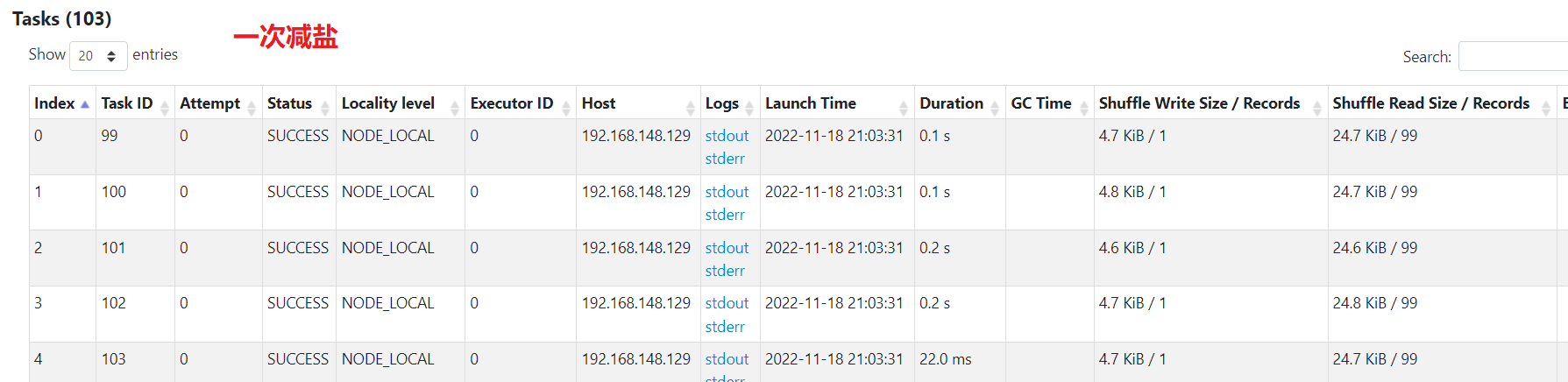
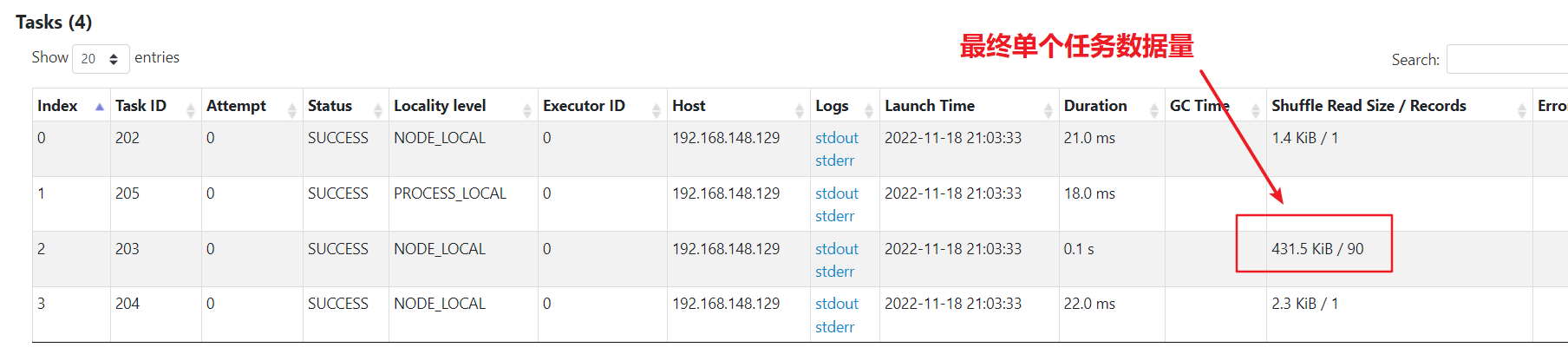
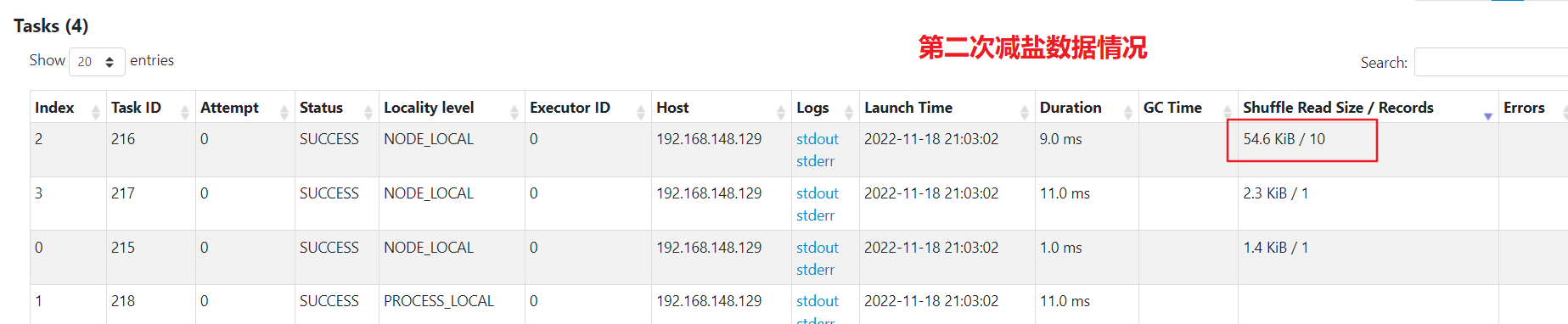
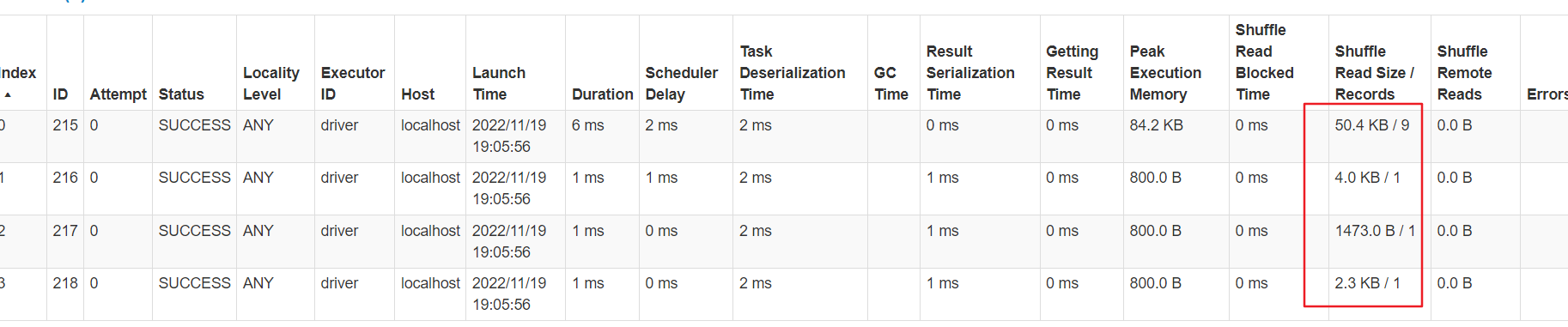
二次减盐
数据已经被均分到多个任务,不再倾斜。比一次减盐多了一次shuffle,最后单个任务汇总处理的最大数据量为50kb,比较均匀
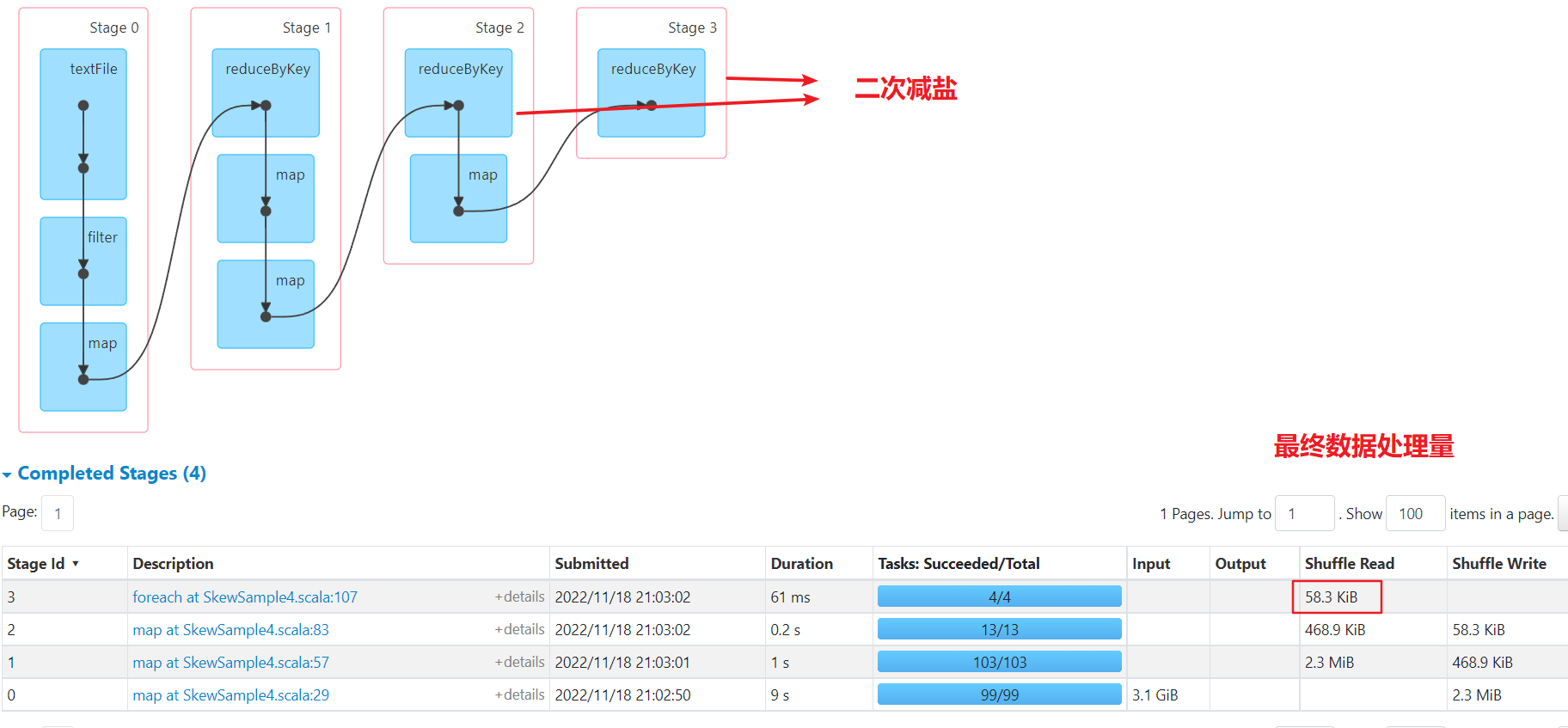
综合对比
综合来看,
- 单独处理:其实原理和加盐减盐也差不多,都是将倾斜键想办法分配到多个任务。但是要多一个job,感觉使用的场景会比较少
- 一次减盐:shuffle次数少,如果汇总计算是简单计算,最后结果数据量小,则性能较好
- 二次减盐:shuffle次数多了一次,但是整体每个任务处理的数据量都比较均匀,如果汇总计算生成的结果比较复杂,建议多次减盐。
分区问题
可以看到最后的分区汇总时,4个任务里有1个任务在空转,没有处理数据,这是因为默认shuffle时是按 HashPartitioner来进行分区,原理是取 key的hashcode然后对分区数量取模:
key.hashCode % numPartition = 对应的最终分区

解决思路
根据key特性进行分区:公众号文章中的方式比较取巧,最终4个key是ip,最后一位数字不同,且最后一位数模4结果都不同,因此可以用这种方式创建自定义分区器处理
提前取出去重后的所有key,做好到分区的映射,然后将映射传入到自定义分区器中使用。优点是可以完全按自己需求来分区,缺点也是有两个job
利用分布式锁:利用redis或者zk等组件做一把分布式锁,锁的value当做分区值,并缓存已有的key和分区映射,每个task取分区时先获取锁,然后判断是否在缓存内有对应分区,有则取出返回,无则将锁的value作为分区返回,并将此关系缓存,value加1。 优点是性能会比第二种方式好,但是需要引入新的组件,可能会有组件和并发问题。 因为我电脑没装redis和zk,直接用mysql的写锁作为分布式锁来实现了
最终代码
倾斜键单独处理
import org.apache.spark.{Partitioner, SparkConf, SparkContext}
import java.util
import java.util.Map.Entry
import scala.util.Random
object SkewSample3 {
def main(args: Array[String]): Unit = {
skew3()
}
/**
* 倾斜key单独拿出来跑
*/
def skew3():Unit = {
val conf = new SparkConf().setAppName("DataSkewTest03")
val spark = new SparkContext(conf)
val rawRDD = spark.textFile("/root/data/skewdata.csv")//读取数据源
/**筛选满足需要的数据,已到达数据倾斜的目的*/
val filteredRDD = rawRDD.filter(line => {
val array = line.split(",")
val target_ip = array(3)
target_ip.equals("106.38.176.185") || target_ip.equals("106.38.176.117") || target_ip.equals("106.38.176.118") || target_ip.equals("106.38.176.116")
})
filteredRDD.cache()
val normalKeyRDD = filteredRDD.filter(line => {
val array = line.split(",")
val target_ip = array(3)
target_ip.equals("106.38.176.117") || target_ip.equals("106.38.176.118") || target_ip.equals("106.38.176.116")
})
val skewKeyRDD = filteredRDD.filter(line => {
val array = line.split(",")
val target_ip = array(3)
target_ip.equals("106.38.176.185")
})
/**根据目的ip进行汇总,将访问同一个目的ip的所有客户端ip进行汇总*/
val reducedRDD1 = normalKeyRDD.map(line => {
val array = line.split(",")
val target_ip = array(3)
val client_ip = array(0)
val index = client_ip.lastIndexOf(".")
val subClientIP = client_ip.substring(0, index) //为了让后续聚合后的value数据量尽可能的少,只取ip的前段部分
(target_ip,Array(subClientIP))
}).reduceByKey(_++_,3)//将Array中的元素进行合并,然后将分区调整为已知的4个
//reducedRDD.foreach(x => println(x._1, x._2.length)) //查看倾斜key
/**将访问同一个目的ip的客户端,再次根据客户端ip进行进一步统计*/
val targetRDD1 = reducedRDD1.map(kv => {
val map = new util.HashMap[String,Int]()
val target_ip = kv._1
val clientIPArray = kv._2
clientIPArray.foreach(clientIP => {
if (map.containsKey(clientIP)) {
val sum = map.get(clientIP) + 1
map.put(clientIP,sum)
}
else map.put(clientIP,1)
})
(target_ip,map)
})
/**根据目的ip进行汇总,将访问同一个目的ip的所有客户端ip进行汇总*/
val reducedRDD2 = skewKeyRDD.map(line => {
val array = line.split(",")
val target_ip = array(3)
val client_ip = array(0)
val index = client_ip.lastIndexOf(".")
val subClientIP = client_ip.substring(0, index) //为了让后续聚合后的value数据量尽可能的少,只取ip的前段部分
(target_ip,Array(subClientIP))
}).reduceByKey(new MySkewPartitioner(100), _++_)// 将数据随机分配到100个分区中
//reducedRDD.foreach(x => println(x._1, x._2.length)) //查看倾斜key
/**将访问同一个目的ip的客户端,再次根据客户端ip进行进一步统计*/
val targetRDD2 = reducedRDD2.map(kv => {
val map = new util.HashMap[String,Int]()
val target_ip = kv._1
val clientIPArray = kv._2
clientIPArray.foreach(clientIP => {
if (map.containsKey(clientIP)) {
val sum = map.get(clientIP) + 1
map.put(clientIP,sum)
}
else map.put(clientIP,1)
})
(target_ip,map)
})
// 合并结果
val targetRDD3 = targetRDD2.reduceByKey((v1, v2) => {
val newMap = new util.HashMap[String,Int]()
newMap.putAll(v1)
val value: util.Iterator[Entry[String, Int]] = v2.entrySet().iterator()
while(value.hasNext){
val value1: Entry[String, Int] = value.next()
if (newMap.containsKey(value1.getKey)) {
val sum = newMap.get(value1.getKey) + value1.getValue
newMap.put(value1.getKey,sum)
} else {
newMap.put(value1.getKey, value1.getValue)
}
}
newMap
}, 1)
targetRDD1.foreach(x => println(x._1, x._2.size()))
targetRDD3.foreach(x => println(x._1, x._2.size()))
// targetRDD1.saveAsTextFile("tmp/DataSkew01") //结果数据保存目录
}
class MySkewPartitioner(partitions: Int) extends Partitioner{
override def numPartitions: Int = partitions
override def getPartition(key: Any): Int = {
Random.nextInt(partitions)
}
}
}
二次减盐
一次减盐不写了,去掉第一段减盐即可
import org.apache.spark.{SparkConf, SparkContext}
import java.util
import java.util.Map.Entry
import scala.util.Random
object SkewSample4 {
def main(args: Array[String]): Unit = {
skew4()
}
/**
* 倾斜key单独拿出来跑
*/
def skew4():Unit = {
val conf = new SparkConf().setAppName("DataSkewTest04")
val spark = new SparkContext(conf)
val rawRDD = spark.textFile("/root/data/skewdata.csv")//读取数据源
// val rawRDD = spark.textFile("D:\\BaiduNetdiskDownload\\尚硅谷\\上网DNS日志数据\\part-00000-7dc7257d-dd48-4e7f-9865-d7181c3c4c37-c000.csv")//读取数据源
/**筛选满足需要的数据,已到达数据倾斜的目的*/
val filteredRDD = rawRDD.filter(line => {
val array = line.split(",")
val target_ip = array(3)
target_ip.equals("106.38.176.185") || target_ip.equals("106.38.176.117") || target_ip.equals("106.38.176.118") || target_ip.equals("106.38.176.116")
})
val reducedRDD_01 = filteredRDD.map(line => {/**解决倾斜第一步:加盐操作将原本1个分区的数据扩大到100个分区*/
val array = line.split(",")
val target_ip = array(3)
val client_ip = array(0)
val index = client_ip.lastIndexOf(".")
val subClientIP = client_ip.substring(0, index)//为了让后续聚合后的value数据量尽可能的少,只取ip的前段部分
if (target_ip.equals("106.38.176.185")){/**针对特定倾斜的key进行加盐操作*/
val saltNum = 99 //将原来的1个key增加到100个key
val salt = new Random().nextInt(saltNum)
(target_ip + "-" + salt,Array(subClientIP))
}
else (target_ip,Array(subClientIP))
}).reduceByKey(_++_,103)//将Array中的元素进行合并,并确定分区数量
val targetRDD_01 = reducedRDD_01.map(kv => {/**第二步:将各个分区中的数据进行初步统计,减少单个分区中value的大小*/
val map = new util.HashMap[String,Int]()
val target_ip = kv._1
val clientIPArray = kv._2
clientIPArray.foreach(clientIP => {//对clientIP进行统计
if (map.containsKey(clientIP)) {
val sum = map.get(clientIP) + 1
map.put(clientIP,sum)
}
else map.put(clientIP,1)
})
(target_ip,map)
})
val reducedRDD_02 = targetRDD_01.map(kv => {/**第3步:对倾斜的数据进行减盐操作,将分区数从100减到10*/
val targetIPWithSalt01 = kv._1
val clientIPMap = kv._2
if (targetIPWithSalt01.startsWith("106.38.176.185")){
val targetIP = targetIPWithSalt01.split("-")(0)
val saltNum = 9 //将原来的100个分区减少到10个分区
val salt = new Random().nextInt(saltNum)
(targetIP + "-" + salt,clientIPMap)
}
else kv
}).reduceByKey((map1,map2) => { /**合并2个map中的元素,key相同则value值相加*/
//将map1和map2中的结果merge到map3中,相同的key,则value相加
val map3 = new util.HashMap[String,Int](map1)
val value: util.Iterator[Entry[String, Int]] = map2.entrySet().iterator()
while(value.hasNext){
val value1: Entry[String, Int] = value.next()
if (map3.containsKey(value1.getKey)) {
val sum = map3.get(value1.getKey) + value1.getValue
map3.put(value1.getKey,sum)
} else {
map3.put(value1.getKey, value1.getValue)
}
}
map3
},13)//调整分区数量
val finalRDD = reducedRDD_02.map(kv => {/**第4步:继续减盐,将原本10个分区数的数据恢复到1个*/
val targetIPWithSalt01 = kv._1
val clientIPMap = kv._2
if (targetIPWithSalt01.startsWith("106.38.176.185")){
val targetIP = targetIPWithSalt01.split("-")(0)
(targetIP,clientIPMap)//彻底将盐去掉
}
else kv
}).reduceByKey((map1,map2) => { /**合并2个map中的元素,key相同则value值相加*/
//将map1和map2中的结果merge到map3中,相同的key,则value相加
val map3 = new util.HashMap[String,Int](map1)
val value: util.Iterator[Entry[String, Int]] = map2.entrySet().iterator()
while(value.hasNext){
val value1: Entry[String, Int] = value.next()
if (map3.containsKey(value1.getKey)) {
val sum = map3.get(value1.getKey) + value1.getValue
map3.put(value1.getKey,sum)
} else {
map3.put(value1.getKey, value1.getValue)
}
}
map3
},4)//调整分区数量
finalRDD.foreach(x => println(x._1, x._2.size()))
// targetRDD1.saveAsTextFile("tmp/DataSkew01") //结果数据保存目录
}
}
自定义分区
package skew
import org.apache.spark.{Partitioner, SparkConf, SparkContext}
import org.spark_project.jetty.server.Connector
import org.spark_project.jetty.util.component.{Container, LifeCycle}
import java.sql.{Connection, DriverManager, ResultSet, Statement}
import java.util
import java.util.Map.Entry
import scala.util.Random
object SkewSample7 {
def main(args: Array[String]): Unit = {
skew4()
}
/**
* 倾斜key单独拿出来跑
*/
def skew4():Unit = {
val conf = new SparkConf().setAppName("DataSkewTest01").setMaster("local[4]")
val spark = new SparkContext(conf)
// val rawRDD = spark.textFile("/root/data/skewdata.csv")//读取数据源
val rawRDD = spark.textFile("D:\\BaiduNetdiskDownload\\尚硅谷\\上网DNS日志数据\\part-00000-7dc7257d-dd48-4e7f-9865-d7181c3c4c37-c000.csv")//读取数据源
/**筛选满足需要的数据,已到达数据倾斜的目的*/
val filteredRDD = rawRDD.filter(line => {
val array = line.split(",")
val target_ip = array(3)
target_ip.equals("106.38.176.185") || target_ip.equals("106.38.176.117") || target_ip.equals("106.38.176.118") || target_ip.equals("106.38.176.116")
})
val reducedRDD_01 = filteredRDD.map(line => {/**解决倾斜第一步:加盐操作将原本1个分区的数据扩大到100个分区*/
val array = line.split(",")
val target_ip = array(3)
val client_ip = array(0)
val index = client_ip.lastIndexOf(".")
val subClientIP = client_ip.substring(0, index)//为了让后续聚合后的value数据量尽可能的少,只取ip的前段部分
if (target_ip.equals("106.38.176.185")){/**针对特定倾斜的key进行加盐操作*/
val saltNum = 99 //将原来的1个key增加到100个key
val salt = new Random().nextInt(saltNum)
(target_ip + "-" + salt,Array(subClientIP))
}
else (target_ip,Array(subClientIP))
}).reduceByKey(_++_,103)//将Array中的元素进行合并,并确定分区数量
val targetRDD_01 = reducedRDD_01.map(kv => {/**第二步:将各个分区中的数据进行初步统计,减少单个分区中value的大小*/
val map = new util.HashMap[String,Int]()
val target_ip = kv._1
val clientIPArray = kv._2
clientIPArray.foreach(clientIP => {//对clientIP进行统计
if (map.containsKey(clientIP)) {
val sum = map.get(clientIP) + 1
map.put(clientIP,sum)
}
else map.put(clientIP,1)
})
(target_ip,map)
})
val reducedRDD_02 = targetRDD_01.map(kv => {/**第3步:对倾斜的数据进行减盐操作,将分区数从100减到10*/
val targetIPWithSalt01 = kv._1
val clientIPMap = kv._2
if (targetIPWithSalt01.startsWith("106.38.176.185")){
val targetIP = targetIPWithSalt01.split("-")(0)
val saltNum = 9 //将原来的100个分区减少到10个分区
val salt = new Random().nextInt(saltNum)
(targetIP + "-" + salt,clientIPMap)
}
else kv
}).reduceByKey((map1,map2) => { /**合并2个map中的元素,key相同则value值相加*/
//将map1和map2中的结果merge到map3中,相同的key,则value相加
val map3 = new util.HashMap[String,Int](map1)
val value: util.Iterator[Entry[String, Int]] = map2.entrySet().iterator()
while(value.hasNext){
val value1: Entry[String, Int] = value.next()
if (map3.containsKey(value1.getKey)) {
val sum = map3.get(value1.getKey) + value1.getValue
map3.put(value1.getKey,sum)
} else {
map3.put(value1.getKey, value1.getValue)
}
}
map3
},13)//调整分区数量
val reducedRDD_03 = reducedRDD_02.map(kv => {/**第4步:继续减盐,将原本10个分区数的数据恢复到1个*/
val targetIPWithSalt01 = kv._1
val clientIPMap = kv._2
if (targetIPWithSalt01.startsWith("106.38.176.185")){
val targetIP = targetIPWithSalt01.split("-")(0)
(targetIP,clientIPMap)//彻底将盐去掉
}
else kv
})
val finalRDD = reducedRDD_03.reduceByKey(new MyMapPartitioner(4), (map1,map2) => { /**合并2个map中的元素,key相同则value值相加*/
//将map1和map2中的结果merge到map3中,相同的key,则value相加
val map3 = new util.HashMap[String,Int](map1)
val value: util.Iterator[Entry[String, Int]] = map2.entrySet().iterator()
while(value.hasNext){
val value1: Entry[String, Int] = value.next()
if (map3.containsKey(value1.getKey)) {
val sum = map3.get(value1.getKey) + value1.getValue
map3.put(value1.getKey,sum)
} else {
map3.put(value1.getKey, value1.getValue)
}
}
map3
})//调整分区数量
println("asdfsd")
finalRDD.foreach(x => println(x._1, x._2.size()))
// targetRDD1.saveAsTextFile("tmp/DataSkew01") //结果数据保存目录
Thread.sleep(600000)
}
/**
* ip分区器
* @param keys
*/
class MyIpPartitioner(partitionNum: Int) extends Partitioner{
override def numPartitions: Int = partitionNum //确定总分区数量
override def getPartition(key: Any): Int = {//确定数据进入分区的具体策略
val keyStr = key.toString
val keyTag = keyStr.substring(keyStr.length - 1, keyStr.length)
keyTag.toInt % partitionNum
}
}
/**
* keys分区器
* @param keys
*/
class MyMapPartitioner(keys:Array[String]) extends Partitioner{
override def numPartitions: Int = keys.length
val partitionMap = new util.HashMap[String, Int]()
var pointer = 0
keys.foreach(k =>{
partitionMap.put(k, pointer)
pointer += 1
if(pointer == keys.length){
pointer = 0
}
})
println(partitionMap)
override def getPartition(key: Any): Int = {
println(key, "-", partitionMap.get(key))
partitionMap.get(key)
}
}
/**
* mysql分区器
* @param partitions
*/
class MyMapPartitioner(partitions:Int) extends Partitioner{
val jdbcURL = "jdbc:mysql://xxx.xxx.xxx.xxx:3306?zyk&useSSL=false"
val username = "test"
val password = "123456"
override def numPartitions: Int = partitions
override def getPartition(key: Any): Int = {
getPartitionByMysql(key)
}
/** ddl
CREATE TABLE `pointer` (
`pointer` int DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
INSERT INTO pointer VALUES (0);
CREATE TABLE `key_partition_map` (
`key_string` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`partition_index` tinyint DEFAULT NULL,
PRIMARY KEY (`key_string`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
*/
def getPartitionByMysql(key:Any):Int = {
var partition = 0
Class.forName("com.mysql.jdbc.Driver")
val conn: Connection = DriverManager.getConnection(jdbcURL, username, password)
// 开启事务
conn.setAutoCommit(false)
val statement: Statement = conn.createStatement()
// 用mysql的写锁作为分布式锁, pointer表用于当成锁,和递增的指针, key_partition_map表存储 key和分区的映射
val lock: ResultSet = statement.executeQuery("select pointer from zyk.pointer for update;")
lock.next()
partition = lock.getInt(1)
val map: ResultSet = statement.executeQuery("select partition_index from zyk.key_partition_map where key_string = '" + key + "';")
// 如果有结果则取对应映射,如果没有结果,则插入新增映射,并将指针加1
if(map.next()){
partition = map.getInt(1)
} else {
statement.execute("insert into zyk.key_partition_map values ('" + key + "', " + partition + ");")
partition += 1
if(partition == numPartitions) partition = 0
statement.executeUpdate("update zyk.pointer set pointer = " + partition + ";")
conn.commit()
}
conn.close()
println(key, "-", partition)
// 返回最终分区
partition
}
}
}
记一次spark数据倾斜实践的更多相关文章
- Spark性能优化之道——解决Spark数据倾斜(Data Skew)的N种姿势
原创文章,同步首发自作者个人博客转载请务必在文章开头处注明出处. 摘要 本文结合实例详细阐明了Spark数据倾斜的几种场景以及对应的解决方案,包括避免数据源倾斜,调整并行度,使用自定义Partitio ...
- Spark 数据倾斜
Spark 数据倾斜解决方案 2017年03月29日 17:09:58 阅读数:382 现象 当你的应用程序发生以下情况时你该考虑下数据倾斜的问题了: 绝大多数task都可以愉快的执行,总 ...
- Spark数据倾斜解决方案(转)
本文转发自技术世界,原文链接 http://www.jasongj.com/spark/skew/ Spark性能优化之道——解决Spark数据倾斜(Data Skew)的N种姿势 发表于 2017 ...
- spark数据倾斜处理
spark数据倾斜处理 危害: 当出现数据倾斜时,小量任务耗时远高于其它任务,从而使得整体耗时过大,未能充分发挥分布式系统的并行计算优势. 当发生数据倾斜时,部分任务处理的数据量过大,可能造成内存不足 ...
- spark 数据倾斜的一些表现
spark 数据倾斜的一些表现 https://yq.aliyun.com/articles/62541
- 最详细10招Spark数据倾斜调优
最详细10招Spark数据倾斜调优 数据量大并不可怕,可怕的是数据倾斜 . 数据倾斜发生的现象 绝大多数 task 执行得都非常快,但个别 task 执行极慢. 数据倾斜发生的原理 在进行 shuff ...
- Spark数据倾斜解决方案及shuffle原理
数据倾斜调优与shuffle调优 数据倾斜发生时的现象 1)个别task的执行速度明显慢于绝大多数task(常见情况) 2)spark作业突然报OOM异常(少见情况) 数据倾斜发生的原理 在进行shu ...
- Spark数据倾斜及解决方案
一.场景 1.绝大多数task执行得都非常快,但个别task执行极慢.比如,总共有100个task,97个task都在1s之内执行完了,但是剩余的task却要一两分钟.这种情况很常见. 2.原本能够正 ...
- spark数据倾斜
数据倾斜的主要问题在于,某个分区数量很巨大,在做map运算的时候,将会发生别的分区task很快计算完成,但是某几个分区task的计算成为了系统的瓶颈,明显超过其他分区时间: 1.方案:Kafka的 ...
- Spark 数据倾斜调优
一.what is a shuffle? 1.1 shuffle简介 一个stage执行完后,下一个stage开始执行的每个task会从上一个stage执行的task所在的节点,通过网络传输获取tas ...
随机推荐
- ASP.NET Core 6框架揭秘实例演示[35]:利用Session保留语境
客户端和服务器基于HTTP的消息交换就好比两个完全没有记忆能力的人在交流,每次单一的HTTP事务体现为一次"一问一答"的对话.单一的对话毫无意义,在在同一语境下针对某个主题进行的多 ...
- 华南理工大学 Python第4章课后小测-2
1.(单选)下面程序的输出结果是: for c in "ComputerScience": if c=="S": continue print(c,end=&q ...
- Base64加密、解密
#region Base64加密方法 /// <summary> /// Base64加密,采用utf8编码方式加密 /// </summary> /// <param ...
- Shell分析日志文件
文章转载自:https://mp.weixin.qq.com/s/o63aIM2p9rc2OjhxiC6wgA 1.查看有多少个IP访问: awk '{print $1}' log_file|sort ...
- Docker MySql 查看版本的三种方法
目录 Docker MySql 查看版本的三种方法 1.mysql -V命令查看版本 2.status命令查看版本 3.version命令查看版本 Docker MySql 查看版本的三种方法 1.m ...
- Vue实现拖拽穿梭框功能四种方式
一.使用原生js实现拖拽 点击打开视频讲解更加详细 <html lang="en"> <head> <meta charset="UTF-8 ...
- 华为交换机GVRP基础配置
GVRP基础配置 int G0/0/1 port link-type trunk 配置接口类型为trunk port trunk allow-pass vlan all 允许所有VLAN通过 int ...
- IDEA快速生成数据库表的实体类
IDEA连接数据库 IDEA右边侧栏有个DataSource,可以通过这个来连接数据库,我们先成功连接数据库 点击进入后填写数据库进行连接,注意记得一定要去Test Connection 确保正常连接 ...
- 魔改editormd组件,优化ToC渲染效果
前言 我的StarBlog博客目前使用 editor.md 组件在前端渲染markdown文章,但这个组件自动生成的ToC(内容目录)不是很美观,我之前魔改过一个树形组件 BootStrap-Tree ...
- 齐博x1注意事项:再强调严禁用记事本改任何文件
提醒大家,X1任何文件,不要用记事本修改.比如这个用户就改出问题了 导致后台不能升级. 当然这是问题之一, 还有其它意料之外的问题.还没发现. 这个用户做一个测试风格. 配置文件可能是用记事本修改的. ...