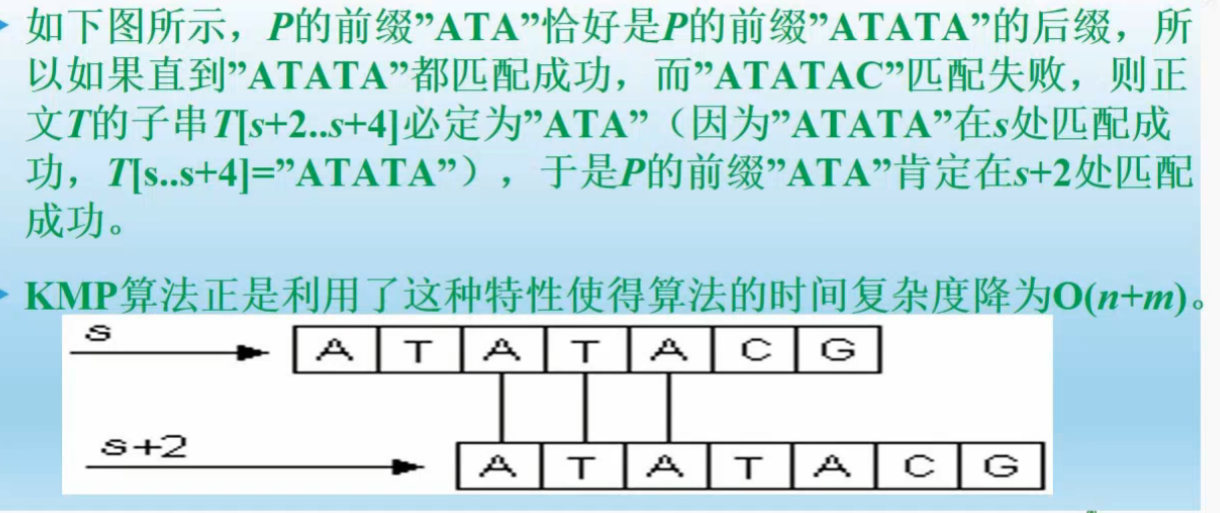
字符串处理------Brute Force与KMP
一,字符串的简单介绍




例:POJ1488 http://poj.org/problem?id=1488
题意:替换文本中的双引号;
#include <iostream>
#include <cstring>
#include <cstdio>
using namespace std; int main()
{
char c,flag=1;
//freopen("Atext.in","r",stdin);
while((c=getchar())!=EOF){
if(c=='"'){printf("%s",(flag? "``" : "''"));flag=!flag;}
else printf("%c",c);
}
return 0;
}
二,模式匹配------Brute Force与KMP简介
1,Brute Force算法


例:POJ3080 http://poj.org/problem?id=3080 枚举,BF
新:strstr(str1,str2) 函数用于判断字符串str2是否是str1的子串。如果是,则该函数返回str2在str1中首次出现的地址;否则,返回NULL。
Description
As an IBM researcher, you have been tasked with writing a program that will find commonalities amongst given snippets of DNA that can be correlated with individual survey information to identify new genetic markers.
A DNA base sequence is noted by listing the nitrogen bases in the order in which they are found in the molecule. There are four bases: adenine (A), thymine (T), guanine (G), and cytosine (C). A 6-base DNA sequence could be represented as TAGACC.
Given a set of DNA base sequences, determine the longest series of bases that occurs in all of the sequences.
Input
- A single positive integer m (2 <= m <= 10) indicating the number of base sequences in this dataset.
- m lines each containing a single base sequence consisting of 60 bases.
Output
Sample Input
3
2
GATACCAGATACCAGATACCAGATACCAGATACCAGATACCAGATACCAGATACCAGATA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
3
GATACCAGATACCAGATACCAGATACCAGATACCAGATACCAGATACCAGATACCAGATA
GATACTAGATACTAGATACTAGATACTAAAGGAAAGGGAAAAGGGGAAAAAGGGGGAAAA
GATACCAGATACCAGATACCAGATACCAAAGGAAAGGGAAAAGGGGAAAAAGGGGGAAAA
3
CATCATCATCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCC
ACATCATCATAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AACATCATCATTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTT
Sample Output
no significant commonalities
AGATAC
CATCATCAT
Source
#include <iostream>
#include <cstring>
#include <cstdio>
using namespace std; int main()
{
//freopen("Atext.in","r",stdin);
int n,m,len;
char ans[70],s[15][65],tmp[65];
cin >> n;
while(n--){
cin >> m;
int k=3,flag=0; //枚举的字符串长度;
ans[0]='\0',tmp[0]='\0',len=0;
for(int i=0;i<m;i++)
for(int j=0;j<60;j++)
cin >> s[i][j];
while(k<=60){ //字符串起点
for(int i=0;i<=60-k;i++){ //枚举长度为k的字符串的起点
memset(tmp,0,sizeof(tmp));//必须记得清空数组!!
for(int j=i,t=0;j<i+k;j++)//这里的i+k,原来敲的是k,傻了傻了,还找了半天!!!
tmp[t++]=s[0][j];
for(int j=1;j<m;j++){
if(strstr(s[j],tmp)==NULL){flag=1;break;}//不是公共子串就标记跳出;
}
if(flag==0){
if(k>len){strcpy(ans,tmp);len=k;}
else if(k==len&&strcmp(ans,tmp)>0){strcpy(ans,tmp);len=k;}
}
flag=0;
}
k++;
}
if(len!=0){
for(int i=0;i<len;i++)
cout << ans[i] ;
}
else
cout << "no significant commonalities" ;
cout << endl;
}
return 0;
}
2,KMP算法




例:POJ3461 Ouliop

例:POJ3461 Oulipo


#include <iostream>
#include <cstdio>
#include <cstring>
const int maxn=10005;
using namespace std;
string s,t;
int n,m;
int nex[maxn];
void getnex(){
int j=0,k=-1;
nex[0]=-1;
while(j<n){
if(k==-1||t[j]==s[k]){
nex[++j]=++k;
}else
k=nex[k];
}
}
int kmp(){
int i=0,j=0,cnt=0;
getnex();
while(i<m){
if(j==-1||s[i]==t[j]){
i++;j++;
}else
j=nex[j];
if(j==n)
cnt++;
}
return cnt;
}
int main()
{
int c;
//freopen("Atext.in","r",stdin);
ios::sync_with_stdio(false); //加了这个,关闭了输入输出同步就过了,不然超时;
cin >> c;
while(c--){
int ans=0;
cin >> t >> s;
n=t.size();
m=s.size();
ans=kmp();
cout << ans << endl;
}
return 0;
}
字符串处理------Brute Force与KMP的更多相关文章
- 常用字符串匹配算法(brute force, kmp, sunday)
1. 暴力解法 // 暴力求解 int Idx(string S, string T){ // 返回第一个匹配元素的位置,若没有匹配的子串,则返回-1 int S_size = S.length(); ...
- 数据结构(十六)模式匹配算法--Brute Force算法和KMP算法
一.模式匹配 串的查找定位操作(也称为串的模式匹配操作)指的是在当前串(主串)中寻找子串(模式串)的过程.若在主串中找到了一个和模式串相同的子串,则查找成功:若在主串中找不到与模式串相同的子串,则查找 ...
- 字符串模式匹配算法--BF和KMP详解
1,问题描述 字符串模式匹配:串的模式匹配 ,是求第一个字符串(模式串:str2)在第二个字符串(主串:str1)中的起始位置. 注意区分: 子串:要求连续 (如:abc 是abcdef的子串) ...
- DVWA全级别之Brute Force(暴力破解)
Brute Force Brute Force,即暴力(破解),是指黑客利用密码字典,使用穷举法猜解出用户口令. 首先我们登录DVWA(admin,password),之后我们看网络是否为无代理,: ...
- DVWA实验之Brute Force(暴力破解)- High
DVWA实验之Brute Force(暴力破解)- High 有关DVWA环境搭建的教程请参考: https://www.cnblogs.com/0yst3r-2046/p/10928380.ht ...
- DVWA实验之Brute Force(暴力破解)- Medium
DVWA实验之Brute Force(暴力破解)- Medium 有关DVWA环境搭建的教程请参考: https://www.cnblogs.com/0yst3r-2046/p/10928380. ...
- DVWA Brute Force:暴力破解篇
DVWA Brute Force:暴力破解篇 前言 暴力破解是破解用户名密码的常用手段,主要是利用信息搜集得到有用信息来构造有针对性的弱口令字典,对网站进行爆破,以获取到用户的账号信息,有可能利用其权 ...
- DVWA之Brute Force
DVWA简介 DVWA(Damn Vulnerable Web Application)是一个用来进行安全脆弱性鉴定的PHP/MySQL Web应用,旨在为安全专业人员测试自己的专业技能和工具提供合法 ...
- DVWA(二): Brute Force(全等级暴力破解)
tags: DVWA Brute Force Burp Suite Firefox windows2003 暴力破解基本利用密码字典使用穷举法对于所有的账号密码组合全排列猜解出正确的组合. LEVEL ...
- 小白日记46:kali渗透测试之Web渗透-SqlMap自动注入(四)-sqlmap参数详解- Enumeration,Brute force,UDF injection,File system,OS,Windows Registry,General,Miscellaneous
sqlmap自动注入 Enumeration[数据枚举] --privileges -U username[CU 当前账号] -D dvwa -T users -C user --columns [ ...
随机推荐
- 2022.07.13 vue3下pinia的简单使用及持久化
使用前说明: 当前demo使用了vue3 + vite + typescript + pinia搭建的简单项目,主要介绍了在单文件组件(sfc)基础上使用pinia的用法,懒得看api的兄弟们,来这瞅 ...
- python random包常用函数
random.random() random.random()方法返回一个随机数,其在0至1的范围之内,以下是其具体用法: import random print ("随机数: " ...
- AbstractRoutingDataSource - 动态数据源
AbstractRoutingDataSource 类说明: (1)它的抽象方法 determineCurrentLookupKey() 决定使用哪个数据源. (2)项目启动时,先调用 setTarg ...
- mybatis-plus使用FIND_IN_SET
xxxQueryWrapper.eq("is_deleted","0").apply(deptUser.getDeptId() != null,"de ...
- 实践Pytorch中的模型剪枝方法
摘要:所谓模型剪枝,其实是一种从神经网络中移除"不必要"权重或偏差的模型压缩技术. 本文分享自华为云社区<模型压缩-pytorch 中的模型剪枝方法实践>,作者:嵌入式 ...
- Why WebRTC丨“浅入深出”的工作原理详解
前言 近几年实时音视频通信应用呈现出了大爆发的趋势.在这些实时通信技术的背后,有一项不得不提的技术--WebRTC. 今年 1 月,WebRTC 被 W3C 和 IETF 发布为正式标准.据调研机构 ...
- 网页静态化技术 Freemarker
网页静态化解决方案在实际运用中比较多,例如新闻网站,门户网站中的新闻频道或者是文章类的频道.对于电商网站的商品详细页(几百万的商品,同样的页面模板格局)来说,每个商品又有大量的信息,这样的情况同样也适 ...
- BEST 定理与矩阵树定理的证明
BEST 定理:计算有向图的欧拉回路数量 欧拉图 \(G\) 的欧拉回路个数为 \(T_s(G)\prod(out_i-1)!\),其中 \(T_s(G)\) 代表以 \(s\) 为根的内向树个数,\ ...
- Hive 和 Spark 分区策略剖析
作者:vivo 互联网搜索团队- Deng Jie 随着技术的不断的发展,大数据领域对于海量数据的存储和处理的技术框架越来越多.在离线数据处理生态系统最具代表性的分布式处理引擎当属Hive和Spark ...
- [Java]排序算法>选择排序>【简单选择排序】(O(n*n)/不稳定/)
1 选择排序 1.1 算法思想 每一趟从待排序的记录中选出关键字最小的记录,按顺序放在已排序的记录序列的最后(or最前面),直到全部排完位置. 1.2 算法特征 属于[选择排序] 简单选择排序 堆排序 ...