MySQL原理
MySQL基础:
- sql语句的执行过程:
- 连接器:登录连接sql数据库
- 分析器:分析解读sql语句,并检查是否符合SQL语法规则
- 优化器:对实现方式进行优化,比如在查询时决定使用哪个索引。
- 执行器:执行。
- 事务:一系列聚合性操作,一组不可分割的sql语句。要么全部执行,要么全部不执行。
- 原子性:不可分割。undo log保证可以回滚
- 隔离性:事务不可被其他事务干扰。MVCC保证。
- 一致性:数据库处理结果应与其所代表的客观世界中真实状况保持一致。由其他三个特性保证
- 持久性:即便故障也不应该使数据的改变失效。redo log、bin log
- 隔离级别:
- 读未提交:事务未提交,修改就能被其他事务看到。
- 读提交:事务修改后,修改才能被其他事务看到。解决脏读
- 可重复读:事务在执行过程中,数据会保持与开始时一致。mysql默认,解决不可重读。
- 串行化:写锁,读锁。阻塞。解决幻读。
- 行锁:在InnoDB事务中,行锁是在需要的时候才加上的,但并不是不需要了就立刻释放,而是要等到事务结束时才释放。这个就是两阶段锁协议。
- 一个事务对数据对象 A 加了 X 锁,就可以对 A 进行读取和更新。加锁期间其它事务不能对 A 加任何锁。
- 一个事务对数据对象 A 加了 S 锁,可以对 A 进行读取操作,但是不能进行更新操作。加锁期间其它事务能对 A 加 S 锁,但是不能加 X 锁。
- 意向XS锁:对整个表加意向锁,表明已有事务正在对此表/此表的某行进行读/写,阻塞其他想要获取表锁的事务,如果没有意向锁,想要获取表锁的事务逐条查看是否有行锁。
- 表锁:很重量级,因此很少使用,通常只在整表的复制、备份中使用
MVCC:mysql实现读提交和可重复读两个隔离级别的方式。
原理:每行数据的三个隐藏属性:回滚指针(指向undo log串成的版本链),自增ID,最近修改该数据的事务ID。
读视图:记录活跃事务列表,也就是还未提交的事务。通过这个列表来判断记录的某个版本是否对当前事务可见。从版本链上的最新记录开始寻找,若更改某条记录的事务id小于读视图中的最小活跃事务id,也就是说当前事务是已提交的,就返回这条记录。
- 如何实现读提交:每次select都创建一个读视图。
- 如何实现可重复读:一个事务只创建一次读视图。
当前读:读取最新记录、update insert delete时用,需要加锁。
快照读:读版本链、读视图,不需要加锁。
MVCC 可以解决什么问题?
- 读写之间阻塞的问题,通过 MVCC 可以让读写互相不阻塞,读不相互阻塞,这样可以提升数据并发处理能力。
- 降低了死锁的概率,读取数据时,不需要加锁,写操作,只需要锁定必要的行。
- 解决了一致性读的问题,当我们朝向某个数据库在时间点的快照是,只能看到这个时间点之前事务提交更新的结果,不能看到时间点之后事务提交的更新结果。
MVCC在可重复读级别下,部分地解决了幻读问题,但这种情况下仍然可能出现幻读:一个事务不光进行查询,还进行update。
a事务先select,b事务insert之后提交。然后a事务update,若a事务再次select就会出现b事务中的新行,并且这个新行已经被update修改了.
上面这样,事务2提交之后,事务1再次执行update,因为这个是当前读,他会读取最新的数据,包括别的事务已经提交的,所以就会导致此时前后读取的数据不一致,出现幻读。
并发事务带来哪些问题?
- 脏读:某事务在修改数据还未提交时,被另一事务读取了这个数据进行了错误的操作。
- 丢失修改:两个事务同时修改某数据而未被阻塞,那么先修改的就会丢失。
- 不可重读:事务在两次读取数据中间某个时刻被其他事务修改了该数据,造成两次不一样。
- 幻读:事务在两次查询中间某个时刻被其他事务添加或删除了数据。比如查询年龄大于20的人,但被其他事务增加了几条记录。
- 日志:
- bin log:属于sever层,写满后重新开一块,记录原始操作逻辑。可用于读写分离主从库
- redo log:属于InnoDB引擎,写满后擦除重写,是物理日志。
- 两段提交:让bin和redo保持一致。
- Undo log:修改记录的链表,版本链、
索引:
- 哈希表只适用于等值查询,使用b+树,具有与二叉排序树相似的特点与性能,但层数更低,更适合于在硬盘中存储。
- 为什么不使用红黑树?
- 红黑树层数高、结点多、访问磁盘IO次数多,B+树索引在设计时,一个结点就是磁盘中的一页,也就是一个结点只需要一次IO。
- B 树& B+树两者有何异同呢?
- B 树的所有节点都存放数据(data),而 B+树只有叶子节点data,其他内节点只存放 key。这样内结点每个页可以存放更多的索引。相同高度b+树能够存放更多记录,也就是能降低树的高度
- B 树的叶子节点都是独立的;B+树的叶子节点有一条引用链指向与它相邻的叶子节点。
- B 树的检索的过程相当于对范围内的每个节点的关键字做二分查找,需要进行大量的回溯。而 B+树,从根节点到叶子节点后,因为顺序访问指针,所以范围查找很方便。
- 主键索引:随表建立,建立在主键上,不允许索引值出现空。
- 唯一索引:建立在unique字段上的索引,允许有空。
- 聚集/非聚集索引:是否在索引中存放数据。
- 聚集:定位快,定位到索引就定位到数据。依赖有序索引(主键使用AUTO_INCREMENT的原因)。更新代价大。InnoDB
- 非聚集:叶子结点不存放数据,只存放指向数据的指针 或主键。更新代价小。一般会需要进行回查,也就是找两遍树。MyISAM
- 覆盖索引:覆盖索引即需要查询的字段正好是索引的字段,那么直接根据该索引,就可以查到数据了, 而无需回表查询。可以在常用查询上建立覆盖索引,比如通过电话号码查询姓名。
- 前缀索引:字符串或者二进制作为索引时,只索引部分前缀,以减少计算和存储的开销。但无法order和group
- 全文索引:在需要进行全文检索的场景中
- 最左前缀:多字段建立联合索引是按照最左字段排的索引顺序。因此,在查询时,一定要带上联合索引中的最左字段,否则不会走索引。
- 索引下推:在非主键索引上,查询多个条件的时候,预先对后续条件进行判断,减少回查次数。
建立索引的原则:
- 有序、连续、重复值很少的字段适合建索引,比如自增ID。
- 分布过于离散且数值过大的字段不要建索引:身份证号、uuid
- 重复值太多的列不要建索引
- 区分度太低的列不要建
- 定义为text image bit 的字段不要建立索引
- 频繁更新的字段不要建立索引
- 定义为外键的列一定要创建索引
- 长字符串中,建立前缀索引
- 尽量扩展索引 而不是新建索引。
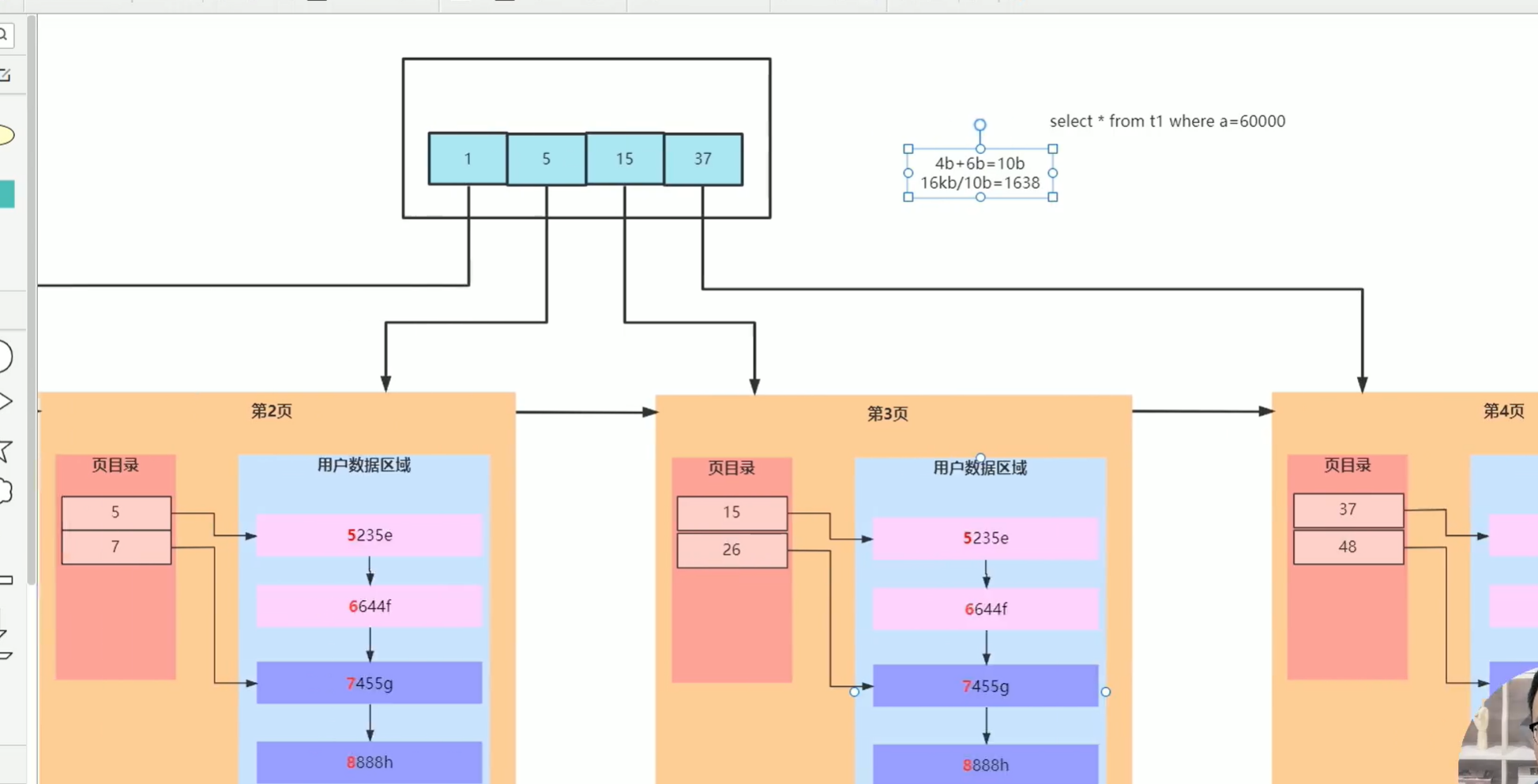
InnoDB页:在存储和查询时按页,从磁盘中存取(默认16kb)。B+树的实现
- 页头:前驱后继指针。
- UserRecord:以链表存储数据。在插入时默认保持主键有序(使用自增ID的原因)。
- 页目录:提高链表查询效率
- 页扩充:开新页增加记录时,用指针指向新页,仍然要保持有序,因此新记录有可能存放于旧页,而旧页中的某记录可能被挪至新页(使用自增ID的原因)
- 建立页目录的目录。(成为B+树了)
其他引擎:
- MyISAM: 不支持行级锁。不支持事务。不支持安全恢复。不支持外键。使用非聚集索引。
- Memory:使用哈希存储数据,存在内存中。
VARCHAR:一个字符占用3个字节,最多2^16=65536个字节。
一条记录中除text、blob外所有字段的字节数和不能超过65536.
如何提高insert性能?


- 索引失效:
- 建立了联合索引,但查询where 没有查最左字段
- 如建立了abc的索引,但只查询bc。因为索引是根据最左前缀原则建立的。
- 在范围查找时,如select的字段没有建立索引,且范围内数据比较多
- 如select * where b>2。可以在b索引中找到b>2的所有主键然后回表,也可以直接在主键索引中全表扫描。若范围内数据比较多,那么走索引因为回表次数很多,并不一定比全表扫描快。
- order by的某字段没有建立索引。
- 在where中对字段进行了类型转换/运算/函数。如索引是用varchar建立的,而where中用得是整型数条件,相当于进行了类型转换。char字母默认转为数字0。 char数字默认转为相应数字。
- where中使用了like '%‘开头。
- 在where中使用or时,两边其中有一个字段没有创建索引,另一个字段有索引也会失效。应当使用union。
Explain select *:执行计划

- id:查询语句的id(自增)
- type:MySQL Explain 之 type 详解 | MySQL 技术论坛 (learnku.com)
- const、唯一索引、范围查找、索引全扫描、全表扫描
- possible_keys:可能会使用的索引(但可能失效而不使用)
- key:使用的索引
- key_len:命中了几个索引
- rows:select会扫描的行数
- filtered:返回行数/rows的百分比
分库分表:
- 主从赋值读写分离:使用多个从库副本(Slaver)负责读,使用主库(Master)负责写。并通过bin log对从库进行同步更新。
- 垂直切分:字段很多,将不常用或字段长度较大的字段拆分出去到扩展表中,实际上是对业务进行解耦合,更便于开发与维护,也能避免跨页问题,一条记录占用空间过大会导致跨页,造成额外的性能开销。另外数据库以行为单位加载到内存中,表中字段长度较短的话,内存能加载更多的数据,命中率更高,减少了磁盘IO,从而提升了数据库性能。
- 水平分库:垂直切分后,无法解决数据库或表行数过多,进行水平切分,并可以在不同机器存储。有效缓解单机单库带来的性能瓶颈和压力。范围切分、hash取模切分、时空切分。但需要解决分布式事务、无法跨库使用join
MySQL原理的更多相关文章
- Mysql原理与优化
原文:https://mp.weixin.qq.com/s__biz=MzI4NTA1MDEwNg==&mid=2650763421&idx=1&sn=2515421f09c1 ...
- mysql 原理 ~ 二阶段提交协议通说
一 简介: 今天是第二篇,讲解的是mysql的事务日志 二 具体 1 WAL技术(先写日志,再写磁盘) 2 binlog redolog 二阶段提交协议 目的 保持 redo log和binl ...
- Oracle数据库,忽略大小写Like模糊查询(SQL Server,MySql原理相同)
背景 在使用Oracle或者其它数据库时,使用like 关键字进行模糊查询是大家经常使用的功能,在纯中文环境中使用非常好用,还有一些通配符可以使用,但是在纯英文环境中,会出现大小需要精确匹配的问题,主 ...
- mysql原理以及相关优化
说起MySQL的查询优化,相信大家积累一堆技巧:不能使用SELECT *.不使用NULL字段.合理创建索引.为字段选择合适的数据类型..... 你是否真的理解这些优化技巧?是否理解其背后的工作原理?在 ...
- Mysql 原理以及常见mysql 索引等
## 主键 超键 候选键 外键 (mysql数据库常见面试题) 数据库之互联网常用架构方案 数据库之互联网常用分库分表方案 分布式事务一致性解决方案 MySQL Explain详解 ## 数据库事务的 ...
- 要了解mysql原理,还是要心里有点B树才行
要了解数据库索引的底层原理,我们就得先了解一种叫树的数据结构,而树中很经典的一种数据结构就是二叉树!所以下面我们就从二叉树到平衡二叉树,再到B-树,最后到B+树来一步一步了解数据库索引底层的原理! ...
- 【MySQL 原理分析】之 Trace 分析 order by 的索引原理
一.背景 昨天早上,交流群有一位同学提出了一个问题.看下图: 我不是大佬,而且当时我自己的想法也只是猜测,所以并没有回复那位同学,只是接下来自己做了一个测试验证一下. 他只简单了说了一句话,就是同样的 ...
- mysql 原理 ~ redo
一 简介:redo log二 文件 ib_logfile0 ib_logfile1 两个redo log 默认为一组 循环覆盖写入三 相关参数 innodb_log_file_size=256 ...
- mysql 原理 ~ 线程与IO
一 简介:今天来聊聊具体的线程和IO 二 具体线程与作用 1 master thread mysql的主要工作触发线程 1 redo and binlog日志 2 合并插入缓冲. ...
随机推荐
- 大一/初学者学C语言前必看!!!(建议收藏)
目录 数据类型 常量.变量 数组 字符串.转义字符 选择语句 循环语句 函数 操作符 结构体 指针 神秘的学习资料基地jq.qq.com/?_wv=1027&k=5kWJsY1z 一.数据类 ...
- 【ConcurrentHashMap】浅析ConcurrentHashMap的构造方法及put方法(JDK1.7)
目录 引言 代码讲解 构造方法 put方法 ensureSegment Segment.put 引言 ConcurrentHashMap的数据结构如下. 和HashMap的最大区别在于多了一层Segm ...
- 干货 | 手把手教你搭建一套OpenStack云平台
1 前言 今天我们为一位朋友搭建一套OpenStack云平台. 我们使用Kolla部署stein版本的OpenStack云平台. kolla是用于自动化部署OpenStack的一个项目,它基于dock ...
- PHP反序列化链分析
前言 基本的魔术方法和反序列化漏洞原理这里就不展开了. 给出一些魔术方法的触发条件: __construct()当一个对象创建(new)时被调用,但在unserialize()时是不会自动调用的 __ ...
- Jackson通用工具类
compile group: 'com.fasterxml.jackson.core', name: 'jackson-core', version: '2.11.1' compile group: ...
- vue - Vue路由
至此基本上vue2.0的内容全部结束,后面还有点elementUI和vue3.0的内容过几天再来更新. 这几天要回学校去参加毕业答辩,断更几天 一.相关理解 是vue的一个插件库,专门用来实现spa( ...
- jenkins插件Role-based添加账号后显示红色"No type prefix"
jenkins插件Role-based添加账号save后,前面显示红色"No type prefix",不影响使用. 查了下原因,网上很少正解,我这里记录下正确的方法: 添加用户: ...
- Spring Boot 3.0.0 M3、2.7.0发布,2.5.x将停止维护
昨晚(5月19日),Spring Boot官方发布了一系列Spring Boot的版本更新,其中包括: Spring Boot 3.0.0-M3 Spring Boot 2.7.0 Spring Bo ...
- Java线程同步操作
synchronized 作用于对象实例:对给定对象加锁,进入同步代码前要获得给定对象的锁. 作用于实例方法:相当于对当前实例加锁,进入同步代码前要获得当前实例的锁. 作用于静态方法:相当于对当前类加 ...
- R-CNN学习笔记
R-CNN学习笔记 step1:总览 步骤: 输入图片 先挑选大约2000个感兴趣区域(ROI)使用select search方法:[在输入的图像中寻找blobby regions(可能相同纹理,颜色 ...