JVM学习笔记——内存模型篇
JVM学习笔记——内存模型篇
在本系列内容中我们会对JVM做一个系统的学习,本片将会介绍JVM的内存模型部分
我们会分为以下几部分进行介绍:
- 内存模型
- 乐观锁与悲观锁
- synchronized优化
内存模型
这一小节我们来详细介绍一下内存模型和内存模型的三个特性
内存模型简介
首先我们来简单介绍一下内存模型:
- 内存模型,全称Java Memory Model,也就是我们常说的JMM
- JMM中定义了一套在多线程读写共享数据时,对数据的可见性,有序性和原子性的规则和保障
内存模型之原子性
我们将在下面仔细介绍原子性的特点
原子性介绍
我们首先介绍一下原子性:
- 原子性是指将一系列操作规划为一个操作,全称不可分离进行
原子性的注意点:
- 我们在单线程下不会出现原子性的问题
- 但在多线程下,每条语句的实际底层操作不止一步,可能就会导致操作错误
原子性问题
我们给出一个简单的例子来解释原子性:
package cn.itcast.jvm.t4.avo;
// 在下述操作中,我们分别创造两个线程,分别执行i++和i--50000次,按正常逻辑来说结果应该为0
public class Demo4_1 {
static int i = 0;
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
for (int j = 0; j < 50000; j++) {
i++;
}
});
Thread t2 = new Thread(() -> {
for (int j = 0; j < 50000; j++) {
i--;
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(i);
}
}
但我们多次运行的结果如下:
// 每次结果均不相同
302
-986
0
原子性分析
首先我们分别给出i++和i--的底层操作:
// i++
getstatic i // 获取静态变量i的值
iconst_1 // 准备常量1
iadd // 加法
putstatic i // 将修改后的值存入静态变量i
// i--
getstatic i // 获取静态变量i的值
iconst_1 // 准备常量1
isub // 减法
putstatic i // 将修改后的值存入静态变量i
我们的原子性分为两种情况:
- 单线程情况下:我们的顺序肯定是按照正常顺序来执行
- 多线程情况下:我们i++的操作按顺序执行,i--的操作按顺序执行,但两者操作可能会交替进行
首先我们给出单线程情况下底层代码:
// 单线程
// 假设i的初始值为0
getstatic i // 线程1-获取静态变量i的值 线程内i=0
iconst_1 // 线程1-准备常量1
iadd // 线程1-自增 线程内i=1
putstatic i // 线程1-将修改后的值存入静态变量i 静态变量i=1
getstatic i // 线程1-获取静态变量i的值 线程内i=1
iconst_1 // 线程1-准备常量1
isub // 线程1-自减 线程内i=0
putstatic i // 线程1-将修改后的值存入静态变量i 静态变量i=0
然后我们分别给出多线程情况下多种结果的底层代码:
// 多线程
// 负数
// 假设i的初始值为0
getstatic i // 线程1-获取静态变量i的值 线程内i=0
getstatic i // 线程2-获取静态变量i的值 线程内i=0
iconst_1 // 线程1-准备常量1
iadd // 线程1-自增 线程内i=1
putstatic i // 线程1-将修改后的值存入静态变量i 静态变量i=1
iconst_1 // 线程2-准备常量1
isub // 线程2-自减 线程内i=-1
putstatic i // 线程2-将修改后的值存入静态变量i 静态变量i=-1
// 正数
// 假设i的初始值为0
getstatic i // 线程1-获取静态变量i的值 线程内i=0
getstatic i // 线程2-获取静态变量i的值 线程内i=0
iconst_1 // 线程1-准备常量1
iadd // 线程1-自增 线程内i=1
iconst_1 // 线程2-准备常量1
isub // 线程2-自减 线程内i=-1
putstatic i // 线程2-将修改后的值存入静态变量i 静态变量i=-1
putstatic i // 线程1-将修改后的值存入静态变量i 静态变量i=1
原子性实现
那么我们该如何实现多线程的原子性:
- 使用synchronized(同步关键字)
我们这里给出synchronized的使用方式:
synchronized( 对象 ) {
// 要作为原子操作代码
}
我们如果要实现之前的代码,我们可以将代码修改为:
package cn.itcast.jvm.t4.avo;
public class Demo4_1 {
// 这里的i应该被多线程共用,设为静态变量
static int i = 0;
// 这里是Obj对象,我们设置它为锁,注意两个线程中的synchronized所对应的锁应该是同一个对象(锁)
static Object obj = new Object();
public static void main(String[] args) throws InterruptedException {
// 采用synchronized设置锁实现原子性,这样i++操作就会完整进行
Thread t1 = new Thread(() -> {
synchronized (obj) {
for (int j = 0; j < 50000; j++) {
i++;
}
}
});
Thread t2 = new Thread(() -> {
// 采用synchronized设置锁实现原子性,这样i--操作就会完整进行
synchronized (obj) {
for (int j = 0; j < 50000; j++) {
i--;
}
}
});
t1.start();
t2.start();
t1.join();
t2.join();
// 我们的输出结果自然是0了~
System.out.println(i);
}
}
内存模型之可见性
我们将在下面仔细介绍可见性的特点
可见性介绍
首先我们简单介绍一下可见性的定义:
- 我们需要保证,在多个线程中,对同一变量的修改需要被其他线程所知道并且可以调用
可见性的注意点:
- 我们的程序往往具有自动优化,对于多次取同一值的数据可能会封装在自己的程序中而不是在源程序读取,这就会导致可见性失效
可见性问题
我们同样给出一段代码作为可见性的案例:
package cn.itcast.jvm.t4.avo;
public class Demo4_2 {
static boolean run = true;
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(()->{
while(run){
}
});
t.start();
Thread.sleep(1000);
run = false; // 线程t不会如预想的停下来
}
}
我们的运行结果如下:
// 我们上述代码希望:程序在执行1s后停止运行,但我们的程序却一直运行不会停止
...
可见性分析
首先我们回顾开头的注意点:
- 程序具有自身很多的优化步骤,可能哪一步就会导致我们的程序出错
我们来简单分析:
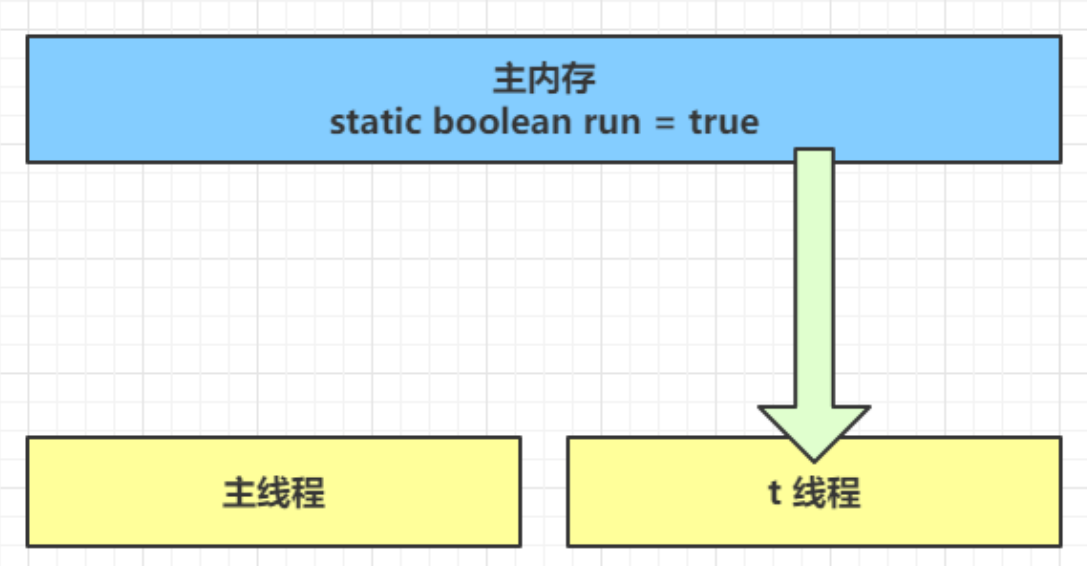
- 初始状态, t 线程刚开始从主内存读取了 run 的值到工作内存。
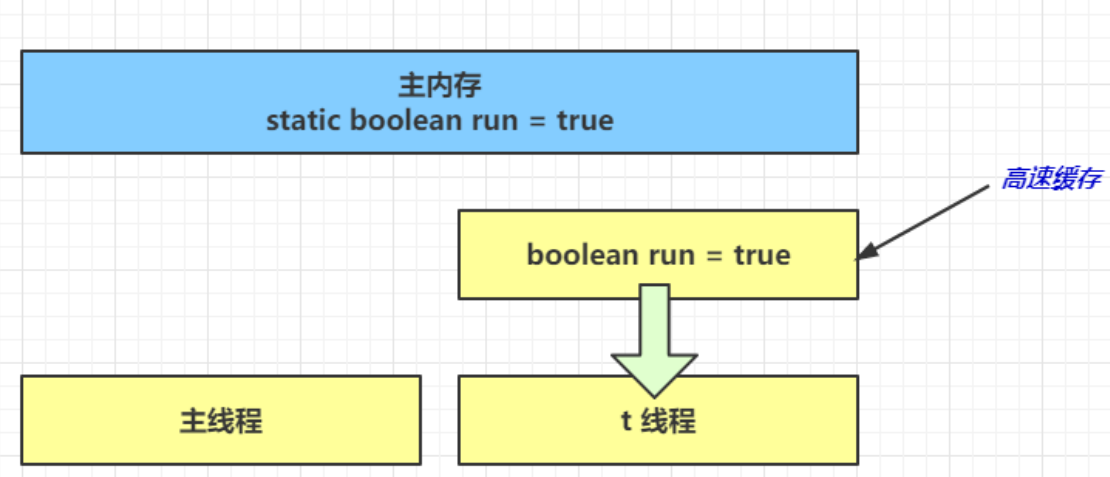
- 线程要频繁从主内存中读取 run 的值,JIT 编译器会将 run 的值缓存至自己工作内存中的高速缓存中,减少对主存中 run 的访问
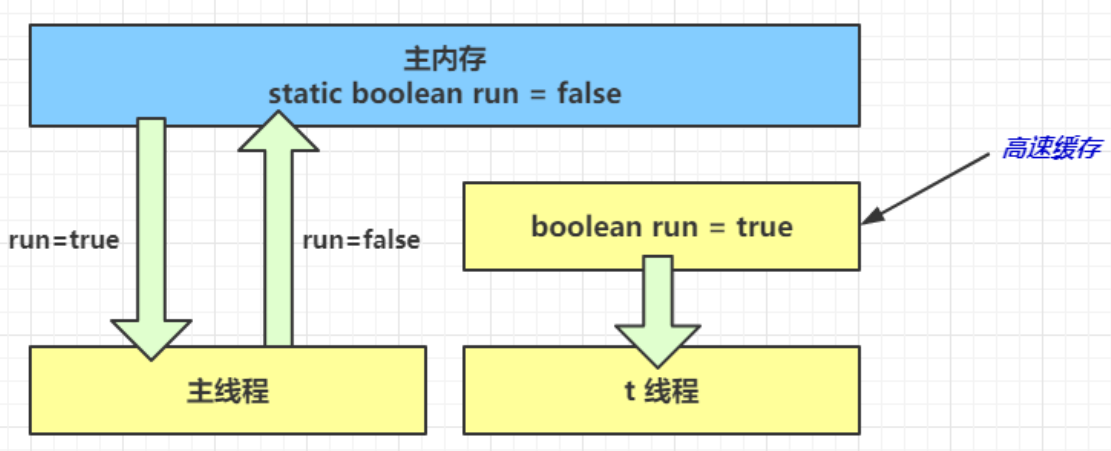
- 1 秒之后,main 线程修改了 run 的值,并同步至主存,而 t 是从自己工作内存中的高速缓存中读取这个变量的值,结果永远是旧值
可见性实现
我们的可见性经常通过一种修饰词来实现:
- volatile(易变关键字)
- 它可以用来修饰成员变量和静态成员变量
- 他可以避免线程从自己的工作缓存中查找变量的值,必须到主存中获取它的值,线程操作 volatile 变量都是直接操作主存
同时我们给出另一种方法:
- synchronized 语句块
- synchronized既可以保证代码块的原子性,也同时保证代码块内变量的可见性
- 但缺点是synchronized是属于重量级操作,性能相对更低
我们如果修改之前代码,就可以采用volatile修改:
package cn.itcast.jvm.t4.avo;
public class Demo4_2 {
static volatile boolean run = true;
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(()->{
while(run){
}
});
t.start();
Thread.sleep(1000);
run = false; // 线程t不会如预想的停下来
}
}
内存模型之有序性
我们将在下面仔细介绍有序性的特点
有序性介绍
首先我们简单介绍一下有序性的定义:
- 有序性就是指我们底层代码实现的具体顺序,在正常情况下是按正常顺序执行
有序性的注意点:
- 同样底层也会进行部分优化,对于有序性的优化常常被称为指令重排,是指在不影响操作的前提下进行语句的优化调整
有序性问题
我们同样给出一段代码:
int num = 0;
boolean ready = false;
// 线程1 执行此方法
public void actor1(I_Result r) {
if(ready) {
r.r1 = num + num;
} else {
r.r1 = 1;
}
}
// 线程2 执行此方法
public void actor2(I_Result r) {
num = 2;
ready = true;
}
我们下面会给出其所有情况:
// 具体分为四种情况,前三种属于正常的多线程无锁导致的情况
// 情况1:线程1 先执行,这时 ready = false,所以进入 else 分支结果为 1
// 情况2:线程2 先执行 num = 2,但没来得及执行 ready = true,线程1 执行,还是进入 else 分支,结果为1
// 情况3:线程2 执行到 ready = true,线程1 执行,这回进入 if 分支,结果为 4(因为 num 已经执行过了)
// 但是第四种!却是因为代码重排所导致的情况:
有序性分析
首先我们在重新介绍一下指令重排:
- JIT 编译器在运行时的一些优化,这个现象需要通过大量测试才能复现
我们可以给出结果为0的执行顺序:
线程2:ready = true;(由于操作更加简单,导致JIT将它放在前面编译)
线程1:if判断 true
线程1:r.r1 = num + num;(此时num为0),结果r1=0
JVM 会在不影响正确性的前提下,可以调整语句的执行顺序:
// 下面是模拟情况:
static int i;
static int j;
// 在某个线程内执行如下赋值操作
// i为较为耗时的操作,j为简单操作
i = ...;
j = ...;
// 底层代码会认为i和j的赋值操作毫无关系,他们谁先执行都可以,所以会优先执行简单的操作
// 所以我们的代码可能变为:
static int i;
static int j;
j = ...;
i = ...;
有序性实现
我们的可见性经常通过一种修饰词来实现:
- volatile 修饰的变量,可以禁用指令重排
所以我们的代码经过修改后可以改造为以下代码:
int num = 0;
boolean volatile ready = false;
// 线程1 执行此方法
public void actor1(I_Result r) {
if(ready) {
r.r1 = num + num;
} else {
r.r1 = 1;
}
}
// 线程2 执行此方法
public void actor2(I_Result r) {
num = 2;
ready = true;
}
happens-before
我们在最后插入一个简单的内容happens-before :
- 规定了哪些写操作对其它线程的读操作可见,它是可见性与有序性的一套规则总结
我们来简单介绍一些:
- 线程 start 前对变量的写,对该线程开始后对该变量的读可见
static int x;
x = 10;
new Thread(()->{
System.out.println(x);
},"t2").start();
- 线程对 volatile 变量的写,对接下来其它线程对该变量的读可见
volatile static int x;
new Thread(()->{
x = 10;
},"t1").start();
new Thread(()->{
System.out.println(x);
},"t2").start();
- 线程解锁 m 之前对变量的写,对于接下来对 m 加锁的其它线程对该变量的读可见
static int x;
static Object m = new Object();
new Thread(()->{
synchronized(m) {
x = 10;
}
},"t1").start();
new Thread(()->{
synchronized(m) {
System.out.println(x);
}
},"t2").start();
- 线程结束前对变量的写,对其它线程得知它结束后的读可见(比如其它线程调用 t1.isAlive() 或t1.join()等待它结束)
static int x;
Thread t1 = new Thread(()->{
x = 10;
},"t1");
t1.start();
t1.join();
System.out.println(x);
- 线程 t1 打断 t2(interrupt)前对变量的写,对于其他线程得知 t2 被打断后对变量的读可见
static int x;
public static void main(String[] args) {
Thread t2 = new Thread(()->{
while(true) {
if(Thread.currentThread().isInterrupted()) {
System.out.println(x);
break;
}
}
},"t2");
t2.start();
new Thread(()->{
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
x = 10;
t2.interrupt();
},"t1").start();
while(!t2.isInterrupted()) {
Thread.yield();
}
System.out.println(x);
}
- 对变量默认值(0,false,null)的写,对其它线程对该变量的读可见
- 具有传递性,如果 x hb-> y 并且 y hb-> z 那么有 x hb-> z
乐观锁与悲观锁
这一小节我们来详细介绍一下乐观锁和悲观锁的概念以及原型
乐观锁与悲观锁简介
我们首先分别简单介绍一下乐观锁和悲观锁:
- 乐观锁的思想:最乐观的估计,不怕别的线程来修改共享变量,就算改了也没关系,我继续重试即可。
- 悲观锁的思想:最悲观的估计,得防着其它线程来修改共享变量,针对共享数据直接上锁,只有我解锁后你们才能抢夺
我们在这里再简单讲一下两种锁的日常选用:
- 乐观锁用于竞争不激烈且为多核CPU的情况,因为其实乐观锁的不断尝试需要cpu处理并且也会消耗一定内存
- 悲观锁用于竞争激烈需要抢夺资源的情况下,我们直接停止其他操作可以减少其他不必要的内耗
乐观锁实现
乐观锁的实现是采用CAS:
- CAS 即 Compare and Swap ,它体现的一种乐观锁的思想
我们通过一个简单示例展示:
// 需要不断尝试
while(true) {
int 旧值 = 共享变量 ; // 比如拿到了当前值 0
int 结果 = 旧值 + 1; // 在旧值 0 的基础上增加 1 ,正确结果是 1
/*
这时候如果别的线程把共享变量改成了 5,本线程的正确结果 1 就作废了,这时候
compareAndSwap 返回 false,重新尝试,直到:
compareAndSwap 返回 true,表示我本线程做修改的同时,别的线程没有干扰
*/
if( compareAndSwap ( 旧值, 结果 )) {
// 成功,退出循环
}
}
悲观锁实现
乐观锁的实现是采用synchronized:
- synchronized体现的是一种悲观锁的思想
我们通过一个简单示例展示:
package cn.itcast.jvm.t4.avo;
// 我们进行操作时,直接上锁,不允许其他进程涉及!
public class Demo4_1 {
// 这里的i应该被多线程共用,设为静态变量
static int i = 0;
// 这里是Obj对象,我们设置它为锁,注意两个线程中的synchronized所对应的锁应该是同一个对象(锁)
static Object obj = new Object();
public static void main(String[] args) throws InterruptedException {
// 采用synchronized设置锁实现原子性,这样i++操作就会完整进行
Thread t1 = new Thread(() -> {
synchronized (obj) {
for (int j = 0; j < 50000; j++) {
i++;
}
}
});
Thread t2 = new Thread(() -> {
// 采用synchronized设置锁实现原子性,这样i--操作就会完整进行
synchronized (obj) {
for (int j = 0; j < 50000; j++) {
i--;
}
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(i);
}
}
原子操作类
其实JUC中为我们提供了原子操作类:
- 可以提供线程安全的操作,例如:AtomicInteger、AtomicBoolean等,它们底层就是采用 CAS 技术 + volatile 来实现的。
我们采用改写之前的一个例子来进行展示:
package cn.itcast.jvm.t4.avo;
import java.util.concurrent.atomic.AtomicInteger;
public class Demo4_4 {
// 创建原子整数对象
private static AtomicInteger i = new AtomicInteger(0);
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
for (int j = 0; j < 5000; j++) {
i.getAndIncrement(); // 获取并且自增 i++
// i.incrementAndGet(); 自增并且获取 ++i
}
});
Thread t2 = new Thread(() -> {
for (int j = 0; j < 5000; j++) {
i.getAndDecrement(); // 获取并且自减 i--
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(i);
}
}
synchronized 优化
这一小节我们来详细介绍一下synchronized的优化部分
Mark Word
我们首先来介绍一个概念:
- Java HotSpot 虚拟机中,每个对象都有对象头(包括 class 指针和 Mark Word)。
那么我们主要需要这个Mark Word来存储信息:
- Mark Word 平时存储这个对象的哈希码,分代年龄
- 当加锁时这些信息就根据情况被替换为 标记位,线程锁记录指针,重量级锁指针,线程ID 等内容
轻量级锁
首先我们先来介绍一下轻量级锁:
- 如果一个对象虽然有多线程访问,但多线程访问的时间是错开的(也就是没有竞争),那么可以使用轻量级锁来优化。
我们通过一个简单案例展示:
static Object obj = new Object();
public static void method1() {
synchronized( obj ) {
// 同步块 A
method2();
}
}
public static void method2() {
synchronized( obj ) {
// 同步块 B
}
}
我们会发现即使上述为两个锁,但是同时都属于当前主线程下,并且是按顺序执行,这是就采用了轻量级锁
我们通过一个表格写出其具体流程:
| 线程 1 | 对象 Mark Word | 线程 2 |
|---|---|---|
| 访问同步块 A,把 Mark 复制到 线程 1 的锁记录 | 01(无锁) | - |
| CAS 修改 Mark 为线程 1 锁记录 地址 | 01(无锁) | - |
| 成功(加锁) | 00(轻量锁)线程 1 锁记录地址 | - |
| 执行同步块 A | 00(轻量锁)线程 1 锁记录地址 | - |
| 访问同步块 B,把 Mark 复制到 线程 1 的锁记录 | 00(轻量锁)线程 1 锁记录地址 | - |
| CAS 修改 Mark 为线程 1 锁记录 地址 | 00(轻量锁)线程 1 锁记录地址 | - |
| 失败(发现是自己的锁) | 00(轻量锁)线程 1 锁记录地址 | - |
| 锁重入 | 00(轻量锁)线程 1 锁记录地址 | - |
| 执行同步块 B | 00(轻量锁)线程 1 锁记录地址 | - |
| 同步块 B 执行完毕 | 00(轻量锁)线程 1 锁记录地址 | - |
| 同步块 A 执行完毕 | 00(轻量锁)线程 1 锁记录地址 | - |
| 成功(解锁) | 01(无锁) | - |
| - | 01(无锁) | 访问同步块 A,把 Mark 复制到 线程 2 的锁记录 |
| - | 01(无锁) | CAS 修改 Mark 为线程 2 锁记录 地址 |
| - | 00(轻量锁)线程 2 锁记录地址 | 成功(加锁) |
| - | ... | ... |
锁的膨胀
我们同样先来介绍锁膨胀的概念:
- 如果在尝试加轻量级锁的过程中,CAS 操作无法成功
- 这时一种情况就是有其它线程为此对象加上了轻量级锁(有竞争),这时需要进行锁膨胀,将轻量级锁变为重量级锁。
我们直接给出一个表格写出其具体流程:
| 程 1 | 对象 Mark | 线程 2 |
|---|---|---|
| 访问同步块,把 Mark 复制到线程 1 的锁记录 | 01(无锁) | - |
| CAS 修改 Mark 为线程 1 锁记录地 址 | 01(无锁) | - |
| 成功(加锁) | 00(轻量锁)线程 1 锁 记录地址 | - |
| 执行同步块 | 00(轻量锁)线程 1 锁 记录地址 | - |
| 执行同步块 | 00(轻量锁)线程 1 锁 记录地址 | 访问同步块,把 Mark 复制 到线程 2 |
| 执行同步块 | 00(轻量锁)线程 1 锁 记录地址 | CAS 修改 Mark 为线程 2 锁 记录地址 |
| 执行同步块 | 00(轻量锁)线程 1 锁 记录地址 | 失败(发现别人已经占了 锁) |
| 执行同步块 | 00(轻量锁)线程 1 锁 记录地址 | CAS 修改 Mark 为重量锁 |
| 执行同步块 | 10(重量锁)重量锁指 针 | 阻塞中 |
| 执行完毕 | 10(重量锁)重量锁指 针 | 阻塞中 |
| 失败(解锁) | 10(重量锁)重量锁指 针 | 阻塞中 |
| 释放重量锁,唤起阻塞线程竞争 | 01(无锁) | 阻塞中 |
| - | 10(重量锁) | 竞争重量锁 |
| - | 10(重量锁) | 成功(加锁) |
| - | ... | ... |
重量级锁
我们这里也来简单介绍一下重量级锁的优化方法:
- 重量级锁竞争的时候,还可以使用自旋来进行优化
- 如果当前线程自旋成功(即这时候持锁线程已经退出了同步块,释放了锁),这时当前线程就可以避免阻塞
我们对自旋进行简单补充:
- 在 Java 6 之后自旋锁是自适应的
- 比如对象刚刚的一次自旋操作成功过,那么认为这次自旋成功的可能性会高,就多自旋几次;反之,就少自旋甚至不自旋
- 自旋会占用 CPU 时间,单核 CPU 自旋就是浪费,多核 CPU 自旋才能发挥优势。
- Java 7 之后不能控制是否开启自旋功能
首先我们给出自旋成功的流程展示:
| 线程 1 (cpu 1 上) | 对象 Mark | 线程 2 (cpu 2 上) |
|---|---|---|
| - | 10(重量锁) | - |
| 访问同步块,获取 monitor | 10(重量锁)重量锁指针 | - |
| 成功(加锁) | 10(重量锁)重量锁指针 | - |
| 执行同步块 | 10(重量锁)重量锁指针 | - |
| 执行同步块 | 10(重量锁)重量锁指针 | 访问同步块,获取 monitor |
| 执行同步块 | 10(重量锁)重量锁指针 | 自旋重试 |
| 执行完毕 | 10(重量锁)重量锁指针 | 自旋重试 |
| 成功(解锁) | 01(无锁) | 自旋重试 |
| - | 10(重量锁)重量锁指针 | 成功(加锁) |
| - | 10(重量锁)重量锁指针 | 执行同步块 |
| - | ... | ... |
然后我们给出自旋失败的流程展示:
| 线程 1(cpu 1 上) | 对象 Mark | 线程 2(cpu 2 上) |
|---|---|---|
| - | 10(重量锁) | - |
| 访问同步块,获取 monitor | 10(重量锁)重量锁指针 | - |
| 成功(加锁) | 10(重量锁)重量锁指针 | - |
| 执行同步块 | 10(重量锁)重量锁指针 | - |
| 执行同步块 | 10(重量锁)重量锁指针 | 访问同步块,获取 monitor |
| 执行同步块 | 10(重量锁)重量锁指针 | 自旋重试 |
| 执行同步块 | 10(重量锁)重量锁指针 | 自旋重试 |
| 执行同步块 | 10(重量锁)重量锁指针 | 自旋重试 |
| 执行同步块 | 10(重量锁)重量锁指针 | 阻塞 |
| - | ... | ... |
偏向锁
我们首先来介绍一下偏向锁:
- 轻量级锁在没有竞争时(就自己这个线程),每次重入仍然需要执行 CAS 操作,Java 6 中引入了偏向锁来做进一步优化
- 只有第一次使用 CAS 将线程 ID 设置到对象的 Mark Word 头,之后发现这个线程 ID是自己的就表示没有竞争,不用重新 CAS.
我们给出偏向锁的一些补充信息:
- 撤销偏向需要将持锁线程升级为轻量级锁,这个过程中所有线程需要暂停(STW)
- 访问对象的 hashCode 也会撤销偏向锁
- 如果对象虽然被多个线程访问,但没有竞争,这时偏向了线程 T1 的对象仍有机会重新偏向 T2,重偏向会重置对象的 Thread ID
- 撤销偏向和重偏向都是批量进行的,以类为单位
- 如果撤销偏向到达某个阈值,整个类的所有对象都会变为不可偏向的
- 可以主动使用 -XX:-UseBiasedLocking 禁用偏向锁
我们采用轻量级锁的代码但是加入了偏向锁之后的流程:
| 线程 1 | 对象 Mark |
|---|---|
| 访问同步块 A,检查 Mark 中是否有线程 ID | 101(无锁可偏向) |
| 尝试加偏向锁 | 101(无锁可偏向)对象 hashCode |
| 成功 | 101(无锁可偏向)线程ID |
| 执行同步块 A | 101(无锁可偏向)线程ID |
| 访问同步块 B,检查 Mark 中是否有线程 ID | 101(无锁可偏向)线程ID |
| 是自己的线程 ID,锁是自己的,无需做更多操作 | 101(无锁可偏向)线程ID |
| 执行同步块 B | 101(无锁可偏向)线程ID |
| 执行完毕 | 101(无锁可偏向)对象 hashCode |
其它优化
我们下面来简单介绍一下其他的几种优化:
- 减少上锁时间
/*
上锁期间的代码是影响上锁时间的最大因素
我们应该确保同步代码块中尽量短
*/
- 减少锁的粒度
/*
将一个锁拆分为多个锁提高并发度
例如:LinkedBlockingQueue 入队和出队使用不同的锁,相对于LinkedBlockingArray只有一个锁效率要高
*/
- 锁粗化
/*
多次循环进入同步块不如同步块内多次循环
另外 JVM 可能会做如下优化,把多次 append 的加锁操作粗化为一次(因为都是对同一个对象加锁,没必要重入多次)
例如:new StringBuffer().append("a").append("b").append("c");
*/
- 锁消除
/*
JVM 会进行代码的逃逸分析,例如某个加锁对象是方法内局部变量,不会被其它线程所访问到,这时候就会被即时编译器忽略掉所有同步操作。
*/
- 读写分离
/*
CopyOnWriteArrayList
ConyOnWriteSet
*/
结束语
到这里我们JVM的内存模型篇就结束了,希望能为你带来帮助~
附录
该文章属于学习内容,具体参考B站黑马程序员满老师的JVM完整教程
这里附上视频链接:01-JMM-概述_哔哩哔哩_bilibili
JVM学习笔记——内存模型篇的更多相关文章
- JVM学习笔记——垃圾回收篇
JVM学习笔记--垃圾回收篇 在本系列内容中我们会对JVM做一个系统的学习,本片将会介绍JVM的垃圾回收部分 我们会分为以下几部分进行介绍: 判断垃圾回收对象 垃圾回收算法 分代垃圾回收 垃圾回收器 ...
- JVM学习笔记——内存结构篇
JVM学习笔记--内存结构篇 在本系列内容中我们会对JVM做一个系统的学习,本片将会介绍JVM的内存结构部分 我们会分为以下几部分进行介绍: JVM整体介绍 程序计数器 虚拟机栈 本地方法栈 堆 方法 ...
- JVM学习--(二)内存模型、可见性、指令重排序
我们将根据JVM的内存模型探索java当中变量的可见性以及不同的java指令在并发时可能发生的指令重排序的情况. 内存模型 首先我们思考一下一个java线程要向另外一个线程进行通信,应该怎么做,我们再 ...
- JVM学习笔记-内存管理
第一章 内存分配 1. 内存区域. 方法区和堆(线程共享),程序计数器 , VM栈 和 本地方法栈(线程隔离). 1) java虚拟机栈:线程私有.描写叙述的是java方法执行的内存模 ...
- jvm内存JVM学习笔记-引用(Reference)机制
在写这篇文章之前,xxx已经写过了几篇关于改jvm内存主题的文章,想要了解的朋友可以去翻一下之前的文章 如果你还不了解JVM的基本概念和内存划分,请阅读JVM学习笔记-基础知识和JVM学习笔记-内存处 ...
- JUC学习笔记——共享模型之内存
JUC学习笔记--共享模型之内存 在本系列内容中我们会对JUC做一个系统的学习,本片将会介绍JUC的内存部分 我们会分为以下几部分进行介绍: Java内存模型 可见性 模式之两阶段终止 模式之Balk ...
- JVM学习笔记(四)------内存调优【转】
转自:http://blog.csdn.net/cutesource/article/details/5907418 版权声明:本文为博主原创文章,未经博主允许不得转载. 首先需要注意的是在对JVM内 ...
- JVM学习笔记(四)------内存调优
首先需要注意的是在对JVM内存调优的时候不能只看操作系统级别Java进程所占用的内存,这个数值不能准确的反应堆内存的真实占用情况,因为GC过后这个值是不会变化的,因此内存调优的时候要更多地使用JDK提 ...
- JVM学习笔记-第三章-垃圾收集器与内存分配策略
JVM学习笔记-第三章-垃圾收集器与内存分配策略 tips:对于3.4之前的章节可见博客:https://blog.csdn.net/sanhewuyang/article/details/95380 ...
随机推荐
- linux --stdin 管道 标准输入重定向
linux --stdin 标准输入重定向 --stdin This option is used to indicate that passwd should read the new passwo ...
- 【Java】学习路径49-练习:使用两个不同的线程类实现买票系统
练习:使用两个不同的线程类实现买票系统 请创建两个不同的线程类.一个测试类以及一个票的管理类. 其中票的管理类用于储存票的数量.两个线程类看作不同的买票方式. 步骤: 1.创建所需的类 App售票线程 ...
- VS2017Enterprise版本安装ImageWatch 2017问题解决
按照Andrei给的方法并不一定能成功. 方法如下: 1. Download the extension (ImageWatch.vsix) and open it using WinRAR 2. F ...
- Jetpack架构组件学习(4)——APP Startup库的使用
最近在研究APP的启动优化,也是发现了Jetpack中的App Startup库,可以进行SDK的初始化操作,于是便是学习了,特此记录 原文:Jetpack架构组件学习(4)--App Startup ...
- Java中数组
数组的定义格式: 1: 数据类型[] 数组名 2: 数据类型 数组名 动态初始化: 初始化的时候 系统会默认给数组赋值 数据类型[] 变量名 = new 数据类型[数组长度] int[] arr = ...
- 第九十六篇:恶补JS基础
好家伙,来补基础啦,补JS的基础 先来一些概念性的东西 1.什么是JavaScript? javaScript的简写形式就是JS,一种广泛用于客户端Web开发的脚本语言,常用来给HTML网页添加动态 ...
- ubuntu生成ssh_key
ssh-keygen cat ~/.ssh/id_rsa.pub
- 我也是一个“翻译家”——关于“robust”
每次看到"鲁棒性",总是不知道是什么意思,一度怀疑自己是不是中国人,是不是说汉语.每次都要查英汉字典,然后一次次看到: robust(adj.精力充沛的; 坚定的; 粗野的,粗鲁的 ...
- 点赞和取消点赞实现Redis缓存(只思路)
思路:点赞.取消点赞 --> Redis --> (每两个小时)存到数据库(MySQL),所以就相当于每次查询或者存储都需要先经过Redis,而查询的目的是为了判断用户的点赞状态(已点赞o ...
- Dapr 集成 Open Policy Agent
大型项目中基本都包含有复杂的访问控制策略,特别是在一些多租户场景中,例如Kubernetes中就支持RBAC,ABAC等多种授权类型.Dapr 的 中间件 Open Policy Agent 将Reg ...