NodeJS 实战系列:DevOps 尚未解决的问题
本文将通过展示 NodeJS 应用里环境变量的提取过程,来一窥 DevOps 技术是如何应用在现在云平台上的运维工作中的。同时我也想让大家在这里看到 DevOps 的另外一面,即它并非全能,从本地开发到持续部署再到实际运行,有一些运维鸿沟依然还未被填平。“人工操作”依然是工作中的最大风险。
实战系列来自于个人开发以及运维 site2share 网站过程中的经验
不完美的环境变量抽取
有一件事我想我们都会同意,那就是不应该在代码中硬编码(hard code)环境变量,比如生产环境数据库的用户名和密码。之所以称之为环境变量,是因为这些变量是依据你代码部署的环境而定的,例如生产环境和本地环境数据库用户名和密码就多半不会相同。下面就是一段使用 sequelize 连接数据库的代码的反例,其中硬编码了用户名和密码:
const connectionCfg = {
username: "admin",
password: "!password",
database: "order_db",
dialect: "mysql",
}
new Sequelize(connectionCfg);
将环境变量硬编码在代码中会产生几个问题:
- 安全:将用户名密码暴露给所有的开发人员并不安全,删库跑路的风险大大增加
- 耦合:运维同学如果需要对环境进行变更(比如迁移、新增),需要联系“无辜的”开发同学重现编辑和部署代码
所有我们应该利用 process.env 或者是 dotenv 工具,来将环境变量独立管理,让代码与环境解耦。
思路我们有了,本地开发的时候如果你使用了 dotnev,它默认会读取 .env 里的内容作为环境变量。但是当考虑到下一步我们把应用部署到生产环节时,你要面临的问题就是如何在你的云服务商环境上管理你的环境变量了。
这取决于你选择云服务解决方案。以 site2share 为例,因为我选择将它部署在 Azure App Service(App Service 简单来说是一个托管性质的服务部署平台,我可以快速部署代码而不用去维护背后的运行环境,并且它还提供了诸如监控、灰度部署等常用功能) 上,所以我可以直接使用 App Service 为我准备的环境变量解决方案。我只需要在我环境的 UI 界面上填写我的环境变量即可:
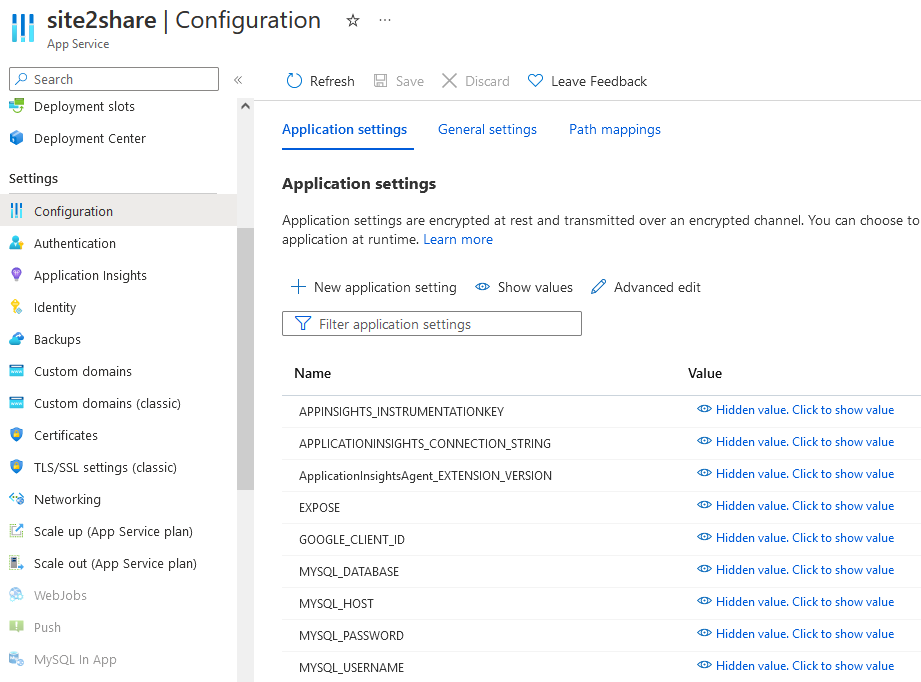
基本上目前主流云服务厂商提供的完全托管服务(full managed service)都提供类似的机制,下面是 Digital Ocean 的 App Platform 方案提供的环境变量管理界面:

到这里看似完美了——这样会带来一个风险:它并非是 IaC(Infrastructure as Code) 的。
什么是 IaC 我在这里举个例子,例如每次代码提交之后都会触发流水线运行测试,这里我把“需要运行测试”这件事记录在一个 yaml 文件里并且提交:
- script: |
npm run test
displayName: 'npm test'
这样将来无论是我自己回忆,还是新同学加入,都可以通过阅读这个文件判断流水线干了什么。如果有一天测试不小心被删掉了,也能追溯为什么被删以及被谁删掉的
非 IaC 的风险在于,如果你将来本地开发时新增了环境变量 REDIS_HOST,你需要保证云平台上的每个环境也需要新增 REDIS_HOST 变量(反过来说不用的环境变量也应该删除来避免将来给维护人员带来疑惑),然而这个步骤目前看来完全是依赖人工来完成的,因为云平台无法自动识别到你新增了变量
这里我们遇到了第一道鸿沟:开发环境与云平台的环境变量同步问题
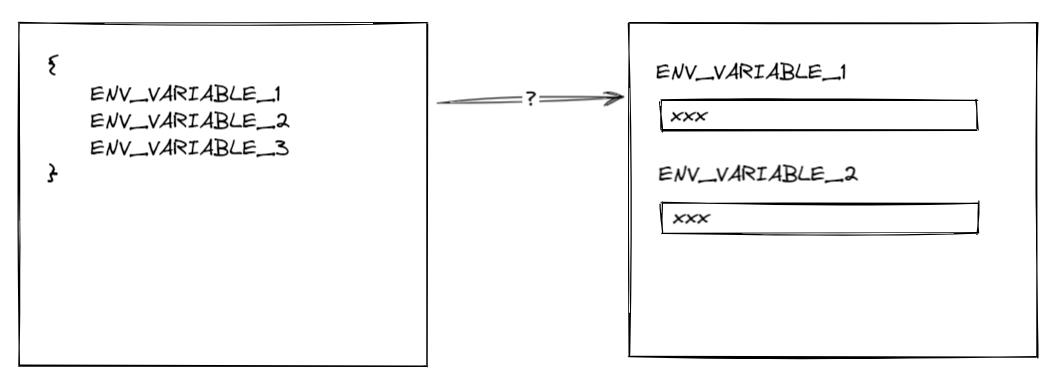
问题才刚刚开始
DevOps 没有解决的问题
“人” 是DevOps 想要解决的问题之一,如果每次上线的成功都依赖自资深工程师的经验,那出错不过是早晚的事情而已。 把难的事情频繁做就是 CI(持续集成)/CD(持续交付) 的背后思想。
例如我们常常需要对数据库做变更,新增表或者列。把这类操作交给程序员手工去每个环境手工执行并非明智选择,我们应该把它交给持续交付的流水线去完成,这样会推动我们部署环境的标准化和自动化,减少风险。这一步骤我们将它命名为数据迁移( migration),我们看看 site2share 的数据迁移是如何做的。
因为我在代码中选择了 sequelize 作为数据库框架,所以理想情况是我只需要创建好数据迁移文件之后执行 sequelize 提供的命令工具即可:sequelize-cli db:migrate
第一个问题是:它怎么知道应该连接哪个数据库以及如何连接数据库?
sequelize 允许我们在目录添加一个名为 .sequelizerc 的配置文件来对 sequelize 进行配置,我们可以在其中设定数据库的连接字符串和数据迁移文件目录,比如
const path = require('path');
const migrationDir = path.join(__dirname, "migration");
require('dotenv').config();
module.exports = {
'config': path.join(migrationDir, 'config.js'),
'migrations-path': path.join(migrationDir, 'migrations'),
'seeders-path': path.join(migrationDir, 'seeders'),
};
其中 config.js 文件存储的就是数据库的连接配置,如用户名和密码:
第二个问题是:我们如何将用户名和密码等环境变量如第一小节所示抽取出来?config.js 允许我们访问 process.env.MYSQL_USERNAME,但 MYSQL_USERNAME 究竟应该如何让流水线知道呢?
site2share 使用 Azure DevOps 作为 CI/CD 工具。很遗憾 Azure DevOps 并没有如 App Service 那样提供一个最优解,一种解决思路是我可以使用 Azure KeyVault 服务用作密钥存储,在构建的时候读取;而我选择的是一种更为简单粗暴的方式:
- 将环境变量存储到名为 .env.ci 的文件中
- 把文件上传到 Azure DevOps 的 Secure Files 中,Secure Files 可以用于存储证书类型文件,上传后的文件不可以被预览,不可以被下载
- 在 CD 过程中将 .env.ci 文件从 secure files 里下载到代码目录里,然后使用 dotenv 读取载入作为环境变量
- 执行 sequelize-cli db:migrate 命令
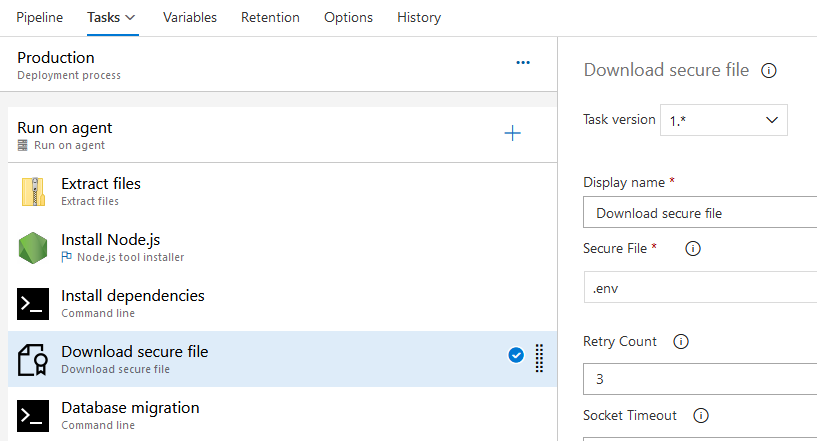
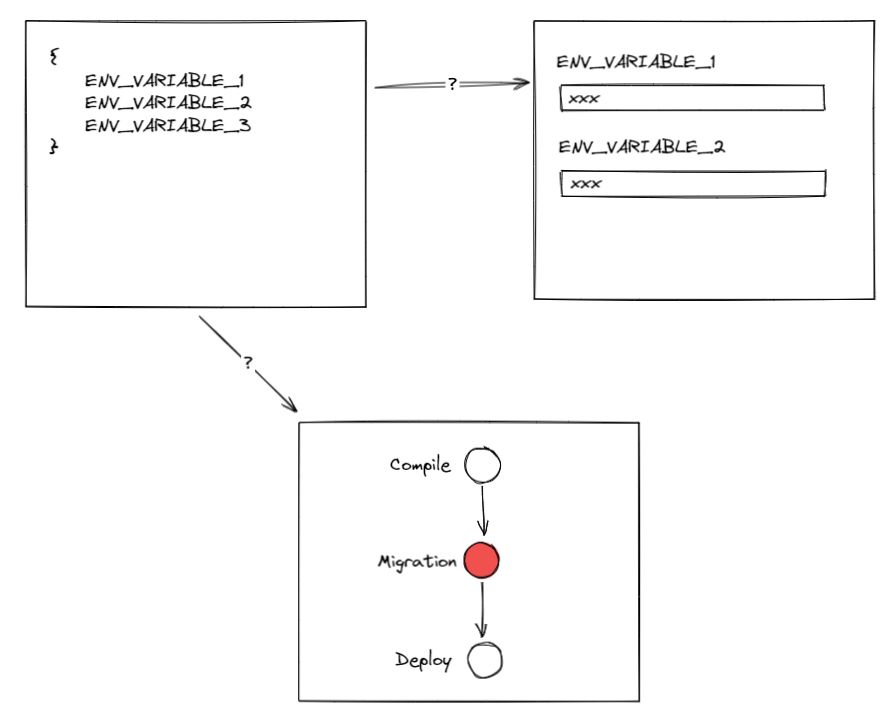
和在界面上编辑环境变量的行为类似,这种方法看上去同样不具有可持续性的。它依赖人的手工操作
所以在这里我们看到另一道鸿沟:环境变量从开发环境到流水线的同步问题
DevOps 是进步不是银弹
DevOps 话题很大我们这里暂且只看技术层面。我这里不是对 DevOps 批评,更不是对 Azure 的批评。这类问题在不同的平台都会存在,例如你如果使用阿里云效,他们甚至不允许你以 yaml 代码去编辑和保存流水线(IaC),但 IaC 也不是万能的,当你的 yaml 文件长达800行时基本等同于不可读时,它起到的效果等同于不存在。云平台本身的 vendor-lock 的问题也是原罪
在这里我们可以想象没有它们运维工作会比现在难上不知道多少倍——不能因为美中不足就否认它们给我们带来的帮助。
我们要接纳这样的一个现实:并不是所有的问题都可以用工具完美解决,“手工”暂且无法被彻底消灭。承认不完美的存在,尽所能把风险降到最小就好。
你可能也会喜欢:
- NodeJS 实战系列:DevOps 尚未解决的问题
- NodeJS 实战系列:如何设计 try catch
- 做一个能对标阿里云的前端APM工具(下)
- 做一个能对标阿里云的前端APM工具(上)
- 小心 Serverless
- SQL Server 查询语句优化入门
- 利用Node.js+express框实现图片上传
- 一篇来自前端同学对后端接口的吐槽
- 关于Node.js后端架构的一点后知后觉
- 在Node.js中搭建缓存管理模块'
NodeJS 实战系列:DevOps 尚未解决的问题的更多相关文章
- NodeJS 实战系列:如何设计 try catch
本文将通过一个 NodeJS 程序里无效的错误捕获示例,来讲解错误捕获里常见的陷阱.错误捕获不是凭感觉添加 try catch 语句,它的首要目的是提供有效的错误排查信息,只有精心设计的错误捕获才有可 ...
- Nodejs实战系列:数据加密与crypto模块
博客地址:<NodeJS模块研究 - crypto> Github :https://github.com/dongyuanxin/blog nodejs 中的 crypto 模块提供了各 ...
- CODING DevOps 代码质量实战系列最后一课,周四发车
随着 ToB(企业服务)的兴起和 ToC(消费互联网)产品进入成熟期,线上故障带来的损失越来越大,代码质量越来越重要,而「质量内建」正是 DevOps 核心理念之一. <DevOps 代码质量实 ...
- CODING DevOps 微服务项目实战系列第一课,明天等你
CODING DevOps 微服务项目实战系列第一课<DevOps 微服务项目实战:DevOps 初体验>将由 CODING DevOps 开发工程师 王宽老师 向大家介绍 DevOps ...
- CODING DevOps 微服务项目实战系列第二课来啦!
近年来,工程项目的结构越来越复杂,需要接入合适的持续集成流水线形式,才能满足更多变的需求,那么如何优雅地使用 CI 能力提升生产效率呢?CODING DevOps 微服务项目实战系列第二课 <D ...
- CODING DevOps 微服务项目实战系列最后一课,周四开讲!
随着软件工程越来越复杂化,如何在 Kubernetes 集群进行灰度发布成为了生产部署的"必修课",而如何实现安全可控.自动化的灰度发布也成为了持续部署重点关注的问题.CODING ...
- Spark入门实战系列--7.Spark Streaming(上)--实时流计算Spark Streaming原理介绍
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark Streaming简介 1.1 概述 Spark Streaming 是Spa ...
- .NET Core加解密实战系列之——消息摘要与数字签名算法
目录 简介 功能依赖 消息摘要算法 MD算法 家族发展史 应用场景 代码实现 MD5 示例代码 SHA算法 应用场景 代码实现 SHA1 SHA256 示例代码 MAC算法 HMAC算法的典型应用 H ...
- Spark入门实战系列--1.Spark及其生态圈简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .简介 1.1 Spark简介 年6月进入Apache成为孵化项目,8个月后成为Apache ...
- Spark入门实战系列--2.Spark编译与部署(上)--基础环境搭建
[注] 1.该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取: 2.Spark编译与部署将以CentOS 64位操作系统为基础,主要是考虑到实际应用 ...
随机推荐
- 【笔记】入门DP(Ⅱ)
0X00 P1433 吃奶酪 状压 \(DP\),把经过的点压缩成01串.若第 \(i\) 位为 \(0\) 表示未到达,为 \(1\) 则表示已到达. 用 \(f[i][j]\) 表示以 \(i\) ...
- 记一次hook mac地址实现伪装硬件码
1. 前言 好久没写文章了,工作比较忙,不过我还是对技术比较热爱,即使它不能给我带来利益,保持初心. 工作期间遇到一个问题,连接vpn的软件是校验机器硬件码,不是公司电脑不让使用vpn软件,上下班已经 ...
- APACHE正向代理配置
Apache快速安装和反向代理配置:https://www.cnblogs.com/brad93/p/16718104.html Apache正向代理配置参考教程:https://www.cnblog ...
- 爬虫笔记之xpath
目录 xpath如何取包含多个class属性 xpath获取当前标签下的所有文本(包括子标签) xpath如何取包含多个class属性 如果HTML结构是这样 <div class=" ...
- MasaFramework -- 领域驱动设计
概念 什么是领域驱动设计 领域驱动的主要思想是, 利用确定的业务模型来指导业务与应用的设计和实现.主张开发人员与业务人员持续地沟通和模型的持续迭代,从而保证业务模型与代码的一致性,实现有效管理业务的复 ...
- MetaTown:一个可以自己构建数字资产的平台
摘要:华为云Solution as Code重磅推出<基于MetaTown构建数字资产平台>解决方案. 本文分享自华为云社区<基于MetaTown构建数字资产平台>,作者: 阿 ...
- kubernetes CKA题库(附答案)
第一题 RBAC授权问题权重: 4% 设置配置环境:[student@node-1] $ kubectl config use-context k8s Context为部署管道创建一个新的Cluste ...
- 记开源项目:DotNetCore.CAP.MySql问题分析:only mysqlparameter objects may be stored
1. 简介 最近在学习分布式事务及解决方案,最终找到了开源项目DotNetCore.CAP ,因为自己用的MySql数据库比较多.于是也使用MySQL+EFCore+RabbitMQ+CAP实现事务 ...
- PPT排版技巧
- JavaScript:七大基础数据类型:数值number及其表示范围
数值number类型,用来表示任何类型的数字:整数或者浮点数都可以: 实际上,JS中的数值,是一个64位的浮点数,这与Java中的double类型的浮点数是一致的: 但是它有表示的范围,在范围内,JS ...