如何设计一个分布式 ID 发号器?

大家好,我是树哥。
在复杂的分布式系统中,往往需要对大量的数据和消息进行唯一标识,例如:分库分表的 ID 主键、分布式追踪的请求 ID 等等。于是,设计「分布式 ID 发号器」就成为了一个非常常见的系统设计问题。今天我将带大家一起学习一下,如何设计一个分布式 ID 发号器。
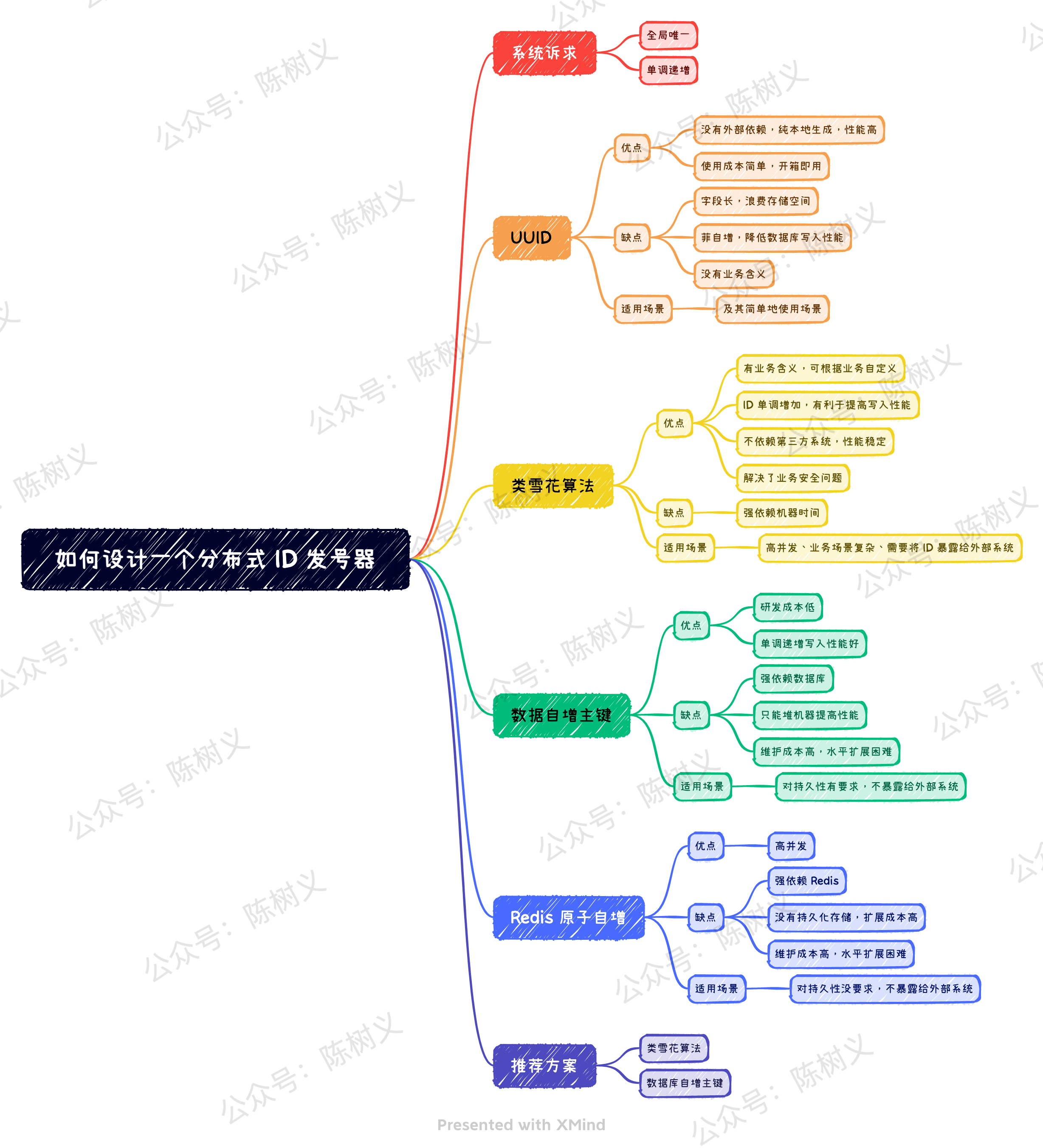
系统诉求
对于业务系统而言,对于全局唯一 ID 一般有如下几个需求:
- 全局唯一。 生成的 ID 不能重复,这是最基本的要求,否则在分库分表的场景下就会造成主键冲突。
- 单调递增。 保证下一个 ID 大于上一个 ID,这样可以保证写入数据库的时候是顺序写入,提高写入性能。
对于上面两个需求来说,第一点是所有系统都要求的。而第二点则并不是所有系统都需要,例如分布式追踪的请求 ID 就可以不需要单调递增。而那些需要存到数据库里作为 ID 逐渐的场景,可能就需要保证全局唯一 ID 是单调递增的。
此外,我们可能还需要考虑安全方面的问题。如果一个全局唯一 ID 是顺序递增的,那么有可能会造成业务信息的泄露。例如订单 ID 每次递增 1,那么竞争对手直接通过订单 ID 就可以知道我们每天的订单数,这对于业务来说是不可接受的。
对于上述的诉求,现在市面上有非常多的唯一 ID 解决方案,其中最为常见的方案有如下 4 种:
- UUID
- 类雪花算法
- 数据库自增主键
- Redis 原子自增
UUID
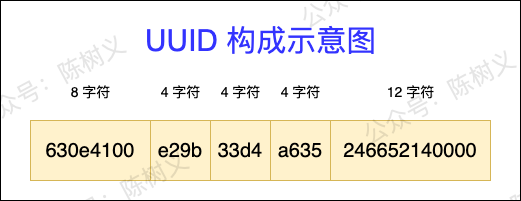
UUID 全称叫 Universally Unique Identifier,即全局唯一标识符,它是 Java 中自带的 API。 一个标准的 UUID 包含 32 个 16 进制的数字,以中横线作为分隔符分为 5 段,每段的长度分别为 8 字符、4 字符、4 字符、4 字符、12 字符,大小为 36 个字符,如下图所示。一个简单的 UUID 示例:630e4100-e29b-33d4-a635-246652140000。
对于 UUID 这种唯一 ID 解决方案,优点是没有外部依赖,纯本地生成,因此其性能非常高。但缺点也是非常明显的:
- 字段非常长,浪费存储空间。 UUID 一般长度为 36 个字符串,如果作为数据库主键存储,极大地增加索引的存储空间。
- 非自增,降低数据库写入性能。 UUID 不是自增的,如果作为数据库主键,那么无法实现顺序写,从而会降低数据库写入性能。
- 没有业务含义。 UUID 是没有业务含义的,我们无法从 UUID 中获取到任何含义。
因此,对于 UUID 而言,其比较适用于非数据库 ID 存储的情况,例如生成一个本地的分布式追踪请求 ID。
类雪花算法
雪花算法(SnowFlake)是 Twitter 开源的分布式 ID 生成算法,其思路是用 64 位来表示一个 ID,并将 64 位分割成 4 个部分,如下图所示。
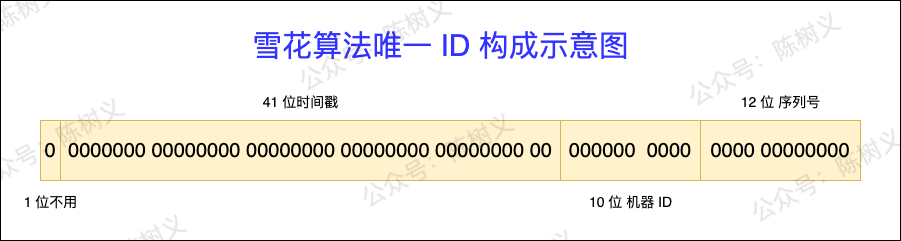
- 第一个部分:1 位。 固定为 0,表示为正整数。二进制中最高位是符号位,1 表示负数,0 表示正数。ID 都是正整数,所以固定为 0。
- 第二个部分:41 位。 表示时间戳,精确到毫秒,可以使用 69 年。时间戳带有自增属性。
- 第三个部分:10 位。 表示 10 位的机器标识,最多支持 1024 个节点。此部分也可拆分成 5 位 datacenterId 和 5 位 workerId,datacenterId 表示机房 ID,workerId 表示机器 ID。
- 第四部分:12 位。 表示序列化,即一些列的自增 ID,可以支持同一节点同一毫秒生成最多 4095 个 ID 序号。
雪花算法的优点是:
- 有业务含义,并且可自定义。 雪花算法的 ID 每一位都有特殊的含义,我们从 ID 的不同位数就可以推断出对应的含义。此外,我们还可根据自身需要,自行增删每个部分的位数,从而实现自定义的雪花算法。
- ID 单调增加,有利于提高写入性能。 雪花算法的 ID 最后部分是递增的序列号,因此其生成的 ID 是递增的,将其作为数据库主键 ID 时可以实现顺序写入,从而提高写入性能。
- 不依赖第三方系统。 雪花算法的生成方式,不依赖第三方系统或中间件,因此其稳定性较高。
- 解决了安全问题。 雪花算法生成的 ID 是单调递增的,但其递增步长又不是确定的,因此无法从 ID 的差值推断出生成的数量,从而可以保护业务隐私。
雪花算法几乎可以是非常完美了,但它有一个致命的缺点 —— 强依赖机器时间。 如果机器上的系统时间回拨,即时间较正常的时间慢,那么就可能会出现发号重复的情况。对于这种情况,我们可以在本地维护一个文件,写入上次的时间戳,随后与当前时间戳比较。如果当前时间戳小于上次时间戳,说明系统时间出了问题,应该及时处理。
整体而言,雪花算法不仅长度更短,而且还具有业务含义,在数据库存储的场景下还能提高写入性能,因此雪花算法生成分布式唯一 ID 受到了大家的欢迎。 现在许多国内大厂的开源发号器的实现,都是在雪花算法的基础上做改进,例如:百度开源的 UidGenerator、美团开源的 Leaf 等等。这些类雪花算法的核心都是将 64 位进行更合理的划分,从而使得其更适合自身场景。
数据库自增主键
说起唯一 ID,我们自然会想起数据库的自增主键,因为它就是唯一的。
对于并发量低的情况下,我们可以直接部署 1 台机器,每次获取 ID 的时候就往数据库表插入一条数据,随后返回主键 ID。这种方式的好处是非常简单,实现成本低。此外,生成的唯一 ID 也是单调自增的,可以满足数据库写入性能的要求。
但其缺点也非常明显,即其强依赖数据库。当数据库异常的时候,会造成整个系统不可用。即使做了高可用切换,主从切换时数据同步不一致时,仍然可能造成重复发号。另外,由于是单机部署,因此其性能瓶颈限制在单台 MySQL 机器的读写性能上,注定无法承担起高并发的业务场景。
对于上面说到的性能问题,我们可以通过集群部署来解决。而集群部署之后的 ID 冲突问题,我们可以通过设置递增步长来解决。例如如果我们有 3 台机器,那么我们就设置递增步长为 3,每台机器的 ID 生成策略为:
- 第 1 台机器,从 0 开始递增,步长为 3,生成的 ID 分别是:0、3、6、9 等等。
- 第 2 台机器,从 1 开始递增,步长为 3,生成的 ID 分别是:1、4、7、10 等等。
- 第 3 台机器,从 2 开始递增,步长为 3,生成的 ID 分别是:2、5、8、11 等等。
这种方式解决了集群部署以及 ID 冲突的问题,可以在一定程度上提升并发访问的容量。但其缺点也比较明显:
- 只能依赖堆机器提高性能。 当请求再次增多时,我们只能无限堆机器,这貌似是一种物理防御一样。
- 水平扩展困难。 当我们需要增加一台机器时,其处理过程非常麻烦。首先,我们需要先把新增的服务器部署好,设置新的步长,起始值要设置一个不可能达到的值。当把新增的服务器部署好之后,再一台台处理旧的服务器,这个过程真的非常痛苦,可以说是人肉运维了。
Redis 原子自增
由于 Redis 是内存数据库,其强大的性能非常适合用来实现高并发的分布式 ID 生成。基于 Redis 实现自增 ID,其主要还是利用了 Redis 中的 INCR 命令。该命令可以将某个数自增一并返回结果,并且这个操作是原子操作。
通过 Redis 实现分布式 ID 功能,其模式与通过数据库自增 ID 类似,只是存储介质从硬盘变成了内存。当单台 Redis 无法支撑并发请求的时候,Redis 同样可以通过集群部署和设置步长的方式去解决。但数据库自增主键有的问题,Redis 自增 ID 的方式也同样会有,即只能堆机器,同时水平扩展困难。此外,比起数据库存储的持久化,Redis 是基于内存的存储,需要考虑持久化的问题,这同样是一个头疼的问题。
总结
看了这么多个分布式 ID 的解决方案,那么我们到底应该选哪个呢?
当我们在决策的时候,我们应该确定决策的维度。对于这个问题,我们应该关注的维度大致有:研发成本、并发量、性能、运维成本。
首先,对于 UUID 而言,其在各个方面其实都不如雪花算法,唯一的优点是 JDK 自带 API。因此,如果你只是极其简单地使用,那么就直接使用 UUID 就可以,毕竟雪花算法还得写一写实现代码呢。
其次,对于类雪花算法而言,其毋庸置疑是非常好的一种实现。与 UUID 相比,其不仅有 UUID 本地生成、不依赖第三方系统的优点,还有业务含义、能提高写入性能、解决了安全问题。但其缺点在于要实现雪花算法的代码,因此其研发成本稍稍比 UUID 高一些。
最后,对于数据库自增 ID 与 Redis 原子自增这两种方式。数据库自增 ID 的方式,其优点同样在于简单方便,不需要太高的研发成本。但其缺点是支撑的并发量太低,并且后续运维成本太高。因此,数据库自增 ID 这种方式,应该适用于小规模的使用场景下。而 Redis 原子自增的方式,其优先在于能支撑高并发的场景。但缺点是需要自行处理持久化问题,运维成本可能比较高。
本人更倾向于数据库自增方式。这两种方式都是非常类似的,唯一的区别是存储介质。Redis 原子自增方式非常快,可能单机可以是数据库方式的好几倍。但是如果要考虑持久化的问题,那对于 Redis 来说就太复杂了。
我们把上面这四种实现方式整理一下,可以汇总成下面的对比表格:
| 实现方案 | 优点 | 缺点 | 使用场景 |
|---|---|---|---|
| UUID | 性能高、不依赖第三方、研发成本低 | 字段长浪费存储空间、ID 不自增写入性能差、无业务含义 | 非常简单的使用场景(用于简单测试) |
| 类雪花算法 | 有业务含义、单调递增写入性能好、不依赖第三方、业务安全 | 强依赖机器时间 | 高并发、业务场景复杂、需要将 ID 暴露给外部系统 |
| 数据库自增 ID | 研发成本低、单调递增写入性能好 | 依赖数据库、只能堆机器提高性能、维护成本高 | 对持久性有要求,不暴露给外部系统 |
| Redis 原子自增 | 高并发、单调递增写入性能好 | 依赖 Redis、有业务问题、有持久性问题 | 对持久性没要求,不暴露给外部系统 |
总的来说,如果站在长期使用考虑,那么运维成本、高并发肯定是需要考虑的。在这个基础条件下,类雪花算法与数据库自增 ID 或许是相对好的选择。
参考资料
- 分布式系统全局发号器的几点思考 - 掘金
- VIP!!非常好!Leaf—— 美团点评分布式 ID 生成系统 - 美团技术团队
- (8 条消息) 六种方式实现全局唯一发号器_北鹤 M 的博客 - CSDN 博客_发号器
- VIP!!不错,扩展视野!10 | 发号器:如何保证分库分表后ID的全局唯一性?
如何设计一个分布式 ID 发号器?的更多相关文章
- 就这?分布式 ID 发号器实战
分布式 ID 需要满足的条件: 全局唯一:这是最基本的要求,必须保证 ID 是全局唯一的. 高性能:低延时,不能因为一个小小的 ID 生成,影响整个业务响应速度. 高可用:无限接近于100%的可用性. ...
- spring boot:redis+lua实现顺序自增的唯一id发号器(spring boot 2.3.1)
一,为什么需要生成唯一id(发号器)? 1,在分布式和微服务系统中, 生成唯一id相对困难, 常用的方式: uuid不具备可读性,作为主键存储时性能也不够好, mysql的主键,在分库时使用不够方便, ...
- 全局唯一ID发号器的几个思路
标识(ID / Identifier)是无处不在的,生成标识的主体是人,那么它就是一个命名过程,如果是计算机,那么它就是一个生成过程.如何保证分布式系统下,并行生成标识的唯一与标识的命名空间有着密不可 ...
- 来吧,自己动手撸一个分布式ID生成器组件
在经过了众多轮的面试之后,小林终于进入到了一家互联网公司的基础架构组,小林目前在公司有使用到架构组研究到分布式id生成器,前一阵子大概看了下其内部的实现,发现还是存在一些架构设计不合理之处.但是又由于 ...
- 设计一个分布式RPC框架
0 前言 提前先祝大家春节快乐!好了,先简单聊聊. 我从事的是大数据开发相关的工作,主要负责的是大数据计算这块的内容.最近Hive集群跑任务总是会出现Thrift连接HS2相关问题,研究了解了下内部原 ...
- 分布式ID生成器(CosId)的设计与实现
分布式ID生成器(CosId)设计与实现 CosId 简介 CosId 旨在提供通用.灵活.高性能的分布式 ID 生成器. 目前提供了俩类 ID 生成器: SnowflakeId : 单机 TPS 性 ...
- 分布式ID方案有哪些以及各自的优劣势,我们当如何选择
作者介绍 段同海,就职于达达基础架构团队,主要参与达达分布式ID生成系统,日志采集系统等中间件研发工作. 背景 在分布式系统中,经常需要对大量的数据.消息.http请求等进行唯一标识,例如:在分布式系 ...
- 分布式ID生成器PHP+Swoole实现(上) - 实现原理
1.发号器介绍 什么是发号器? 全局唯一ID生成器,主要用于分库分表唯一ID,分布式系统数据的唯一标识. 是否需要发号器? 1)是否需要全局唯一. 分布式系统应该不受单点递增ID限制,中心式的会涉及到 ...
- spring boot / cloud (十六) 分布式ID生成服务
spring boot / cloud (十六) 分布式ID生成服务 在几乎所有的分布式系统或者采用了分库/分表设计的系统中,几乎都会需要生成数据的唯一标识ID的需求, 常规做法,是使用数据库中的自动 ...
随机推荐
- postman 脚本和变量
背景 后端接口有登录或鉴权验证,通过 swagger 调用比较费劲,并且 java 的 swagger 库(不够自动化,嵌套类支持需要各种配置才能正常显示 schema)个人感觉也没有 .net co ...
- linux篇-linux数据库mysql的安装
1数据库文件放到opt下面 2赋予权限775 3运行脚本 4运行成功 5数据库操作 密码修改并刷新 权限修改,允许外部设备访问 6工具连接 7附录 1.显示当前数据库服务器中的数据库列表: mysql ...
- el-form 中的数组表单验证(数组可动态添加删除)
除了一些简单的表单验证之外,我们还会有一些稍微复杂点的多层级表单的验证,如下图所示可点击添加,删除对数组进行操作,当点击确定时需要验证每一条form-item不能为空 其tempalte部分主要代码如 ...
- 04C++核心编程(二-泛型编程)
Day08 笔记 1 函数模板 1.1 泛型编程 – 模板技术 特点:类型参数化 1.2 template< typename T > 告诉编译器后面紧跟着的函数或者类中出现T,不要报错, ...
- python新建一个目录
源码部分 import os # 创建目录 def mkdir(path): isExists = os.path.exists(path) if not isExists: os.makedirs( ...
- 一文精通HashMap灵魂七问,你学还是不学
如果让你看一篇文章,就可以精通HashMap,成为硬刚才面试官的高手,你学还是不学? 别着急,开始之前不如先尝试回来下面几个问题吧: HashMap的底层结构是什么? 什么时候HashMap中的链表会 ...
- NC23053 月月查华华的手机
NC23053 月月查华华的手机 题目 题目描述 月月和华华一起去吃饭了.期间华华有事出去了一会儿,没有带手机.月月出于人类最单纯的好奇心,打开了华华的手机.哇,她看到了一片的QQ推荐好友,似乎华华还 ...
- 论文阅读 GloDyNE Global Topology Preserving Dynamic Network Embedding
11 GloDyNE Global Topology Preserving Dynamic Network Embedding link:http://arxiv.org/abs/2008.01935 ...
- 如何搭建android源代码repo仓库
如何搭建android源代码repo仓库 目录 如何搭建android源代码repo仓库 1 repo是如何管理仓库的? 1.1 repo如何工作的? 1.2 搭建repo服务需要做哪些事情? 2 部 ...
- Java 内存模型,或许应该这么理解
大家好,我是树哥. 在前面一段时间,我连续写了几篇关于并发编程的文章: 从 CPU 讲起,深入理解 Java 内存模型! - 陈树义的博客 深入理解 happens-before 原则 - 陈树义的博 ...